稀疏奖励下基于MADDPG 算法的多智能体协同
2020-07-07许诺杨振伟
许诺,杨振伟
(四川大学电子信息学院,成都610065)
0 引言
采用深度强化学习算法[1-3]研究多智能体系统时,不可避免地要面对多智能体环境中的非平稳性问题[4],这将使得深度强化学习算法[5]失去收敛性的保证。因此,提出一个既能解决环境非平稳性问题,又能够简化训练,促进多智能体学会协同策略的算法和训练框架是非常有必要的,也是进行深入研究的前提和基础。MADDPG 算法[4]采用了一种中心化训练-去中心化执行架构解决了环境的非平稳性问题,本文针对多智能体合作导航场景,对其进行改进,引入了神经网络参数共享机制[6]。本文认为带神经网络参数共享的MADDPG 算法,能够大量减少待训练的网络数量和网络参数,降低了网络的复杂度,加快训练速度。
奖励函数在强化学习中是非常重要的[7],它提供了环境中对智能体行为的唯一反馈,直接决定了智能体是否能学到目标策略,并影响算法的收敛性和最终的实现效果。本文针对某些多智能体协同场景中,无偏的连续奖励函数设计困难,提出一种基于群体目标状态的奖励函数。虽然这种奖励函数更加准确,但也由此带来了奖励稀疏性问题,这将严重影响智能体的训练效率,经验缓存器中大量的无意义样本会导致智能体无法学会任何协同策略。在单个智能体领域,基于优先级的经验重放方法[8]通过赋予经验缓存器中“高价值”样本以更高的采样权重,特别在稀疏奖励场景中,取得了较好的效果。本文将带优先级的经验重放方法扩展至多智能体环境中,在基于群体目标状态的奖励函数下,结合带有优先级的经验重放方法,可以训练出稳定的协同策略。本文在不同智能体数量的合作导航场景中进行了仿真实现,展示了方法的有效性。
1 基于参数共享的多智能体训练架构
采用强化学习方法研究多智能体系统时,最极端的训练架构是完全中心化架构[9],将一个协作场景下的多智能体系统建模为一个单智能体(Meta-agent),输入是所有智能体状态的拼接,输出是所有智能体的联合动作,采用单智能体强化学习方法处理。然而,这个Meta-agent 的状态空间和动作空间的维数随着智能体数量的增加而指数级增长。另一种训练架构是去中心化架构,每个智能体被独立于其他智能体进行训练,即将其他智能体都视为环境的一部分,独立维护自己的价值函数网络或策略函数网络。尽管这一架构下,神经网络输入维度不会随着智能体数量增长而增长,可扩展性好。但是,去中心化架构下智能体之间缺乏显式的合作,同时由于多智能体环境的非平稳性造成训练效果差。目前,比较最有效的训练范式是结合中心化架构和去中心化架构的优点,采用中心化训练-去中心化执行架构[4,10],其中最具代表性的是2017 年OpenAI 提出的一种基于Actor-Critic 算法[11]的变体:MADDPG 算法。