动态博弈框架下的分布式动态优化
2020-07-15王可心邵之江
朱 强,王可心,邵之江
(浙江大学控制科学与工程学院,浙江杭州 310027)
1 引言
当前,多智能体系统的动态优化是控制理论研究的前沿问题,此类系统是由一群具备一定感知、通信、计算和执行能力的智能体通过通讯等方式关联成的一个网络系统.对于此类大规模网络系统的动态优化问题,滚动时域优化是当前被广泛使用的一种动态优化策略,该策略在实际应用过程中依赖于实时在线求解动态优化问题[1].对于一些具有非线性动态特性的大规模集中式动态优化问题,虽然优化结果的最优性可以保证,但由于每个优化周期内求解的优化问题复杂度较高,常常难以保证实时在线成功求解,所以在利用滚动时域优化策略实时在线求解此类动态优化问题时常常面临巨大挑战[2].为了保证大规模复杂动态优化问题的实时在线求解和灵活操作,研究者们提出了分布式动态优化[3].分布式优化方法比传统的集中式优化方法更为灵活,操作起来更为方便,这也使得利用分布式优化策略来合作完成目标的研究得到了迅速发展[4].在分布式动态优化中,为了减小优化求解的复杂度从而保证实时在线求解,原本非线性大规模多约束的集中式动态优化问题首先被分解为若干个小规模分布式动态优化子问题.之后求解各子问题,并通过各问题之间的通信来综合各问题的最优解以便最终获得原问题的整体最优[5-6].在分布式动态优化求解过程中,最重要的一步是求解各动态优化子问题.求解算法涉及诸多可行的策略,其中,一些研究者从动态博弈的角度来考虑求解上述问题[7-8].博弈论与控制优化理论之间有很多共同之处,最大的共同点在于它们都是通过优化自身的操作来实现自身目标的最优化[9].所以从动态博弈的角度看,分布式动态优化本质上是一个动态博弈,其中各子问题对应动态博弈中的玩家,最优控制对应博弈中的策略,各子问题的目标函数对应博弈中的支付函数[10].基于动态博弈求解分布式动态优化中的子问题时,常用的方法包括基于梯度信息的数值优化算法以及无梯度信息的随机数值优化算法.无梯度信息优化算法相比于基于梯度信息的优化算法优势在于可以处理一些具有不连续不光滑函数的动态优化问题,而且优化计算的逻辑相对容易理解,易于实现[11].但缺点是此类方法得到的结果往往具有随机性,每次求解的结果可能会不同,优化计算的最优性难以保证,而且优化求解的计算代价和时间代价较大.基于梯度信息的数值优化算法是确定性算法,其提供的梯度信息可以保证优化计算的最优性,计算代价和时间代价较无梯度优化算法有较大提升,可以有效的克服上述无梯度信息优化算法的缺点,所以基于梯度信息的数值优化算法优势更为突出,应用场景更广.此类算法中常用的方法是间接法[12].对于一些简单优化问题,上述方法可提供高精度的最优解.但对于复杂优化问题,如果无法为协态变量以及约束和非约束操作之间的切换结构提供足够好的初值,利用上述方法求解动态优化问题将很难成功收敛[13].为了解决上述问题,研究者们提出了直接法.该方法无需求解解析的一阶必要性条件,同时对协态变量和切换结构的初值也不敏感.所以与解析法和间接法相比,直接法更容易进行初始化操作,从而克服了传统方法的缺点.但传统直接法只能求解单边最优控制问题,而基于动态博弈求解分布式动态优化中的子问题时往往涉及双边或多边最优控制问题.如果想使用直接法求解基于动态博弈的分布式动态优化,关键需要对原始多边最优控制问题进行数学变换,将其转换为直接法可以求解的单边最优控制问题.但文献中关于如何变换多边问题并用直接法求解多边最优控制问题的相关研究较少[14-16].
在分布式动态优化方案的实际应用中,除了需要研究分布式动态优化的求解策略之外,在分布式动态优化方案下系统稳定性分析也十分重要.追求分布式动态优化目标函数的极大化或极小化必须在保证系统稳定性的前提下讨论才有意义.例如,当分布式动态优化的目标函数涉及到经济效益时,本文需要在保证系统稳定性的前提下极大化系统的经济效益.所以无论使用哪一种分布式动态优化方案求解动态优化问题,本文首先需要分析该方案下系统稳定性是否满足以及如何满足.由于分布式动态优化方案只能获得系统开环最优控制,所以当本文分析系统稳定性同时也为了保证系统的稳定性时,首先需要构建一个闭环控制系统.本文以极大化系统经济效益作为目标函数,求解极值状态下系统各状态变量和控制变量的稳态值作为闭环控制系统的设定值.因为分布式动态优化方案是基于滚动时域优化来求解开环最优控制,并且本文假设分布式动态优化的目标函数是极大化系统经济效益,所以分布式动态优化方案可看作是经济模型预测控制器.在经济模型预测控制(economic model predictive control,eMPC)下,渐进稳定是研究控制系统稳定性的一个有效理论工具.对于满足耗散结构的系统来说,eMPC下系统的渐进稳定性可以满足,但对于一般的系统来说,系统的渐进稳定性很难被保证.为了解决这一问题,当涉及到eMPC下系统稳定性时,传统的分析系统稳定性的工具需要更新.输入状态实际稳定性(input-to-state practical stability,ISpS)是目前分析eMPC下系统稳定性的常用分析工具之一[17].
在本文研究中,目标是:1)提出滚动合作博弈优化(receding cooperative game optimization,RCGO)方案,从动态博弈角度分析分布式动态优化;2)提出数值优化直接法,分解迭代法(decomposition iterative method,DIM),基于动态博弈求解分布式动态优化;3)在RCGO分布式动态优化方案下,使用ISpS分析系统稳定性.为检验RCGO方案和DIM算法,本文使用一个由两个连续搅拌反应釜和一个绝热闪蒸器组成的化工过程网络作为仿真平台.
本文章节安排如下:第2部分提出RCGO分布式动态优化方案.第3部分展示DIM算法细节.第4部分分析RCGO方案下系统稳定性.第5部分展示数值仿真结果及相关讨论.第6部分总结全文,得出结论.
2 分布式动态优化方案RCGO
本章节提出滚动集中优化(receding centralized optimization,RCO)和滚动合作博弈优化两种动态优化方案.他们都基于滚动时域优化求解动态优化问题.
