基于云计算的海量大数据智能清洗系统设计
2020-08-04黄正鹏王力张明富
黄正鹏 王力 张明富
摘 要: 大数据资源是企业拥有的最重要的战略资源之一,也是管理层制定远景规划,提高市场竞争力的主要方式和途径,但大数据中会存在错误、冗余和不完整的数据,降低了大数据的总体质量。为此设计一种基于云计算的海量大数据智能清洗系统,改善现有大数据清洗系统在脏数据处理性能上的不足。分析了基于云计算的大数据智能清洗系统的总体框架和硬件构成,数据清洗系统的硬件部分由数据预处理模块、数据云聚类模块、数据识别模块和实体划分模块等部分组成;给出了智能大数据清洗系统的总体软件工作流程,并重点分析大数据空间聚类、相似度计算等关键的数据处理技术。验证结果表明,提出的基于云计算的海量大数据智能清洗系统设计的总体功能性较为完善,在系统性能测试方面也能够保持95%以上的数据查准率和召回率。
关键词: 云计算; 海量大数据; 智能清洗系统; 云聚类; 查准率; 召回率
中图分类号: TN02?34 文献标识码: A 文章编号: 1004?373X(2020)03?0116?05
Design of intelligent cleaning system for massive data based on cloud computing
HUANG Zhengpeng, WANG Li, ZHANG Mingfu
(School of Information Engineering, Guizhou University of Engineering Science, Bijie 551700, China)
Abstract: Big data resource is one of the most important strategic resources owned by the enterprise. It is also the main way and approach for the management to make long?term plans and improve market competitiveness of the enterprise. However, there are errors, redundancies and incomplete data in big data, which reduces the overall quality of big data. For this reason, an intelligent cleaning system for massive data based on cloud computing is designed to improve the shortcomings of the dirty data processing performance in the existing big data cleaning system. The overall framework and hardware structure of the intelligent cleaning system for big data based on cloud computing are analyzed. The hardware of the system consists of data preprocessing module, data cloud clustering module, data identification module and entity partition module. The overall software workflow of the intelligent cleaning system for big data is provided, and the key data processing technologies like big data clustering and similarity calculation are emphatically analyzed. The verification results show that the proposed intelligent cleaning system for massive data based on cloud computing has perfect overall functions and the precision and recall rate of data can be kept above 95% in the system performance testing.
