基于贝叶斯网络对全国PM2.5浓度影响因素分析
2020-07-26李超群
李超群


摘 要:为能更有针对性的控制PM2.5浓度,对2000-2017年间全国31個省市PM2.5浓度数值和由专家先验得出的影响PM2.5的六种人为因素分别建立了基于BIC评分函数、K2评分函数进行结构学习的两种贝叶斯网络模型、支持向量机模型、K-近邻模型进行分析。利用5-折交叉验证对四种模型进行评估。发现在样本量不太大的情况下,贝叶斯网络表现出更好地稳健性与优越性,而基于K2评分函数进行结构学习的贝叶斯网络模型具有更好地分类性能。为政府相关部门对我国PM2.5浓度更加有效的控制,以及采取更加具有针对性的治理方案提供了思路与方案。
关键词:PM2.5;贝叶斯网络;结构学习;参数学习;模型评估
中图分类号:TP18 文献标志码:A 文章编号:2095-2945(2020)22-0001-06
Abstract: For controlling the concentration of the PM2.5, with the data of PM2.5 concentration values of 31 provinces in China during theyears 2000 to 2017, and six influencing factors of PM2.5 concentration obtained by experts' prior experience. Two Bayesian Network Models based on BIC score function and K2 score function respectively, Support Vector Machine, K-Nearest Neighbor Model are analyzed. Using the method of 5-fold cross validation, the four models are trained and tested. In conclusion, in the case of small sample size, the Bayesian Network shows better robustness and superiority, while the Bayesian Network Model based on K2 score function for structural learning has better performance. It is meaningful to provide a new idea and scheme for the control of PM2.5 concentration in China.
Keywords: PM2.5; bayesian network; structure learning; parameter learning; assessment of models
引言
近几年,随着我国不断发展,城市化的程度不断提高,在有了越来越多的机遇同时,也面临着环境的巨大挑战。我国PM2.5数值频繁“爆表”,长期的雾霾天不仅严重影响了我国正常的生产进程,还影响了人们正常的生活。因此,对PM2.5的影响因素进行分析,就显得十分迫切,但是PM2.5浓度的变化是一个不确定的、复杂的过程,这也增加了建模过程以及分析的难度。近年来,许多专家学者致力于对PM2.5影响因素进行分析。国内学者解蕾等[1]使用二元定距变量的相关分析,分析了两两变量之间的关联程度,最终得出结论PM2.5与SO2,PM2.5与CO,PM2.5与PM10之间都存在着较强的相关性,之后建立PM2.5与PM10的线性回归方程,进一步分析二者之间的线性关系。学者卢德彬等[2]采用Theil-Sen median趋势分析,Mann-Kendall、R/S和相关分析方法,分析了PM2.5的时空格局、空间变化特征、污染来源。学者罗毅等[3]将BP神经网络与支持向量机相结合,构建了PM2.5浓度组合的模拟模型,分析了PM2.5污染规律和趋势。学者王娟[4]利用灰色关联度分析,找到了主要影响因素,建立主要影响因素与PM2.5的二次多元回归方程,综合考虑了各因素的影响。虽然上述模型均取得了不错的结果,然而,利用上述方法在对PM2.5进行分析时仍存在着一些不足:(1)将所有可能影响因素拆分开来单独分析,仅考虑单因素的影响,而忽略了多因素之间的交互作用;(2)相关分析只能反映出两个或者多个因素之间的线性相关程度,而不能得出具体的因果关系;(3)由于PM2.5浓度变化的复杂性,各因素与其之间的关系是不确定的,多元回归模型可能并不能反映出其变化的真实规律;(4)大多文献