2.1 滚动集中优化(RCO)
每一个优化周期内,RCO方案只求解一个动态优化问题就可同步获得大规模非线性系统的所有最优控制和状态变量.在t∈[kΔT,(k+P)ΔT]中,动态优化问题可表示为如下形式:
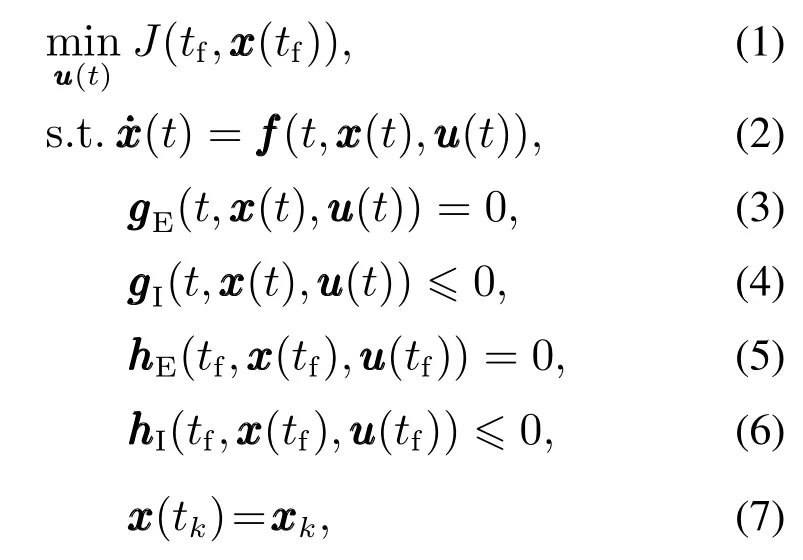
其中:t∈[kΔT,(k+P)ΔT],k∈{0,…,M},xxx(t)和uuu(t)分别表示系统的状态变量和控制变量,fff表示系统模型,gggE和gggI分别表示等式和不等式路径约束,hhhE和hhhI分别表示等式和不等式终态约束,xxxk表示状态变量的初值,J表示目标函数,ΔT表示采样周期,k表示第k个采样周期,M表示采样周期的个数,P表示优化时域.在优化周期t∈[kΔT,(k+P)ΔT]中,在线求解最优控制序列uuu(t),并且从时刻tk=kΔT开始,在时间段t∈[kΔT,(k+L)ΔT](L <P)内执行最优控制序列直到系统得到新的状态变量,其中L表示控制时域,缺省值为1.然后在下一个优化周期内重新求解动态优化问题并重复上述过程,直到获得全部优化时间段内的最优控制序列.
2.2 滚动合作博弈优化(RCGO)
当使用RCO动态优化方案求解大规模非线性动态优化问题时,随着问题规模和复杂度的增加,计算成本和时间代价也将随之迅速增加.为了能够高效求解大规模非线性动态优化问题,一个可行的替代方案是将原本大规模非线性集中式的动态优化问题分解为若干个小规模分布式局部动态优化子问题,也就是分布式动态优化.如引言部分所说,分布式动态优化本质上是一个动态博弈.在动态博弈研究中,合作式博弈又是其中主要的研究方向.合作式动态博弈是指某个大系统中的多个决策主体通过达成某种共识从而优化各自决策变量实现整个大系统性能最优[18].这里作者借鉴合作式动态博弈的概念,基于动态博弈提出了一种分布式动态优化方案RCGO.在RCGO中,所有的局部动态优化子问题共享同一个目标函数.每一个局部动态优化子问题通过极小化全局目标函数来计算自身的最优控制,并考虑自身的最优控制如何影响所有局部动态优化子问题的输出.图1展示了RCGO方案如何获得所有局部动态优化子问题的最优控制从而求解分布式动态优化问题.其中,N是子系统个数,xxx=[xxx1xxx2… xxxN]和uuu=[uuu1uuu2… uuuN]分别是系统的状态变量和控制变量,xxxi和uuui(i∈{1,2,…,N})分别是第i个子系统的状态变量和控制变量.在优化周期t∈[kΔT,(k+P)ΔT]中,第i个子系统对应的局部子问题可表示为如下形式:

其中:t∈[kΔT,(k+P)ΔT],k∈{0,1,…,M},i∈{1,2,…,N}.
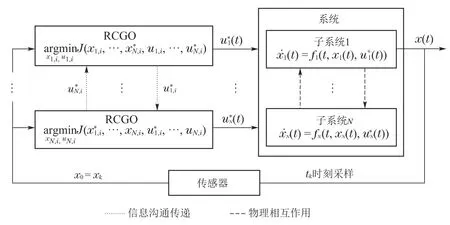
图1 滚动合作博弈优化方案Fig.1 Receding cooperative game optimization scheme
当求解第i个子系统对应的局部动态优化子问题时,往往是基于其他子系统对应的局部动态优化子问题的最优控制.为了获取其他子系统对应的局部动态优化子问题的最优控制,过去常用的方法是第i个子系统根据过去的历史信息估计其他子系统当前的最优控制和最优状态.但这么做存在一个缺点是:如果子系统i在迭代计算自身最优控制时只是估计其他子系统的状态和输入,那意味着需要提前假设过程网络中不存在任何不确定性,所有的子系统(博弈玩家)均是足够智能且一定会选用自身的最优控制作为输入.但在实际过程中,由于过程网络中存在各种过程噪声、测量噪声、外部干扰等不确定性,使得其他子系统实际使用的控制输入与子系统i估计得到的其他子系统的状态与输入存在失配现象.这样会导致子系统i优化计算的最优性无法保证,从而导致整个系统的优化性能下降.在本文中,由于本文是基于滚动时域优化框架,也就是说在每一个优化周期内都要进行一次动态博弈优化计算.在某个优化周期求解第i个子系统对应的局部动态优化子问题之前,要求各子系统之间通讯他们当前的最优控制,也就是说需要其他子系统不断迭代更新并提供他们最新的最优控制值给第i个子系统.在其他子系统均处于最优操作的前提下,以其他子系统的当前最优控制作为控制输入的初值,通过动态博弈优化计算当前优化周期内第i个子系统的最优控制.这样做的目的既是为了保证每个优化周期内优化求解的精度和最优性,同时也是为了消除不确定性的影响而进行的各子系统最优控制的在线矫正.之后更新第i个子系统的最优控制并依此类推重复上述过程,迭代求解获得所有子系统的最优控制.例如,在第1次迭代开始之前,每一个子系统都有各自的控制变量初值.首先本文求解第1个子系统对应的局部动态优化子问题,前提是其他子系统应当为第1个子系统提供他们当前的最优控制.然后作者更新第1个子系统的最优控制并依此类推求解下一个子系统对应的局部动态优化子问题.重复上述过程直到求解完成所有的子系统对应的局部动态优化子问题,这算做第1次迭代.之后作者检查迭代过程终止条件是否满足,例如,当连续两次迭代计算的最优控制欧几里得范数之差小于容限或者迭代次数达到最大迭代次数上限时,迭代过程终止.否则的话,继续重复上述迭代过程直到求解得到所有子系统的最优控制.此时,在优化周期t∈[kΔT,(k+P)ΔT]内的分布式动态优化问题已求解.下一个优化周期重复上述过程直到获得全部优化时间段内的最优控制序列.
