复杂化工系统的可靠性评估研究
2020-06-24赵凡锐赵元沛孙仲平
赵凡锐,赵元沛,孙仲平,周 利,吉 旭
(1.四川大学 化学工程学院,四川 成都 610065;2.重庆大学输配电装备及系统安全与新技术国家重点实验室,重庆 400044)
当前工业生产过程正日益向大型化和复杂化发展,HSE(Health,Safety,Environment)评估模型已成为企业通过智能化措施保持持续发展的重要模式[1-2]。系统可靠性(System reliability,)是评估企业HSE状态的重要因素之一[3-4], Saleh和Marais研究了复杂系统的可靠性理论[5],Graves等人利用全贝叶斯方法根据多状态及多层次信息传递特点构建系统故障树[6],刘文等人建立了面向故障的可靠性模型,用于评估化学系统的安全性、环境性和经济性[7],李总根总结了基于概率统计的常规可靠性评估进展,给出了基于信息理论的复杂系统可靠性多层次模型[8]。
然而对于具有多输入、多输出、非线性、数据高维等特点的复杂化工系统[9],传统的基于物理模型的方法已经难以进行有效评估。随着先进技术的逐步应用,计算机建模为开发更有效的系统可靠性评估方法提供了机会,神经网络模型已成为此类复杂化工系统的研究重点。Liu等人提出了一种GRA-GA-BP-MCRC的混合算法[10],其中灰色关联分析(GRA)用于指标体系的降维,GA-BP为模型的训练及预测算法,马尔科夫链残差校正(MCRC)用于预测误差的校正。神经网络模型对于有足够数据水平的复杂系统是可行的,但是化工系统通常仅在短时间内稳定,来自化工系统的数据通常是小样本。小样本的数据通过神经网络方法难以达到较好的预测效果。近年来,智能算法逐渐应用于可靠性评估的问题。Nieto等人建立了一个基于PSO-SVM的混合模型,用于预测飞机发动机的剩余使用寿命并评估其可靠性,这是在可靠性领域的成功探索[11]。Benali等人比较了运用人工神经网络和随机森林算法预测太阳辐射组成,发现随机森林算法的预测精度要好[12]。
