基于智能电表大数据的异常用电检测
2020-07-06潘磊杨延连浩方龙泉
潘磊 杨延 连浩 方龙泉


摘 要:异常或欺诈造成的非技术性电力损失是电力公司损失的主要源头之一。智能电表的广泛使用,使得运用大数据方法实现对非技术性电力损失的有效检测成为可能。提出了一种使用监督学习进行非技术损失检测的方法。该方法基于智能仪表记录的所有信息(耗电量、异常警报等)结合辅助数据库所提供的有关每个智能电表的地理位置和技术参数的附加信息,使用最优的机器算法来深入分析用电客户的用电行为,生成异常用电客户列表。通过现场检查的结果表明,该方法能够较为准确地识别智能电网中所存在异常用电客户。
关键词:监督学习;非技术损失;智能电表;超梯度提升树
中图分类号:TP391 文献标识码:A
文章编号:1003—6199(2020)02—0177—07
Abstract:Non-technical power loss is one of the main sources of power company abnormal losses. The wide use of intelligent meters makes it possible to effectively detect non-technical power losses by using big data. A supervised learning method for non-technical loss detection is proposed. Based on all the information recorded by intelligent meters (power consumption,abnormal alarm,etc.) and the additional information about the geographical location and technical parameters of each smart meter provided by the auxiliary database,the method uses the optimal machine algorithm to analyze the power consumption behavior of power customers in depth,and generates a list of abnormal power users. The results of on-site inspection show that this method can accurately identify abnormal customers in smart grid.
Key words:supervised learning;non-technical loss;smart meter;extreme gradient boosted trees
由于电表安装错误、电表参数化错误,电表故障或窃电行为所导致的非技术电力损失(NTL)不仅会造成电力公司巨大的收入损失,而且还会影响耗电量测量的不确定性以至于影响电力系统的稳定运行[1-3]。因此降低NTL是电力公司希望迫切解决的问题,由于智能电表(SM)已经得到普及,使得电力公司设计基于智能电表所采集的大数据来检测NTL成为可能。为此,提出了一种使用SM数据和辅助数据库来确定客户用电行为的各种特征,并结合有关SM的地理位置等附加信息,采用监督机器学习算法对这些特征进行分类,最终生成一个异常用电客户列表。通过使用实际数据对模型进行训练、验证和测试,表明該NTL检测数据模型具有优于其他分类算法的良好性能。