3 分布式动态优化数值算法
在RCGO分布式动态优化方案中,求解分布式动态优化最重要的一步是求解每个子系统对应的局部动态优化子问题.考虑到大规模复杂非线性动态优化问题求解的复杂度,本文采用直接法求解各子系统对应的局部动态优化子问题.当每个子系统计算各自的最优控制时,需要其他子系统不断迭代更新并提供他们最新的最优控制值.一个很自然的想法是,在优化周期t∈[kΔT,(k+P)ΔT]内当某个子系统计算自身的最优控制时,假设其他子系统将采样时刻tk=kΔT提供的最优控制值在整个优化周期内保持恒定不变.虽然这样假设可以给计算带来方便,但也会给计算过程引入较大误差,因为在实际情况中其他子系统的最优控制随时间处于连续变化中.为了减小上述假设造成的误差,需要将采样时刻tk=kΔT提供的其他子系统最优控制值作为初值,重新求解其他子系统实际的最优控制值.总结起来,为了求解每个子系统对应的局部动态优化子问题,需处理带有形式目标函数的动态优化问题.但传统的直接法只能用来求解单边最优控制问题,无法求解上述双边或多边最优控制问题[14].在本文中,提出了分解迭代法这种全新的直接法策略,在RCGO动态优化方案框架下基于动态博弈数值求解每个子系统对应的局部动态优化子问题从而求解分布式动态优化问题.为了清晰说明该方法的算法细节,作者考虑一个只有两个子系统的分布式动态优化问题.这里以子系统1对应的局部动态优化子问题的求解过程作为例子,子系统1和子系统2都试图最小化自身目标函数,该动态优化问题可表示为如下形式:
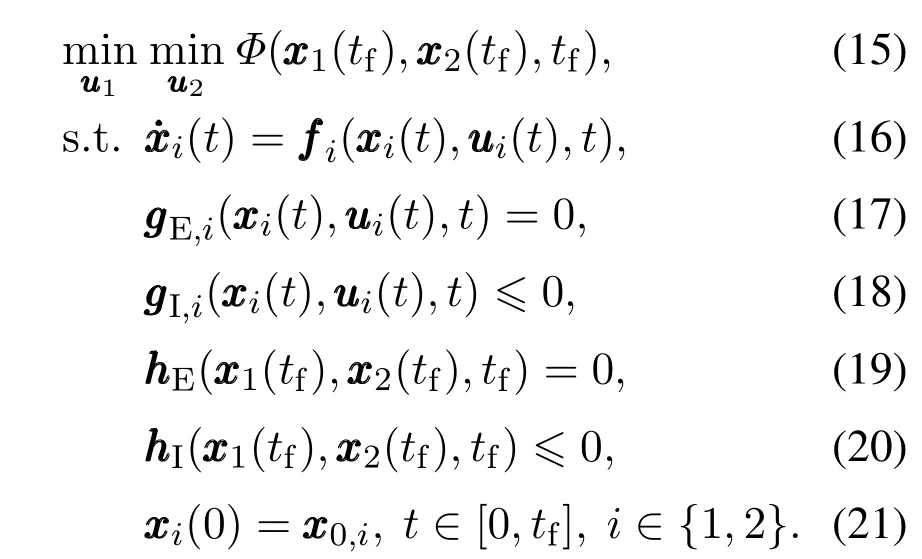
本文通过以下迭代过程来求解上述动态优化问题.每一次迭代中,先固定子系统1当前的最优控制和状态,同时求解子系统2的极小化问题.之后再求解一个线性极小化问题来更新子系统1的最优控制.首先,作者先给出子系统2的极小化问题,可表示为如下形式:


之后,本文求解子系统1的极小化问题如下:
其中α0和β0分别是等式和不等式终态约束的拉格朗日乘子.所以用来近似子系统1原极小化问题的线性极小化问题可以改写为以下形式:


为了能清晰说明分解迭代法的算法细节,本文选用了一个只有两个子系统的分布式动态优化问题作为研究对象.但对于一些本身复杂的系统,其可能会分解成若干个子系统(多于两个).对于求解此类具有多个子系统的动态优化问题时,本文关心的问题是随着系统规模变大,上述分解迭代法的时间复杂度与空间复杂度如何变化.首先本文分析了该算法的时间复杂度.假设某个动态优化问题被分解为n个子系统.每一次迭代计算中,每一个子系统均需要按照分解迭代法的流程求解n个最优控制问题,所有n个子系统共需要求解n×n个最优控制问题.在迭代计算满足判断条件前,每一次迭代n个子系统共需要执行优化计算的次数为n×n,所以该算法的时间复杂度为O(n2).对于该算法的空间复杂度而言,每一次迭代计算每一个子系统均需要按照分解迭代法的流程求解n个最优控制问题.而每一次求解均需创建新的变量存储空间,所有n个子系统在一次迭代计算中共需创建n×n个变量存储空间,所以该算法的空间复杂度也为O(n2).