基于此,本文建立了PCA-RF混合预测模型,利用随机森林算法(RF)所需样本小、泛化能力强的特点实现可靠性的预测,主成分分析法(PCA)主要用于指标体系的约简,以达到简化运算提高预测精度的目的。
1 背景理论简介
1.1 主成分分析法
主成分分析法(Principal component analysis,PCA)是一种提取特征或提取有效信息的方法。在实际的问题研究中,为了全面的反映某一问题,必须考虑影响该问题的众多因素,这些因素称为指标,也叫变量。通常这些变量间存在着一定的相关性,因此反应的信息也有部分重叠,而且众多的变量也会增加问题的复杂度,降低模型收敛速度等。因此在研究变量时,理想的方法就是用最少的指标来反映最多的信息,PCA方法就是研究此类问题的理想工具。PCA方法是在保证损失最少信息的前提下,将影响问题的变量线性组合为几个综合指标,即主成分,这些主成分不仅保留了原始变量的主要信息,而且相互之间不存在相关关系,避免了信息的冗余,达到简化模型的作用。
1.2 随机森林算法
随机森林算法(Random forest,RF)是一种集成学习方法[13]。集成学习方法是一种将个体学习器通过某种策略集成为一个强学习器来完成学习任务的方法。随机森林是一种以决策树为基学习器Bagging集成方法的组合算法。
Bagging是并行式集成方法的典型代表。它通过自助采样法(bootstrap)进行重采样,设给定含有m个样本的数据集,从样本数据集中随机抽取一个放入采样器中,然后再把该样本数据放回原数据集中,这样下次抽取的时候该数据还有被抽中的可能,经过m次这样有放回的抽取,得到了一个含有m个样本的采样集。这种抽样的结果是,有的数据被多次抽中而有的数据则一次都没被抽中,有数据表明,这种重采样技术每个样本被抽中的概率是63.2%。
按照上述方法抽取T个含有m个样本的采样集,针对每一个采样集,训练一个基学习器,然后把这些基学习器组合起来进行输出,这就是Bagging集成方法的基本流程。对于分类问题,基学习器之间的组合方式就是简单投票法,对于回归问题,基学习器之间的组合方式是简单平均法。
