基于卷积神经网络的FrameNet框架消歧研究
2020-07-13郭宇飞郝晓燕
郭宇飞, 郝晓燕
(1. 太原理工大学 软件学院, 山西 太原 030024; 2. 太原理工大学 信息与计算机学院, 山西 太原 030024)
1 FrameNet简介
1.1 FrameNet概述
FrameNet项目由美国加州大学伯克利分校所建立, 是以框架语义学为基础的英语词汇数据语料库. 该语料库以归纳、 总结英语词汇的语义与语法信息的框架结构为基础, 核心内容是将词语的词义表述与框架语义结构相融合[1-2]. 语料库中的例句以目标词为依托, 标注句中的词元词性(如名词[NN]、 副词[RB]和形容词[JJ]等)及词汇的短语类型(如名词性短语[NP]、 动词性短语[VP]、 介词性短语[PP] 等). FrameNet语料库主要由框架库、 词元库、 句子库所构成.
1.2 框架词元
在框架语义知识库中, 将能够激起两个或两个以上框架的单词称作词元. 例如, 框架“Containers”涉及的词元单词包括: amphora.n; ampule.n; ashtray.n; backpack.n; bag.n; barrel.n; basin.n; basket.n; beaker.n; bin.n; bottle.n; bowl.n; box.n; briefcase.n; bucket.n; can.n; 等[3].
2 特征提取
以歧义词为中心, 从其上下各3个邻接词汇单元中依次提取词义信息、 词性信息、 句法分析类型信息和依存句法分析父节点作为消歧特征, 共提取24个消歧特征用来判断识别歧义词所能激起的框架类别[4]. 当歧义词上下两方向的邻接单词数量不足3个时, 所空缺位置的消歧特征值用null代替, 从而保证每个歧义词都包含数量相等的消歧特征.
在选择歧义词邻接词汇单元时, 构建目标词元所在例句的依存句法分析树, 目前词的前3个邻接词汇单元以目标词为中心结点向其父亲节点及左兄弟结点方向选择距离目标词节点最近的3个结点, 目标词的后3个邻接词汇单元为中心结点的子亲节点及右兄弟结点中距离中心结点最近的3个结点, 当出现2个结点与中心结点距离相同时, 选择在例句中与目标词距离短的作为邻接单词.
在完成邻接词汇单元选择后, 为了便于统计, 选取4种特征类别: 单词词义(用M表示), 父节点单词词义(用F表示), 单词词性(用P表示), 依存句法分析类型(用D表示), 则1个待消歧词提取出的24个消歧特征F可表述为
F=(ML3,FL3,PL3,DL3,ML2,FL2,PL2,DL2,ML1,FL1,PL1,DL1,MR1,FR1,PR1,DR1,MR2,FR2,PR2,DR2,MR3,FR3,PR3,DR3).
3 基于卷积神经网络的词义消歧
3.1 输入层
在卷积神经网络中, 输入层一般为一个向量矩阵[5-6], 所以实验中选择将24个消歧特征向量化, 通过word2vec以FrameNet框架语料库中的100 000个单词作为训练语料库, 建立300维的词向量, 则得到特征向量矩阵为s=24行,d=300列的矩阵A∈Rs×d, 如图 1 所示.

图 1 特征矩阵向量图Fig.1 Eigenmatrix vector diagram
3.2 卷积层
卷积层的目的是通过选取不同的卷积核提取输入的不同特征, 同时降低输入层维度. 对于特征向量矩阵A, 可以将其看作一个像素图, 需要运用卷积神经网络进行特征的分析提取. 卷积层在作用于图像中时, 因其每个像素点代表独立、 具体有实义的特征, 而基于卷积神经网络的自然语言处理方面, 一个词汇单元的意义表达通常为输入矩阵中的一整行特征向量, 且相邻向量之间的关联性总是很高, 所以为了保证在卷积操作中提取特征信息的完整性和有效性[7], 卷积核的宽度只能固定为与输入层宽度相同的维度且沿向下的一个方向移动. 据此该卷积神经网络中卷积核w依照输入矩阵的维度可设置为
w∈n×k,
(1)
式中:n为卷积窗口的行数;k为输入层特征矩阵的维数. 卷积层中卷积核有n×k个参数, 每进行一次迭代意味着需要对卷积核中n×k个参数进行更新. 在更新中通常需要加入偏置项以达到更好的迭代, 设置偏置项的运算函数为
f1=w·A[i:i+n-1]+b,
(i=1,2...,s-n+1),
(2)
式中:A[i:j]表示从矩阵的第i行到第j行.
卷积核在输入矩阵中通常根据特定的步长在特征向量矩阵中自上向下进行滑动卷积, 每滑动一次就进行一次卷积操作, 提取消歧特征. 例如当选择以步长为1进行滑动时, 得到特征图a
a=[a1,a2,…,as-n+1].
(3)
卷积层的模型图如图 2 所示.