在分析完分解迭代法的算法时间复杂度和空间复杂度之后,本文的目标是对于求解大规模动态优化问题时,如何进一步提升该算法的计算效能,从而减少优化计算耗时.这其中多个子系统的求解顺序将对整个求解过程的计算代价和时间代价产生很大影响.目前最简单的求解模式是:所有的子系统均按照某种特定的顺序依次求解.当所有的子系统均求解结束后(一次迭代结束),得到的各子系统最优控制变量需要与上一次迭代的结果进行对比,如果某个子系统当前迭代得到的最优控制与上一次迭代得到的结果之差大于容限,那么所有的子系统进入下一次迭代,重新求解各自的最优控制.但上述求解模式可能会出现以下情况:某一次迭代中,大部分子系统的最优控制已经收敛,只有少数几个子系统最优控制没有收敛.这种情况下,真正需要继续迭代求解的只是少数几个还没有收敛的子系统,已经收敛的子系统只需要采用当前收敛的最优控制即可.但所有的子系统如果还按照事先确定的某种求解顺序来依次进行优化求解,势必会重复计算已经收敛的子系统,导致整个计算耗时增加.所以,当优化求解涉及的子系统较多时可以采用以下求解顺序:
1) 迭代初期,先按照事先确定的求解顺序依次获得各子系统当前的最优控制;
2) 一次迭代后,检查哪些子系统的最优控制已经收敛.在下一次迭代中,已经收敛的子系统不再参与迭代求解,这时更新当前求解顺序;
3) 重复上述过程直到所有的子系统最优控制均已收敛,算法结束.
4 RCGO优化方案下系统稳定性分析
本章节使用系统稳定性分析工具ISpS给出了RCGO优化方案下系统的稳定性分析.考虑系统:
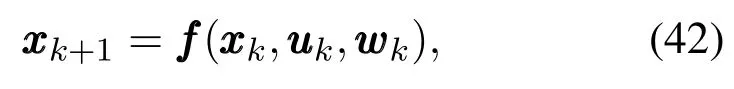
其中:xxx∈X是系统状态变量,uuu∈U是控制变量,同时也是xxx的函数,www∈W是干扰变量.定义|·|为2范数,k=[www0… wwwk-10 …]为k时刻的干扰变量序列,以及=[www0www1www2…]为全部优化时间内的干扰变量序列.首先,给出以下几个假设和定义.
假设11)对于所有的xxx∈X,www∈W,都会有fff(xxx,uuu,www)∈X成立;2)集合W有上界,并定义‖‖:=sup|wwwk|;3)fff(·,·,·)相对于www一致连续.
定义1函数α属于K类函数当且仅当该函数是连续的严格增函数,并且满足α(0)=0;函数α属于K∞类函数当且仅当该函数是K类函数,并且满足函数β属于KL类函数当且仅当对于每一个t≥0,β(·,t)属于K类函数,且对于每一个s≥0,β(s,·)是非增函数并且满足
定义2在假设1成立的前提下,系统(42)是输入状态实际稳定(ISpS)当且仅当对于所有的xxx0∈X,k≥0,都有|xxxk|≤β(xxx0,k)+γ(‖‖)+c成立,其中β∈KL,γ∈K,c∈R,R是实数集.
定理1在假设1成立的前提下,对于系统(42),如果存在一个函数V(k,,xxx0)满足
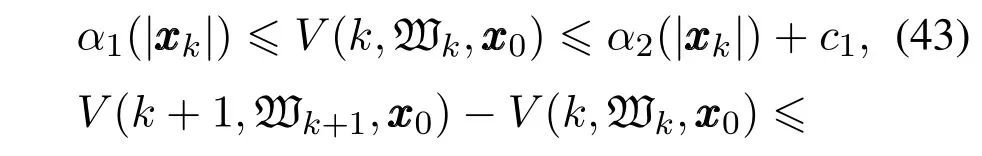
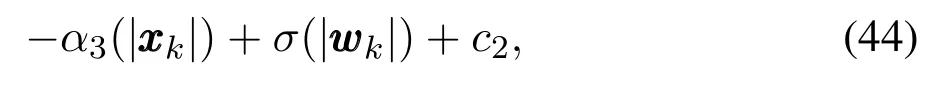
其中:∀xxx0∈X,www∈W,k∈Z,α1,α2,α3∈K∞,σ∈K,c1,c2∈R,Z是整数集,那么系统(42)是输入状态实际稳定.
证见文献[17].
如引言部分所述,RCGO动态优化方案可以看作是一个eMPC控制器,即经济模型预测控制器.所以研究RCGO优化方案下系统的稳定性可以转换为研究在基于RCGO优化方案的eMPC控制器下系统的稳定性.现在考虑了基于RCGO优化方案的eMPC(eMPC-RCGO)命题构造形式.这里仍然考虑一个只有两个子系统的分布式动态优化问题.对于每一个子系统,标准目标函数可表示为


其中ρ1和ρ2是两个子系统的目标函数权重系数.所以eMPC-RCGO控制器求解的非线性规划可表示为如下形式:
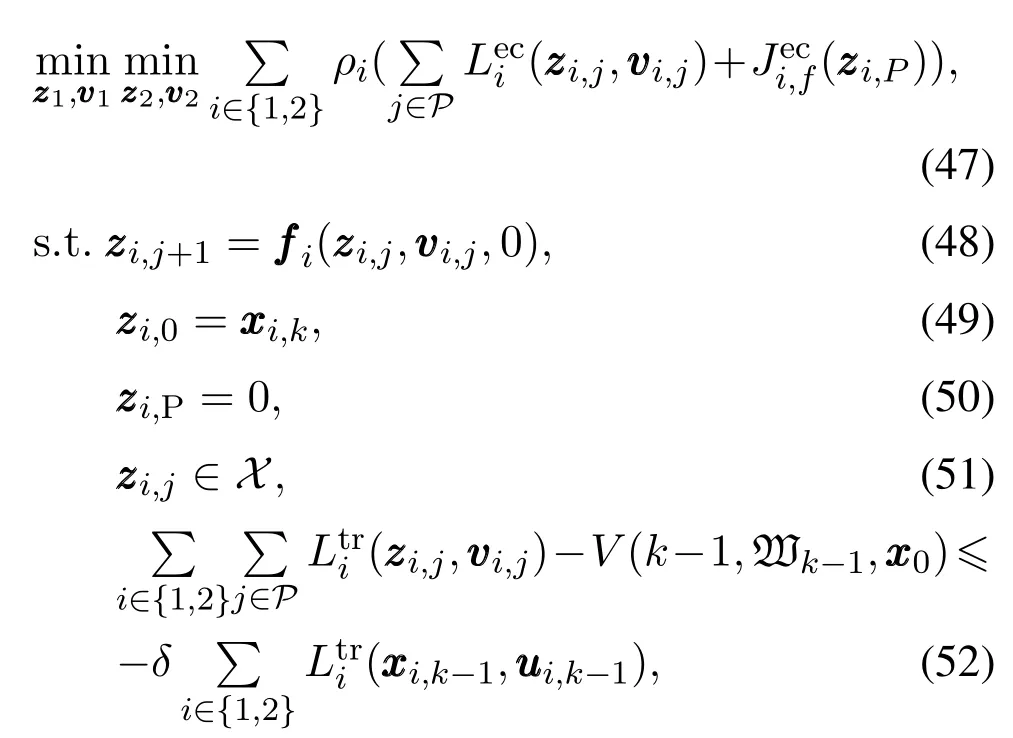
其中:vvvi,j∈U,i∈{1,2},j∈P=[0,…,P -1],是第i个子系统在动态过程中产生的跟踪阶段成本,用来衡量各状态变量和控制变量偏离稳态值的程度,是采样时刻k非线性规划(47)-(52)的解,

如定义2和定理1所述,文献[17]给出了输入状态实际稳定的定义以及在输入状态实际稳定意义下的李雅普诺夫稳定性判定定理及证明.接下来将在文献[17]的基础上说明在由式(47)-(52)组成的eMPCRCGO控制器下系统是输入状态实际稳定.