Keywords: cloud computing; massive data; intelligent cleaning system; cloud clustering; precision; recall rate
0 引 言
当前大数据已经成为企业重要的战略资源和决胜未来的关键因素,大数据具有海量性的特征,但只有真实、完整的大数据才有价值[1?2]。大数据体系内包含大量冗余、错误的干扰性脏数据,降低了数据整体质量的同时还会干扰管理者的决策。由此可见,数据质量将会对企业现有数据的分析、整合及应用产生十分重要的影响,在大数据的使用之前必须对全部数据进行系统清洗和处理,以提高大数据的总体质量。随着数据挖掘技术的发展[3?5],人们对于大数据的质量要求越來越高,但数据库中不完整的数据和脏数据会误导决策,从使用成本和效率的角度来考虑,如果系统数据库中存在大量的脏数据,会拖慢系统的响应时间,增加数据处理的成本费用[6?7]。影响数据质量的原因主要包括两点:在数据录入系统时即存在缺陷或完整程度不高;随着数据库系统软硬件的升级,原有的过期数据也会转变成为干扰数据,需要及时地清除掉释放系统的内存空间,以保证系统的整体功能性不被破坏。目前主要的脏数据清洗系统设计包括单机式清洗方案[8?9]和集中式处理方案[10?11]两种。其中,单机式大数据清洗系统是一种孤立式的数据清理方案,即直接在单机上运行相关的大数据清理程序,对现有的数据库的冗余、错误进行处理,清理完成后形成数据库的状态报告。这种数据清理系统运行较为灵活,但数据处理能力有限。集中式大数据清理方案是以局域网为单位,整合局域网范围内的数据处理资源,与单机式系统相比,集中数据清洗方案的数据处理能力能够得到本质上的提升,但面对海量大数据处理任务时仍旧无能为力。针对现有数据清洗系统存在的数据处理能力弱,清洗效率低下的不足,本文设计一种基于云计算的海量数据清洗系统,利用云计算强大的云端空间并行计算能力[12?13],提高大数据清洗系统的数据处理能力、效率和准确性,同时也能够避免在大数据清洗过程中过滤掉部分关键有用数据。
1 大数据智能清洗系统总体框架设计
随着信息产业和网络技术的发展,企业的经营决策越来越依赖于大数据,规模较大的企业拥有企业级数据库,并有专业人员进行数据管理,而规模较小的企业可以将本企业的数据存储于云端,由云端专业的数据存储企业或部门进行数据维护和综合管理。目前,对企业运营大数据的分析,已经成为企业经营决策的主要依据,大数据的质量从某种程度上说将决定企业的经营业绩。在数据库的建立和维护中,各种异构的数据源将被不断地加载到本地数据库中,因此数据库的规模将会不断增大。在数据的存储和维护中,数据的错误录入、关键数据遗失、个别数据过期及恶意数据攻击等问题都会频繁发生。因此,在数据导入和使用前必须对全部数据进行清洗和维护,去除干扰的冗余错误数据,提高海量大数据的价值。
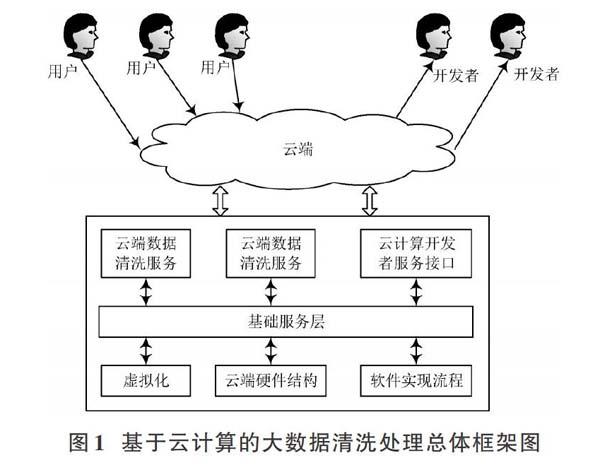
大数据的清洗过程具体包括海量冗余数据的识别与剔除、错误数据的纠正、不完整数据的补充、不规范数据的格式转换等。处理海量大数据最有效的方式是云计算,因为云是一种多配置、扩展性极强的虚拟化资源处理系统,能够提供硬件构建、软件开发等云端服务,并且具有强大的并行数据计算和处理能力。云计算以互联网为中心,将虚拟资源进行了深度整合,并按照用户的需求提供多样化的服务。云计算的大数据处理方式是一种广义上的并行计算方式,能够同时处理多用户的海量数据资源。云计算平台基于云资源而建立,云平台的网络兼容性十分强大,针对用户的不同需求提供多样化的定制服务。鉴于海量大数据智能化清洗处理的需要,本文设计一种基于云计算平台的数据清洗系统,用户通过云端向云平台的开发者提出大数据处理要求,云端针对用户的数据清洗要求整合虚拟的硬件、软件资源,为用户提供个性化的服务,基于云计算平台的海量大数据清理系统总体框架设计如图1所示。
云平台的基础服务层是总体框架的核心部分,能够将云端虚拟化的硬件和软件资源整合,为用户提供全方位、便捷的数据清洗服务。本文分别从硬件结构设计和软件流程设计两个方面,系统阐述了基于云计算的海量大数据智能清洗系统。
2 基于云计算的大数据智能清洗系统硬件设计
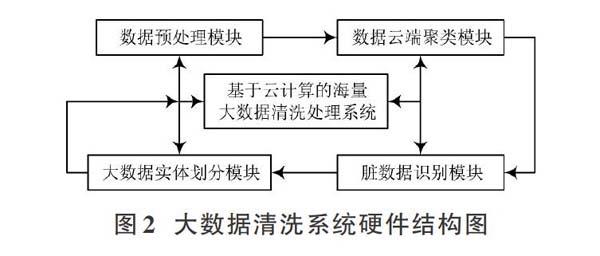
