基于语料库的翻译单位本体性研究
2020-09-03李康熙
李康熙,孟 洁
(合肥工业大学 外国语学院,合肥 230601)
一、引 言
众所周知,文本的翻译并非是逐词进行的。首先,单词本质上是多义的(polysemous),在脱离上下文语境时很难确定其具体涵义;其次,源语与目标语的词法、句法和语义体系不尽相同,因此多数情况下无法在词汇层面上建立二者的一一对应关系。鉴于以上事实,翻译学研究中引入了翻译单位这个概念,用于描述译者在翻译过程中所使用的操作单位。
不幸的是,尽管翻译单位的概念很早即已提出[1]21,且在翻译学研究中引起了足够多的讨论,但是由于研究方法上普遍缺乏对翻译单位本体的重视,一定程度上造成了翻译单位概念的混乱。彭长江[2]认为某些学者“往往不明确否定巴氏[巴尔胡达罗夫]定义的核心,实际上将其抛弃,却不为翻译单位重新下定义”。司显柱[3]也曾指出在翻译单位问题上,各家立论之间彼此相互对立,互不相容。只有回归翻译单位的本体性研究,才有可能厘清翻译单位的基本性质,并为后续研究提供准确的概念参照体系。
本研究拟转变现有的翻译单位研究的范式,通过语料库定量研究方法来代替传统的定性研究方法来界定翻译单位的内涵与外延。在详细对比各种翻译单位定义的基础上,本研究总结了翻译单位的四种基本属性,并据此对双语平行语料库中的翻译单位进行手工标注。最后对标注结果进行统计分析,进而加深人们对翻译单位概念的本体性认识。
二、翻译单位定义
纵观翻译单位的研究历史可见,早期的翻译单位研究倾向于对翻译单位给出明确的定义,其中具有代表性的定义及其翻译如下:一是最小的话语片段,其全部符号结合得如此紧密以至于不可能分开翻译[1]21。二是在译文中能够找到对应物的源文单位,但它的组成部分单独地在译文中却并没有对应物。换言之,翻译单位就是源语在译语中具备对应物的最小(最低限度)的语言单位[4]。 三是最小的可以独立于其他部分而作为一个整体翻译的源文片段[5](1)此处为Newmark对Vinay & Darbelnet提出的翻译单位定义的重新阐述。。四是译者在翻译时所关注的源文片段,该片段在目标语中需要作为一个整体来对待[6]。五是翻译过程中最小的无歧义的(源文)语言单位[7]。六是两类(翻译)单位称为话语层翻译的分析单位和转换单位。话语层翻译的分析单位指一个相对完整的语言材料,它能帮助我们对话语内部、话语外部以及属于理解语言心理机制等方面的非语言因素做出恰当分析的单位。话语层翻译的转换单位指在译文中能够找到相应的源语单位,不过它的组成部分不一定能在译文中找到对应物[8]。
这些代表性的翻译单位定义的共性是显而易见的,即它们都认为翻译单位是源文的某一级语言单位,它由于某种因素在翻译过程中作为一个整体来对待。这些定义还暗示着,翻译单位并非一成不变地固定在词汇这个级别,否则我们将没有任何必要去研究这种翻译现象。对比发现,各翻译单位定义之间的差异主要在于如何界定翻译单位这个方面。本研究总结认为,翻译单位的定义属性包括以下四个方面:
一是紧密性(compactness),即源文某语言单位内部各成分密不可分,因此不可以分开逐个翻译或根据字面意思进行翻译。如上所述,Vinay和Darbelnet的翻译单位(见定义一)就是根据紧密性来定义的。
二是独立性(independence),即源文某语言单位与上下文其他成分相对独立,也就说无需参照上下文即可给出翻译对应物。独立性可以看作是紧密性的对立面。前者从语言单位的外部特征来界定翻译单位,后者则从语言单位的内部属性着手。根据定义,独立性是Newmark的翻译单位的根本特征。
三是无歧义性(lack of ambiguity),即源文某语言单位在语义上是自足的。将无歧义性作为翻译单位根本属性的代表人物是Teubert[7,9]。他注意到很多词汇单位都是多义性的,其具体意义取决于上下文语境,所以最小的可翻译单位应该是单词和其相关的上下文语境的组合,这些上下文语境提供了消除词汇歧义的所有必要信息。
四是无对应性(lack of correspondence),即源文某语言单位本身在译文中有对应物,但其下一级组成单位却没有对应物。强调翻译单位的无对应性特征的代表人物是巴尔胡达罗夫。与基于源文分析的紧密性、独立性和无歧义性特征不同,无对应性特征不是根据源文各符号之间的衔接关系来判断翻译单位的。基于无对应性定义的翻译单位是转换性的,一切视源文某单位是否在译文中具有对应物而定。
以上四种定义属性分别从不同的角度来界定翻译单位,体现了翻译单位的多重特征。在翻译的分析过程中,翻译单位取决于源文某单位内部各成分之间的紧密性、与上下文之间的独立性、语义上的无歧义性等特征;而在翻译的转换过程中,翻译单位则取决于该语言单位及其组成成分与译文单位的对应关系。对于同一源文单位,根据不同的定义属性可能会得到不同的判定结果。通过下面的语料标注过程和结果分析,我们可以清晰地发现这四种界定标准之间的区别和联系。
三、数据搜集及处理
本研究划分翻译单位的标准是根据上文提到的四种定义属性来制定的。其中,紧密性、独立性和无歧义性三种属性是作为一个整体来处理的。这主要是出于两方面考虑:其一,三者都是从源文的角度来分析翻译单位的,因此切分结果彼此重合之处很多;其二,紧密性与独立性划分标准的主观性较强,在实际操作时很难处理,而结合无歧义性标准之后则能够获得较为确切的分析结果。相对而言,无对应性标准则是从源文与译文的对比角度来分析翻译单位的,与其他三种标准差异较大,因此本研究将其区别对待。
本研究中翻译单位的标注语料来自NIST 2002机器翻译评测项目的测试集[10]。该语料库包括491对句珠,体裁全部为新闻语料,见表1。

表1 用于翻译单位标注的语料库情况
