改进和声搜索算法的近红外光谱特征变量选择
2020-06-12丁香乾宫会丽吴丽君白晓莉
张 磊,丁香乾,宫会丽,吴丽君,白晓莉,罗 林
1.中国海洋大学信息科学与工程学院,山东 青岛 266100 2.云南中烟工业有限责任公司技术中心,云南 昆明 650024
引 言
近红外光谱分析作为光谱测量和化学计量学结合的分析技术,是近年来分析化学领域发展最迅速的高新分析技术,以其简便、快速、低成本、绿色环保、涵盖信息量大和多组分同时测定等优点,广泛应用于烟草、石油、纺织、食品等领域的定量检测和定性分析,是现阶段开展广域范围、大规模样品检测最佳的技术手段[1]。然而,近红外光谱由于变量维度高、包含众多与测定量无关的冗余信息和高频噪声等,对其直接建模不但会增加模型的复杂度,同时也会影响模型的预测性能和泛化能力[2]。因此,如何从高维的光谱变量中筛选与预测指标密切相关的特征变量,从而构建准确、稳定、高效的预测模型就显得尤为重要。
目前,许多学者参与到近红外光谱的特征变量筛选研究当中,取得了一定成果。李倩倩等[3]应用无信息变量消除法(uninformative variables elimination,UVE)剔除了光谱中不含有效信息的光谱点,然后构建总氮和总糖的PLS定量模型。但由于过度依赖光谱和指标关联关系,并且需要单个变量逐一提取,容易忽略光谱变量全局贡献度。徐宝鼎等[4]应用粒子群算法(particle swarm optimization,PSO)进行近红外光谱特征选择,采用特征分层的方式划分初始粒子群。但优化过程中只针对固定的初始粒子群内部进行优选,忽略了不同粒子群光谱之间的比较。
鉴于此,本文提出了基于改进和声搜索(harmony search,HS)算法的光谱特征变量选择方法。首先通过偏最小二乘(partial least square,PLS)载荷系数计算各光谱点的特征贡献度,作为和声搜索算法改进的扰动权重。然后应用和声搜索算法进行最优光谱变量选择,为了避免陷入局部最优或者收敛速度过慢,引入变量特征贡献度(变量扰动权重)对初始和声记忆库生成方法进行优化,并对和声搜索算法的参数进行动态调整,提高了算法的自适应能力,为近红外光谱的特征变量选择提供了更好的解决方案,有效降低了建模复杂度并提高了模型性能。
1 理论与算法
1.1 光谱变量特征贡献度
为了计算光谱变量的特征贡献度[5],首先应用PLS方法计算各光谱点的载荷(X-Loading)系数pi。通过定义光谱矩阵提取因子ti和预测指标矩阵提取因子ui之间最大的协方差,求解如式(1)的最优化问题
max{Cov(t1,u1)}=max〈E0w1,F0c1〉
(1)
利用拉格朗日乘数法求出w1和c1满足式(2)
(2)

(3)
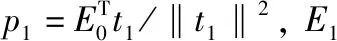
最后应用式(4)计算每个光谱变量的贡献度:其中,n为光谱维数。
(4)
1.2 和声搜索算法的改进和光谱特征变量选择过程
和声搜索算法是一种相对较为新颖的启发式优化算法,在2001年由Geem等提出,主要用于解决组合优化和特征变量选择问题,在许多研究领域展现了良好的性能。与演奏家们的目标是合奏出最优美的和声一样,HS的标准就是优化问题的目标函数[6]。
和声搜索算法的改进和特征变量选择步骤如下。
1.2.1 初始化和声记忆库
和声记忆库(harmony memory,HM)中解向量的每一个分量都是用该决策变量的下界和上界之间均匀分布的随机数(范围[Lxi,Uxi],1≤i≤N)来初始化[7]。第j个解向量的第i个分量通过式(5)给出
(5)
其中,j=1,2,3,…,HMS,rand[0,1]是0-1之间均匀分布的随机数。
第j个解向量的目标函数值用f(xj)来表示,置为解向量的最后一个分量。对应HM的矩阵结构由式(6)生成
HM(j,1:N)=xj
HM(j,N+1)=f(xj)
(6)
由于上述和声记忆库的初始解向量完全是随机生成的,其在整个解空间Xi中的分布可能存在极端情况,经过不断迭代很容易陷入局部最优的状态,在一定程度上影响算法的搜索性能[8]。为了增强全局搜索能力,在各分量生成时引入该分量的特征贡献度gi作为激励因子,采用随机遍历和激励因子共同作用的方式生成初始解向量,如式(7)所示
(7)
本工作中,输入变量个数为1 555个光谱点,各光谱点依次横向在和声向量中排列。如果该光谱点被选定,则其值设为1,否则设为0。每一行的最后一位表示该解向量目标函数。HM矩阵结构如图1所示。