定理2如果假设1成立,那么存在α1,α2,α3∈K∞,σ∈K,c1,c2∈R,使得存在V(k,,xxx0)满足定理1,并且对于所有的xxx0∈X,www∈W,k∈Z都有eMPC-RCGO控制器下系统是输入状态实际稳定.
证假设是K∞类函数,且存在下界


基于上述推导,可以得到V 的一个上界.至此,定理1中式(43)可以满足
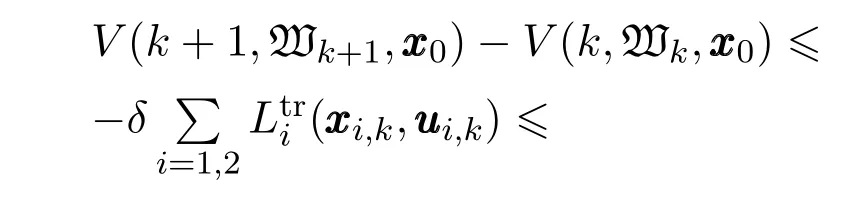
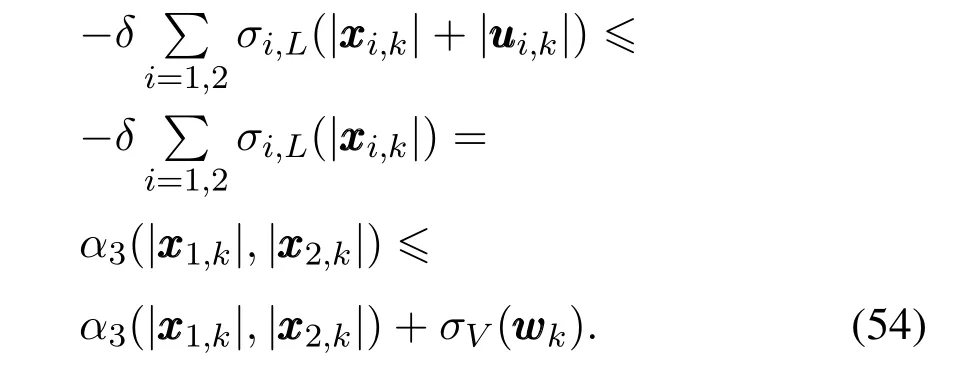
依据上述推导过程,定理1中式(44)可以满足.综上,存在V(k,,xxx0)满足定理1,并且对于所有的xxx0∈X,www∈W,k∈Z都有eMPC-RCGO控制器下系统是输入状态实际稳定.
5 数值仿真案例
为了检验本文提出的RCGO动态优化方案以及DIM数值求解算法的可行性,选择一个由两个连续搅拌反应釜(continuous stirred tank reactor,CSTR)和一个绝热闪蒸器组成的化工过程网络作为仿真验证平台.如图2所示,在每一个CSTR中,期望产品B是通过一阶主反应获得,同时存在的副反应会消耗一部分期望产品B并生成不需要的副产品C.CSTR 2的出料流股被送到闪蒸器中,并将原料A从B和C中分离出来.其中主要包含原料A的一部分气相流股被排出,以防止副产品C的积累,剩余的气相流股回流到CSTR 1中.而主要包含B和C的液相流股则从闪蒸器中排出备用.本章节使用RCO和RCGO两种动态优化方案来求解上述化工过程网络中涉及的大规模动态优化问题.在RCO动态优化方案中,目标函数可以表示为如下的形式:

其中:J是系统的现金流,αFbxBb是售卖期望产品B获得的收入,[β(F0xA0+F1xA1)+γ(Qr+Qm+Qb)]是由原料流股成本和热负荷成本组成的操作成本,η(Qr+Qm+Qb)是CO2排放产生的成本,(ω1×(F0+F1)+ω2×(Qr+Qm+Qb))是外部市场因素造成的风险成本.α,β,γ,η,ω1,ω2是每一项成本和收入对应的系数.在RCGO动态优化方案中,CSTR 1,CSTR 2以及闪蒸器被看作是3个子系统,他们各自的目标函数可以分别表示为
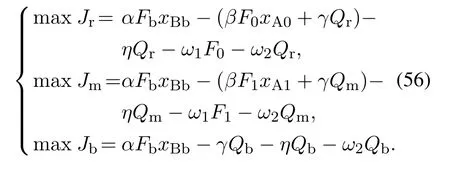
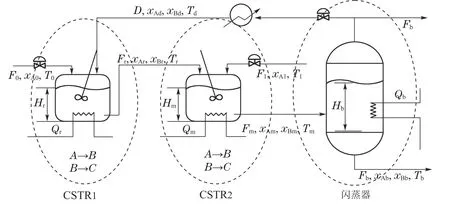
图2 连带绝热闪蒸器的双反应器链Fig.2 Two-reactor chain followed by nonadiabatic flash
因为本文提出的分布式动态优化方案是合作式的,也就是说单独来看每个独立子系统都有自己的目标函数,但是在合作式动态博弈优化计算中,所有的子系统目标是使得整个系统的整体优化性能最大.所以每个子系统使用的目标函数是关于提升整个系统的优化性能并且应该是一致的.对于目标函数的选择,一般的做法是将每个独立子系统的目标函数线性加和,系数则根据实际生产工况、态势决定.因此本文将上述3个目标函数整合为1个大系统的整体目标函数,可表示为以下形式:
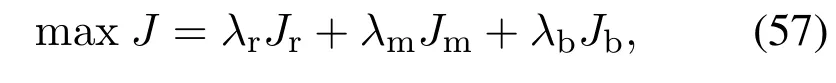
其中λr,λm,λb是各子系统目标函数对应的权值系数,具体数值由生产者根据实际需求决定.
