C 语言程序的理解与编译优化
2020-08-07吴元斌
吴元斌
(重庆三峡学院计算机科学与工程学院,重庆404000)
0 引言
在多年的C 语言教学实践中发现,不少初学者对C 语言中运算求值存在一些模糊认识。很多人认为C语言的算术表达式求值顺序与数学中算术表达式的求值顺序相同,即先乘除、后加减。C 语言标准规定了运算符间的优先级及同级运算的结合性[1],也是乘除运算的优先级高于加减运算,因此对于表达式a+b-c*d,其运算顺序看起来是:*、+、-,但事实上并非如此。
一些习题包括一个变量多次自增(或自减)求和的表达式,如:(a++)+(a++)。C 语言并没有规定这两个自增运算与相加的求值顺序。通常的理解是:先求左边自增的值,再求另右边自增的值,最后将两个值相加,但实际上,有些编译器进行了优化:先进行两次自增,然后再将两个a 相加。还有其它依赖于编译器的问题,出现在习题或思考题甚至考试题中。这种情况是应该避免的,因此程序的运行结果是依赖于编译器的,在不同的编译器下运行结果可能不同。
为了清楚的理解C 语言教学中存在的一些编译相关的问题,使初学者编写与不依赖于编译器的C 语言程序,本文将列举一些典型的C 语言示例程序,给出了它们在集成开发环境Eclipse + MinGW GCC、LCCWin32 以及在Visual Studio 2019 下的运行结果对比。由于多数示例程序的运行结果存在一些差异,进一步展示、对照和分析了源程序在开源编译器MinGW GCC和LCC 下目标程序的反汇编程序,目标程序的反汇编程序是利用Eclipse+MinGW GCC、LCC-Win32 两种集成开发环境调试程序环境下得到的。本文还对编译器翻译算术表达式的基本思想进行说明,并分析编译器在表达式运算求值顺序实现中的具体差异。
1 示例源程序及其目标程序反汇编分析
1.1 算术表达式中运算的次序
算术表达式是用二元运算符+、-、*、/和圆括号连接起来的满足语法和语义规则的式子,C 语言规定了其中运算符的优先级和结合性,如圆括号的优先级最高,之后是乘除,加减最低,同一优先级的两个算术运算符的结合性是从左到右,但C 语言算术表达式中运算的次序不等同于数学中运算的次序。通过分析一些C 语言教材[2-4]中给出的容易引起模糊认识的示例,用下列典型程序段进行说明:
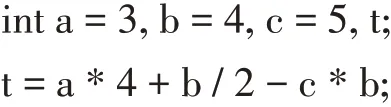
照数学运算规则,赋值语句右边的表达式运算顺序依次是:*、/、*、+、-,运算过程和结果可以表示为:a* 4 + b/ 2- c * b →12 + b/ 2- c * b →12 + 2 - c *b →12+2-20 →14-20 →-6。虽然C 语言程序中表达式的运行结果值也是-6,但运算次序与上述数学运算次序是不同的。编译程序是用下面的文法对算术表达式进行了严格的定义,文法指明了运算符的结合性和优先级,算术表达式的文法为[5-6]:

其中非终结符E 表示一组以+号或-号分隔的项所组成的表达式;T 表示由一组以*号或/号分隔的因子所组成的项,F 表示因子,它是用括号括起来的表达式或标识符id。变量和常数被词法分析程序归类为标识符id。利用该文法生成上面表达式的语法树是唯一的,如图1 所示。