随机森林是Bagging集成技术的一个变体。随机森林在以决策树为基学习器Bagging集成的基础上,加入了随机属性的选择。通常决策树在选择属性划分时是在当前结点所有的属性中(假设有d个属性)选择一个最佳属性,而随机森林中的基决策树在选择属性划分时,从当前结点的属性集合中随机选择k个属性进行划分。参数k决定了随机属性的引入程度,当k=d时,随机森林中的基决策树与普通决策树一样,进行全特征属性的划分;当k=1时,则是随机选择一个属性进行划分,一般情况下,。
随机森林算法的流程图如图1所示:
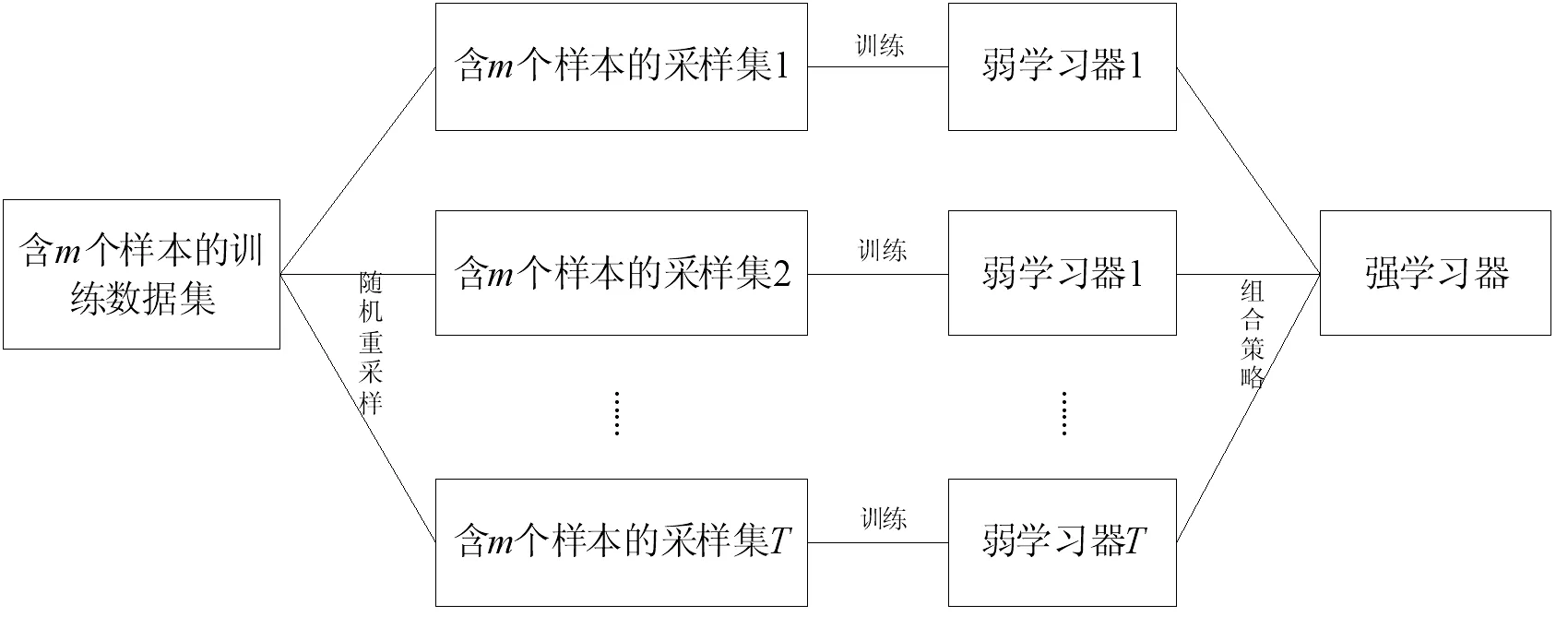
图1 随机森林流程图
随机森林具有算法简单、容易实现、计算开销小等特点。大量的研究和实践表明,随机森林算法具有很好的预测效果,泛化能力强,并且能够适应异常值和噪声值,即使是数据损失也能够保持较高的预测效果。
2 基于PCA-RF混合算法的可靠性评估模型
以复杂化工系统为研究体系,以系统可靠度为研究对象,由影响系统可靠性的影响因素来预测化工系统的可靠度是本研究的主要内容。
2.1 可靠性评估指标体系的4M1E分类法
在进行化工系统可靠性评估模型构建前,首先要确立可靠性评估指标体系,影响化工系统可靠性的因素众多,不仅要考虑设备发生故障的总频次、造成停车的总时间,还涉及到环境因素、人为因素等,因此指标体系涉及到的因素众多。本文将企业运行和现场管理的4M1E模型,即人员(Man),机器(Machine),物料(Material),管理方法(Management),环境(Environment)五个要素,应用于化工系统可靠性评估指标体系的构建,这五个方面基本涵盖了化工生产的各个方面,能较全面且系统的反映化工生产的各个环节。具体指标如表1~表5。

表1 人员模块相关指标
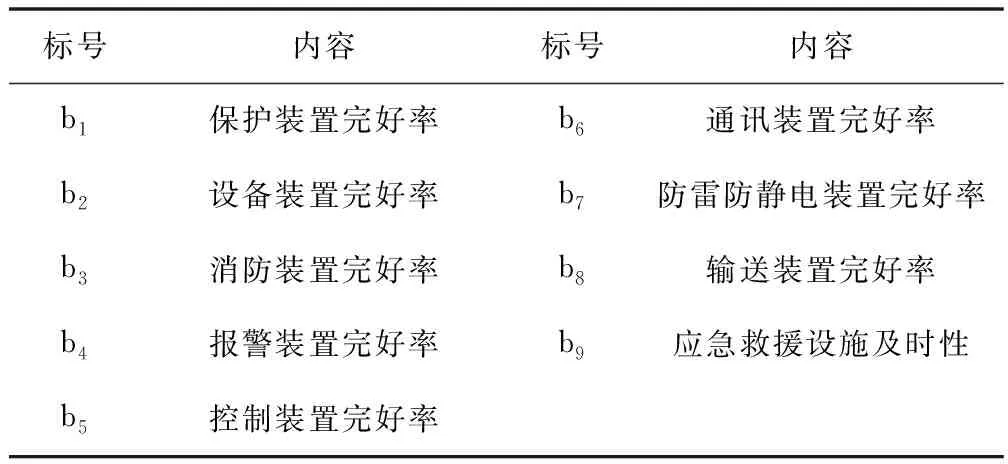
表2 机器模块相关指标

表3 物料模块相关指标
