一种高效的嵌入式图文分离算法
2020-06-13唐春艳
文/唐春艳
(吉林大学珠海学院 公共基础与应用统计学院 广东省珠海市 519041)
1 引言
随着打印机、扫描仪和多功能一体机等嵌入式设备的普及,用户希望设备性能好、价格便宜的同时,还对质量的要求也越来越高,总希望得到文字锐利和图像平滑的文稿。用户扫描和复印时常常采用经过印刷或打印得到的原稿,这类原稿受印刷或打印工艺的限制,图像部分由多个大小不一的黑白网点组成,以致图像和文字不能同时进行增强处理;另外,因为文字和线条的边缘特征与网点区域极为相似,简单的阈值分割算法也很难将这两者进行区分。因此要取得较好的图像质量,首先需要将文字和图像做有效分离。
随着一些机构的研究,陆续提出了多种图像分离算法[1~6],这些算法或多或少的解决了某些特定的问题,但是要么处理时间长,要么对设备硬件资源要求高;表1列举了两种常用的图文分离算法在常用的A4幅面纸张300*300 dpi情况下相对应的性能参数:
由表1可知:
(1)多卷积算法虽然需要的内存低、图像处理步骤简单,但是其平均运行时间较长;在实际应用中将导致办公设备的页面输出变慢,影响用户体验;
(2)彩色分离算法虽然在平均运行时间上较有优势,但是内存需求为多卷积算法的3倍,且在黑白输出设备中需要额外的处理步骤,导致硬件成本增加,实际很少使用。
因此,设计一种对硬件资源要求小,且处理时间短的嵌入式图文分离算法对于提高图像质量、降低机器成本、改善用户体验具有很大的实际意义。本文基于印刷和打印文稿的数据特征,结合FIR滤波检测原理,设计出一种适用于灰度数据的嵌入式图文分离算法,该算法简便高效,能较好地对图文进行分离,实例验证结果说明了该算法的有效性。
2 硬拷贝原稿的数字特征
目前印刷领域比较常见的输出分辨率为133line/inch和200line/inch,分别应用于普通印刷品(如报纸)和高档印刷品(如杂志),这两类输出分辨率对应的网点分布特征及扫描输出示意图分别如图1和图2所示。
从图1和图2可知图像网点区域存在如下特征:
(1)原稿中网点区域黑白界限分明,经过影像设备的扫描光学成像系统处理之后,黑白点之间被中间阶调的数据填充,并且网点形状发生明显变化;
(2)原稿中网点分布均匀且呈周期性分布,经过扫描之后图像数据分布也规律性发生变化,并且存在一定周期,133和200line/inch扫描数据变化周期分别为3*3和7*7 pixel*pixel。
实际上原稿中的文字和线条区域经过扫描之后的输出数据也存在着上述变化,即黑白界限模糊,线条边缘过渡明显,如图3所示,左图是原稿,右图是扫描后输出文稿:
由上述分析可知,虽然网点区域与文字、线条区域经过扫描处理后都存在一定程度的模糊现象,但是还是有显著性差异,网点经过扫描之后的数据分布特征成邻域像素规律性分布,而文字和线条扫描后只在边缘呈模糊状态,因此可以通过设置不同的FIR滤波检测方式对两者进行有效分割。

图1:133lines/inch网点图像扫描前后对比分析

图2:200lines/inch网点图像扫描前后对比分析

图3:文字和线条区域扫描前后对比图
3 图文分离的算法设计
FIR滤波,也称为有限长单位冲激响应滤波,其主要特点是在保证任意幅频特性的同时具有严格的线性相频特性,同时其单位抽样响应是有限长的,因此是一种稳定的滤波系统。在图像处理领域[7],常用以下FIR滤波器公式:

