肿瘤电子病历数据挖掘技术的应用研究
2020-08-12童刚,姜宁,刘焕
童 刚,姜 宁,刘 焕
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
0 引 言
数据挖掘是指从大量的数据中通过算法搜索其中重要信息的过程。在医学中,医疗诊断的方法及选择模式尤其重要,将数据挖掘技术应用在此便于医生对疾病进行诊断,从而在医疗科研方面提供了科学依据[1]。随着医疗信息系统的发展,医院的数据库信息在医疗分类诊断上变得更加重要,如何有效利用这些信息进行分类挖掘是很多研究者的工作重心。冠心病是目前威胁人类身体健康的一项重大疾病,利用当今流行的数据挖掘技术提炼出冠心病积累的临床信息资料中的有用信息,并通过神经网络算法进行分类诊断,诊断的精确率已经高达90%[2]。除此之外,在其他相关疾病诊断中,此类技术的应用也达到了预期效果。Chen等[3]在提取规则方面,运用了决策树算法,然后采用CBR技术修改过往问题的解决流程,并应用到肿瘤疾病的新情况中进行诊断。Murate等[4]将神经网络算法及支持向量机算法应用在早期前列腺疾病的诊断中。Anand等[5]在疾病的诊断分类中,将病人的医学数据通过混合人工神经网络进行分析,在分类精度上有所提高。Huang Z等[6]提出了增强迭代次数的分类算法,对处理急性冠脉综合征患者心脏不良事件失衡问题有显著效果。肖勤[7]在建立乳腺X线分类模型上选用决策树算法,在分类诊断上取得了很好的效果。Feng等[8]在慢性胃炎中的分类诊断中应用了信息熵决策树算法。刘绿[9]将一些分类算法进行了性能对比,结果显示决策树的综合性能最佳。许腾[10]在甲状腺疾病的分析研究中,将纹理及超声图像进行了融合运用。于霄[11]创建了基于分类算法的医疗服务系统,并弥补了决策树本身存在的过拟合问题。
1 肿瘤电子病历的分类挖掘实验
电子病历中包含的医疗信息十分丰富。对其数据的有效处理和利用,是一项非常有意义的工作。通过数据预处理等[12]可部分消除数据中的噪声和不完整性,实现数据的规范化和有效压缩,从而使数据的再处理更加有效。最终将非结构化的电子病历文本数据转换成可直接挖掘利用的结构化数据。在电子病历中,病程记录是其重要组成部分,病程记录中包含了大量可供挖掘的患者就诊信息及过往病史信息,因此病程记录可以作为数据抽取的关键。首次病程记录的内容结构如图1所示。