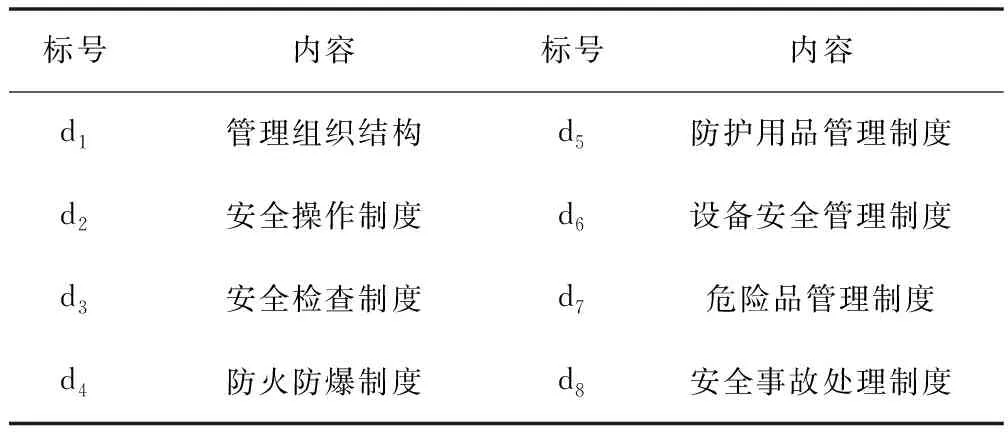
表4 管理方法模块相关指标

表5 环境模块相关指标
综合人员,机器,物料,管理方法和环境因素,共产生37个影响因素指标,这37个指标基本涵盖了复杂生产操作系统所有的环节。
2.2 两步法PCA-RF混合算法预测模型
在构建了影响系统可靠性的指标体系后,接下来进行系统可靠度预测模型的构建,提出用两步法PCA-RF混合算法模型来实现化工系统可靠度的预测。第一步,首先预测按照4M1E分类法得到的五个子系统的评价值;第二步由预测得到的五个子系统的评价值作为输入来预测整个系统的可靠度。两步法的拓扑图如图2所示。主成分分析法(PCA)用于对指标体系的降维,去除掉对系统可靠性影响小的指标,达到简化运算,提高预测精度的目的。随机森林算法(RF)作为模型的训练及预测算法,主要用于第一步中各个子系统评价值的预测及第二步中整个系统可靠度的预测。两步法PCA-RF混合算法模型的具体结构框图如图3所示。

图2 两步法拓扑结构图
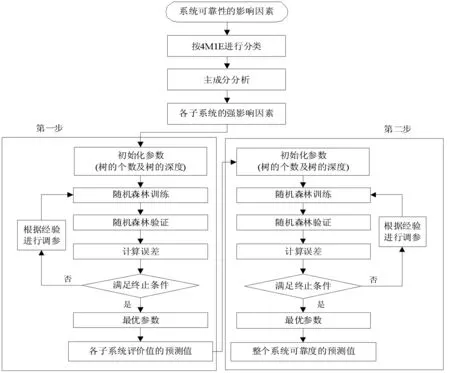
图3 两步法PCA-RF混合算法模型结构图
3 案例应用分析
3.1 案例背景
本研究以我国某集团合成氨分厂提供的数据为例,进行模型的验证[14]。图4显示的是该合成氨分厂部分工序的生产流程图,包括脱除二氧化碳工序、空气净化分离工序、闪蒸工序、解吸工序、冷凝工序等15个工序。以建立的可靠性评估指标体系,即4M1E指标分类原则,获取研究所需的数据样本。
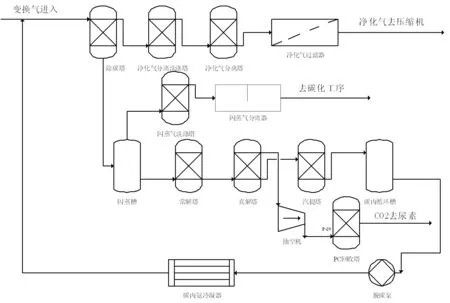
图4 合成氨分厂部分工序生产流程图
3.2 原始数据获取
由于化工厂数据的采集和维护具有周期性,复杂系统的数据收集也较困难,获得了该厂2013年稳定运行的100组数据进行研究,是典型的小样本数据。将收集到的数据分为人,机,料,法,环五个方面,具体指标见表1~5。