其中:y为滤波输出,h为滤波参数,x为输入数据,由式(1)可知,在输入数据相同的情况下,滤波参数的设计决定了最终的输出效果。
根据图1~图3分析,扫描后的网点区域呈规律性分布,且其在水平和垂直方向上的梯度值最大;而文字、线条的边缘梯度方向比较分散,即网点区域和文字、线条区域与传统的图像区域相比,它们的边界梯度特征值明显,因此可以通过不同角度的梯度来检测这两者之间的差别。
3.1 梯度检测
梯度检测是基于邻域内像素值之间的差异来实现的,其检测的效果取决于邻域内像素值的差异情况及检测模板。根据上文对扫描之后数据的特征分析,本算法采用Prewitt算子进行水平和垂直方向梯度检测,计算公式如下:

图4:文字处理示意图

图5:133 lpi网点处理示意图

图6:200 lpi网点处理示意图

图7:区域转换前后对比图
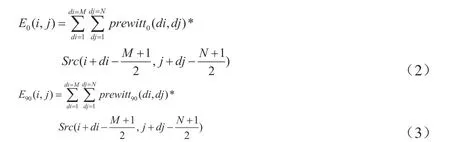
其中,i、j为当前卷积邻域中心点位置坐标,E0、E90分别表示图像数据在水平和垂直方向的边缘检测强度值,di、dj为当前卷积邻域点位置坐标,M、N为邻域的长和宽,例如3*3邻域,则M=3,N=3,Src表示原图像数据,prewitt0、prewitt90分别表示水平和垂直方向的边缘检测FIR滤波器。
原图像中的文字线条区域和图像区域在进行边缘检测之后,其边缘强度值分别处于不同的区域,如文字线条区域可能介于[128,255],图像区域可能介于[0,64],因此需要通过设置简单阈值,将其进行有效分离,得到分割之后的文字线条区域强度值为1,图像区域的强度值为0。

其中,EStren表示图像数据最终的边缘强度值,StrenThr表示检测阈值,DStren表示通过阈值分离之后的输出图像的强度值。
为了验证梯度检测处理的效果,下面分别对文字线条、133lpi和200lpi网点进行处理的效果对比图(图4、图5、图6)。四幅图从左至右分别是:原图、水平方向边缘检测强度输出图像、垂直方向边缘检测强度输出图像、阈值分割后的强度输出图像:
在上述处理中,由于文字和线条区域的边缘分布基本为3600方向,因此在水平和垂直两个方向上的检测不仅不会对其边缘特征造成丢失,反而会使其更加明显;相反,对于网点区域而言,因为其数据分布存在固定的规律,因此最终检测的结果是降低边缘强度,两个方向相互叠加之后边缘将全部丢失,即边缘强度为0,依据这种明显特征可以使用简单阈值分割的方式对其进行分离。
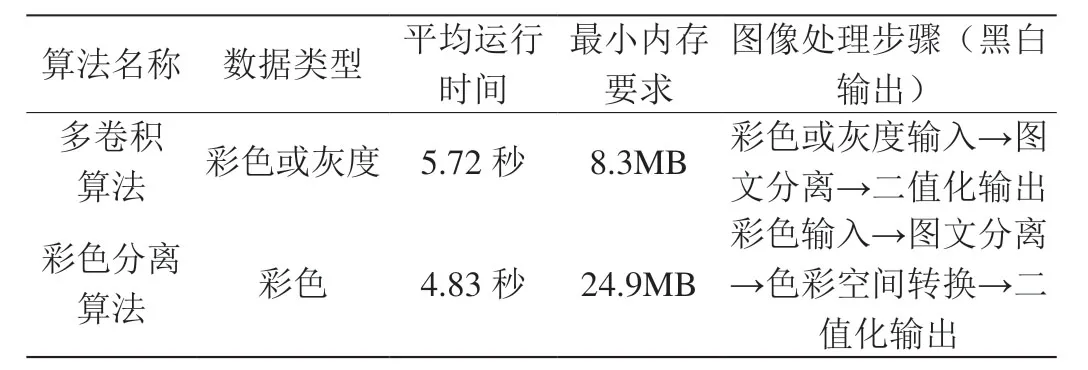
表1:主流图文分离算法性能对照表