图1 首次病程记录的内容结构
数据抽取又叫信息抽取,是数据预处理技术中的关键。基于目前的实体抽取模型的优劣性并结合研究数据的特点,文中采用了基于条件随机场的多特征融合的医疗实体识别方法[13-14]。具体识别流程如图2所示。
如图2所示,首先将原始语料库进行相应的中文分词和标注处理后,变为训练语料,再将训练语料分词进行同样的处理形成训练模型。其次将测试语料输入到训练模型中进行实体识别。最后将识别后形成的结果按照一定的方法规则进行评测,得到评测结果来检验整体模型的科学性。
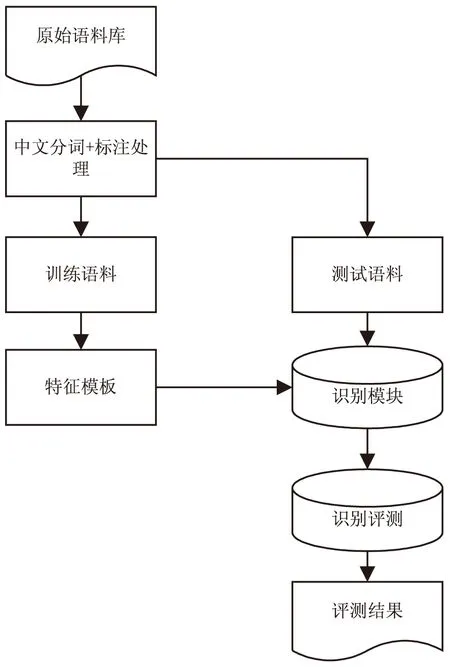
图2 基于条件随机场的实体识别方法框架
2 挖掘实验重点探究
中文分词被视为最基础的问题,中文分词常用的方法有三种:基于词典的分词、基于统计的分词、基于理解的分词。根据电子病历中医疗术语较多的特点,采用基于词典的分词算法[15],即将分字符串中的词,按照一定的标准和规则与词典中的词进行比对,若可以在词典中找到该字符串,则匹配成功。若找不到,则按照一定的算法策略继续匹配。基于词典的分词算法中逆向最大匹配法的分词精确率较高,缺点是分词速度较慢[16]。为解决这个问题,结合电子病历数据的表达特点提出了改进后的逆向最大匹配算法,在分词速度上有明显提高。
逆向最大匹配算法的思想如下:事先设置一个n值,然后从最后一个字开始向前截取n个字,先把这n个字与词典进行匹配,看能否找到匹配的词语,若匹配成功,即识别出一个词。若不能,则删除这n个字最左边的字,然后再把这n-1个字与词典继续匹配直到匹配成功,或者前n-1个字都没匹配成功,那就把第n个字当成一个独立的词,然后再向前移动分出来的词的长度,再截取n个字直到全部分好词为止。
改进后的算法思想:
(1)将分字符串中的词A与词典中的词B进行对比,如果词典B中没有A,则选择逆向最大匹配法进行分词。
(2)如果词典B中有A,将A前后位置的词分别与A进行组词,将新组成的分词与词典B进行比对:若有一个存在于词典B中,将A和新匹配的词一起作为一个分词,并在此处将字符串分为两段,最后再利用逆向最大匹配算法将这两段进行分词;若两个词都存在于词典B中,采用最大概率分词法进行确定;若在词典B中两个词均无法找到,那么以A为切点将字符串分成前后两段,再采用逆向最大匹配算法进行分词。
改进后的算法流程如图3所示。
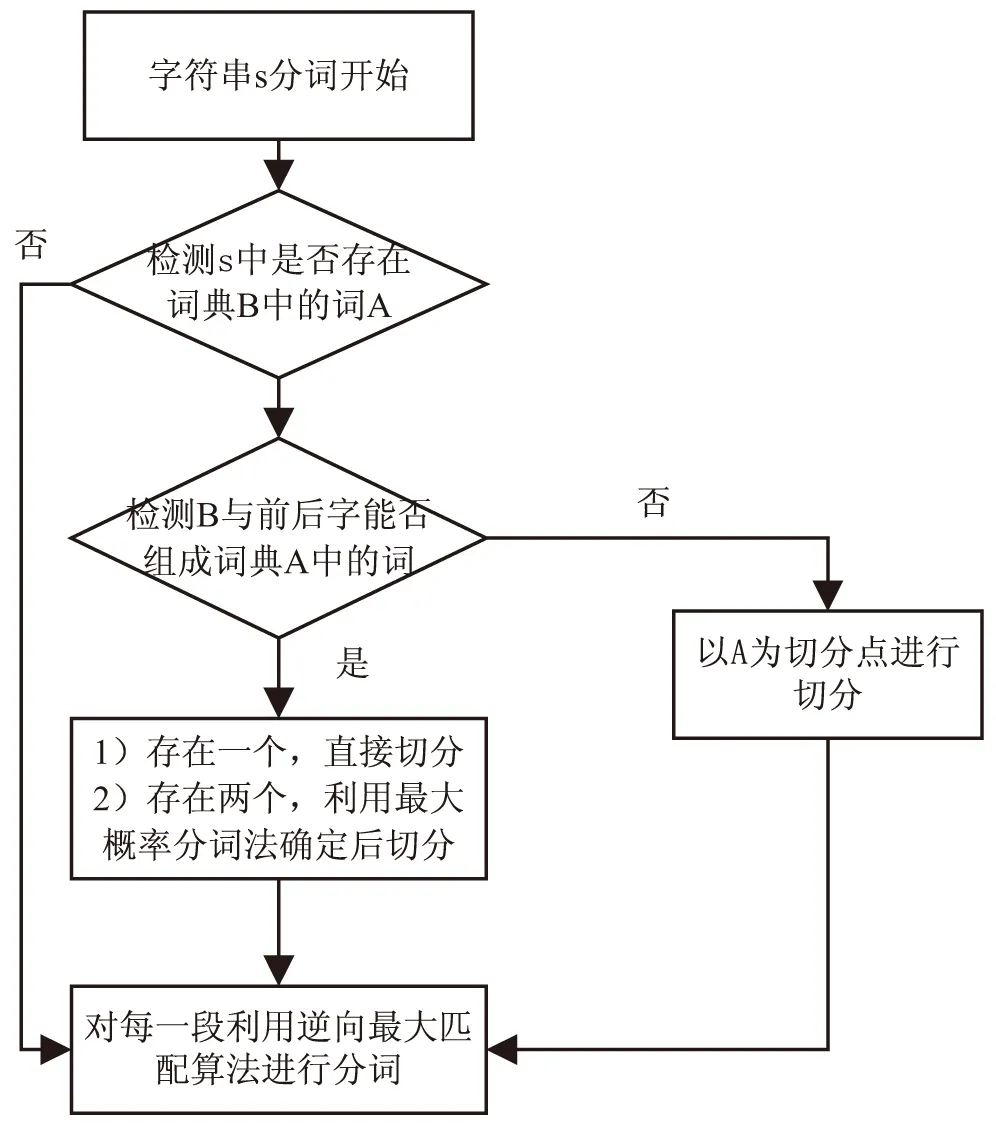
图3 改进后的逆向最大匹配算法流程
电子病历的语言表达中会有很多单用词如“和”“到”“若”“及”等,对这些单用词进行切分,不仅提高了分词效率和准确率,还不影响最终结果。因此将类似的这类单用词组建成一个新的词典,同时找出一些症状专有名词和疾病判断词也放入新词典中。最后判断待分字符串中是否有新词典中的词,若有则在此处分词,对切分后的每个词,再继续分词。利用传统的逆向最大匹配算法及改进后逆向最大匹配算法分别对电子病历部分内容进行分词的对比结果如表1所示。