1 NTL检测方法
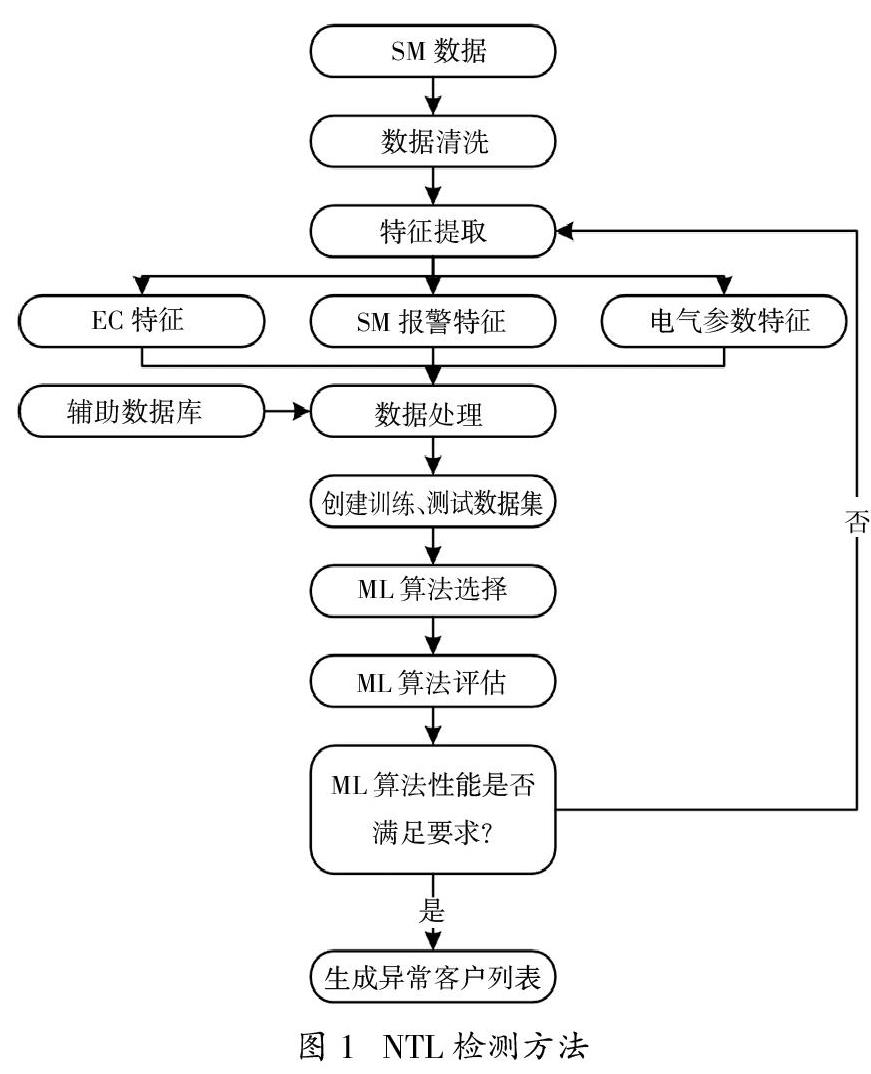
所述方法的主要目的是根据电力公司的智能电表出现异常的概率,为用电客户提供一份异常排名表。该方法中使用SM数据进行特征提取的算法流程如图1所示。所提取的特征主要SM报警数据、电能消耗数据(EC)和电气参数测量数据,以及从辅助数据库中提取的地理信息和智能电表技术参数。在对数据集进行预处理后,将这些特征作为输入插入到多个机器学习(ML)算法中,用于算法选择和评估。如果评估最优的算法性能满足所需的标准,则会保存其参数,并用于预测新客户样本,获得最终输出的客户排名列表。
2 智能电表(SM)数据
使用北京市供电公司提供的SM数据进行模型训练、验证和测试。所研究的SM数据客户包括工业和大型商业客户。智能电表具备每15分钟记录一次EC的性能,但为了减少数据处理量以及避免可能出现的侵犯客户隐私问题,数据采样频率降低到5次/天。所采集的SM数据中包含的测量内容如表1所示。
根据所采集的SM数据评估检测模型的性能。被检测的客户用电数据则根据不同采样周期被分成多个目标样本,如图2所示。
所使用的监督机器学习(ML)方法,通过使用这些类型客户的所有现场检查结果来验证学习结果。训练数据集是通过对被检测客户的用电数据采样而创建的。该数据集被用来训练一个ML算法,以发现异常用电的特征模式。
排名列表是为从未进行过检测或上次检测时间超过90天前的客户创建的,如图2所示。这个列表是通过使用一个经过训练的模型对那些客户用电样本进行预测而获得的。目标客户数量如表2所示。
3 SM数据的特征提取
使用SM数据中质量字节(QB)开发出可以提取有关电表故障或数据篡改特征的功能;使用SM数据中EC测量数据提取用电量的异常下降的特征。
3.1 从QB中提取的特征
在IEC 870-5-102协议中,QB使用8位bit來生成智能电表报警信息[4]。表3显示了QB的警报类型。其中一个二进制字节被分成八个单独的bit位,每个bit代表一个警报类型。如果在测量期间(文中是一天)触发了警报,则其值将设置为1;否则,其值将为零。
3.2 从EC测量中提取的特征
对于大多数窃电相关的异常,通常可以表现为EC的突然减少[5]。但是,如果EC的异常减少在检测之前开始,则无法捕捉。因此需要引入聚类技术以捕捉这种异常的用电行为。
为了避免测量误差,测量日类型t分别为工作日、周六和周日,公共假期期间所采集的测量值则被删除。特征的计算周期n分别为15天、30天、45天、60天和90天。表4显示了可以使用Zscore所得出的特征。
EC测量还可用于检测智能电表故障。 每组测量的时间戳可用于计算在最近n天内接收的测量数量。这些数据可以向ML模型通知某个SM的最近n天中缺失测量的数量。此外,SM数据还可以用于获取用电量为0 kW/h的用电客户。
由于在分析期之前已经开始的用电异常减少的情况无法采用上述办法发现,因此必须采用聚类技术提取异常用电特征。
为了发现可能的异常用电客户,使用每个客户样本中的约定功率创建客户分类。这些分类是使用k-均值聚类算法创建的。所创建的最佳分类簇数为25。
为了实现对异常客户的分类,本文采用了基于距离的分类方法[6]。该方法是基于每个客户用电量生成基础用电模式,然后依据基础用电模式对客户进行分类,最后根据客户的用电模式和基础用电模式的距离来生成异常用电特征。在使用每个客户的用电量实现客户分类后,为每个月的用电分析创建了基础用电模式。每个客户分类的基本用电模式都是使用属于该分类的所有非异常客户样本的EC创建。