此语料库中的所有句珠都是1∶1的对齐模式。这意味着在标注过程中不可能出现比句子更大的翻译单位的情况。对于每一对句珠,我们用中括号对英文中的翻译单位进行手工标记。例如:
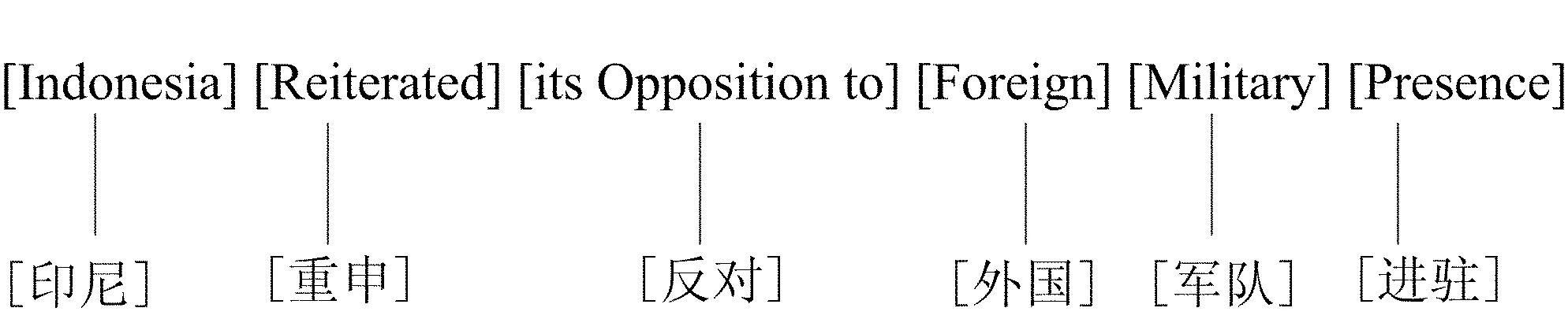
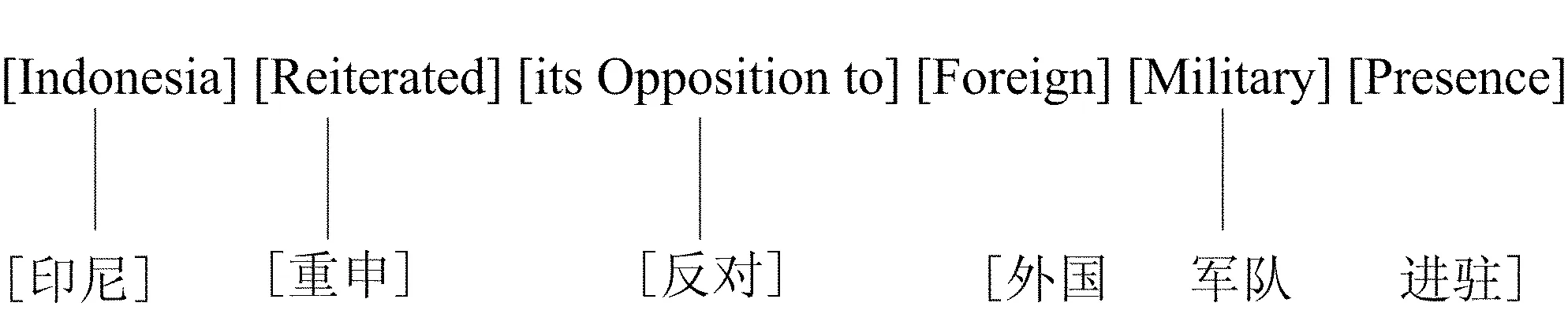
此例是按照无对应性标准来划分翻译单位的。其中,短语foreign military presence的各个组成部分在译文中都有确定的对应物,因此,根据无对应性定义,此短语中的每个单词都是翻译单位。相反,如果根据紧密性或独立性定义,foreign military presence整个短语可视为一个整体概念,因此更适合被标记为一个短语层的翻译单位。从无歧义性的角度看,foreign和military两个词基本上是单义的,但是presence却是一个多义词。只有根据上下文中的特征词military才可以断定它指的是军队进驻,而不是一般意义上的出席或者存在。鉴于此,综合紧密性、独立性和无歧义性三种属性的分析结果,本研究将foreign military presence标注为一个基于源文分析(即综合考虑紧密性、独立性和无歧义性三个标准)的翻译单位,用中括号标注如下:
词性标注是语料预处理的常见步骤。本研究对英文和中文文本进行词性标注的工具为Stanford POS Tagger工具包[11]。之所以使用词性标注工具是为了发现翻译单位的统计分布与词性之间的统计关联。
四、结果分析
传统的翻译单位研究方法通常依赖个人内省经验,导致研究结论主观性较强。相反,本研究根据语料库中的真实翻译实例进行统计分析,从而能够获得更加客观可信的结论。以下是从双语对应语料库的标注结果中得到的几个主要研究发现。
1.翻译单位的统计分布
根据无对应性标准,本研究从上述语料库中共划分出8 568个翻译单位,而基于源文分析的翻译单位共7 295个。具体的标注结果见表2和表3。

表2 基于无对应性的翻译单位统计

表3 基于源文分析的翻译单位统计
由表2可见,基于无对应性的翻译单位主要集中在一元组(unigram)和二元组(bigram)这两个层次上。需要指出的是,本语料的体裁为新闻稿,其中有大量的人名或地名采用音位(字位)层的翻译方式,从而导致该层次的翻译单位比例比正常文本大很多,可见文体是影响翻译单位大小的因素之一。另外,所有的音位(字位)层翻译单位实际上仅仅是由591个单词切分而成的,约占整个英文语料的4.33%。如果按照单词数目来计算的话,实际上以音位(字位)层作为翻译单位的比例是远低于三元组(trigram)翻译单位的。通过对比两类翻译单位的统计结果,本研究发现以下规律:
其一,与基于无对应性的翻译单位相比,基于源文分析的翻译单位平均长度更大。前者的平均长度是1.25词/单位,后者则达到2.49词/单位。