图1 生成示例表达式的语法树
其中,图中的id 对应的变量或常量从左到右依次是a、4、b、2、c、b。通过语法制导翻译(类似于语法树自下而上或递归下降分析),上述表达式被翻译成为每条指令最多一个运算符的指令序列[5]。将上述表达式计算的同一示例程序在两种集成环境中调试视图截图(源程序及反汇编)如图2 所示,左图是Eclipse+Min-GW GCC,右图LCC-Win32,两个子图的上面部分都是源程序,下面都是目标程序的反汇编程序。左、右两图放在一起是便于对比分析(下面示例都采用这种方式)。
其中左图中最后用红色边框包括的列为手工添加的代码说明,右图的反汇编用圆括号包含了变量名。两种编译器采用的指令不完全相同,左图中除法比右图的实现复杂,详细分析可见文献[7]。可以看出,两个编译器处理表达式的运算次序相同的,它们的次序都是:*、/、+、*、-,显然与数学运算规则不同。这个运算次序也就是图1 中的语法树按运算符从下到上、从左到右得到的运算次序。
实际上,C 语言算术表达式求值中在处理当前运算符时,要与其右边相邻的运算符进行比较,若当前运算符高于其相邻右边的运算符,或者它们的优先级相同,且结合性是从左到右,则完成当前运算,否则先处理其右边相邻的运算,其右边相邻的运算也要处理方法也是相同的,如此等等,直到所有运算完成。编译器自下而上的翻译法在表达式最后添加了一个运算符$(优先级最低)运算符[5-6],它就没有右边相邻的运算符了。
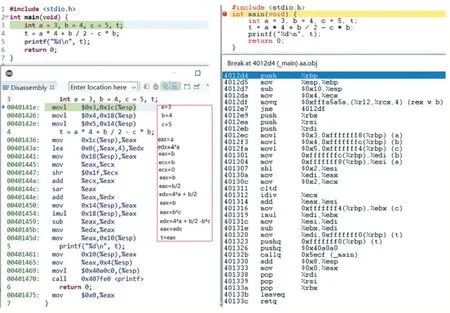
图2 两种编译器表达式运算次序相同
1.2 表达式运算次序的副作用
很多时候无论是按数学运算次序还是按编译程序指定的次序运算,算术表达式的值是相同的,看起来不用区分C 语言表达式的运算次序,但并不总是这样。当表达式中存在项与项之间的值存在依赖关系时,结果就可能不同,如将上面的程序段修改为:

所作的修改只是将上例的表达式最后一项改为(b=2),由于第2 项中的b 与最后一项的b 存在依赖关系,编译器MinGW GCC 与LCC 对表达式的优化处理不同,程序在两种环境下的运行结果不同,分别为4和3,在Visual Studio 2019 下运行的结果也为3。
该程序在MinGW GCC 与LCC 编译反汇编对比如图3 所示,分析发现LCC 编译器中b 赋值为2 的指令被提前,MinGW GCC 则没有,两条指令分别用红色方框标出,表达式中其它的运算次序还是与上例相同。可见,两种编译器只是对“(b=2)”的处理不同,在LCC环境下表达式中所有b 的值都是2,而在MinGW GCC环境下只是最后的b 的值为2,因此导致了程序的运行结果不同,所以该程序的运行结果完全依赖于编译环境。