侧重于对影响PM2.5浓度的自然因素进行分析,而简化了对人为源的分析。基于此,本文利用已有的专家先验知识,找出影响我国PM2.5浓度的6个主要人为因素,分别建立基于K2评分进行结构学习的贝叶斯网络以及根据BIC评分进行结构学习的两种贝叶斯网络模型,对在各因素共同作用下,PM2.5数值是否能达到我国二级标准进行判断,同时建立支持向量机(SVM)、K-近邻(KNN)模型,利用5-折交叉验证对四种模型的分类精度进行对比,考察四种模型在样本数目不太大的情况下的分类精度,找出更为有效的单一分类模型。通过分析影响PM2.5浓度的直接因素、间接因素或无关因素,据此可以为政府相关部门控制PM2.5浓度提供更加有针对性,更为有效的建议方法。
贝叶斯网络是由节点以及有向边组成的概率图模型,是一种在不确定、不完整的因素影响下,进行推理的一种有效的工具。贝叶斯网络提供了一种展示变量之间的因果关系的框架结构。[5]目前贝叶斯网络被广泛应用于故障分析以及相关领域。例如,在故障分析领域,李爽等[6]基于BN-ELM方法对煤矿瓦斯安全态势进行研究;熊宇峰等[7]借助树形贝叶斯网络,实现对配电网故障的快速灾情推断,Hu[8]等借助贝叶斯网络对地震液化势进行预测。在金融领域,严冠等[9]等利用贝叶斯方法建立银行同业借贷网络,对其中的系统风险进行分析研究。
1 研究区域与数据来源
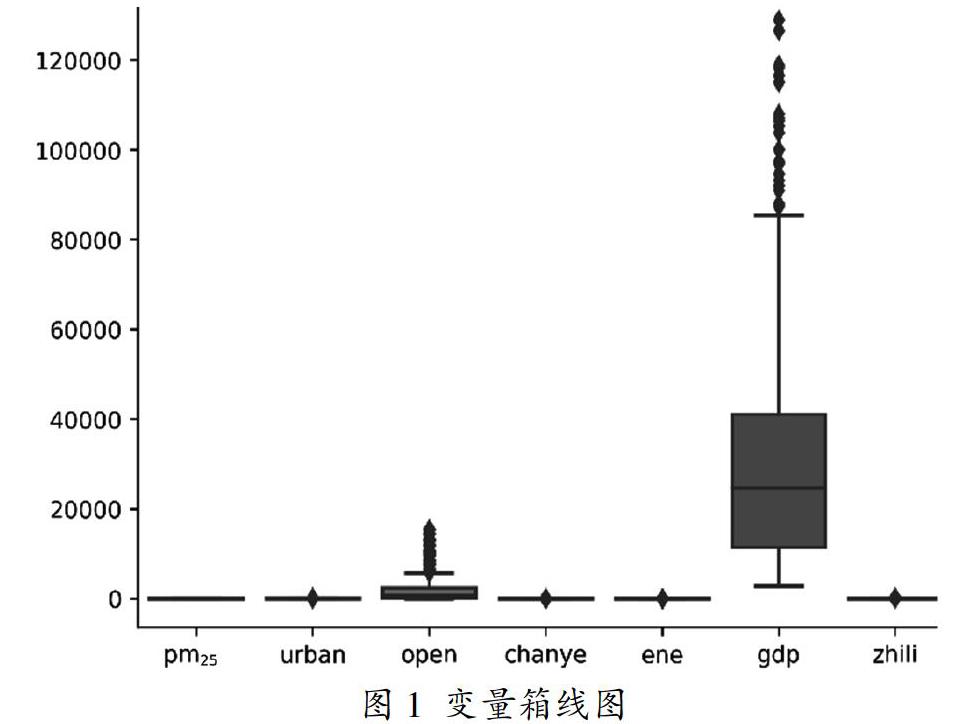
本文面向我国31个省市,收集了2000-2017年相关数据558条。其中,我国2000-2017年的PM2.5值年度数据,由全国城市空气质量实时发布平台获得。根据专家知识,得到影响PM2.5浓度的6个人为因素,包括:城市化水平(Urbanize)、产业结构(IS)、能源结构(ES)、外商直接投资额(Open)、人均生产总值(GRP)、政府治理(PT)。本文使用城镇居民的消费水平与居民消费水平的比值表示城市化水平;产业结构用当地第二产业增加值占该地区生产总值的比重来表示;用该地区煤炭消耗量与该地区生产总值的比值反映能源结构,外商直接投资额以外商投资企业进出口总额与地区生产总值的比值来衡量;由政府治理废气项目完成投资占工业污染治理完成投资的比重来衡量政府治理的力度。相关数据来自《中国统计年鉴》。对数据的统计描述如图1。
从图中可以看出,地区人均生产总值存在较多离群点,且各点之间差距较大,这也从侧面反映出我国的经济发展仍然是不均衡的,地区之间的经济水平差异较大。此外,可以看到外商直接投资也存在较多离群点,根据我们的认识,经济水平更高、地理位置更优越的地区可以吸引更多的外商投资,因此造成了该样本值分布不均、差异较大。为了更加真实的反应各因素对PM2.5浓度的影响,本文将离群点全部保留。
2 研究方法
本文根据历史数据以及专家知识,利用5-折交叉检验方法,对两种贝叶斯网络、SVM模型、K-近邻,四种分类模型进行训练与检验,并对四种模型在样本数目不太大情况下的分类的准确性进行比较,得出更有效的分类模型。
2.1 贝叶斯网络
一个完整的贝叶斯网络模型由贝叶斯网络结构、条件概率表两部分组成。其网络结构是一个有向无环图,[10]其不同节点代表了不同的变量,节点之间的有向弧由父节点指向子节点,表示子节点的取值会受到父节点取值的直接影响。
2.1.1 概率推理
与传统的概率派直接根据样本数据建模分析不同,贝叶斯派为了更加充分利用先验信息,首先引入参数先验分布,再根据样本数据,计算得到参数的后验概率,从而加深对先验信息的认识,在不断迭代,重复上述方法的过程中,不断得到新的先验概率,再将更新修正后的先验信息继续用于求参数的后验概率,从而实现更加准确的推断。通过样本数据,可以对一个给出节点的位置与其条件概率分布的贝叶斯网络重新估计其变量的概率分布,其公式基础便是如下贝叶斯公式与乘法公式:
其中,P(X)为先验概率,P(Y)为边际分布,P(Y|X)是由样本数据得到的似然概率。由于贝叶斯网络的联合分布具有马尔可夫性,即变量只与其父节点取值有关,因此公式(2)可以写成(3)的形式,π(xi)是变量xi的父节点概率。
2.1.2 数据处理
由于贝叶斯网络对于处理离散数据具有更强的稳健性,因此先对数据进行离散化处理。按照PM2.5的浓度是否达到我国二级标准,即年均值是否小于35μg/m3。将均值小于等于35μg/m3赋值1,否则赋值为0。由于外商直接投资额、政府治理两个因素含有大量缺失数据,因此本文将这两个因素中的缺失数据赋值为0,非缺失数据赋值为1,以考察这两个因素的有无对于PM2.5浓度能否达标的影响。对于其他变量的缺失值,本文用插补法进行插补,之后利用k均值的方法将变量人均生产总值、能源结构、产业结构、城市化水平进行聚类,其聚类中心如表1:
表1 變量聚类中心
离散化后的结果如表2所示。
2.1.3 结构学习
贝叶斯网络进行结构学习的方法主要分为两大类:(1)基于约束的结构学习法。这类方法的核心思想是:首先对训练数据集进行条件独立性测试等统计测试,[11]从而找出变量间的条件独立关系。DAG图就是按照尽可能多地覆盖条件独立性关系的原则所构造出来的。[12](2)基于评分搜索的结构学习方法。一种直接的想法是,希望能够遍历DAG结构中的每一种情况,根据某种评价准则,去对每一种可能情况进行评分,选择该标准下的最优结构模型。然而随着贝叶斯网络结构模型中节点数的增加,DAG结构的数量将会大幅增加,Robinson曾给出一个计算DAG结构数量的计算公式:
由公式可以看出,随着节点数增加,DAG结构的数目的增加速度是指数级别的,因此,在节点数比较多的情况下,想要遍历每一种结构形式在有限的时间内是很难完成的。为了解决这一问题,许多学者便提出了利用评分函数的方法,例如爬山算法,面向完全数据模型的K2算法、以及面向含有少量缺失数据的EM算法以及马尔可夫-蒙特卡洛(MCMC)算法,用评分函数作为准则,对各结构进行打分,进而选择出得分最高的结构,该结构即为该准则下最优。评分函数主要分为两大类,一类是包括BDeu评分、K2评分等的贝叶斯评分函数。假设网络拓扑结构G的先验概率为P(G) ,针对给定样本集D,根据贝叶斯公式,网络结构G的后验概率可以表示为:
由于P(D)为样本的函数,与拓扑结构无关,因此对式(5)求极值等价于对其分子P(G)P(D|G)求极值,使得分子达到最大的G,即为所求的,具有最大后验概率的网络结构。为了计算的方便,定义
logP(G,D)=log(P(G)P(D|G))=logP(G)+logP(D|G)(6)
为网络结构的贝叶斯评分,即为MAP测度。[13]另一类是基于信息论的评分函数,BIC评分、MDL评分以及AIC评分等都是使用频率较高的评分函数。爬山算法是贪婪算法的一种,通过不断迭代最大程度提高分数,一旦找到局部最大值,搜索将终止,并返回相应的局部最优的结果。本文以爬山算法作为搜索策略,分别选择贝叶斯评分函数中的K2评分函数,基于信息论的BIC评分函数对模型进行打分,结合专家先验知识确定出两个局部最优的DAG网络结构。为了表述的方便,下文分别将基于K2评分函数的贝叶斯网络模型与基于BIC评分的贝叶斯网络结构模型记为BN-K2模型与BN-BIC模型。两种贝叶斯网络模型的结构图如下图2:
其中,P表示精确率,R表示召回率。
AUC(Area Under Curve)指ROC曲线下的面积,取值介于0.1到1之间,并且越接近于1表示模型的性能越好。基于混淆矩阵的各指标的计算结果汇总如表7。
由表7可以看出,BN-K2模型优势比较明显,各项得分均为最高。根据F1得分可以看出,BN-K2模型得分最高,为60.366%。根据AUC的值表现出的结果与F1得分类似,BN-K2模型取值为0.546,是表现最好的模型。支持向量机模型的AUC值最低,只有0.509。
3.2 讨论
综合考虑5-折交叉验证得分与基于混淆矩阵的评分指标,可以得出结论,两种贝叶斯网络模型是四种模型中最为稳健的,并且模型对于先验知识的利用,也使其在样本量不大的情况下,有着更为优秀的表现。对样本量不大的问题仍有着较为不错的表现也是贝叶斯网络模型的优势之一。