其二,基于源文分析的翻译单位分布区间更大。在极端情况下,翻译单位的长度达到12个单词,如cost the US corporations and government agencies billions of dollars in losses,由于cost和in losses之间的远距离依存关系(long-distance dependency),导致该单位中各部分不能分开独立翻译。
其三,基于源文分析的翻译单位分布更加均匀。从表3可见,虽然此类翻译单位以三元组为主,但是与其他长度的翻译单位相比,统计学差异并不明显。相反,基于无对应性的翻译单位则呈现出截然相反的趋势,多达53%的无对应性翻译单位都出现在单词这个层次上。换句话说,基于无对应性的翻译单位的分布规律性更强,而基于源文分析的翻译单位则主要呈随机分布的特点。
除了长度上的差异之外,本研究还发现两类翻译单位的切分结果是密切联系的。一般来讲,基于源文分析的翻译单位与基于无对应性的翻译单位呈现一种包含与被包含关系。具体来说,前者一般是后者的同级或者上一级语言单位。前者倾向于将词与其上下文语境组合为翻译单位,后者则倾向于以词为翻译单位。
这种现象是很容易解释的。各种基于源文分析的翻译单位,不管是出于内部的紧密性、与上下文的独立性还是无歧义性考虑,最终的结果都要求这些源文单位在译文中具有对应物。这是所有翻译单位定义所暗含的前提假设。只有在找到源文某单位在译文中的对应物之后,我们才会进一步讨论它是否符合紧密性、独立性或无歧义性标准。如果不符合以上翻译单位标准的话,我们将继续分析该单位的上层语言结构,依此类推。基于无对应性的翻译单位的判断过程与此恰恰相反:在确定了源文某单位在译文中的对应物之后,我们将分析该单位的下层结构在译文中的对应情况。当且仅当它的内部某成分在译文中缺乏对应物时,才可以判定它是一个基于无对应性的翻译单位。
以上分析清晰地表明,翻译单位本质上是一个动态的复杂概念。随着分析的角度不同,翻译单位的大小不尽相同。而且,即使选择了确定的角度,我们也不能一劳永逸地将翻译单位固定在某个特定的语言层次。鉴于此,本研究认为,我们有必要采取兼容并包的方式来重新定义翻译单位,即源文中任何一个语言单位,只要它满足上述四种定义属性中的任何一个,即可将其认定为翻译单位。只有这样,我们才能将翻译单位概念应用于整个翻译的分析和转换过程中。
2.翻译单位的影响因素
影响翻译单位的因素是多方面的。结合词性标注工具本研究发现,翻译单位既与单词词性、源语与目标语的相似程度等客观因素,又与译者的翻译策略等主观因素密切相关,见表4。
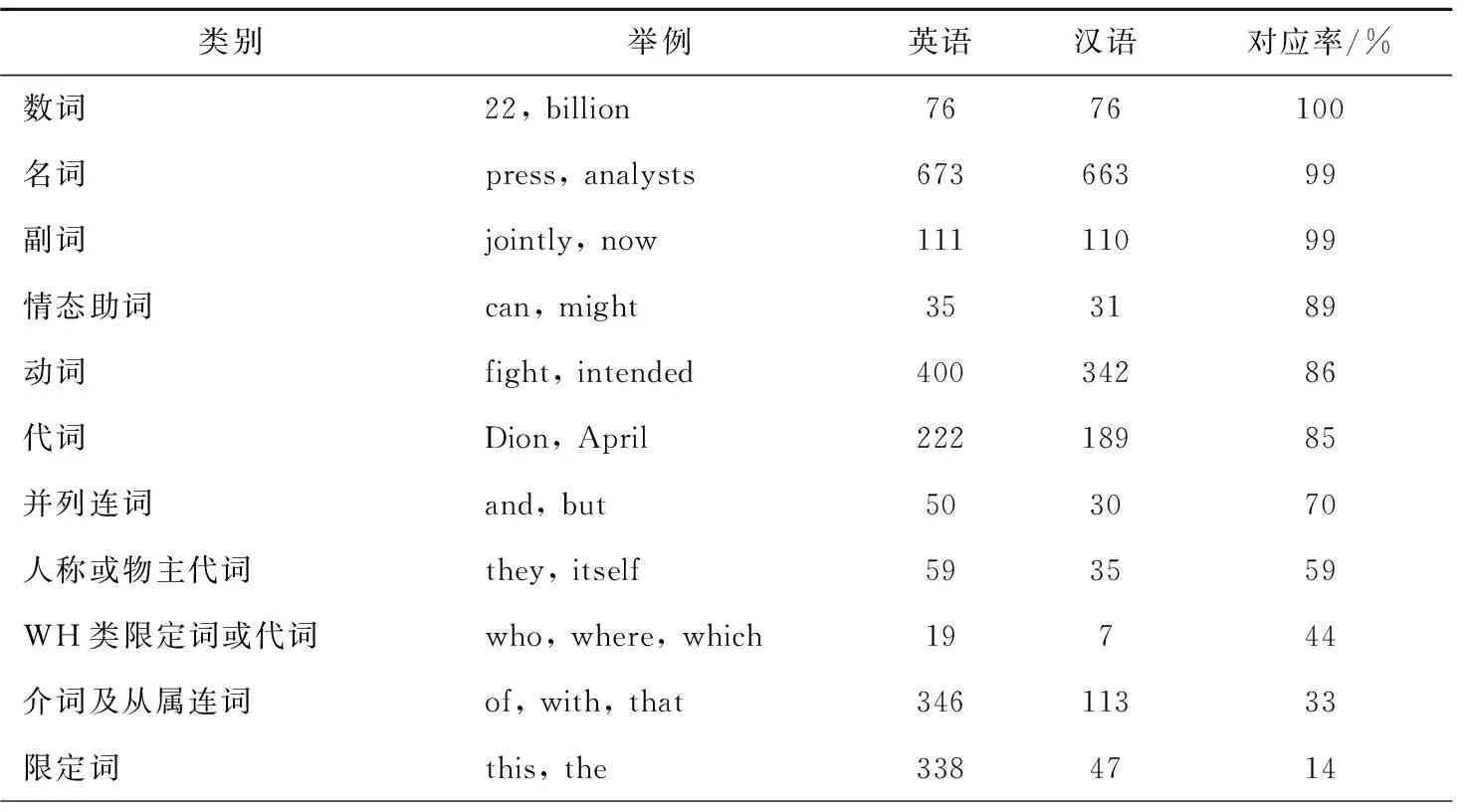
表4 不同词性的英文单词与汉语的对应情况