表1 逆向最大匹配算法改进前后分词结果比对
利用数据抽取中常用的P值、R值、F值三个评价指标加上分词速度对实验结果进行对比评测[17],评测结果如表2所示。
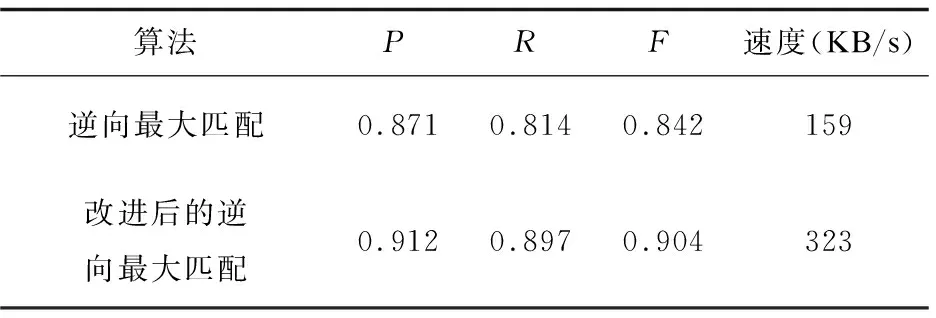
表2 逆向最大匹配算法改进前后性能比对
按照改进之后的逆向最大匹配分词法对电子病历分词后,经过标注处理及相应的特征选择后,得到初步的数据抽取结果,再对其进行数据清理、数据变换、数据归约等操作完成整个的数据预处理,图4为预处理之后的部分截图。
图4 预处理之后的肿瘤疾病数据集部分截图
3 分类算法的选取
挖掘实验过程中的关键问题在于挖掘算法的选取,针对医疗数据自身的独特性,筛选出合适的算法进而实现辅助诊断变得更加重要。然而不同的数据挖掘算法具有不同的特性[18],通过其特性对比发现,在分类选取方面,C4.5算法和BP神经网络效果最佳[19]。C4.5算法的基点是ID3算法,具备ID3算法的优点,在属性选择上用信息增益率进行选择,由于属性选择时会优先选择取值多的属性,C4.5算法有效解决了这类问题。不仅可以将连续属性离散化处理,还能够处理一些不完整数据。BP神经网络的主要特点是信号和误差按照相反方向进行传播。信号传播过程中,信号从输入层进入隐藏层,最后到达输出层,下一层的信号状态只由上一层影响。如果最后输出的信号并不是期望信号,则进入误差的反向传播过程。再根据误差进行调整权值和偏向,最后使得输出信号不断逼近期望输出。因此BP神经网络具有高度自学习和自适应的能力。下面对这两种算法进行分类挖掘实验。
3.1 C4.5分类实验
预处理后得到的数据集使用C4.5算法进行挖掘实验,采用十折交叉验证法测试算法的准确性[20]。
运行结果如图5所示。

图5 C4.5算法疾病分类效果
实验结果表明,C4.5算法分类结果性能:分类正确率约为86%,错误率约为14%,建模时间为129 s。
3.2 BP神经网络分类实验
BP神经网络算法具有实现任何复杂非线性映射的功能且可以进行复杂的数学运算[21]。它还具有一定的推广、概括、自学习等能力。在实际应用中,多数神经网络模型都采用BP神经网络的变化形式,在分类挖掘应用方面有较好的实验效果。运行结果如图6所示。

图6 BP神经网络算法疾病分类效果
由以上效果图可以看到BP神经网络算法的分类精确率约为88%,错误率约为12%,建模时间为398 s。
3.3 实验结果对比
C4.5与BP神经网络在肿瘤病历数据上的实验对比如表3所示。

表3 分类实验精度性能对比
通过以上分析可以得出结论,BP神经网络算法在分类的精确率上略高于C4.5算法,但是其运行时间效率要比C4.5算法慢3倍。综合来看,两种算法的精确率相差较小,但是C4.5算法的运算效率却远远超过BP神经网络算法,因此C4.5算法具有较高的综合性能,更适用于肿瘤电子病历的分类挖掘。
4 结束语
肿瘤电子病历挖掘过程中包含两个重要环节:中文分词及算法选取,针对中文分词,文中结合肿瘤电子病历的表达特点,采用了一种基于特定字词切分的方法对最大逆向匹配分词算法进行改进。实验结果表明,改进后的算法不仅提高了分词效率同时在分词精确度上也有明显提高。在算法选取阶段,对比了分类领域中性能较高的两种算法:C4.5和BP神经网络算法,经对比之后发现C4.5算法的综合性能要高于BP神经网络,因此选用C4.5算法作为肿瘤电子病历的分类挖掘算法。通过以上研究,可以实现利用数据挖掘技术辅助医生进行疾病诊断的目的,能够提高肿瘤疾病诊断的精确率及效率,进而提高肿瘤疾病的治愈率。
