基于多特征和规则约束的事件时序关系识别
2020-08-13方贤进
廖 涛,陈 红,方贤进
(安徽理工大学 计算机科学与工程学院 安徽 淮南 232001)
随着大数据和网络技术的发展,网络提供的数据已经成为人们最主要的信息来源。其中就包括了大量的新闻文本,而新闻一般是由各种主题的事件构成的。这些事件往往不是孤立存在的,它们一定是围绕着某个主题或相关主题以一定的顺序关联在一起。
定义1 事件(Event)[1]:指在某个特定的时间和环境下发生的、由若干角色参与、表现出若干动作特征和影响的一件事情。
事件作为感知世界的一种描述,它是在不同的新闻报道、故事文本以及其他重要文件中描述的,是信息组织的语义单元。而通过对新闻文本进行事件时序关系的识别,能得到文本中事件发生的先后关系,可以帮助人们更快更好的理解文本内容。识别文本中事件的事件关系是自然语言理解的重要一步,它可以直接应用于知识图谱、问答系统、事件时间轴生成、文档聚合等任务。以下是两个关于事件时序关系的例子:
E1:消防、武警和民警赶赴<e1>现场,疏散<e2>周边群众,扑救<e3>大火。
E2:案件的侦察<e4>及追捕<e5>其他嫌疑人的工作仍在继续之中。
在E1一句中,事件e1发生在e2之前,事件e2发生在e3之前,故时序关系为e1 beforee2,e2 beforee3。在E2一句中,事件e4和e5是同时发生的,故时序关系是e4 overlape5。
现有的事件时序关系识别大多是基于机器学习的分类方法,通过相关特征集合来构建分类器对事件对进行时序关系的预测。而这类方法往往只考虑了单个事件对之间的关系,忽略了各个事件对之间的隐含的时序逻辑关系,会造成整体事件时序关系的不一致。针对这一问题本文提出了一种基于多特征和规则约束的事件时序关系识别方法,首先考虑到中英文语言表达的差异以及常用特征的局限性,抽取了事件要素、特殊词、因果标志词和触发词相似度等特征来提高分类器的性能,尽可能地保证部分事件对的时序关系能够被正确识别。然后挖掘一篇文本中多个事件之间存在的与时序相关的语义规则,将其作为约束条件,来对识别结果进行优化。
1 相关工作
面向事件的时序关系识别方法主要包括基于规则的方法和基于机器学习的方法。
基于规则的方法通过人工制定一些规则集合或者模板来对时序关系进行推理和匹配。1984年Allen[2-3]就提出了一套完整的时序关系理论,把时间看作一个区间,利用区间代数来对时间关系进行规则推理,将时间关系分为13个类别。Li[4]通过对时间信息进行提取,并设计了一组规则将句子中的时间信息映射到其相应的时间关系。Gao[5]通过构建语义知识库与动词序列的共现网络,为新闻原子事件时间关系的识别建立语义时间关系规则库,提高了同句中原子事件的时序关系。