图 2 卷积层模型图Fig.2 Convolution layer model graph
3.3 池化层
池化层输入为卷积层的输出, 池化层的目的是进一步减少训练参数的数量、 维度从而尽可能减弱过拟合因素的影响, 通过整合将价值相对高的信息保留, 减少噪声. 另外, 不同宽度的卷积核得到的特征图大小是不同的, 当同时采用多个不同规格的卷积核时就需要使用池化函数, 使它们的输出维度相同. 池化函数有多重类型, 其中最大池化法1-max pooling较为常用且效果颇佳. 最大池化法1-max pooling表述为
ai=max(a1,a2,…,am-h+1).
(4)
最大池化法以选择特征图中每一块固定区间中的最大值作为输出, 通过选择每个特征图区间的最大值, 提取出相对最重要的特征. 当对不同规格的卷积核卷积后, 长度不同的输出采用不同长度的1-max pooling函数函数后使得其输出长度相同. 如图 3 所示, 设置池化层输出为向量V,vi表示V中的第i个元素,vj表示V中的每个元素, 卷积层的输出a的长度分别为23和12, 为了使池化层的输出长度相同, 在选择最大池化函数时选取的长度分别为4个单位和2个单位, 以此保证池化层的输出长度相同. 池化层输出向量可表述为
V=(v1,v2,v3,v4,v5,v6).
(5)
其他池化层较为常用的函数包括 average pooling函数和K-Max Pooling函数. average pooling函数是选取卷积层输出的每个区间所有值的平均数作为输出; K-Max Pooling函数是选取卷积层输出的每个区间上Top-K的值, 并且保留其初始次序.

图 3 池化层模型图Fig.3 Model diagram of pool layer
3.4 全连接层
全连接层的输入为池化操作后形成的一维向量, 将该一维向量通过激活函数后输出分类. 该实验的目的是处理多义词的消歧问题, 而每个歧义词至少可以激起两个或两个以上的FrameNet框架, 该卷积神经网络的输出是多分类问题, 所以采用Softmax函数.
Softmax函数在多分类过程中将一维向量的各个节点通过运算输出映射到(0,1)区间内, 每个输出数值的总和为1, 因此可以将其输出结果看作不同框架选择的概率分布问题, 从而进行多分类求解.
池化层输出为向量V,vi表示V中的第i个元素, 设置vk表示V中的任一元素,j为元素个数, 则这个元素的Softmax值为

(6)
将池化层输出的一维向量V(v1,v2,v3,…,vn)通过Softmax函数作用, 就映射成为(0,1)的输出值, 而这些值的累和为1(满足概率的性质), 因此Softmax函数的输出可以理解为对不同结果的概率分析, 而在最后选取输出结点时, 概率最大也就是值对应最大的结点, 就是所要选择的激起框架目标节点.
全连接层的输出s是池化层输出的一维向量V与W系数矩阵的相乘, 即s=WV. 对于多分类问题, 使用 Softmax 对线性输出进行处理. 其中,Syi表示训练句子能够激起正确框架的得分函数,Syk表示任一函数,c表示总类别个数,Si为与正确激起框架高概率值的 Softmax输出. 在增加log函数后不会影响原函数的单调性, 所以对Si添加log函数
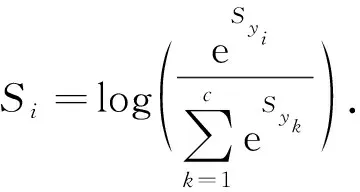
(7)
当式(7)的输出数值越高, 意味着选取得到正确激活框架的概率值越高, 所以在Si前增加负号表示损失函数