化工系统的可靠性用系统可靠度进行表征,系统可靠性分五个等级,如表6所示,系统可靠度的取值为[1,5],具体评价值采用德尔菲法[15]由专家打分给出。德尔菲法是一种匿名函询反馈法,具体步骤为:将要评估的问题匿名发放给各位专家,获取专家的意见后,进行整理、归类、统计、总结后,再匿名反馈给各位专家,再次获取意见,再集中,再反馈,直到获得一致的意见为止。

表6 系统可靠性的五个等级
化工系统可靠性评估的原始数据如表7所示。{1,0.9,0.8,0.7,0.5}代表定性指标定量化后的五个定量等级(例如a5,c1)。a,b,c,d,e表示五个子系统的评价值,表示整个化工系统的评价值。a,b,c,d,e,的评价值及其他定性评价指标(例如d2,e4)均由德尔菲法由专家打分给出。

表7 可靠性评估原始数据
3.3 结果分析
3.3.1 主成分分析
利用SPSS软件分别对五个子系统进行主成分分析,以达到保留主要影响因素,去除冗余因素,简化模型输入指标的作用。下面以物料子系统为例进行结果分析。
由表8可以看出,各指标之间存在较强的相关性,有必要进行主成分分析。表9为总方差解释,代表各个指标方差占总方差的比重,由表9可以看出,有一个最大贡献率的主成分,即特征值为7.454,满足特征值其贡献率达到93.177%,这说明第一个主成分就提供了足够多原始数据的信息,因此得到一个主成分。
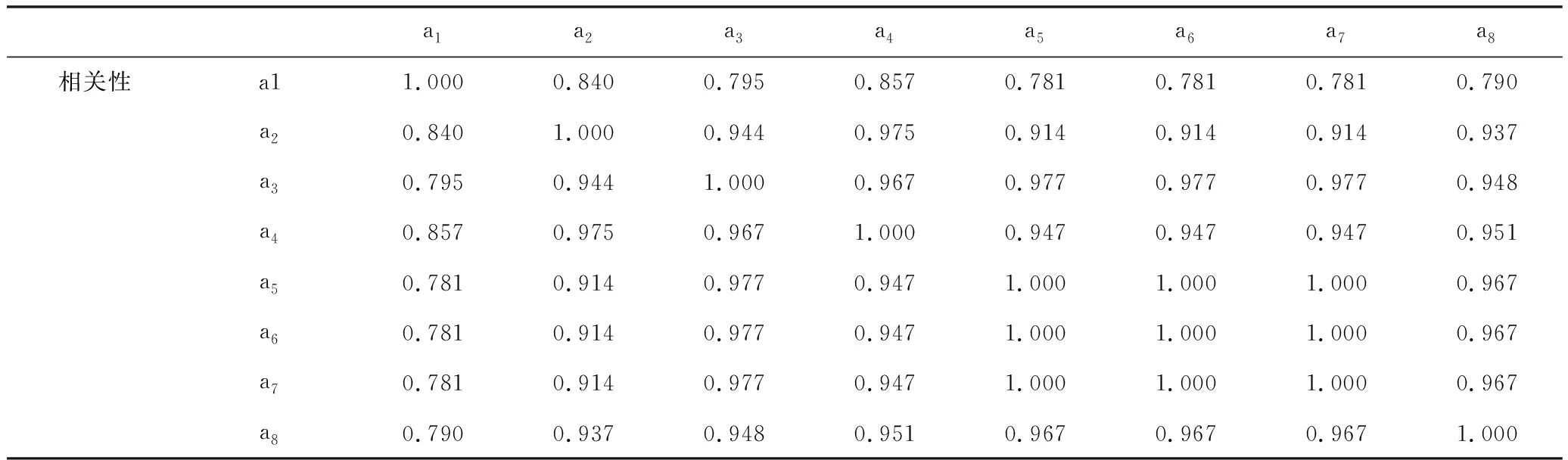
表8 相关性矩阵
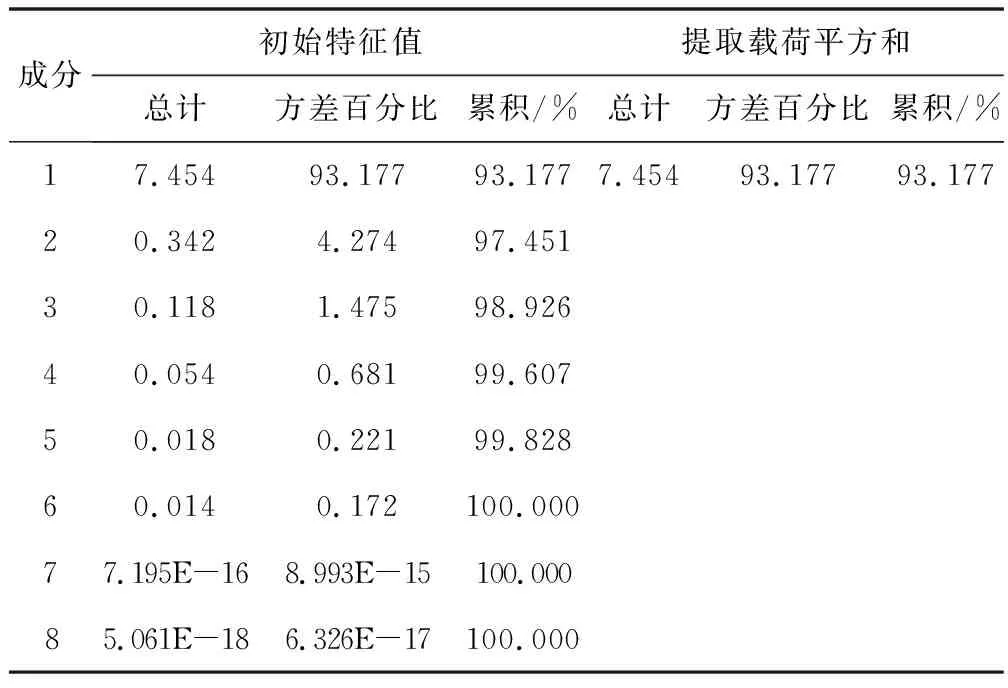
表9 总方差解释
如图5所示的碎石图是根据SPSS软件自动生成的,碎石图也可以作为判断主成分个数的依据。碎石图横坐标代表主成分的个数,纵坐标代表各个主成分的特征值,由图可以看出,在第二个主成分处发生明显偏折,且其之后的特征值都不满足特征值λ≥1。
综上,物料子系统的指标所提取到的主成分个数为一个。表10是由SPSS软件得到的成分得分系数矩阵,该矩阵代表各个变量在主成分中对应的系数,可用下式进行表示:
Z1=0.115a1+0.129a2+0.132a3+0.132a4+0.132a5+0.132a6+0.132a7+0.131a8
(1)
由式(1)可以看出,a3,a4,a5,a6,a7,a8的系数远大于a1,a2的系数,因此第一主成分Z1是由a3,a4,a5,a6,a7,a8所确定的,可将a1,a2剔除,达到简化运算的目的。
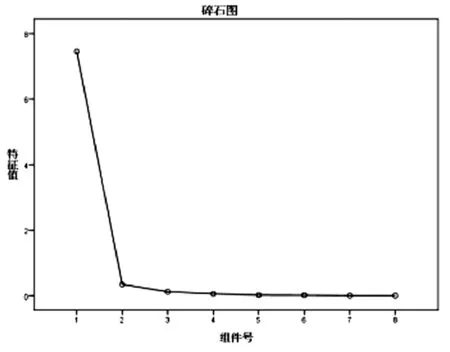
图5 主成分分析法碎石图
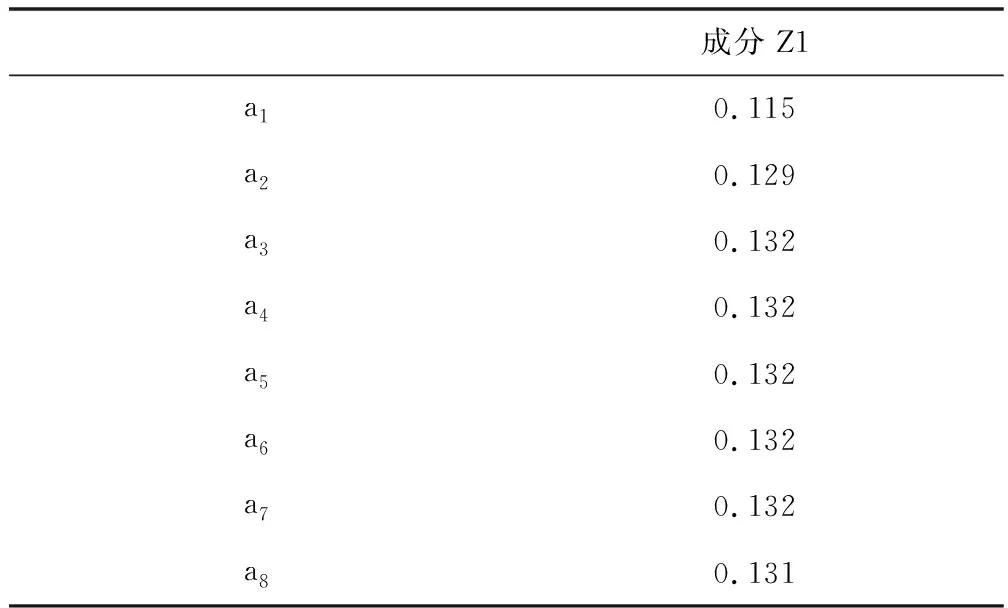
表10 成分得分系数矩阵
以同样的方法对其他四个子系统进行主成分分析,得到如下结论:
机器子系统:
得到一个主成分Z2,各个变量在主成分中对应的系数如式(2):
Z2=0.068b1+0.120b2+0.12363+0.123b4+0.122b5+0.122b6+0.123b7+0.122b8+0.121b9
(2)
Z2由b2,b3,b4,b5,b6,b7,b8,b9所确定,可将b1剔除。
物料子系统:
得到一个主成分Z3,各个变量在主成分中对应的系数如式(3):
Z3=0.180c1+0.180c2+0.180c3+0.180c4-0.157c5-0.165c6
(3)
Z3由c1,c2,c3,c4所确定,可将c5,c6剔除。
管理方法子系统:
得到一个主成分Z4,各个变量在主成分中对应的系数如式(4):
Z4=0.125d1+0.130d2+0.130d3+0.126d4+0.125d5+0.130d6+0.130d7+0.130d8
(4)
Z4由d2,d3,d6,d7,d8所确定,可将d1,d4,d5剔除。
环境子系统:
得到一个主成分Z5,各个变量在主成分中对应的系数如式(5):
Z5=0.171e1+0.171e2+0.171e3-0.167e4-0.168e5-0.170e6
(5)
Z6由e1,e2,e3所确定,可将e4,e5,e6剔除。
这样,经过主成分分析,将37个影响系统可靠性的因素简化为26个。
3.3.2 随机森林算法预测分析