大数据清洗的主要目的是清除冗余、错误的干扰数据,提高大数据的总体质量,以便更好地为数据的使用者服务。数据清洗系统硬件模块的设计围绕着大数据的云端聚类、特征提取、分体识别等要求执行,而数据清洗过程中最重要的环节是数据重复记录或相似记录检测与消除。冗余的错误数据指数据库中表达方式雷同或拼写错误的数据,这些数据存在于数据库系统中会干扰正常数据的分类和识别。为消除海量大数据中的冗余错误数据,本文在硬件模块设计中增加了大数据预处理模块,对进入云端的海量大数据采用字符区位定码策略,降低字符或符号的错误率,降低数据的匹配难度并提高对脏数据的检测率。基于云计算的海量大数据清洗系统的硬件模块构成,如图2所示。
未经过处理的海量大数据进入清洗系统后,首先到达数据预处理模块,数据预处理模块的最主要功能是去除冗余干扰,并对整个数据进行降维处理,降低后续数据聚类分析的难度。造成数据库中出现冗余的主要原因是不同输入源头的同一数据的格式存在差异,而且在数据的传递、存储和交互中也容易发生错误。预处理模块将输入清洗系统的每一条数据都进行了模式的匹配与变换,大数据的格式变换后有助于后续模块的聚类分析及特种识别,也能够减少后续数据處理的代价。云计算数据处理中常用多条属性值来表示一个实体,基于这种特性云端聚类模块采用索引列表的方式,将具有同一字段特征的数据进行初步归类,依靠同属性索引归类的方式将相同字段的冗余数据汇聚到同一个索引下,进而删除字段雷同但不完整或不合理的干扰数据,以达到大数据智能清洗的目的。
在实体属性识别中,不同实体描述的重要性程度不同,贡献率也不同。为此,基于云计算的海量大数据清洗系统脏数据识别模块为每一类输入系统的数据都匹配了不同的权值。权值的比重由相关大数据专家按照领域知识而设定,本文模块还可以按照索引的类别进行模块类别的划分,得到实体模块的相似度,再通过数据分类阈值大小判断冗余删除结果是否输出。采用大数据实体模块划分的方法进行错误数据和冗余数据的删除降低了数据处理的成本,也有效地缩小了函数阈值的边界,适用于海量大数据的清洗处理要求。
3 系统总体实现流程设计与关键技术研究
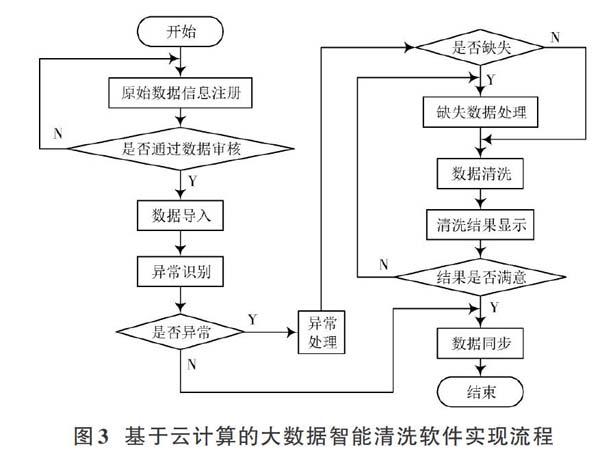
根据海量大数据智能清洗系统硬件结构规划的总体性要求,设计了基于云计算技术的系统总体软件工作流程,如图3所示。
当智能清洗系统开始运行后,将原始的大数据信息输入预处理模块,数据的原始信息要经过系统的初步审核,审核成功后将大数据导入系统。数据导入后系统要基于云计算平台对原始大数据进行聚类分析,识别出异常的风险数据。风险数据的识别与处理要依据大数据聚类的相似度计算,通常将风险数据或异常数据视为缺失数据处理。设大数据类[A]和[B]分别为两个不同的数据实体,那么[A]和[B]之间的实体相似度函数[GA,B]可以表示为:
大数据导入智能清洗系统后,按照数据实体之间的相似度先判断实体之间的相似程度,进行初步的数据聚类。之后再分析实体内部冗余数据的关键字段特征,对于缺失的数据而言可以直接进行数据同步,而对于不完整的大数据而言要按照一定标准将不完整的部分补充完整,经初步聚类后的MAP输出属性索引与索引值见表1。
大数据的云端聚类分析按照数据实体之间的相似度与索引值,对进入智能清洗系统的大数据进行类别划分。对于数据聚类分析模块而言,每输入一组数据将要确定一个数据相似性的分类标准。数据聚类分析需要经过多次反复分组和聚类才能实现,大数据聚类分析方法是基于一种数据收敛变化的思想,利用多次大数据聚类实现在全局范围内寻优,对于每次不符合数据聚类的冗余数据、残缺数据和错误数据予以清洗和消除。基于云计算的数据清洗系统在数据聚类和实体模块划分中,将每一个输入系统的数据集都作为一个初始的类别,然后按照数据集的阈值范围与特性,对数据集进行多次拆分与合并,最后将特性相近的数据集归于一类,在按照聚类索引值分类的过程中,逐步清洗掉不完整和冗余的数据,以达到缩小大数据规模的目的。云计算能够利用其强大的空间并行计算能力,在整个输入大数据范围内寻优,数据聚类与实体模块划分的主要步骤如下:
Step1:确定大数据聚类分析的准则,并按照实体间的相似度初步分组。
Step2:确定数据类别的重心与索引值,并确定其他分组数据与重心的距离。
Step3:清洗掉离重心距离过远的干扰数据和冗余数据并重新分组计算。
Step4:重复上述步骤,直到得到与实体重心数据特征一致的数据集合,即通过多次性能收敛在全局范围内得到最优解。
对于非缺陷数据而言,直接将这些安全数据存储于系统数据库,并进行数据的更新与同步;而对于冗余、有缺陷和不完整的数据而言,与在数据导入时识别出的数据一并清洗处理,并将清洗的结果显示出来。系统管理员可以对清洗结果的满意程度做出判断,如果对于清洗的结果不满意,系统可以返回到缺失数据处理步骤重新处理。如果大数据清洗程序能够达到满意的效果,直接同步清洗结果并输出打印报告,方便后续的查询及使用操作。
