基于API服务器的爬虫项目设计与实现
2020-06-13王予诺
文/王予诺
(西安科技大学 陕西省西安市 710600)
1 前言
在大数据时代,企业所掌握的数据数量决定了该企业的核心竞争力。人们所能接触的数据数量决定了一个人的知识面和生活质量,如何能有效地选取对自己有利的信息逐渐成为人们所追求的能力。网络爬虫可以用来帮助我们获取有效的数据资源,比如:作为学生的你,是否想知道历年高考卷题以及答案来复习;作为找工作的你,是否想知道符合你理想条件的公司都有哪些,他们的标准都是什么;作为家庭妇女的你,是否想知道所有蔬菜水果的最佳搭配等。有了网络爬虫,我们可以轻松获取到我们所需的数据,而API server基于C/S模式,模拟客户端向服务器发送请求,可以轻松获取到海量资源数据,也满足你想拥有一个自己的API的愿望。
2 系统设计
该系统分为API和爬虫两个重要部分。从结构上可以分为客户端和服务器端。客户端包括curl和postman,用于向服务器发送HTTP请求。服务器端包括dbmovie爬虫部分和API服务器部分。这个系统主要操作过程如下:postman/curl从客户端发送一个HTTP请求API服务器已经部署成功,服务器通过调用crawler命令执行爬虫的任务,通过管道将下载的代码进行处理,生成目标文件,然后通过服务器返回结果,返回到客户端和显示一个爬虫内容。系统总体架构如图1所示。
在爬虫框架搭建好的前提下,通过URL发送一个请求到服务器,使用xpath的方法提取的位置信息,在服务器运行正常的情况下,通过一个循环访问数据,用户可以接收请求的页面响应和二进制格式的数据。然后解析器将解析页面的内容。最后,管道会对二进制数据进行提取和处理,输出需要的格式并将其保存,比如json格式,保存到本地。爬虫的工作原理图如图2所示,系统功能架构图如图3所示。
演示操作过程及结果的视频如下:
http://www.iqiyi.com/w_19sb2b9fgh.html
3 网络爬虫部分的设计实现
3.1 scrapy网络爬虫的搭建过程
3.1.1 安装scrapy框架
Dos命令如下:(先安装Twisted库,否则会出错)
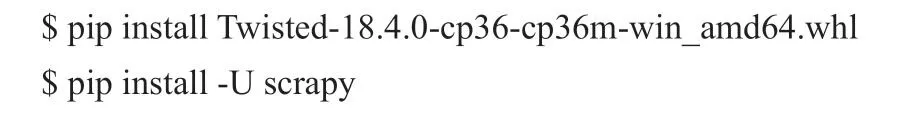
3.1.2 建立项目
命令如下:

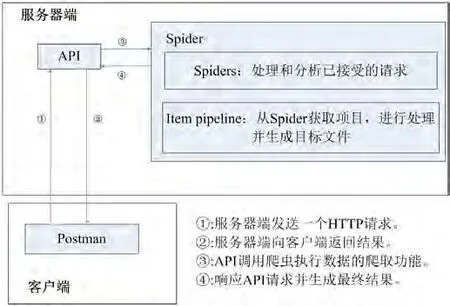
图1:系统总体架构

图2:爬虫工作原理图
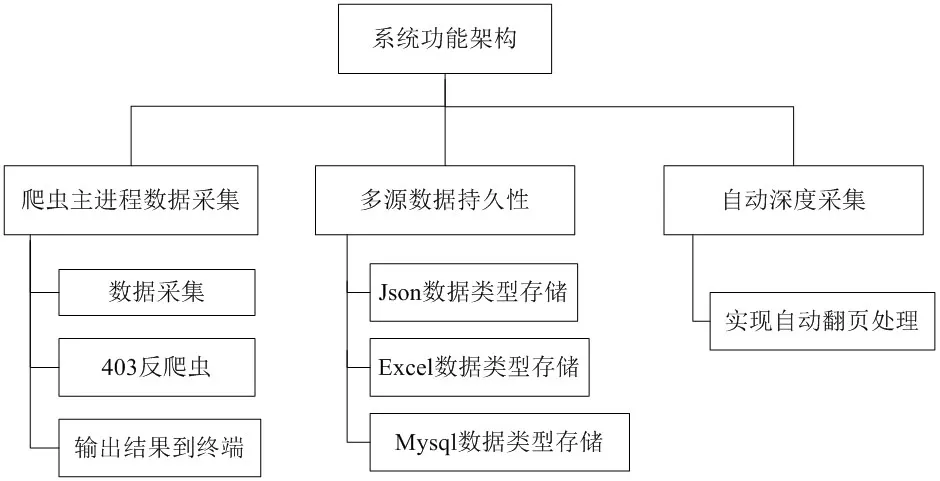
图3:系统功能架构图
可以使用以下命令查看项目文件夹结构
$ tree/f
项目文件夹结构说明
items.py:封装实体类来收集数据
pipelines.py:处理采集到的数据
settings. py:框架核心配置文件
spiders:爬虫主脚本文件
3.1.3 创建爬虫脚本
$ scrapy genspider dbmovie https://movie.douban.com/top250
3.1.4 反爬虫
测试网站连接,此时会有403错误,需要设置页眉信息
$ scrapy shell https://movie.douban.com/top250
此时,我们需要创建一个名为“rotate_useragent”的新代理。在豆瓣电影中实现自动随机选择。
核心代码如下:

并对“设置”进行更改,将rotate_useragent.py配置到框架中。

此时,可以使用shell视图正常访问浏览器(提示:200)
设置"items.py"来确定收集的数据对象。
核心代码如下:
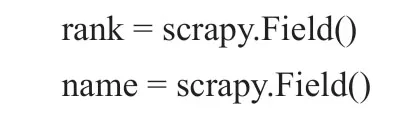
3.1.5 编写"dbmovie.py"文件来分析HTML标记以获取数据
核心代码如下:

3.1.6 编译"pipelines.py"来设置控制台输出。
核心代码如下:

3.1.7 运行

3.2 爬虫主进程数据采集的设计
数据收集主要通过提取Xpath中的字段来实现,使用路径表达式来选择web页面中的节点,并通过节点的元素、属性等来确定特定的信息内容。
“rank”属性的Xpath提取方法:

“name”属性的Xpath提取方法:
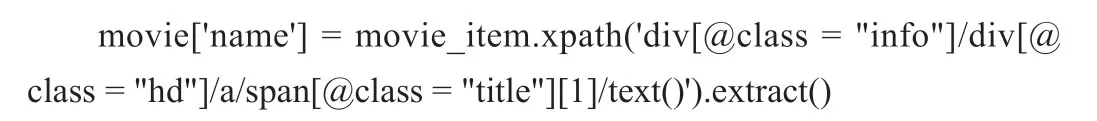
3.3 403反爬虫的设计
很多网站都有反爬虫机制,那么什么是反爬虫机制呢?当我们的crawler刚开始制作的时候,它们通常是简单的,快速的,但是伪装度很低。如果我们抓取的网站没有防爬虫机制,那么我们可以简单的抓取大量的数据,但是如果网站有反爬虫机制,比如检查报头信息或者统计IP访问频率。一旦网站监视器识别爬虫程序,例如相同的IP地址和用户代理总是python,网站将限制对您的IP的访问。此时,我们需要破解反爬虫机制。反爬虫机制可以模拟不同的浏览器行为,以一定的频率改变代理服务器和网关,破解网站的反爬虫检测。
首先,我们可以通过“rotate_useragent”快速获得用户代理列表。实现自动随机选择,核心代码如下:

然后扩展中间件,编写user-agent列表,并将公共浏览器请求头作为列表,部分核心代码如下:

3.4 多元数据持久性的设计
通过对数据的处理,最终可以将数据存储为:json格式、Excel格式、数据库格式。当数据量不是很大时,Json存储是一个很好的选择。当数据从一个项目传递进来时,它被“json.dumps”转换成json文件。注意,因为“json.dumps”为中文序列化默认的ASCII编码,需要为最终输出指定“ensure_ascii = False”,核心代码如下:

CSV类型是最简单的保存类型之一。它只需要改进CSV模块到项目中,并调用“csv.writer”,核心代码如下:

为了将数据保存在Mysql中,首先需要在Mysql数据库中创建一个新的表“test”,然后需要将数据库连接到python代码中的爬虫,主要是通过将数据库的名称与表的名称匹配。使用SQL语句将抓取的结果直接存储到数据库中,核心代码如下:


3.5 自动深度采集
自动深度采集模块主要处理网站的翻页功能。如果没有添加自动翻页,爬虫将只会运行一次,并且只能抓取一个页面的内容,这并不能保证它可以抓取排名在前250的所有信息。通过自动翻页,可以通过xpath方法获得下一页的URL,然后判断“下一页”是否有效。如果是,将其URL拼接到前一页,发送请求后完成所有页面信息的抓取,核心代码如下:

4 API server部分的设计实现
使用命令“pip install”将所需的Flask模块导入到项目中,例如Flask、flask_restful、API等。该应用程序是Flask的一个实例,它可以使用包或模块的名字作为参数,但是它通常会传递参数“__name__”,代码如下:
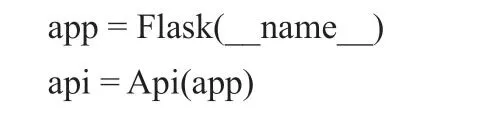
在类中,它继承自flask_rest。资源类,并定义来自请求的方法,如get、post。我主要定义了一个由“get”提交的请求。在这个方法中,我调用了“Popen”方法来运行爬虫项目的指令。在“Popen”中,可以使用“cwd”参数指定shell命令应该运行的位置,代码如下:

如果想将爬网的内容输出到终端,只需读取存储文件的绝对路径并输出即可,代码如下:

最后,在主函数中使用app.run(debug=True,port=9191)启动API,代码如下:
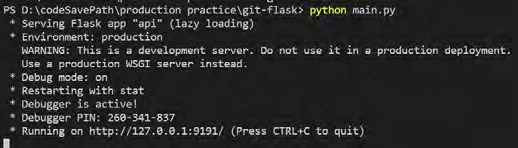
图4:启动API服务器
5 API测试
5.1 启动API服务器
Api服务器搭建完成后,就可以启动main.py来部署我自己的爬虫请求,启动API服务器,如图4所示。
5.2 利用curl测试
curl是一个文件传输实用程序,它使用URL语法从命令行开始工作,测试命令如下:
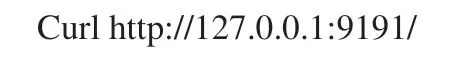
5.3 利用postman测试
postman:这是一个可视化的软件,用来模拟HTTP请求,帮助人们在后台的单元工具。它可以自定义请求URL、请求类型[GET、POST等]、添加头信息和HTTP主体信息等,使我们可以简单直观地测试HTTP请求。只需选择“GET”请求方式,在URL地址栏中输入“http://127.0.0.1:9191/”,再按“send”按钮发送请求,就可以在响应栏中得到输出结果。
6 结语
此项目基于Python语言强大的动态特性和简单的语法,再加上其用于科学和数值计算的标准库,使之性能优于其他编程语言。通过网络爬虫爬取到的源数据,经过pipelines的处理,可以保存为json、csv、Mysql三种形式,此种网络数据的采集提供了一种高效的数据采集方式,网络爬虫与API server的结合应用,更是为用户提供了一种简单、便捷的请求爬虫的方式,其操作方式以及界面的可视化效果都要远远优于网络爬虫本身。