图1 和声记忆库(HM)矩阵结构Fig.1 Harmony memory matrix structure
1.2.2 从和声记忆库生成新的光谱特征选择向量
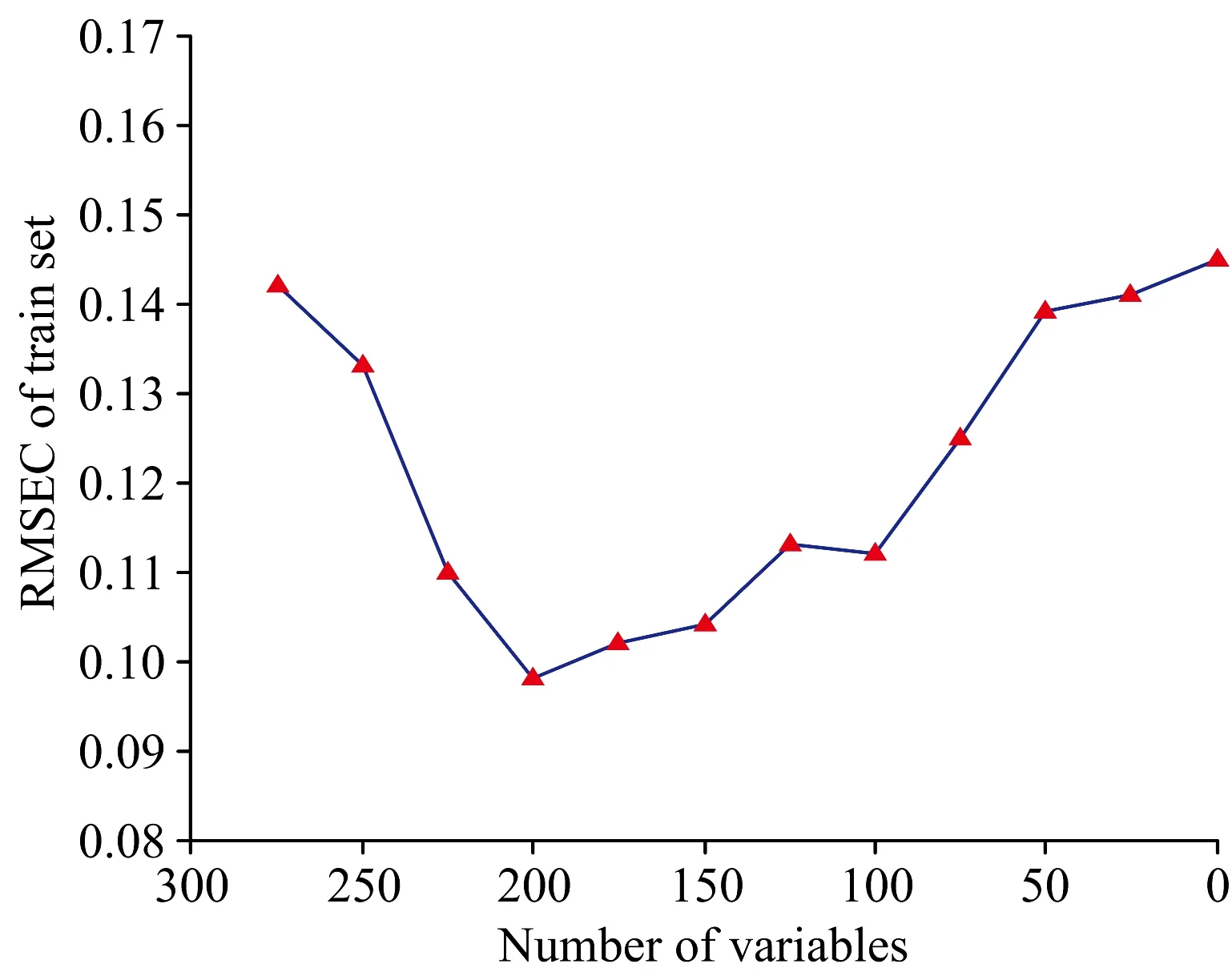
(1)在[0-1]之间生成一个随机数r1,与和声库取值概率(harmony memory considering rate,HMCR)进行比较,若r1 (8) (2)若这个和声变量是从HM中得到的,则对这个和声变量进行微调。在[0-1]之间生成一个随机数r2,与音调微调概率(pitch adjusting rate,PAR)进行比较,若r2 (9) 其中,r3是[0-1]之间的随机数,若r3>0.5,取“+”号;若r3≤0.5,取“-”号。 (10) 传统HS算法中,BW在整个迭代过程中是不变的,在某种程度上会影响搜索过程的遍历性和种群的多样性,容易陷入局部最优[11]。因此,本文以光谱变量特征贡献度gi作为惩罚项,引入α作为BW和gi的平衡因子,并根据式(11)使BW随迭代次数而动态调整,从而适应光谱选择问题特定阶段的搜索。 BW=(1-α)BW-α(BW-gi) (11) 其中,t为当前迭代次数,T为最大迭代数。产生新和声向量的过程如图2所示。 图2 新和声向量生成过程 P(E1),P(E2),P(E3):通过多概率扰动生成新和声;和声库取值概率(E1),音调微调概率(E2),S型函数概率(E3)Fig.2 New harmony vectors generation process P(E1),P(E2),P(E3):Probabilities to improvise a new harmony vector by memory considerations HMCR (E1),pitch adjustment rate PAR (E2),and activation function Sigmoid (E3) 1.2.3 应用光谱特征选择向量构建PLS预测模型 光谱特征向量中各分量表示光谱点选择状态,非零列表示该光谱点被选中。最后一个分量应用各训练子集均方根误差(root mean square error,RMSE)的均值[12]作为光谱特征向量的目标函数,如式(12)所示 (12) 其中,n为样本个数,ei为第i个样本的预测误差,等于第i个样本的预测值pi和真实值ai之间的差值。 针对各训练子集数据,基于HM中每个光谱特征向量对应选择的特征光谱点,分别构建PLS预测模型,最终计算各训练子集模型RMSE的均值作为目标函数值。如果该目标函数值比HM中最差的光谱特征向量好,即f(Xnew) 为验证算法的有效性,共选取800个具有代表性的烟叶样品,随机选取其中的600个样品作为训练集,剩余的200个作为测试集。