式2中Bk i,j,t是为t日(工作日、周六、周日)客户群k的第i个月、第j年的基本用电模式。M表示属于客户群k的客户集合,其具有没有检测到异常的检查,而N是这些客户的数量。PIt、PIIt、PIIIt、PIVt和PVt为采样时间窗期间的t日的平均用电量。
在为每个客户分类创建基础用电模式之后,使用基础模型和客户用电模型之间的距离,为每个客户样本计算了以下几个特征值。
对于每个客户样本,通过平均上个月的工作日和周末的用电量,创建了两种用电模式。
其中Ct代表用电模式,PIt,PIIt,PIIIt,PIVt和PVt是上个月t日的平均用电量。
通过计算客户样本的每种用电模式与其基本用电模式之间的欧几里德和曼哈顿距离可以得出客户独有的用电特征[7,8]。其中曼哈顿距离是针对每个单独的时间范围以及整天计算的,而欧几里德距离是使用所有时间窗口计算的。
其中,Mwt是时间窗w和t日的客户样本的曼哈顿距离,MTt是所有时间窗的曼哈顿总距离。
使用所有时间窗计算的欧几里得距离为:
其中,ETt是所有时间窗的总欧氏距离。使用距离测量获得的特征如表5所示。
4.3 从电气参数中提取的特征
使用电气参数(EM)开发的特征旨在主要检测诸如相位反转和分流(三相客户)之类的窃电行为。电气参数在三个时间范围(上午9点至下午6点,晚上7点至晚上10点,晚上11点至上午8点)进行采样。使用每个时间帧内的最后一个采样值来计算特征。表5显示了使用EM开发的用电特征。
4 从辅助数据库中提取的特征
由地理信息系统(GIS)等相关的应用程序和电力营销数据库中获取如表6中所述的客户用电特征。
地理信息系统(GIS)数据不仅提供了客户的位置信息,还提供了附近地区的NTL信息。设备数据库提供有关智能电表技术参数信息。营销数据库则提供了客户的用电规模、用电类型以及计费费率等相关信息。
5 模型的选择和评估
针对不同的数据集需要采用不同的分类模型能够取得更好的额分类性能。因此本研究在NTL检测方法中采用基于ML算法的评估选择最优的分类模型。为了评估ML算法的性能,将目标训练数据集分为训练数据集、验证数据集和测试数据集。验证数据集用于调整模型的超参数,而测试数据集用于评估模型的分类效果。
所使用模型选择和评估方法如图3中所示。鉴于异常用电样本的稀缺性,选择嵌套交叉验证(NCV)以尽可能多地利用可用数据[10,11]。交叉测试用于模型评估阶段。
由图3可以观察到,与其他传统方法相比,NCV是一种计算成本较高的方法。然而,该方法的主要优势在于提供了对真实误差几乎没有偏差的估计。
在使用ML算法提取上述特征之前,首先对数据集进行如下几个预处理步骤:(1)将每个特征标准化为零均值和单位方差;(2)使用一个热编码将分类变量转换为数值变量;(3)连续特征的缺失值用平均值代替,离散特征的缺失值用最频繁的值代替。
对于模型选择和评估,使用5倍嵌套交叉验证。由于计算的限制,超参数的模型选择是利用数据集里面所有客户。SciKit-learn库[12]用于使用SVM、逻辑回归和K- Nearest Neighbors(KNN)拟合模型。XGBoost[13]的模型拟合是使用其python API完成的。
5.1 模型选择
在模型选择过程中,使用NCV的内环来选择在验证数据集上获得最佳结果的超参数。采用网格搜索方法对超参数进行了优化。
1)K-Nearest Neighbors(KNN)算法:KNN是最简单的分类算法之一。它在测试时使用训练数据来查找最近的邻居。在测试场景中,为了获得新客户的异常概率估计,算法会查看现场检查的结果。因此,需要对最近邻居的现场检查结果进行平均,以便计算新客户的概率。
表7显示了网格搜索期间使用的超参数。在聚类(K)为16和幂参数(p)为2时获得最佳结果,该结果等于欧氏距离。