如图3所示的两步法模型示意图,在经过主成分分析法得到各个子系统的约简指标后,第一步是针对人,机,料,法,环五个子系统,对每个子系统用随机森林算法(RF)进行子系统评价值的预测。将收集到的100条数据(表7)分为两个数据集,其中前50条数据(No.1~No.50)为训练集,后50条数据(No.51~No.100)为测试集。模型的输入为各子系统经主成分分析法简化后的输入节点,输出为各子系统的评价值(即a,b,c,d,e)。
对于各个子系统,算法中的参数及训练精度如表12所示,预测的各个子系统的评价值如表13所示。
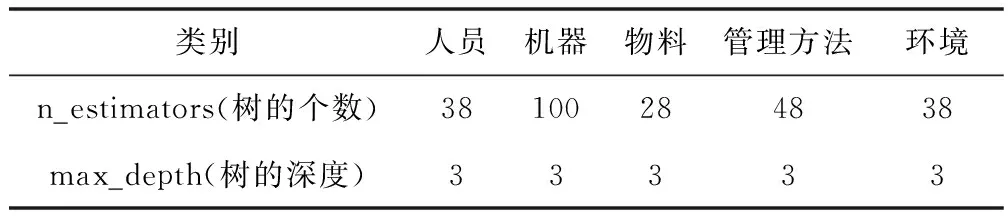
表11 第一步模型训练参数
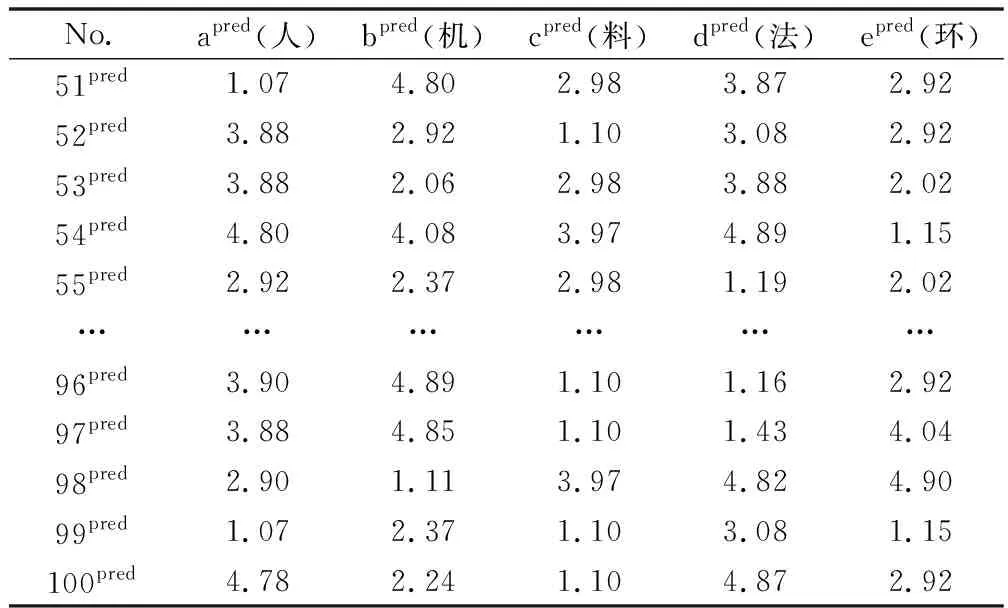
表12 各子系统评价值的预测值
将第一步得到的各个子系统评估值的50组数据,如表12所示,分为两个数据集,其中前40条数据(51pred~90pred)作为第二步的训练集,后10条数据(91pred~100pred)作为测试集,五个子系统评价值的预测值(即apred,bpred,cpred,dpred,epred)作为模型的输入值,整个系统的可靠度为输出值,采用随机森林算法进行模型的训练及预测。
第二步模型的参数及训练精度如表13所示:

表13 第二步模型的训练参数
为了进一步对比模型预测的准确性,刘文等人[10]提出的针对化工系统可靠性预测的两步法GRA-GA-BP-MCRC模型将被用于对比研究。表14给出了两种模型对系统可靠度预测值的对比分析。
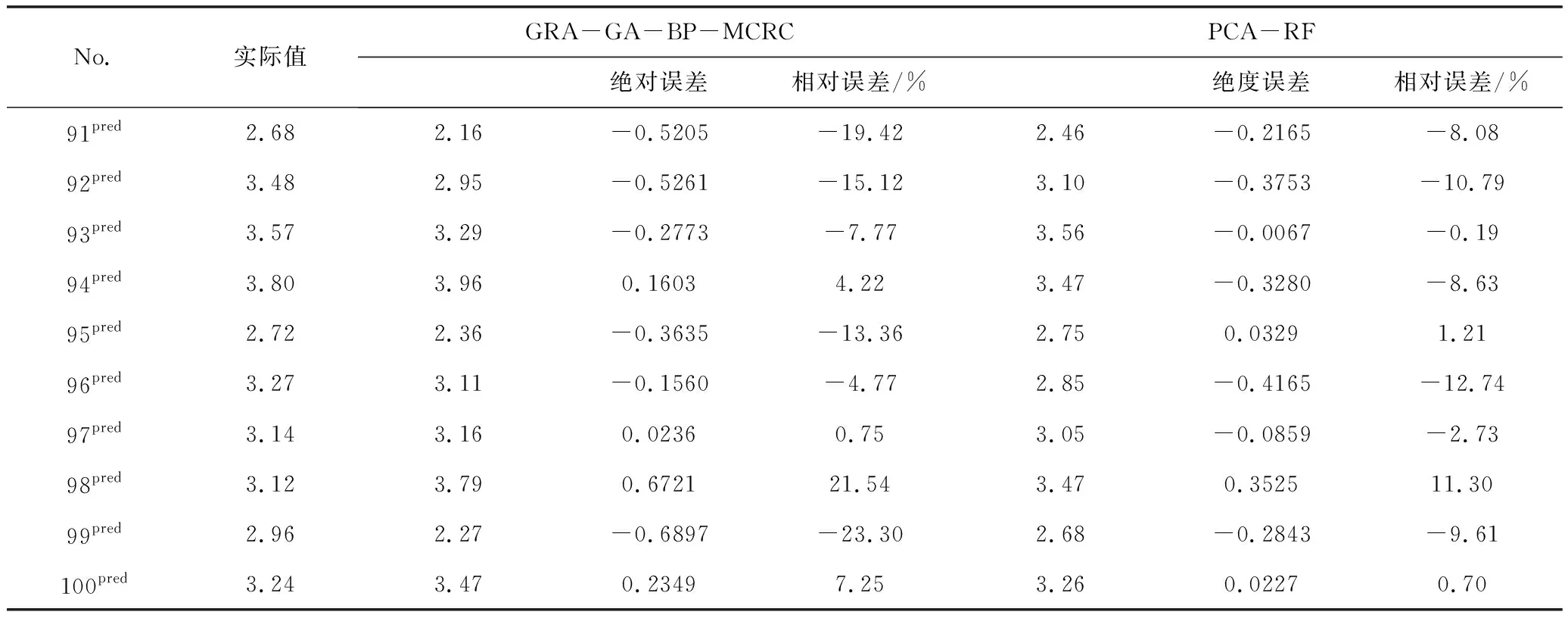
表14 两种模型预测结果对比分析
根据表14可以看出,GRA-GA-BP-MCRC模型相对误差绝对值的波动范围为0~23.30%。PCA-RF模型相对误差绝对值的波动范围为0~12.74%,PCA-RF模型的相对误差波动范围要明显小于GRA-GA-BP-MCRC模型的相对误差波动范围。将两种模型的相对误差绘制成折线图,如图6所示。由图中也可以看出,两步法PCA-RF模型相对误差的波动范围更小,模型具有更强的稳定性和预测精度。