进一步,又将训练集随机划分成3个数量相等的训练子集,用于增强变量选择算法的泛化能力。样本数据分布情况如表1所示。 表1 样本数据分布情况Table 1 Sample data distribution 选用布鲁克公司的MATRIX-I型傅里叶变换近红外光谱仪采集近红外光谱,扫描范围为4 000~10 000 cm-1,分辨率为8 cm-1,扫描次数为64。将烟叶样品放置在60 ℃烘箱中烘干2 h,用旋风磨磨成粉末,过40目筛,放入干燥皿中。每个样品称重15 g,放置于干净的5 cm样品杯中,用压样器自然压实后进行近红外光谱扫描。为保证光谱一致性,每个样品均重复装样扫描三次,采用三次扫描的平均光谱作为该样品的最终光谱,样品三次扫描的平均误差为:1.5×10-3A,标准差为:0.4×10-3。烟碱、总糖、总氮三个化学指标含量均按照烟草行业规定的标准方法测定。 采用一阶导数加Savitzky-Golay平滑的方法进行光谱预处理[14],移动窗口宽度为9,多项式数为3。图3为采用2.2中方法采集的原始光谱图,图4为预处理后光谱图。 图3 原始光谱图Fig.3 Original spectra 为充分验证算法的有效性,选取烟草化学分析中比较重要且常用的烟碱、总糖、总氮三个指标,分别开展对应的光谱特征变量选择和预测建模实验。 图4 预处理后光谱图Fig.4 Pre-processed spectra 在600个样品的训练集上,采用近红外光谱的全谱段和各指标检测结果构建PLS模型,得到第一主成分下各光谱点的载荷矢量,然后求得各光谱变量的特征贡献度。不同预测指标对应光谱变量的特征贡献度均不相同,各指标光谱变量贡献度如图5所示。 改进和声搜索算法根据各训练子集RMSE均值最小化作为约束标准进行光谱特征变量选择,以向量中取值为1的分量作为筛选出的变量。算法在3个训练子集上各运行100次。以烟碱指标为例,图6表示1 555个变量在总计300次训练中被选择的累积频次,频次越高说明该光谱变量对预测指标越重要,可以选做特征变量。将各变量被选择的累积频次从高到低排序,以25为下降梯度不断增加变量数,分别计算训练集上PLS模型预测结果的RMSEC。图7为随变量数的增加RMSEC变化趋势图。由图可知,开始时,随着变量数增加,RMSEC逐渐降低,当选择变量频次为200时达到最小值。如果变量继续增加,会引入噪声和冗余信息,RMSEC随之变大,对模型效果产生不利影响。因此以累积频次200作为临界点,最终得到烟碱指标光谱的特征变量个数为199。对于总糖和总氮指标,临界点分别200和150,光谱特征变量个数分别为213和276。 