超参数C表示正则化强度的倒数,用于控制训练过程中模型的过度拟合。超参数R表示正则化的类型,取值范围为L1和L2。用0.01的C值和L2正则化得到了模型验证的最佳结果。
3)支持向量机(SVM)算法。SVM是常用的异常检测分类器。与其他算法不同,SVM不预测概率估计,而是预测决策值。
SVM算法将输入特征引入高维空间,并尝试寻找最优超平面,使两类向量之间的边界最大化。这个界限将由类的支持向量决定。支持向量是来自训练数据集中最接近决策功能的客户样本。
表9显示了网格搜索SVM时使用的超参数。超参数C与逻辑回归算法参数相似,表示正则化强度的倒数。如果客户聚类在高维空间中不能被超平面线性地分离,那么内核参数是有用的。当C为0.001以及使用线性核函数时得到了模型验证的最佳结果。
4)XGBoost(超梯度增强树,Extreme Gradient Boosted Trees)是常见的ML算法之一。该算法通过结合许多弱分类器的预测来实现强分类。文中XGBoost的分类器是CART回归树。
该模型仅使用一个回归树开始训练过程。此回归树正在寻找一组规则,这些规则尽可能地将具有和不具有异常的客户分开。 在构建第一棵树之后,模型会在每轮训练中添加一个新的回归树。在每一轮中,模型都会查看前一棵树预测不佳的位置,并使用一组规则构建一个新树,这些规则将纠正前一个树的错误。
表10显示了在XGBoost的网格搜索期间使用的超参数。使用以下超参数获得XGBoost的最佳结果:学习率为0.01,最大深度为15,最小子权重为1和2000个回归树。
5.2 模型评估
用于评估ML算法模型性能的最常用指标之一是准确性。然而,算法对严重不平衡数据集的准确性无法提供对其预测能力的真实评估。因此本文使用AUC得分作为评估指标。该指标表现为真正率随着假正率的增加而增加的速度。通过改变决策阈值,可以在接收器操作特征(ROC)曲线上观察到真正率和假正率之间的折衷。
图4顯示了在研究的每个分类模型在评估期间获得的ROC结果。可以看出,XGBoost优于其他分类模型,而KNN获得最低性能。试验使用朴素贝叶斯分类器的性能作为测试基准。
为更好地评估每种算法的性能,绘制试验中每个分类器的精确率-召回率曲线(PRC),如图5所示。与ROC曲线一样,通过改变概率估计的判定阈值来获得PRC。 由图7可知,与其他分类器相比,XGBoost在RCL达到40%时,其PRC可以达到约70%,因此表现出相对其他分类算法更好的性能。
在配置3.9 GHz Intel Core i7 CPU的电脑进行算法计算效率的评估。四种机器学习算法训练和测试期间的执行时间如图6所示。可以看出,逻辑回归算法是运行最快的算法。
6 仿真对比
将所提出的检测方法与其他四种检测方法进行对比。试验数据集如表2所示。试验平台为配置3.9 GHz Intel Core i7 CPU的电脑。对比结果如表11所示。
对于从一开始就检测到NTL的性能是在无法观察到用电量下降的前提下评估算法对客户异常用电行为的检测性能。方法1和方法2是通过ML算法对用电数据进行聚类分析实现NTL检测,并没有对类似客户的用电行为进行任何比较,因此无法实现从一开始就检测到NTL。方法3中的方法在不使用任何集群技术的情况下,将客户用电量与平均用电量进行比较,因此具有良好的从一开始就检测到NTL的性能。方法4通过对地理数据、变压器和消费概况进行k-均值聚类,对客户进行了彻底的比较,因此也具有较好的从一开始就检测到NTL的性能。对新类型NTL检测适应性与特征类型的多样性以及EC度量的粒度有关。方法1和方法2只使用每月的EC和地理数据,因此很难检测到新类型的NTL。方法3和方法4使用更广泛的异常特征,因此能检测更多类型的NTL,然而低粒度的EC采样值使得其难适应突发性的NTL,如间歇性欺诈。本方法采用了更高测量粒度的EC增加了对新类型NTL的检测适应性,缩短了检测延迟,但是降低了客户的数据隐私。在仿真试验中,本方法取得了最高的AUC分数,这表明本方法具有最好的检测准确性。此外,在现场检查的准确性验证中,所生成的异常客户列表达到了21%的精度。
