基于中文文本的同义词提取方法研究
2020-07-07杨浩天胡勇王正
杨浩天,胡勇,王正
(四川大学网络空间安全学院,成都610065)
0 引言
如今,随着自然语言处理技术发展得越来越成熟,文本隐写已成为信息隐藏技术领域的研究热点之一。其中基于语义分析的同义词的替换技术是文本隐写中的重要技术之一。在文本的信息隐藏技术中,利用同义词替换技术查找隐藏载体,能更好地隐藏信息。因此,提升文本实体同义词的提取准确率和查全率至关重要。但同义词在文本中的分布大多都具有两个特点,一是以特定的句子模式的方法[1-2],二是分布在相似的上下文的方法[3,4,5]。前者用于推断两个词之间的关系,例如从句子“华夏子孙又叫为炎黄子孙”,可以推断出“华夏子孙”和“炎黄子孙”是同义词;从“中国和俄罗斯相邻”可以推断“中国”和“俄罗斯”不是同义词。然而,在实际应用中,许多同义词术语很少能够同时出现,导致查全率较低。后者词出现相似的上下文中,如“永远”和“永久”经常出现在相似的上下文中,可以判断它们是同义词。因此,基于上下文的方法通常表示词语的分布特征,需要通过上下文的关系来判断出现在相似上下文中的这一对词语是否是同义词。
而如今大多数同义词提取方法,只考虑其中一个特征来提取同义词,导致同义词的准确率较低,但在基于句子模式特征方法和基于相似上下文特征的方法提取同义词,在很大程度上是互补的。因此,本文将这两个特征组合起来提取同义词集,从而提升同义词的准确率和查全率。
1 研究现状
基于特定句子模式的方法是两个词同时在该句子模式中出现来推断两个词之间的关系。在早期的研究中,研究人员主要依靠选择句子模式来提取实体之间的关系。文献[1]提出了一种提取实体同义词模式的方法,并计算了该模式的置信度。文献[2]提出一种用于提取动词同义词的自动化模式构建方法,并将多个模式组合在一起提取实体同义词而不仅依赖单一的模式,从而提高了召回率。文献[7]提出了一种自动扩展模式,主要是在启发式搜索算法中利用每个实体的匹配数自动化扩展模式,并创建一个特征向量判别每一个实体的词义是否相同。但由于模式度量的可靠性的局限,文献[8]又提出利用通用模式提取语义关系。
基于上下文的方法认为具有相似上下文的词有较大的可能性是同义词。文献[9]提出利用依存句法提取同义词对应的二元依存关系,从大规模语料库中计算二元依存关系的向量距离,得出最佳替换的同义词集。文献[10]提出一种限制语义相似度损失的方法,将同义词典的分布特征转化为词向量进行同义词提取。文献[3]使用连续词袋模型训练词嵌入模型进行最小监督的同义词提取。
针对特定模式的方法得到的结果往往更准确,但由于生成所有模式比较困难,并且许多同义词有较大的可能性不会同时出现在句子中,所以提取的同义词个数会严重受限。而基于上下文的方法识别出的结果语义相似度的准确率较低,不能保证一个词的意思能完全被意思相近的另一个词替代,从而导致提取的同义词准确率较低,但个数相对较多。因此,本文采用将两个特征结合的方法提取同义词集。

图1 实体同义词集提取方法
2 同义词提取方法
2.1 基于句子模式特征的同义词提取方法
从文本可以发现,同义词通常使用特定的提示词来表示同义词之间的关系,如“简称”和“缩写为”。因此,利用模式特征来提高实体同义词提取的准确率,并利用词向量和信息熵相结合的方式生成提示词。T={T1,T2,…,Tn}表示同义词之间的一组模式,W={w1,w2,…,wn}表示T 中的所有实体名词,词wi的熵Ewi表示为:

其中L 和R 分别表示实体wi在一组模式中的左邻居和右邻居,Ewi的值越大,提示词wi越重要。利用大量实体同义词对进行标记句子,然后根据同义词对提取同义词之间的模式。由于在低维向量空间中计算两个词之间相似度的有效性已经得到证明。因此采用文献[11]中的Word2vec 模型进行训练,从而提取出句子模式的提示词。根据提取出的提示词,构建了如“x别称为y”的模式。对于特定模式的方法得到的结果往往会更准确,但由于生成所有的模式比较困难,并且许多同义词有较大的可能性不会出现在句子中,所以提取的同义词个数会受到限制。
2.2 基于上下文的同义词提取方法
在传统的向量模型中,当文本内容较多时可能产生维度爆炸现象,并且为了在具有相似上下文中得到的同义词词义更准确。因此,对基于模式提示词的方法中已经训练好的Word2vec 模型特征向量,采用文献[12]中考虑的词频对特征项的影响,对CHI 模型进行优化,优化后CHI 模型为:

TF-IDF 是用来估计一个词对某个文档集中的某个文档或整个语料库的重要程度,TF-IDF 值表示该词的重要程度会随着它在语料库中出现的频率成反比,会随着该词在指定文档中出现的次数成正比[13]。在改进后文本的向量空间,文本表征为一组特征项的集合,每个特征项都有对应的权值信息,表示该特征项的重要程度。设实体类别总数为N,则实体类特征向量为S(tk)={class1:wk1,class1:wk2,…,class1:wkn}维度为n。如果对于文本特征向量中的特征项tk同时属于多个类别,则将该词对应的类别设为1,否则设为0。用余弦相似度计算两个特征项ti和tj之间的相似度:

确定了特征项ti和tj的相似度,再对相似度高的特征项合并加权。假设特征项ti和tj得到的相似度为sim( S(ti),S(tj)),若ti的TF-IDF 值较大,tj的TF-IDF 值较小,表明主要表达的是特征项ti。最终利用加权后的余弦相似度计算每个相似词wi与目标实体e 的得分:

使具有较高余弦相似度的词得分高,以提高同义词提取的准确率,最终选择得分较高的前N 个词作为目标实体的同义词候选词。如目标实体为“世界”,可得到图2 所示的实体同义词。

图2 “世界”的同义词集
3 实验评估
本文采用开放的中文百科知识库作为数据源,其中互动百科和百度百科与维基百科类似,但比维基百科更大,是目前中国最大的在线百科全书。涵盖了地理、技术、教育、经济、科学和文化等领域大量的词条。百科全书中的条目包括“标签”,即条目所属的域。根据“标签”,分别从百度百科和互动百科爬取了14372和8823 个生活领域的中文网页作为文本数据集。
将基于句子模式的特征和基于相似上下文特征相结合的方法进行实验。在实验过程中,首先采用词向量原始文本数据集进行向量化,利用信息熵提取模式中的提示词。再利用训练好的Word2vec 模型,利用TF-IDF 对余弦相似度加权提取实体同义词,最后根据基于模式提取的提示词和基于相似上下文提取的实体同义词综合得分的方法提取得分较高的实体同义词。
在实际应用中,为了输出质量较高的同义词集,需通过准确率和查全率率对输出结果进行评估,但很难明确每个实体同义词的个数,因此,查全率采用每个实体的平均同义词数进行评估:

在实验过程中,采用基于句子模式的特征和基于相似上下文特征相结合的方法进行实验,提取表示职位的实体同义词集如表1。

表1 表示职位的同义词集
分别采用基于句子模式的特征与基于相似上下文特征和本文将两者结合的提取方法进行实验,并计算每个实体的同义词得分分别获得同义词的词个数和准确率如表2。
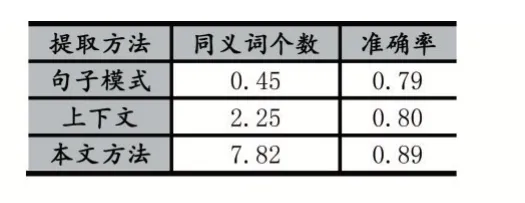
表2 中文文本实体同义词个数和准确率
从表2 可以得出,与单独使用基于句子模式的方法和单独使用基于相似上下文的方法相比,通过将两者结合的方法,在同义词个数上提升比较明显,达到了7.82 个。而在准确率上,与单独使用基于句子模式的方法相比较提升了10%,与单独使用基于相似上下文的方法相比较提升了9%。实验结果表明,采用将基于句子模式特征的方法和基于相似上下文特征的方法相结合的方法提取的实体同义词个数和准确率上更优。
4 结语
本文结合了同义词分布基于模式的特征和基于上下文的特征,对百度百科和互动百科中的目标实体提取同义词。针对句子模式特征,我们采用词向量和信息熵来提取模式中的提示词,针对上下文的特征,对基于句子模式的方法训练好的向量空间,合并词义相近的特征项降维,利用词频对特征项词义的余弦相似度进行相似度加权来提取实体同义词。与单独使用基于两个特征的方法相比,经实验验证,该方法具有更高的提取准确率和查全率。
在下一步工作中,需要考虑结合中文文本的汉语特征和不同实体个数对文本中同义词提取结果的影响和计算性能上进行优化,进一步提高实体同义词的提取准确率和计算性能。