表2:多卷积算法和本文算法性能对照表
3.2 区域转换
经过梯度检测之后的文字线条区域检测结果以边缘形式体现,如图7左图所示,文字和线条出现空心,并非实际的内容区域,因此需要通过区域转换处理使其边界区域转换成内容区域。传统的边界内容转换需要复杂的形态学处理(如腐蚀、膨胀等)[7],或者通过判断当前邻域的边界方向实现,这类处理涉及多次卷积,处理时间较长,并且需要大量缓存存储中间数据。为了克服这些缺陷,本文采用一次邻域加权运算,公式如下:

其中,RThr表示区域分割阈值,R(i,j)表示填充之后的图像数据,1表示填充处理之后的文本数据,0表示填充之后的非文本区域。图7是采用上述算法对区域进行转换前后的对比图。

图8
3.3 算法描述
结合梯度检测和区域转换两种算法可以得到基于FIR滤波的图文分离算法,详细处理步骤如下:
(1)获取图像数据,若输入图像为彩色图像数据,则需要将其转成灰度数据;
(2)设定检测滤波器,分别使用公式(2)和(3)进行滤波处理,并得到对应滤波数据;
(3)根据公式(4)和(5),得到最终的检测结果数据,若结果数据为1,表示文字线条区域;若为0则表示为图像网点区域;
(4)根据公式(6)对第三步检测得到的文字线条区域进行区域转换处理;
(5)设定区域转换阈值,去除多余边缘信息,即得到最终分离的文字线条区域和图像区域。本算法中决定最终图文分离效果的参数主要有:

图9:本文算法(左)与多卷积算法(右)图像及网点区域检测效果图

图10:本文算法文字线条检测效果图

图11:多卷积算法文字线条检测效果图
(1)FIR滤波邻域大小:由扫描图像分辨率决定,对于300dpi输入的原数据而言,采用3*3邻域即可满足要求,对于600dpi,5*5就可以了;
(2)梯度检测阈值:该阈值决定了网点区域与文字、线条区域的分割效果,阈值偏小,则分割效果越差;反之,则对文字线条区域丢失越严重,因此对于普通打印和印刷稿件而言,取值一般介于[16,80];
(3)区域转换阈值:该阈值决定了最终的图文分离的精度,一般取值介于[32,96]。
4 实例验证
为了验证该算法的效果,下面以一副300dpi的图文混合灰度图像作为输入,设置垂直方向梯度检测滤波器参数为[1,0,-1;0,0,0;1,0,-1],水平方向梯度检测滤波器参数为[1,0,1;0,0,0;-1,0,-1],梯度检测阈值为64,区域转换阈值为80,图8是图文混合原稿样张:
本文算法的处理效果和多卷积算法的处理效果图如图9、图10、图11所示。
以上结果表明,本文算法具有较好的图文分离效果,而且整幅图像处理时间大约2.1秒,由于仅使用两次3*3卷积,时间大约是多卷积算法的0.6倍,能够满足目前主流复印设备的应用需求。
为了更好的验证图文分离算法的效果,本文采用识别率和处理时间两个指标进行对比分析,识别率定义为分割识别处理后的效果图数据与原图像数据的标准方差[12~13]。表2列举了多卷积算法和本文算法对不同样稿进行图文分离的结果对比。
根据上述实验测试结果,可以得出:
(1)针对网点样稿及图像样稿,本文算法的识别率明显优于多卷积算法;
(2)针对文本样稿及线条样稿,本文算法比多卷积算法略差,但是由于文字及线条区域本身较黑,且内部像素值分布均匀,在后续滤波处理中可以弥补部分差异,同时受碳粉扩散的影响,用户在最终打印介质上无法识别文字内部这些微小差异,因此可以忽略这些差异。
(3)在处理速度上,不论是标准速度评价样稿,还是其他类型样稿,本文算法都要明显优于多卷积算法。
5 结论
本文通过分析常用硬拷贝原稿中网点区域和文字线条区域页面数据特征之间的差异,同时结合FIR滤波原理设计出一种适用于灰度数据的图文分离算法。该算法以灰度数据作为输入,通过梯度检测和区域转换实现了较为复杂的图文分离效果,大大降低了系统硬件要求;此外还可以通过配置不同的检测系数对最终处理效果进行精确调整,进一步扩大了该算法的实用性,最后实际验证结果表明该算法可以满足实际应用需求。