随着TimeML标注体系和TimeBank时间语料库的出现,机器学习的方法逐渐兴起。英文时序识别工作中,Mani[6]构建了一个最大熵分类器,来对事件对之间的时序关系进行识别。还有一些学者[7-8]提出一种完全自动化的两阶段机器学习体系结构,先学习单个事件描述的时间属性(时态、语法),再结合其他语言特征在第二阶段中用于对两个事件对之间的时间关系进行分类。Paramita[9]在TempEval-3的任务基础上,发现通过一些简单的特征对时间关系进行分类可以获得不错的效果。Kolya[10]使用监督机器学习的条件随机场方法,在TimeML框架下识别相邻句事件之间的关系。Lim[11]提出了一个深度神经网络,基于长短期记忆(long short term memory,LSTM)从朝鲜语自然语言句子中捕获时间语境,以提取时间表达与事件之间的关系。
中文时序关系识别工作中,郑新[12]借鉴英文时序关系的标注方法,利用机器学习的分类方法提出了中文时序关系语料的标注方法,由于中英文在语言上存在很大的差异,目前中文效果略差于英文。丁皑[13]提出了跨事件理论,利用CRF(conditional random field)自动识别信号词,实验证明一定程度上可解决TimeBank时序关系分布稀疏的问题。张义杰[14]、黄一龙[15]等将事件因果关系与时序关系建立了联合推理模型,实验证明了联合模型的有效性。赵红红[16]引入时间片段和主题片段这两种比事件触发词粒度粗的语义单元进行时间关系识别,实验结果表明引入时间片段后可有效减少不必要的事件时序关系的识别。张义杰[17]提出了一种基于自注意力机制的事件时序关系分类模型架构,它可以直接捕获句子中任意两个词之间的关系,实验表明该机制与非线性网络层结合,可以提高事件时序关系分类的性能。
通过相关工作研究发现基于规则的方法有着较高的限制性,准确率高却召回率偏低。而基于机器学习的方法主要就是将时序关系识别看成分类问题,考虑的只是单个的事件对,并没有考虑到整体事件之间的时序关系,会使最后的时序识别结果有所偏差。因此有学者将全局的思想运用到事件关系分类以及事件抽取等任务上,Do[18]等人构造了一条时间链,他们通过构造两个基础分类器E-E(事件对)和E-T(事件时间对),再利用全局模型来优化分类结果,实验效果得到了提升。
由此可见,全局思想可提升事件关系的分类效果。因此,本文将全局思想运用到事件时序关系识别任务中,提出了基于多特征和约束条件的事件时序关系识别方法。首先构造一个时序关系分类器,提取事件要素、特殊词、因果标志词和触发词相似度等特征来提高分类器的性能,尽可能地保证部分事件对的时序关系能够被正确分类。然后挖掘一篇文本中多个事件之间存在的与时序相关的语义规则,将其作为约束条件,对分类结果进行优化,以此来提升事件时序关系识别的效果。
2 事件时序关系识别
本文的工作是进行事件的时序关系识别,即找到一篇文本中任意事件对之间的时序关系。主要为预处理、特征提取、时序识别和识别结果优化,系统框架图如图1所示。