在本文中,从3个角度来衡量RCO和RCGO动态优化方案的优化性能优劣.第1个方面是对象系统的经济效益指标.由于RCO和RCGO方案选择使用的目标函数不同,所以为了能够衡量两种方案的经济效益优劣,首先统一经济效益指标为

第2个方面是对象系统的闭环控制性能指标.该项性能指标主要包括状态变量与其稳态值的积分平方误差(integral square error of state variable,ISE)以及控制变量与其稳态值的积分平方误差(integral square error of control variable,ISC).第3个方面是对象系统的实时计算性能指标,衡量标准是每个采样周期内的平均优化计算时间.
在本文的数值仿真中,可以选用求解器IPOPT(interior point optimizer)来求解非线性规划问题.采样周期ΔT取1 s,优化时域P和控制时域L分别取5和1,迭代终止容限ϵ取0.001,最大迭代次数Imax取10.基于上述参数设置,在RCO和RCGO动态优化方案下得到的过程网络控制变量和状态变量序列分别如图3-4所示.
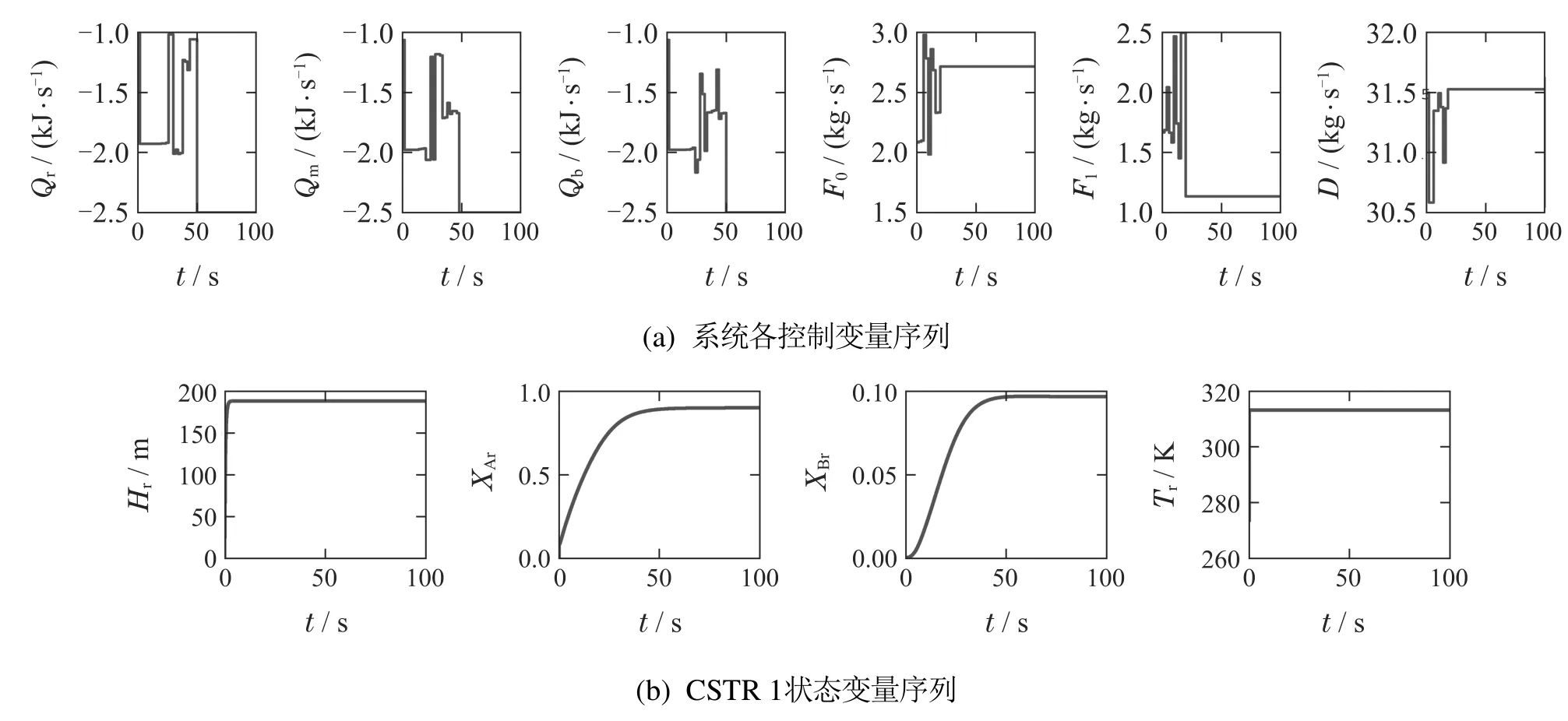
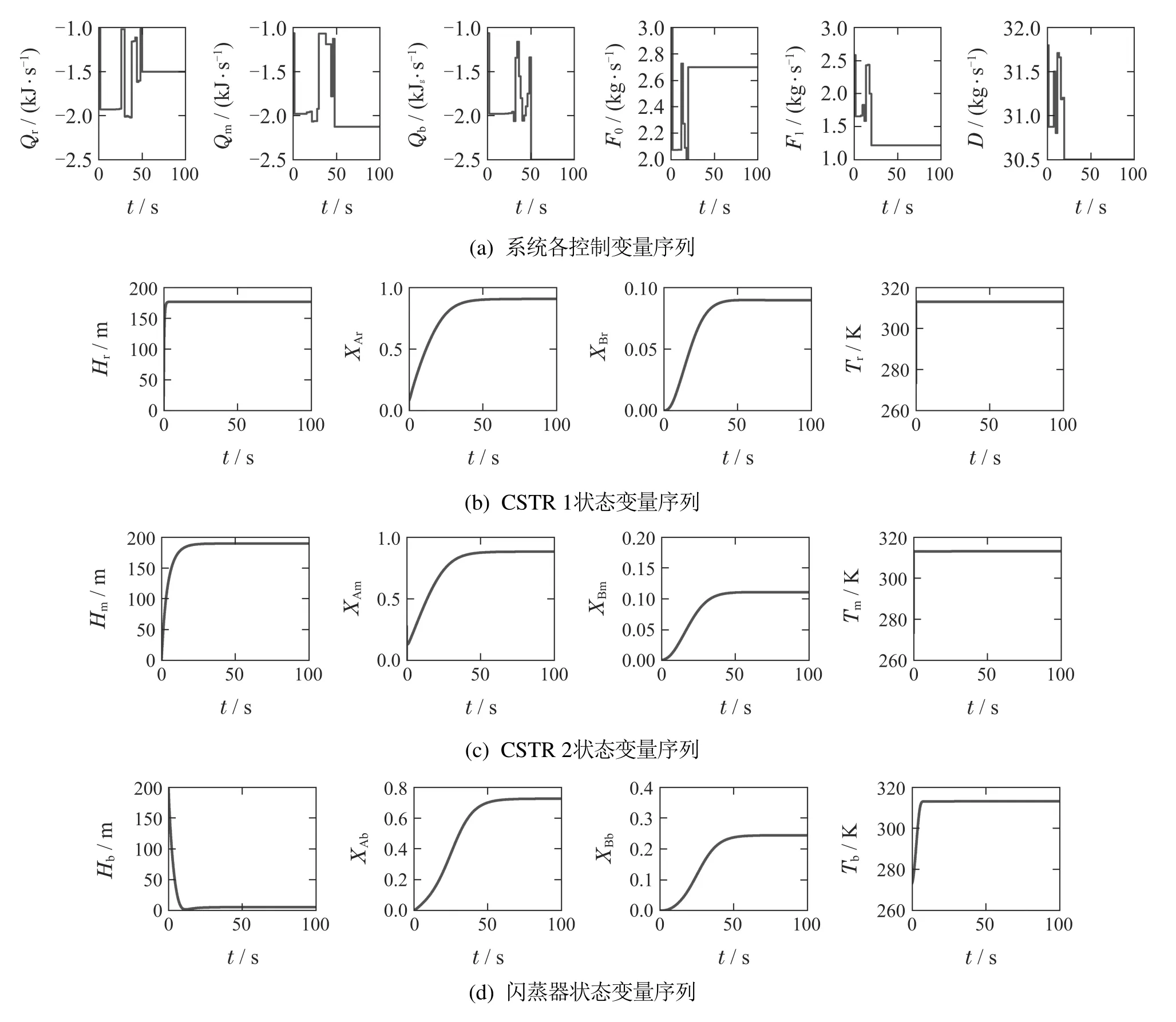
图4 RCGO方案下各变量序列Fig.4 Variable profiles in the RCGO scheme
图3-4观察到两种动态优化方案下系统各状态变量的整定误差经过平滑过渡后均收敛到0,这样的结果保证了系统各状态变量均可以稳定在其对应的稳态值上.同时也注意到两种动态优化方案下系统各控制变量也均可以稳定在其对应的稳态值上.上述结果表明,在RCO和RCGO动态优化方案下的系统是稳定的,同时也验证了第4部分中对RCGO优化方案下系统的稳定性分析.