(8)
化简指数部分后, Softmax 损失函数为

(9)
4 实验及结果分析
4.1 FrameNet语料库多义词选取标准
在FrameNet语料库中, 多义词在不同句子语境中可以激起不同的所属框架, 在每个框架中会有已经标注好的该框架下目标多义词的例句集, 这为多义词的卷积神经网络模型的训练提供了可能. 在选择歧义词汇时, 以选择能够激起两个或两个以上框架并且在所属框架下含有一定量的标注完成的例句集为标准, 使得每个待消歧词语单元拥有不同词义及所属训练集, 保证实验数据获取准确、 科学.
4.2 实验数据获取
实验选取了15个能够在FrameNet框架语料库中激起两个或两个以上框架的多义词词汇:“can” “name” “kill” “say” “suggest” “number” “sense” “show” “see” “know” “time” “treat” “fly” “close” “like”, 选取句子2 600多句.
以下以单词“can”为例. 单词“can”在FrameNet语料库中可以激起“Containers” “Measure_volume” “Preserving” “Capabiliy” “Possibility”5个框架. 并针对每个框架在FrameNet语料库中选含有目标词的句子, 其中“Containers”48句, “Measure_volume”26句, “Preserving” 5句, “Capabiliy” 99句, “Possibility” 57句, 共235句. 随机选择30句作为测试集, 其余作为训练集.
4.3 语料预处理
以包含待消歧词“can”的句子“ I had to go round with a CAN of milk !”为例, 其预处理过程如下:
运用Stanford Parser进行词性标注:
I/PRP had/VBD to/TO go/VB round/NN with/IN a/DT CAN/NNP of/IN milk/NN
运用Stanford Parser进行依存句法分析:
nsubj(had-2, I-1)
root(ROOT-0, had-2)
mark(go-4, to-3)
xcomp(had-2, go-4)
dobj(go-4, round-5)
case(CAN-8, with-6)
det(CAN-8, a-7)
nmod(go-4, CAN-8)
case(milk-10, of-9)
nmod(CAN-8, milk-10)
美国斯坦福句法分析器Stanford Parser可以自动地进行词性分析和依存句法分析, 通过运用Stanford Parser句法分析器对语料库中的句子进行预处理从而完成句子的词性标注与依存句法分析, 然后构建句法分析树, 依存句法分析树以及邻接词汇单元的选择如图 4 所示.
依据句法分析树, 以目标词“can”为中心结点向其父节点及左兄弟结点方向选择距离中心结点最近的3个结点作为邻接单词, 当出现2个结点与中心结点距离相同时, 选择在句中与目标词距离短的作为邻接单词, 另一侧同上. 如图 4 所示提取出“to” “round” “go” “with” “a” “milk” 6个单词作为该句的邻接单词.

图 4 依存句法分析树Fig.4 Dependency parsing tree
特征选取结果为:“to/go/TO/mark”“round/go/NN/dobj”“go/had/VB/xcomp”“with/can/IN/case”“a/can/DT/det”“milk/can/NN/nmod”. 例句中提取出的24个消歧特征可以表述为: ML3=to, FL3=go, PL3=TO, DL3=mark, ML2=round, FL2=go, PL2=NN, DL2=dobj, ML1=go, FL1=had, PL1=VB, DL1=xcomp, MR1=with, FR1=can, PR1=IN, DR1=case, MR2=a, FR2=can, PR2=DT, DR2=det, MR3=milk, FR3=can, PR3=NN, DR3=nmod. 则例句的消歧特征向量矩阵可表示为
将预处理后的训练集向量矩阵及其预期输出结果输入到卷积神经网络中进行训练, 随后将测试集30个句子的特征向量矩阵放入到训练好的卷积神经网络中进行测试运算.
4.4 实验结果分析
使用预先设置的测试集测试输出结果进行汇总, 并采用平均准确率公式进行测评
pi=mi/ni,
式中:pi为第i个目标词的准确率;mi为第i个词测试输出正确的句子个数;ni为第i个目标词参加测试的句子的总个数.
设置整体的准确率测评公式为
P=M/N,
式中:P为整体目标词的准确率;M为测试输出正确的句子个数;N为参加测试的句子总个数.
实验中除采用6个邻接单词的特征选取方法外还实验了选取4个和8个邻接单词. 对于每个目标词的测试集, 当从FrameNet框架预料库中提取的句子数大于200个时, 随机选择30个句子作为训练集, 当提取的句子数在100~200个时, 随机选择25个句子作为训练集, 当提取的句子数小于等于100个时, 随机选择15个句子作为训练集. 整体实验准确率统计如图 5 所示.

图 5 训练集准确率Fig.5 Training set accuracy
根据实验结果分析, 特征向量选用6个邻接词的准确率整体高于4个和8个邻接词, 这是由于4个邻接词所选择的特征向量较少, 卷积操作时提取信息量不足以获取较为全面的信息; 而8个邻接词在某些单词上测试表现良好, 但由于存在过拟合性, 结果有较强的波动性. 对于不同的单词在选用6个邻接词作为特征向量提取时也存在一定的波动性, 其主要影响因素包括训练集句子的总数、 不同框架提取的句子数的比例、 目标词可激起的框架数以及框架所属的词性. 对于框架所属的词性进行进一步分析发现, 当目标词激起的框架主要为同一词性时, 准确率将普遍低于能激起多种词性框架的目标词准确率.
针对相同的特征向量还进行了基于不同算法的实验, 其测试准确率如表 1 所示, 可以看出在FrameNet框架消歧中, 基于卷积神经网络的算法测试准确率更好, 这进一步证明了该实验的有效性[3].

表 1 不同算法下的准确率对比
5 结 语
本文通过在FrameNet语料库的框架模型结构下提取歧义词的句子, 并使用Stanford Parser进行数据预处理, 构建依存句法分析树选取目标词邻接的6个单词的词义、 父节点词义、 词性、 依存句法分析类型作为消歧特征, 运用word2vec对所有特征进行向量化转化为可以输入卷积神经网络的特征向量矩阵, 之后利用卷积神经网络对输出的框架类型进行分类. 实验结果证明了该实验较优于条件随机场等算法, 对FrameNet框架下的消歧性能有所提高.