为更进一步分析模型的预测结果,利用均方误差(MSE)和平均相对误差(MRE)来判断结果的精确度。MSE和MRE越小,真实值和预测值相差越小,模型精确度越高。MSE和MRE的计算公式如下:
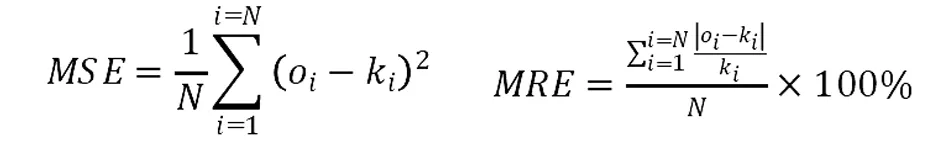
(6)
式中:ki实际值;oi是模拟值;N是数据总数。
表15~16分别给出了两种模型对各个子系统和总系统的预测结果。
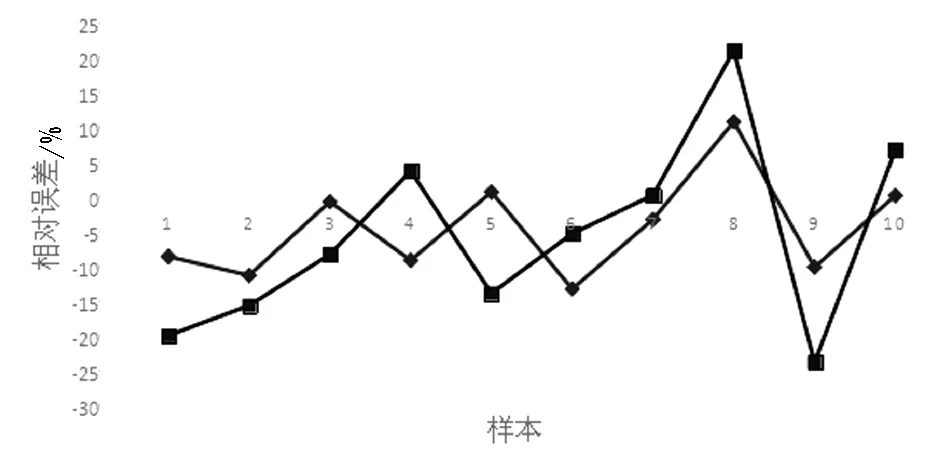
图6 两种模型的相对误差折线图

表15 GRA-GA-BP-MCRC模型预测精度分析

表16 PCA-RF模型预测精度分析
由表15~16可以看出,本文提出的两步法PCA-RF模型比文献中的GRA-GA-BP-MCRC模型具有更高的预测精度。对整个系统可靠度的预测,PCA-RF模型的MSE值为0.068,低于对比模型的MSE值0.131;PCA-RF模型的MRE值为6.60%,同样低于对比模型的MRE值9.69%。因此,对于化工系统可靠性评估问题的研究,本文提出的模型不仅简洁,而且具有更高的预测精度。
5 结论
本研究以复杂化工系统为研究对象,进行可靠性评估指标体系的分类和可靠性评估模型的构建,提出一种两步法PCA-RF混合算法模型,该模型用于解决复杂化工系统的可靠性评估问题,并进行了案例的应用分析,主要结论如下:
(1)根据4M1E分类原则,将影响化工系统可靠性的因素分为五个方面,即人员、机器、材料、管理方法和环境,构建了化工系统可靠性评估的指标体系。
(2)利用主成分分析法进行数据预处理,除去影响因素小的指标,简化模型,避免过拟合现象的发生。
(3)建立了两步法PCA-RF模型。此模型在实例中较GRA-GA-BP-MCRC模型取得了良好的预测结果,平均相对误差从9.69%下降到6.60%,均方误差从0.131下降到0.068。