MADDPG 算法解决了多智能体环境中的非平稳性问题,在许多混合合作和竞争的高维连续状态空间的场景中都表现良好。本文在MADDPG 算法基础上,针对完全合作的任务场景,加入了网络参数共享机制。具体实现形式是:将原本分布式的Critic 网络改进为集中式,所有智能体共享一个Critic 网络,原本分布式的Actor 网络依然分布式设计,但全部Actor 共享底层网络参数,如图1。引入网络参数共享后,既减少了网络中待训练的参数,降低网络的复杂度,又能促进智能体间产生类似行为,利于合作。
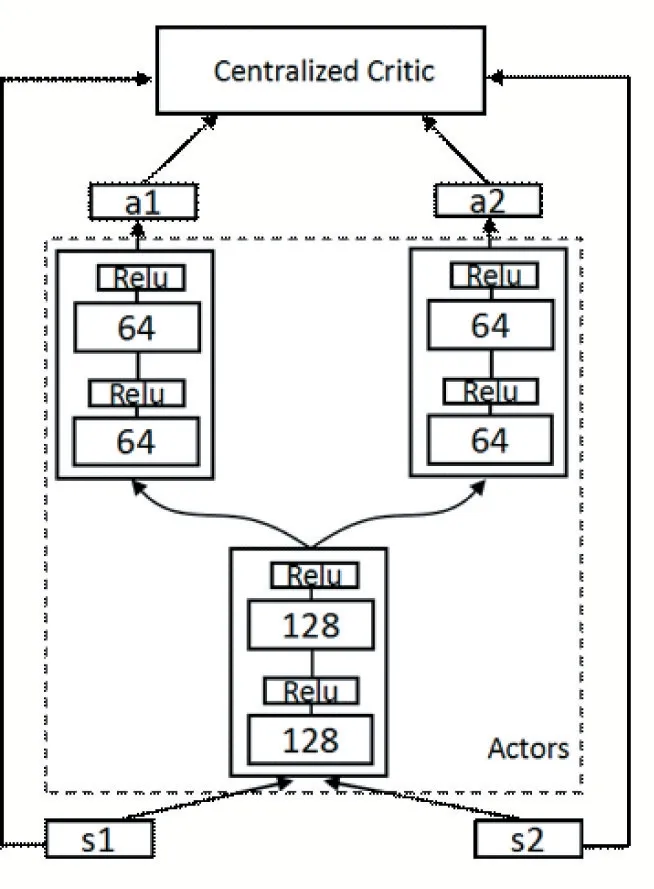
图1 加入神经网络参数共享机制的网络结构
2 基于群体目标状态的奖励函数
2.1 多智能体环境中奖励设计难点
强化学习中,奖励函数可以视为一种特殊语言,将期望实现的目标任务数学化,实现了环境与算法之间的沟通。在大多数单个智能体问题中,一般将奖励函数设计成基于某个变量(距离、时间等)的函数,在这种连续函数的引导下,智能体能很快探索到目标,训练速度和算法收敛性都很好。但是,扩展至多智能体环境时,特别在任务复杂度较大的场景下,这种奖励函数就很难再有良好的效果了。本文总结了在合作导航场景中,奖励函数的设计尤其存在以下两个难点:
(1)无偏的连续奖励函数设计困难
在合作导航场景中,连续的奖励函数在每一步需要考虑每个智能体与全部目标点的相对距离,这就使得奖励函数非常复杂。并且,这种奖励函数是不够准确的,奖励函数引导下的最优,不一定是我们期望实现的策略。可能场景中存在一个点,相比于智能体在目标点邻域内时,与全部目标点的距离之和更小,
这种复杂且不够精确的引导式连续奖励函数,使得训练只能收敛至局部最优。
(2)多智能体信用分配问题
协同场景下设计一个离散的全局奖励,每个智能体在当前动作下获得奖励或惩罚经过累加后,由全部智能体共享。这种方式容易造成多智能体信用分配问题[12-13],产生“Lazy”智能体[14]。即当群体中某些智能体表现很好时,全部智能体都会获得奖励,此时,另一些智能体就会放弃探索而维持当前状态,因为探索是有风险的,而保持当前状态能获得奖励。
本文提出的基于群体目标状态的奖励函数,旨在解决以上两个问题。由于期望实现的最终目标状态是明确的,当全部智能体都处于目标状态时,才能获得奖励。一方面,这大大简化了奖励函数的设计,另外,这种方式下,只有单个智能体到达目标状态是没有意义的,需要全部智能体都到达目标状态才能获得奖励,这就避免了出现“Lazy”智能体。合作导航场景中,只有当N 个智能体完全覆盖N 个目标点时,才给予一个正的奖励,只有单个目标点被覆盖不会获得奖励。于是,基于群体目标状态的奖励函数为:

显然,基于群体目标状态的奖励函数下,正的奖励值是稀疏的,智能体的经验重放缓存(Replay Buffer)中会充满大量0 奖励的经验样本,这对于训练来说是非常不利的。本文扩展基于优先级的经验重放方法到多智能体环境中,使得经验重放缓存中有意义的样本有更大的概率被采集,提高训练速度。
2.2 多智能环境中采样优先级方法
带有优先级采样方法会根据模型对当前样本的表现情况,给予样本不同的采样权重,打破了传统的均匀采样方法,提高了样本的利用率和学习效率。相比而言,带优先级的经验重放主要额外增加了以下两步:
(1)样本优先级的设置;
(2)基于优先级的采样。
样本优先级可以采用强化学习中TD 偏差来衡量:



在本文采用的带有网络参数共享机制的MADDPG算法下,对集中式的Critic 网络训练过程中采用带优先级的采样方法,具体训练流程如图2。
TD 偏差越大,说明智能体在该状态处的参数更新量越大,该样本的学习价值越高。设经验样本i 对应的TD 偏差为δi,对该经验样本的采样概率为:

图2 对集中式Critic带优先级采样的训练流程
3 仿真实验
在合作导航场景,设置环境状态空间为二维连续状态空间:
space.Box(-1.0,+1.0,(2,2),np.float32))
结合状态空间的大小,规定当智能体进入目标点的半径为0.1 的领域内时,认为该目标点被该智能体覆盖。只有全部目标点都被唯一覆盖时,认为协同任务成功。如图3 所示。
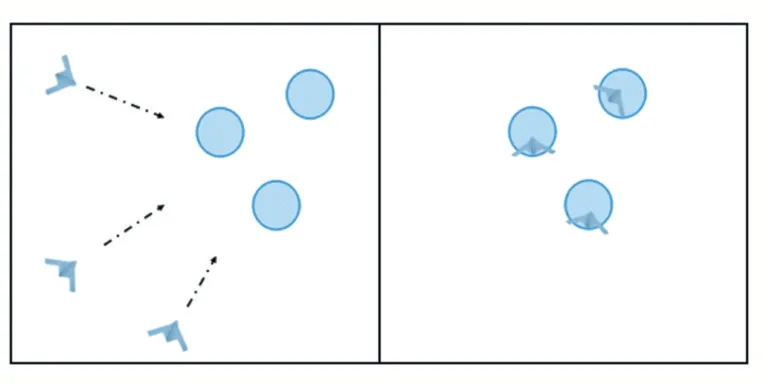
图3 合作导航场景示意图
为了避免智能体陷入无意义的探索,设置每回合最大30 步长,即智能体经过30 次状态-动作决策后,不论是否完成任务都结束本回合的探索,环境初始化,重新开始下一回合的探索。
第2 章中已经说明,基于距离的连续奖励函数存在设计缺陷,训练后的智能体只能收敛至局部最优。因此,本文采取的对比方法是累加个体奖励值的全局奖励函数,在合作导航场景中,当单个智能体唯一覆盖一个目标点时,获得一个奖励值。由于是智能体之间是合作关系,于是累加各个智能体的奖励值作为全局奖励,所有智能体共享这个全局奖励:
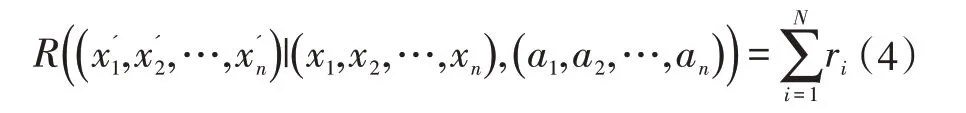
实验采用带网络参数共享的MADDPG 算法,比较不同智能体数量场景中,均匀采样和基于优先级采样两种方式下,本文提出的基于目标状态的奖励函数和累加个体奖励值的全局奖励函数下,平均每回合内协同任务成功次数,如图4。
图4 表明,采用基于目标状态奖励函数结合带优先级的采样方法时,能够实现任务协同,取得较好的训练结果。特别是在4Agents-4Targets 场景下,由于智能体数量增加,任务的复杂度增加,累加个体奖励的全局奖励函数会因为出现“Lazy”智能体,导致无法完成目标任务,而本文所提出的奖励函数则不会出现这种情况。但本文所提出的基于目标状态奖励函数必须结合带优先级的采样方法,否则会因为“高价值”样本稀疏,导致均匀采样下训练的智能体无法学会任何策略。

图4 合作导航场景中,平均每回合内任务成功次数
图4 中,曲线A、B、C、D 对应采用的方法如表1。

表1 各条曲线对应训练时所采用的方法
如图5 所示,本文发现了一个有意义的现象:从图A 至图B 可以发现,智能体1,2,3 都有靠近右边目标点的运动趋势,但任务奖励要求目标点只能被唯一覆盖。随着时间步的推移,智能体1,2,3 似乎发现了这个问题,智能体1,2 观察到智能体3 更靠近这个目标点,于是它们立即改变自己的策略,往其他附近没有智能体的目标点移动,如图C 所示。这一过程中,智能体1,2,3 都没有覆盖某一目标点,它们只是通过观察当前的局势和队友的移动趋势,临时调整了自己的策略,这种临时调整策略的能力不是用奖励函数引导的,而是自身在与环境交互中涌现出来的。
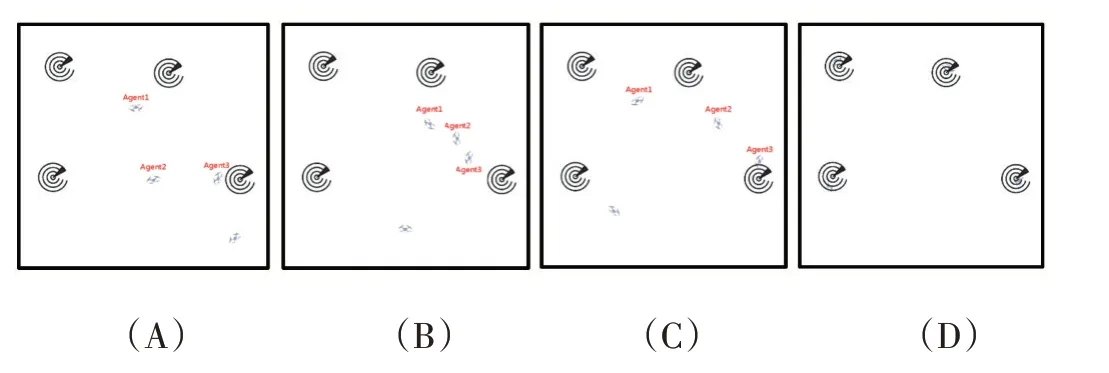
图5 经过30000eposides 的训练后,4 个智能体合作导航实现效果
4 结语
本文提出了一种带有网络参数共享机制的MADDPG 算法,在此基础上针对多智能体合作场景中奖励函数设计难题,提出了一种基于群体目标状态的奖励函数,并进一步把带优先级的经验重放方法引入多智能体领域。最后在不同智能体数量的合作导航场景中,证明了在带有网络参数共享机制的MADDPG 算法下,本文提出的基于群体目标状态的奖励函数结合带优先级的经验重放方法能够取得很好的效果。