由于样本量以及先验信息的限制,模型能够从数据中学习到的信息并不够多,因此模型的预测精度并不高,还需要进一步的提高。接下来的工作中,需要改进提升的地方还有很多,例如:(1)增大样本量,使模型能够从中得到充分的信息,以增加模型的精度;(2)在对数据缺失值处理的时候,可以采用更加有效的处理方式;(3)收集更多的专家先验知识,对模型的结构与参数进行调整与优化;(4)能够使用混合模型对影响因素进行更加深入的分析。
4 结论与建议
本文对我国2000-2017年全国各年平均地PM2.5浓度值,以及根据专家先验得出的六种PM2.5浓度值的影响因素分别建立了BIC-BN模型、K2-BN模型、SVM模型、K-近邻模型四种模型。根据BIC-BN模型的DAG结构图(图2),我们可以看到,地区产业结构是影响PM2.5浓度的直接因素,城市化水平是影响其浓度的间接因素;K2-BN模型得出的DAG结构图复杂得多,揭示了更多的直接影响因素。我们可以发现,地区的人均生产总值、能源结构城市化水平、政府治理与外商直接投资额都会对PM2.5浓度产生直接影响。借助5-折交叉验证与AUC对模型进行评估,得出结论,即在样本量不太大的情况下,两种贝叶斯网络结构模型稳健性更好,模型的性能也较好,而在两种贝叶斯网络结构模型中,基于K2评分的贝叶斯网络模型性能更佳。
最后,根据本文分析的结果,综合考虑两种模型。各个政府要实现对PM2.5浓度的控制,实现达到国家二级标准的目标,需要在大力发展地区经济水平的同时,要重视调整产业结构与能源结构使其变得更加合理,例如提高第三产业的占比,减少煤炭的使用量,增加清洁能源的用量,加大环境治理的力度。根据贝叶斯网络模型得出的有关PM2.5浓度影响因素的结论,为地方政府采取措施提供了更加有效的方向,地方政府可以采取更加有针对性的治理措施,更加有效的解决大气污染问题。
参考文献:
[1]解蕾,狄光智.基于R语言的城市PM2.5影响因素分析[J].软件工程,2019,22(05):15-17+8.
[2]卢德彬,毛婉柳,杨东阳,等.基于多源遥感数据的中国PM2.5变化趋势与影响因素分析[J].长江流域资源与环境,2019,28(03):651-660.
[3]罗毅,邓琼飞,杨昆,等.近20年来中国典型区域PM2.5时空演变过程[J].环境科学,2018,39(07):3003-3013.
[4]王娟.基于多元回归分析的PM2.5预测研究[J].微型电脑应用,2020,36(03):48-51.
[5]丁艳丽,杨敏,杨殿微.型号研制可靠性工作项目转阶段风险预警[J].项目管理技术,2009,7(07):37-40.
[6]李爽,李丁炜,犹梦洁,等.基于BN-ELM的煤矿瓦斯安全态势预测方法研究[J].系统工程,2020,38(03):132-140.
[7]熊宇峰,周刚,陈颖,等.基于树形贝叶斯网络的配电网快速灾情推断[J].电网技术,2020,44(06):2222-2230.
[8]Ji-Lei Hu,Xiao-Wei Tang,Jiang-Nan Qiu. Assessment of seismic liquefaction potential based on Bayesian network constructed from domain knowledge and history data[J].Soil Dynamics and Earthquake Engineering,2016,89.
[9]严冠,刘志东.基于贝叶斯方法的中国商业银行同业借贷网络中系统风险研究[J].中国管理科学,2020,28(04):14-26.
[10]解晶,何桢,冯楠.基于贝叶斯网络的计算机硬件保修成本分析[J].计算机工程与应用,2007(24):104-106.
[11]晏文娟.模糊貝叶斯网络的研究及其在电子商务发展水平中的应用[D].华南理工大学,2009.
[12]李玮玮.贝叶斯网络结构学习方法的研究[D].南京航空航天大学,2009.
[13]胡春玲.贝叶斯网络结构学习及其应用研究[D].合肥工业大学,2011.