图1 事件时序关系识别系统框架图
预处理主要是对 CEC(Chinese emergency corpus)语料中已标注的新闻XML文本进行去标签工作,运用 LTP(language technology platform)工具(由哈工大社会计算与信息检索研究中心研发的语言技术平台)对去标签后的文本进行分词、词性标注以及依存句法分析。
定义2事件触发词(event denoter)[19]:又可以称作事件核心词或事件指示词,是文本中可以清晰的表达事件的词。
定义3事件时序关系识别(temporal relation recognize of event):时序关系分为事件与时间之间的关系、事件与事件之间的时序关系,本文研究的是文本中任意事件对之间的时序关系。即给定事件对<ei,ej>,能够得到事件对之间的时间关系r。其中事件对集合为CEE={e1,e2,…,en}事件时序关系集合R={before,after,overlap,unknown}。表示为:
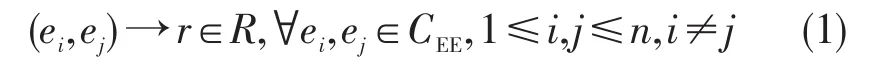
2.1 特征提取
针对英文的大部分特征大多不适用于中文时序识别任务,英文时序识别工作中可以根据动词的时态(表示事件发生在过去、现在和将来)作为特征,而中文表达中动词并没有表现出时态问题。这是中英文时序关系识别工作中的主要不同,使得中文时序识别时可选取的特征减少。而特征的选取对分类器的性能有着较大的影响,被选取的特征要能体现出中文语言表达的特点。中文表达在语法上的复杂性也为时序识别工作带来了困难。
常用于时序识别的特征多为词汇特征、句法特征和上下文特征,而这些特征只适用于同句或相邻近的句子中事件的特征。当事件对相隔较远时,这些特征便逐渐失去了作用。本文针对同一篇新闻文本中任意事件对的时序关系,并根据中文语言的表达特色,提出了多个跨句子的特征,以提高分类器的性能。如下所示:
(ⅰ)事件要素特征(Event_elements):即两个事件的对象要素、环境要素是否相同。如果某个事件对或者某几个事件对之间共享相同的事件要素,那么这几个事件发生的时间存在着一定的交叉关系或共时关系。
(ⅱ)特殊词(Special_words):事件触发词之前(后)是否出现否定词、不确定词。事件触发词之前如果出现否定词,那么这个事件就一定没有发生,也就不会和其他事件存在时间上的先后关系。同理,若事件之前出现不确定词则表示这个事件不一定发生,也就不一定和其他事件存在时间关系。例如:
E3:他们向邻近的双湖区(县级建制)了解<e9>情况当地几乎没有震感<e10>。
可以看出“几乎没有”为否定词和不确定词的组合,则e9和e10之间便没有时序关系存在。通过统计和分析,将特殊词出现的位置确定为事件触发词的前(后)3个词的位置。将是否出现特殊词作为特征融入时序关系分类器中。
(ⅲ)因果标志词(Causal_words):相邻两事件对之间是否出现因果标志词。因果关系也是特殊的时序关系,原因事件一定发生在结果事件之前,这就对事件的时序识别工作带来了帮助。事件对之间的因果关系分为显示因果关系和隐式因果关系。显示因果关系是指事件对之间存在因果标注词,而隐式因果关系是通过对上下文的语义来推断出原因事件和结果事件。本文只对显示因果关系进行了挖掘,即通过对因果标志词的挖掘来实现。由于缺乏中文事件因果关系语料库,本文采用了模式匹配方法识别文中显示因果关系,并将识别结果作为本文事件时序关系识别的一个特征。若事件对<ei,ej>间出现因果标志词,该特征的取值范围是1表示先因后果,0表示先果后因。
对语料进行统计分析后,人工归纳出一个因果标志词词表,再运用同义词词林进行因果标志词扩展。判断位于同句或相邻句中的事件之间是否存在标志词,再将其对应的时序关系作为特征。
(4)事件触发词相似度(Similarity):在CEC语料中,事件触发词被标注为大部分动词和少量的名词,用这些出发词来表示一个事件的发生。而部分事件触发词之间有着较高的相似度,为相近词或者同义词。对同篇文本中不同触发词进行语义相似度的计算,可以帮助判断它们是否为同一事件或相关事件。触发词的相似度通过同义词词林来进行计算,经过实验,取相似度阈值为0.89。若相似度值大于0.89,则认为它们是相似事件。
2.2 时序关系识别
实验过程中分类器使用的是最大熵分类器,是因为最大熵分类器对特征之间是否独立没有要求,如此便不用考虑特征之间会相互影响。计算机只能对量化后的特征向量进行处理,而从标注过的新闻语料中抽取的特征大多是以字符串来表现的。因此将词汇特征、句法特征、上下文特征以及2.1节中提取的多个特征转化成计算机可以处理的向量格式。转化向量的方法采用特征索引表的方式,将每个特征对应的字段在索引表中进行查找,相应字段赋值为1,其他字段赋值为0。
将语料按照3∶1的比例划分为训练集和测试集,用训练集对最大熵模型进行训练,再将测试集输入进行分类,最后输出事件时序关系识别结果。
2.3 事件时序关系识别结果优化
将2.2节中分类器所得到的时序关系识别结果作为基准,利用整数线性规划模型,将相关时序规则作为约束条件结合目标函数对事件对之间的时序关系识别结果进行优化,最后得到优化后的识别结果。整数线性规划是一种数学推理方法,其思想是寻找一组最优解,使得目标函数最大化并且满足一系列约束条件。
2.3.1 目标函数
本文以每篇新闻文本为单位,对文本中的时序关系进行优化。本文的目标函数是在文献[16]的基础上做了改进,将其定义为时序关系分类器预测的概率之和,表示为:

其中:CEE={e1,e2,…,en}表示同一篇文章中事件对的集合;r表示事件ei和ej的时序关系;R表示时序关系集合;x(eiej,r)是一个取值仅为0和1变量,当值为1时,ei和ej的时序关系为r;P(eiej,r)表示分类器预测ei与ej之间的关系为r的概率。
2.3.2 约束条件
(ⅰ)基本约束条件
基本约束条件即同篇文档中任意事件对之间的时序关系必须满足的基本条件,文献[18]所提出的分别为传递性、唯一性和自反性。传递性即时间序列关系的传递闭包性质,若事件对<ei,ej>和<ej,ek> ,有eibeforeej,ejbeforeek,则由传递的闭包性质可以推出eibeforeek。唯一性是指任意事件对之间必然只有一种时序关系,x(eiej,rk)的为一个二元变量,取值为0或1。x(eiej,rk)对应的时序关系时取1,其他情况取0。自反性是指已知<ei,ej>的关系,则<ej,ei>的关系也可以得知。若eibeforeej,那么ejafterei。传递性、唯一性和自反性分别为式(3)、(4)和(5)所示。

(ⅱ)扩展约束条件
由于优化是在分类器的基础上进行的,而基本约束条件只有在时序关系被正确分类的情况下才会发挥作用。对未被正确分类的事件关系对,则需要挖掘更多有效的约束条件加以修正。因此本文对CEC语料库中的新闻文本进行分析,扩展了三个约束条件,分别为连接词条件、事件类型条件和时间信息条件。
①连接词条件
在新闻文本中句子与句子、事件与事件之间存在一些连接词,这些连接词通常代表着特定的时序关系。例如:
E4:3月27日下午2时左右,有多位群众途经<e17>包茂高速安康西服务区时发现<e18>附近山体发生火灾<e19>,随后报警<e20>。
可以看出E4句中,连接词“时”代表着同时发生的含义,而它位于事件e17和e18中间,则可以推出e17和e18的时序关系是e17 overlape18;e19和e20中间存在连接词“随后”,则e19和e20的时序关系是e19 beforee20。
对语料库进行分析和统计,并用同义词词林进行扩展,为相邻事件对和构造连接词与对应时序关系的连接词表List_conj。对事件对之间存在的连接词与连接词表进行匹配,用连接词所对应的特定时序关系来对识别过程进行约束。表1中给出了部分连接词及其对应关系。表示为


表1 部分连接词表
②事件类型条件
CEC语料库中对事件触发词的属性类型进行了标注,如 emergency、movement、statement、operation、action、statechange和 perception 等,每种属性类型所表示的事件种类也不同。事件类型如表2。

表2 事件类型表
这些不同类型的事件之间往往存在着一定的时序规则。如地震发生后,一般会引发人员受伤、组织救援等一系列后续事件,即emergency→statechange→operation。通过对训练集进行统计,若某两种或几种类型的事件出现了三次以上,那么就将其存放到类型对列表中。如地震→救援,爆炸→死亡,中毒→就诊……。通过这些特定的事件类型对或事件类型链来对一些事件对之间的时序关系进行约束。表示为
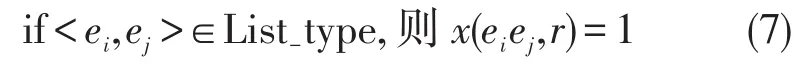
③时间信息条件
事件之间的时序关系识别的本质就是将事件进行时间上的对比,故时间信息对时序关系的识别是至关重要的。CEC语料库中对时间要素进行了标注,主要分为三种类型:relTime、timeInterval和absTime,即相对时间、时间区间和绝对时间。但是中文表达方式复杂多样,不便于直接进行时间关系的比较。因此,本文利用规则的方法对时间信息进行规范化表达,统一格式如下:

假设事件ei和ej的时间表达分别为Ti和Tj,若Ti>Tj,则eibeforeej;若Ti<Tj,则eiafterej。
将新增的约束条件与基础约束条件进行组合,再结合定义的最优目标函数来对时序关系识别的结果进行进一步的优化,以达到更好的识别效果。
3 实验与结果分析
本文的语料库采用CEC 2.0语料库,CEC是专门针对突发公共事件的中文语料库,从各大新闻网站收集了关于地震、交通事故、火灾、恐慌袭击以及食物中毒等五类国内外突发事件的中文新闻报道[20]。CEC 2.0在1.0版本上对文本进行了扩充,CEC语料库主要是对事件及其事件要素的标注,统计结果如表3所示。