图3 两种编译器对运算次序优化存在差异
1.3 函数实参的求值顺序处理
C 语言也没有指定函数各参数的求值顺序[1]。在函数调用时,有的编译器是从左到右,有的则是从右到左。参考文献[3]有一个类似于下面的程序段:
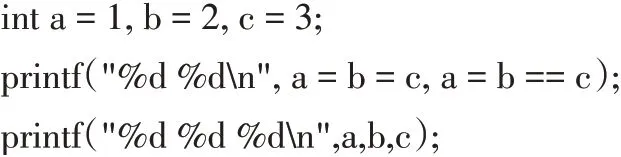
通过在MinGW GCC 与LCC 下运行程序后发现,第1 个输出语句的运行结果不同,分别为“3 3”和“3 0”,而第1 个输出语句在Visual Studio 2019 下运行的结果为“3 3”。三种环境下第2 个输出语句的结果为“3 3 3”,即变量a、b、c 的值最后都是3,这说明在三种环境下编译器的求值顺序都是从右到左。由于第1 个输出存在差异,为了找出问题的原因,将该程序在Min-GW GCC 与LCC 编译反汇编进行对比,如图4 所示。
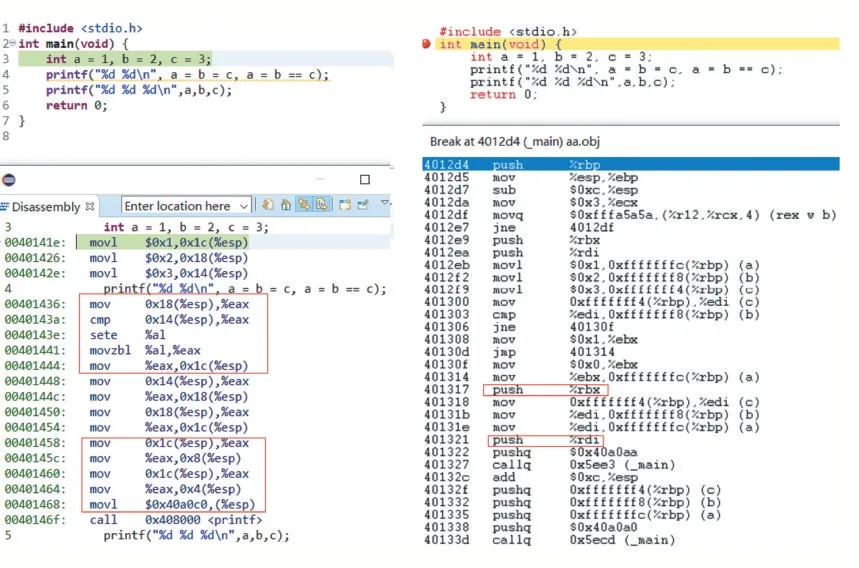
图4 两种编译器对实参求值的处理不同
分析图4 发现,两种编译器都是先计算右边的参数(左图中第1 个加框的部分为第1 个参数的求值,右图中为第1 个加框指令的前6 条指令),然后计算左边的参数。但是它们处理值的方式不同,对MinGW GCC环境中,printf 输出的是变量a 的最终值(左图第2 个加框部分)。但在LCC 环境中是将两个实参的值分别保存在寄存器rbx、rdi 中,计算一个保存一个(右图中两个加框指令),rbx 的值为0,rdi 的值为3。可见尽管都是从右到左计算函数实参,但形参的值却不同,程序的执行结果也依赖于编译程序,只有仔细分析它们的反汇编程序,才能搞清楚其中的原因。
1.4 自增自减运算的副作用
函数调用、嵌套赋值语句、自增与自减运算符都有可能产生“副作用”—在对表达式求值的同时,修改了某些变量的值[1]。一些C 语言教材的练习中常常包含类似于下面的程序段:
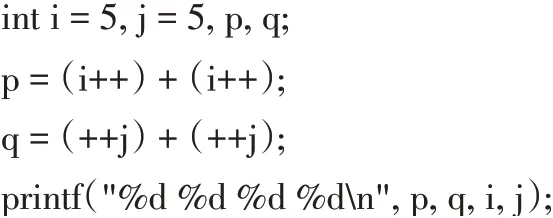
上述程序在MinGW GCC 和LCC 下下的运行结果分别为“11 14 7 7”和“11 13 7 7”,在Visual Studio 2019下的运行结果为“11 14 7 7”。可见输出结果存在差异,为了找出问题的原因,将该程序在MinGW GCC 与LCC编译反汇编进行对比,如图5 所示。

图5 两种编译器对自增运算处理不同
在图5 中,分别对两种环境下相关指令功能进行了说明(红色框线中)。可以看出,两种环境下对后缀的自增运算处理相同,即先累加,再自增,再累加,再自增,累加的结果都是11。但对于前缀的自增运算处理则不同,在MinGW GCC 下前缀的自增运算被优化(在加法运算前进行),而在LCC 下前缀的自增运算则不同,并没有优化,所以前缀的自增运算相加的结果不同,分别为14 和13。因此一个变量多次自增(或自减)求和表达式的值也依赖于编译器。
2 结语
本文讨论了C 语言教学中一些容易引起初学者产生模糊认识的典型问题,通过不同编译环境对目标程序的反汇编对照与分析,能够清楚地看到这些程序的运行结果依赖于编译器,不同编译器可能产生不同的结果。这样的问题还很多,虽然初学者也不一定能够理解这些分析及编译原理的具体细节,但教学中应该让他们知道编写依赖于编译器的程序是不好的习惯。在任何一种编程语言中,如果代码的执行结果与求值顺序有关,则都是不好的程序设计风格。很自然,有必要了解哪些问题需要避免,但是,如果不知道这些问题在各种机器上是如何解决的,就最好不要尝试运用某种特殊的实现方式[1]。因此,C 语言教学一个很重要的工作是让学生学会正确的编程方法,培养良好的编程习惯[2],避免编写执行结果依赖于编译器的C 语言程序。