4 结果验证
4.1 系统功能测试
基于云计算的海量大数据系统功能实验,主要考虑到对系统整体功能的验证,系统各模块接口功能列表和实验环境设置如表2所示。
大数据清洗系统的功能测试能够保证系统的可靠运行,模块的功能测试环节与系统的软件工作流程趋于一致,包括用户登录、信息输入、数据导入、数据处理等环节,基于云计算的海量大数据清洗系统的功能测试结果,如表3所示。对数据清洗系统每个模块的基础性功能都进行验证,全部测试项目都通过了验证,表明系统的功能性较为稳定。
4.2 系统性能测试
系统性能方面的测试主要检测基于云计算的大数据智能清洗系统,在清洗脏数据方面的能力,取一个实验用的样本数据集包括数据29 812条,人为添加重复性干扰脏数据188条,每2 500条数据检测一次检测系统的查准率[ξ]和召回率[ζ]:
式中:[Nc]为准确识别并清洗的数据条目;[Na]为脏数据的总条目;[Ntal]为总数据数量。分别验证传统集中式大数据清洗系统与本文基于云计算的数据处理系统的数据清洗查准确和召回率,30 000条数据的性能测试结果如图4,图5所示。
从传统大数据清洗系统与基于云计算的大数据清洗系统查准率对比结果可知,随着查询条件的增加,传统集中式大数据清洗系统的查准率呈现出快速下降的趋势,当查询30 000条数据记录时,查准率已经跌至90.36%;而文中基于云计算的大数据清洗系统的脏数据查准率始终保持在98%以上。在大数据清洗召回率的对比方面,当查询30 000条数据记录时,传统数据清洗系统的召回率已经低于90%,且在整个大数据的查询清洗过程中召回率出现了波动的情况;而文中提出基于云计算的大数据清洗系统的召回率,尽管也出现了下降的情况,但总体数据清洗处理召回率仍可以保持在95%以上,具有传统清洗系统所不可比拟的优势。
5 结 论
大数据在企业决策与管理层战略制定中发挥着越来越重要的作用,但数据库中冗余、错误和不完整的数据会对大数据的真实性和完整性造成不利的影响。云计算是处理大数据问题最有效的方法之一,本文基于云计算设计了一种海量大数据智能清洗系统,能够改善数据清洗的效率和效果。大数据在未来的市场竞争中將会发挥越来越重要的作用,而保证大数据的真实、完整和有效,并不断提高企业大数据的质量,是发挥出大数据资源优势的必要条件之一。
参考文献
[1] 陶盈春,张红丽,徐健.异常值探测在大数据分析中的应用研究[J].情报科学,2018,36(3):75?80.
[2] 柴谦益,郑文斌,潘捷凯,等.基于大数据分析的智能配电网状态监测与故障处理方法研究[J].现代电子技术,2018,41(4):105?108.
[3] 颜磊,祁冰.基于Android平台的移动学习系统大数据挖掘技术研究[J].现代电子技术,2017,40(19):142?144.
[4] 王磊,陈青,高洪雨,等.基于大数据挖掘技术的智能变电站故障追踪架构[J].电力系统自动化,2018(3):84?91.
[5] 刘炳含,付忠广,王永智,等.基于并行计算的大数据挖掘技术及其在电站锅炉性能优化中的应用[J].动力工程学报,2018,38(6):431?439.
[6] 朱会娟,蒋同海,周喜,等.基于动态可配置规则的数据清洗方法[J].计算机应用,2017,37(4):1014?1020.
[7] 潘玮,牟冬梅,李茵,等.关键词共现方法识别领域研究热点过程中的数据清洗方法[J].图书情报工作,2017,61(7):111?117.
[8] 马平全,宋凯,纪建伟.基于N?Gram算法的数据清洗技术[J].沈阳工业大学学报,2017,39(1):67?72.
[9] 王冲,邹潇.基于Spark框架的电力大数据清洗模型[J].电测与仪表,2017,54(14):33?38.
[10] 林峻,严英杰,盛戈皞,等.考虑时间序列关联的变压器在线监测数据清洗[J].电网技术,2017(11):3733?3740.
[11] 曲朝阳,张艺竞,王永文,等.基于spark框架的能源互联网电力能源大数据清洗模型[J].电测与仪表,2018,55(2):39?44.
[12] 周东清,彭世玉,程春田,等.梯级水电站群长期优化调度云计算随机动态规划算法[J].中国电机工程学报,2017,37(12):79?90.
[13] 闫明,王秀芬,李强,等.基于数据对称打包的云计算并行核心失败校验缓解[J].微电子学与计算机,2017(5):73?78.