由表4可见,源文单词词性不同,作为翻译单位(基于无对应性标准)的几率也不相同。其中,实词比虚词更有可能在译文中找到对应。名词、主要动词、形容词和副词在译文中具有对应物的比例都在80%以上,但是冠词、代词、连词、助动词、叹词和小品词等虚词在译文中的对应比例通常较低。这些虚词通常与邻近的实词组合在一起成为翻译单位,如agree to/赞成和call on/呼吁。多达75%的二元组翻译单位是由一个实词和一个虚词组成的。
除此以外,翻译单位还与翻译的具体语言密切相关。某些语言之间的亲缘关系如此接近,以至于大多数时候源文的词,甚至是比词更小的音素或词素都可以作为翻译单位;另一种极端情况是,翻译涉及的两种语言差异如此之大,以至于译者只能在比词更大的层次上建立对应关系。毋庸置疑,英汉翻译的翻译单位肯定与英法翻译的翻译单位有着截然不同的分布特征。
译者的主观策略也一定程度上能够影响翻译单位的大小。以本语料库中nuclear weapon为例。一种情况下,译者省略了weapon的对应词武器,将其译为核子,此时整个短语便成为一个基于无对应性的翻译单位。同时,我们在语料库中还发现另外一种译法,即nuclear weapon/核武器。由于此例中的每个源文单词在译文中都能找到对应物,翻译单位不再是短语,而是单词。由此可见,译者在翻译时总是拥有一定的自由度,通过个性化的遣词造句方式来影响到翻译单位的大小。
五、结 论
本研究从翻译单位的主要定义出发,通过分析它们在内涵和外延方面的细微差别,最终总结出四种基本的翻译单位定义属性,即紧密性、独立性、无歧义性和无对应性。然后,应用基于语料库的定量研究方法分析了各类翻译单位属性之间的区别和联系。
研究发现,基于源文分析的翻译单位定义分别将紧密性、独立性和无歧义性作为判断的标准,而基于无对应性的翻译单位定义则将译文与源文之间的映射关系作为判断的依据。尽管存在种种差异,各翻译单位定义的共性在于它们都强调了同一类语言现象,即译者在翻译过程中并不总是在词的层次上进行翻译操作的。
从翻译单位的统计分布来看,基于源文分析的翻译单位比基于无对应性的翻译单位长度更大,分布更均匀。但是两者之间也是紧密联系的。一般来说,前者与后者呈现一种包含与被包含关系。虽然在翻译的分析过程中,译者出于某种考虑将源文某单位作为一个整体对待,但是在后续的转换过程中,译者仍然有可能将此整体单位拆分并逐个建立译文对应。这体现出译者在翻译时“大处着眼,小处着手”的思维过程。
总而言之,翻译单位是多种主客观因素共同作用的结果。它与源文的单语特征(如词性)、源语与目标语的关系(如语法和词汇的相似性)以及译者的主体性(如个性化的遣词造句)等因素密切相关。为了更好地描述翻译过程的全貌,本研究主张采取兼容并包的态度,将翻译单位定义为源文的某一语言单位,它由于具有紧密性、独立性、无歧义性或无对应性四种属性之一,因此被视作一个整体来翻译。