在RCGO动态优化方案下,每个优化周期内优化求解的迭代收敛情况和迭代次数如图5所示.每个优化周期内最后两次连续迭代得到的最优控制之差的欧几里得范数(the Euclidean norm of the difference between the vectors of the computed optimal control of the final two consecutive iterations,ENDC)均小于设定的迭代终止容限ϵ=0.001.这意味着在每一个优化周期内,使用RCGO动态优化方案求解过程网络大规模动态优化问题时均可以成功收敛.同时,每个优化周期内优化求解的迭代次数均小于设定的最大迭代次数.这些数值仿真的结果均表明RCGO动态优化方案可以有效求解大规模动态优化问题.
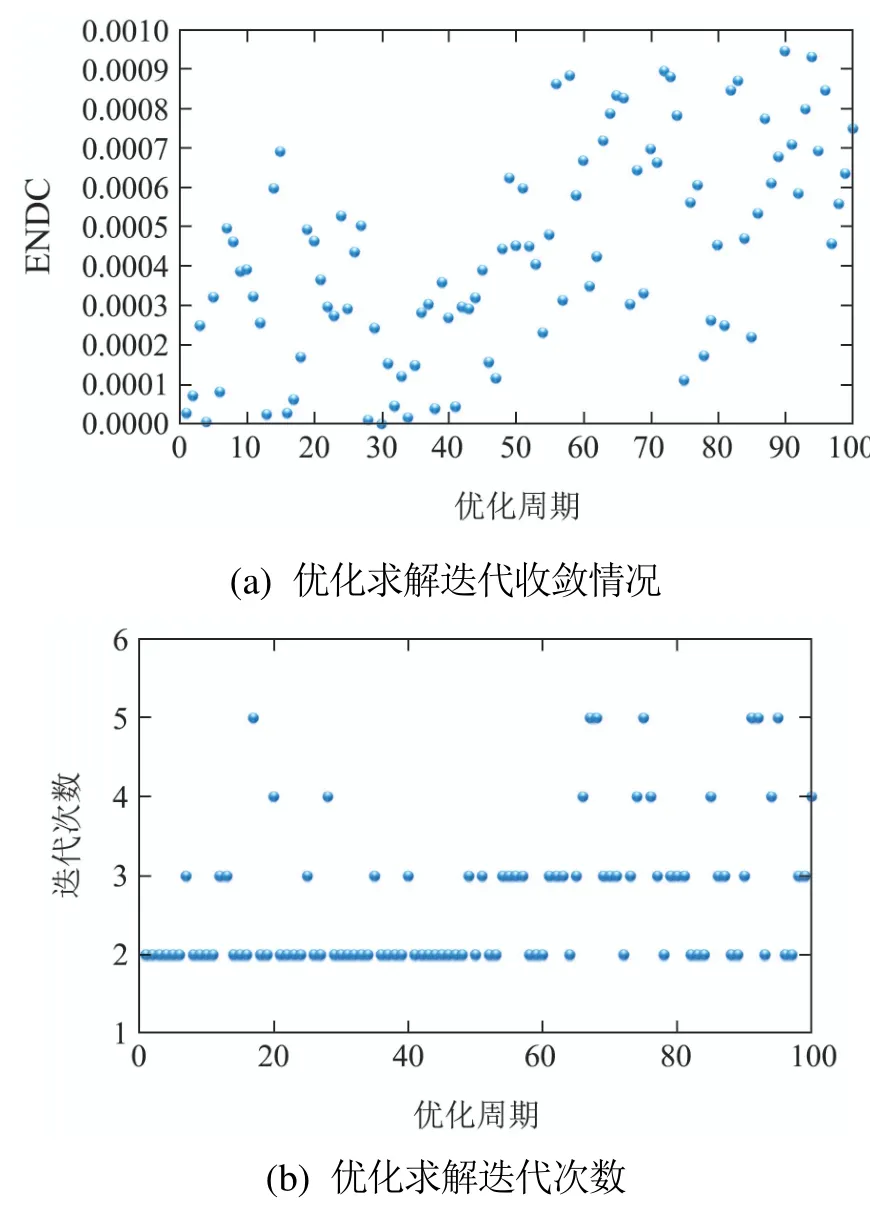
图5 RCGO方案下优化求解迭代收敛情况和迭代次数Fig.5 Convergence and iteration number of the RCGO
从上述数值仿真的结果可以看到,当使用RCO方案求解过程网络大规模动态优化问题时,得到的过程网络经济效益指标和闭环控制性能指标均是最优的.这是因为在优化求解时RCO方案同时考虑过程网络中所有的控制变量,所以该方案下优化求解的结果往往考虑了动态优化问题的全局最优性.当使用RCGO方案时,由于该方案不仅考虑过程网络整体的最优,还考虑了每一个子系统的最优性.这样做会导致过程网络动态优化问题的全局最优性往往不能保证.也就是说,过程网络的经济效益指标和闭环控制性能指标的好坏是权衡子系统最优性和过程网络整体最优性后得到的结果.当使用RCO和RCGO动态优化方案分别求解过程网络大规模动态优化问题时,每个采样周期内的平均优化计算时间如图6(b)所示.当使用RCO方案时,每个采样周
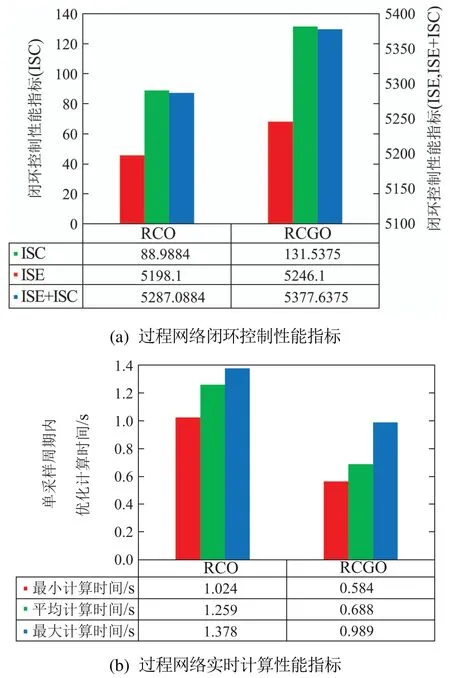
图6 RCO和RCGO方案下过程网络闭环控制性能指标和实时计算性能指标Fig.6 Close-loop and real-time performance indices of the RCO and RCGO