7 结 论
提出了一种基于智能仪表数据和辅助数据库作为原始数据的非技术性损失检测方法。在模型训练过程中,经过检查的客户特征被用来训练算法参数。该方法已经在北京供电公司的真实数据上进行了测试,获得了0.91的AUC分数,具有较好的检测准确性。
参考文献
[1] 许立武,李开成,罗奕. 基于不完全S变换与梯度提升树的电能质量复合扰动识别[J]. 电力系统保护与控制,2019,47(06):24-31.
[2] 李汉巨. 基于非监督学习的恶意欠费用电客户识别[J]. 信息技术,2019(03):33-36.
[3] 柳林溪,陈泰屹. 在智能电网中进行用户异常用电行为辨识的研究[J]. 信息技术,2018,42(12):97-102+107.
[4] 赵文清,沈哲吉,李刚. 基于深度学习的用户异常用电模式检测[J]. 电力自动化设备,2018,38(09):34-38.
[5] 李春阳,王先培,田猛. AMI环境下异常用电检测研究[J]. 计算机仿真,2018,35(08):66-70.
[6] 陈启鑫,郑可迪,康重庆.异常用电的检测方法:评述与展望[J]. 电力系统自动化,2018,42(17):189-199.
[7] 张小斐,耿俊成,孙玉宝. 图正则非线性岭回归模型的异常用电行为识别[J]. 计算机工程,2018,44(06):8-12.
[8] 郭志民,袁少光,孙玉宝.基于L0稀疏超图半监督学习的异常用电行为识别[J]. 计算机应用与软件,2018,35(02):54-59.
[9] 苏适,李康平,严玉廷,等,王飞,董凌. 基于密度空间聚类和引力搜索算法的居民负荷用电模式分类模型[J]. 电力自动化设备,2018,38(01):129-136.
[10] 孙毅,李世豪,崔灿. 基于高斯核函数改进的电力用户用电数据离群点检测方法[J]. 電网技术,2018,42(05):1595-1606.
[11] 王守相,刘天宇. 计及用电模式的居民负荷梯度提升树分类识别方法[J]. 电力系统及其自动化学报,2017,29(09):27-33.
[12] 许刚,谈元鹏,戴腾辉. 稀疏随机森林下的用电侧异常行为模式检测[J]. 电网技术,2017,41(06):1964-1973.
[13] 田力,向敏. 基于密度聚类技术的电力系统用电量异常分析算法[J]. 电力系统自动化,2017,41(05):64-70.
[14] VIEGAS J L,ESTEVES P R,MELCIO R,et al. Solutions for detection of non-technical losses in the electricity grid:a review[J]. Renewable and Sustainable Energy Reviews,2017,80:1256-1268.
[15] LEITE J B,MANTOVANI J R S. Detecting and locating non-technical losses in modern distribution networks[J]. IEEE Transactions on Smart Grid,2016,9(2):1023-1032.