图5 不同指标对应的光谱变量贡献度(a):烟碱;(b):总糖;(c):总氮Fig.5 Contributions of each spectral variable(a):Nicotine;(b):Total sugar;(c):Total nitrogen 图6 光谱变量被选择的累积频次Fig.6 Cumulative frequency of spectral variables selected 为了验证算法的有效性,将改进和声搜索算法与全光谱以及UVE和PSO等光谱特征变量选择方法进行对比,分别构建烟碱、总糖、总氮三个指标的PLS预测模型,以选择的光谱特征变量数、训练集和测试集的决定系数及均方根误差作为评价标准,结果如表2所示。选择多次实验中最小的PRESS值对应的主因子数作为最终PLS模型的主因子数。 图7 RMSEC随变量增加变化趋势Fig.7 RMSEC trends with variables increasing 表2 各类型特征光谱在三个指标训练集和预测集上的性能Table 2 Performance of training and prediction sets using various types of characteristic spectra of three indicators 决定系数R2越大,预测均方根误差RMSEP越小,代表模型的预测性能越好。由表2可见,各种特征变量选择方法相对全光谱来说,均减少了波长点数,同时也提高了预测精度。相较而言,本文提出的改进和声搜索算法对三个预测指标都提取了最少的光谱特征变量(提取的光谱特征变量只占全光谱的13%~18%),具有最高的R2和最小的RMSEP值。同时,经过专家对筛选谱段对应的官能团分析,所选谱段均能够较好的反应其指标项特征信息,充分表明了本算法提取的光谱特征变量能有效降低冗余信息和噪声、消减变量间的多重共线性,使得模型更加稳健、泛化能力更强。 基于改进的和声搜索算法提出了一种近红外光谱特征变量选择方法。首先利用PLS载荷系数计算光谱变量对预测指标的贡献度,作为变量权重。然后,利用和声搜索算法进行特征变量筛选,过程中引入变量权重对和声搜索算法的初始化和参数动态调整进行改进。最后针对筛选后的变量通过PLS建模在烟碱、总糖、总氮三个指标的训练集和测试集进行验证,并与全光谱和几种常用的特征变量选择方法进行对比。实验结果表明,采用本算法进行光谱特征变量选择对模型性能优于全光谱和其他光谱变量选择方法,由此说明对近红外光谱进行特征变量选择的必要性以及本算法的有效性,既保证了模型预测性能又降低了建模的复杂度,为近红外定量预测模型的构建和优化提供了参考。
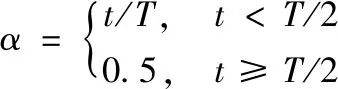

2 实验部分
2.1 样本数据

2.2 仪器设备与采集方法
2.3 光谱预处理

3 结果与讨论

3.1 光谱变量特征贡献度计算
3.2 光谱特征变量选择结果


3.3 预测结果对比

4 结 论