接下来本文从过程网络的经济效益指标、闭环控制性能指标以及实时计算性能指标这3方面对RCO和RCGO动态优化方案优化性能的优劣进行对比.当使用RCO和RCGO动态优化方案分别求解过程网络大规模动态优化问题时,得到的过程网络经济效益指标分别为1.3541和0.9160,且在持续100 s的在线优化操作当中,过程网络的闭环控制性能指标如图6(a)所示.期内的平均优化计算时间相比于使用RCGO方案会更长.这是因为在每一个优化周期内RCO方案需要求解一个大规模动态优化问题,由于规模和复杂度大往往需要耗费较多时间成本.同时,该方案下每个采样周期内的平均优化计算时间会超过采样周期长度,这意味着RCO方案将难以应用到过程网络动态优化问题的实时求解当中.当使用RCGO方案时,由于优化求解的系统模型规模较小,求解复杂度相比RCO方案较低,所以该方案下可以保证过程网络动态优化问题的实时求解.综上,在求解复杂大规模动态优化问题时,RCGO方案较传统的集中式优化方案在由系统经济效益、闭环控制性能及优化求解实时性等组成的综合指标上有较大优势.
6 结论
本文基于动态博弈理论提出了一种分布式动态优化方案,滚动合作博弈优化,来实时在线求解复杂的大规模动态优化问题.通过将原本复杂的大规模动态优化问题分解为若干简单的小规模局部优化子问题,使得计算复杂度降低从而保证优化求解的实时性.本文还基于动态博弈理论提出了分解迭代法来求解各局部优化子问题,并对RCGO优化方案下系统稳定性进行分析.最后本文选择一个化工过程网络作为仿真案例,基于RCGO方案得到了极大化经济效益下该网络的最优操作.优化结果表明在求解复杂大规模动态优化问题时,RCGO方案较传统的集中式优化方案在由系统经济效益、闭环控制性能及优化求解实时性等组成的综合指标上有较大优势.在本文提出的RCGO附动态优化方案中,各子系统均使用相同的目标函数.但在实际应用中,各子系统不仅会考虑整个大系统的目标函数,还可能考虑自身系统的经济效益.所以在后续的工作中,作者打算引入另外一种分布式动态优化方案,各子系统可根据自身经济效益的需求选择使用不同的目标函数.通过提出上述两种分布式动态优化方案,使得复杂大规模动态优化问题实时在线求解的理论框架得到进一步完善.同时,本文使用分解迭代法求解分布式动态优化时,得到的解只能保证其为局部最优解.在后续工作中,作者打算采用自适应调整有限元大小位置以及有限元之间的拉格朗日插值多项式阶次等措施来进一步提升优化求解的质量和最优性.