表3 CEC各项统计结果
CEC语料库中仅包含了332篇关于突发事件的中文新闻报道,但是对事件的标注却很全面,所以本文采用CEC语料库中的语料来进行实验。本文将基于最大熵的事件时序关系识别作为基准系统,在此基础的识别结果上,通过多个事件之间的语义规则作为约束条件来对分类结果进行优化,以尽可能消除分类器带来的部分时序逻辑矛盾。将其转化为寻求最优解的问题,利用整数线性规划方法来求解。实验识别结果的评价标准采用P(准确率)、R(召回率)和F1 值来衡量。
本文将文献[18]所提出的基本约束条件与本文的扩展约束条件对实验结果的影响分别做了对比。不同约束条件对时序关系识别效果的影响如表4所示。由表4可以看出,扩展约束条件中“时间信息条件”对实验结果的作用最好。这是由于事件的时序关系识别本质就是时间先后的对比,并且事件的时间信息在文本中是最容易获取,也是存在的较多的一个要素。若两个事件都有其对应的时间信息并且可以进行比较,那么两个事件之间的事件关系就很可以被确定。

表4 不同约束条件对时序关系识别效果的影响/%
使用“连接词条件”和“事件类型条件”的约束时,提升的性能要低于使用“时间信息条件”提升的性能。通过对语料进行分析发现语料中存在的连接词的事件对并不多,即能产生作用的事件对数量不多。并且存在部分一词多义的连接词,如“而”,可以表示转折、递进、并列和顺承等关系,对识别的效果会有影响,故整体上的结果作用低于“时间信息条件”。“事件类型条件”虽然能够约束相对较多的事件对,但是特定时间对之间的时序关系并不是总是不变的,会产生一定数量错误样例,对识别结果有一定影响。
本文还将部分约束条件组合后进行实验,组合约束条件对实验效果的影响如表5所示。

表5 组合约束条件对时序关系识别效果的影响/%
结果由表5可知,“基准+基本约束条件+时间信息条件”的组合效果最好,是因为加入“时间信息条件”后,修正了部分事件对的正确率,再加上基本约束中传递约束的闭包性质,从而进一步保证了更多事件对之间的时序关系能够被正确识别。而“基准+基本约束条件+连接词条件”与“基准+基本约束条件+事件类型条件”这两个组合效果略低,是因为语料中存在的连接词不多,且“事件类型条件”虽然能够约束相对较多的事件对,但是特定事件对之间的时序关系并不是总是不变的,会产生一定数量错误样例。将“全部约束条件”进行组合后可以看出比仅仅加入“基本约束条件”的实验效果要好。因此新加入的三个约束条件对时序识别的优化是有效的,可以提升时序识别的效果。
目前在中文事件时序关系识别领域还未出现统一规范的评测体系,并且语料库的差异以及预处理方式的不同,即便是同一语料库中测试集与训练集的选择不同,都会对识别结果产生影响。因此无法客观公正地对各个方法比较优劣,只能在一定程度上反应某个方法的有效性。将已有的事件时序识别方法与本文进行比较,各方法实验结果如表6所示。
由表6可以看出,相比较于基础系统,F1值提高了4.49%,这表明通过相关约束条件来对时序关系识别进行修正和优化是有效果的。因为优化方法综合考虑了整篇文本中各事件对之间的时序逻辑规则,加入作为规则的约束条件后,将多个事件对联合起来进行处理,尽可能的修正时序分类错误的事件对,最终使得时序识别结果得到提升。然后,与已有的事件时序识别方法相比,本文所用的方法在P、查全率R和F1值都有所提升。虽然提升不是很大,但在一定程度上表明本文所用方法的有效性。并且根据表4、5可以看出加入的约束条件是有效的,使得时序关系的识别结果的优化效果得到了提升。

表6 各方法实验效果
4 小结
本文提出了基于多特征和规则约束的事件时序关系识别的方法。首先考虑到中英文语言表达的差异以及常用特征的局限性,挖掘了更多跨句子的篇章级别的中文语言特征提高来分类器的性能,尽可能地保证部分事件对的时序关系被正确识别。然后通过对CEC语料进行分析,将事件之间的时序语义规则作为约束条件,进行时序关系识别结果的优化。实验结果表明,将抽取出的跨句子的篇章级特征结合相关语义规则约束,对时序关系的识别效果有了不错的提升。
在下一步工作中可以提取更多篇章层次的特征运用于有监督机器学习的基础系统中,来提高跨句子的事件对之间的时序关系;并引入更多的约束规则来对结果进行优化,提高优化效果。另一方面,本文的实验是面向CEC语料库来实现的,只限于突发事件领域,且语料库相对较小。在下一步工作中要扩大语料数量和类型,搜集更多类型的文本语料。
