基于预训练模型的机器阅读理解研究综述
2020-06-09张超然裘杭萍王中伟
张超然,裘杭萍,孙 毅,王中伟,2
1.陆军工程大学 指挥控制工程学院,南京210007
2.中国人民解放军73658部队
1 引言
机器阅读理解(Machine Reading Comprehension,MRC)是一项测试机器理解自然语言的程度的任务,要求机器根据给定的上下文回答问题。早期的MRC系统可以追溯到20 世纪70 年代,其中最著名的是Lehnert[1]提出的QUALM系统。但是当时构建的系统非常小,并且仅限于手工编码的脚本,很难推广到更广泛的领域。在20世纪80年代和90年代,对MRC的研究大多被忽视。20世纪90年代末,Hirschman等人[2]提出了Deep Read系统,并创建了一个阅读理解数据集,数据集包含了120个来自三至六年级素材的故事。使用这些来构建和评估一个基线系统,该系统包括基于规则的词袋方法以及附加的自动化语言处理(词干提取、名称识别、语义类识别和代词解析等)。这些系统在检索正确句子时达到了30%~40%的准确率。由于这些系统需要依靠大量的手工规则或特性,导致泛化能力弱,在包含更多类型文章的大型数据集上性能会急剧下降。
由于之前提出的数据集规模比较小,以及基于规则和基于机器的方法的局限性,早期的MRC 系统表现不佳,很难用于实际应用。自2015年以来,随着神经网络的发展,经过预训练的词向量技术(如Word2Vec、Glove、FastText等)[3-5]也取得了一定的进步,对词语以及文章的表示有了很大的提升,另外Seq2Seq 结构[6]的神经网络和Attention注意力机制[7]的提出使得设计更复杂的网络模型成为可能。DeepMind研究人员Hermann等人[8]提出了一种新颖而代价小的解决方案,用于为学习阅读理解模型创建大规模的有监督训练数据,构建了CNN/Daily Mail数据集。他们还提出基于注意力的LSTM模型the attentive reader,the impatient reader,它们在很大程度上优于传统自然语言处理(Natural Language Processing,NLP)方法。
2016 年Chen 等人[9]研究了上述的数据集并证明了一个简单、精心设计的神经网络模型能够将CNN 数据集的性能提升到72.4%,Daily Mail 数据集的性能提升到75.8%。与传统的基于特征的分类器相比,神经网络模型能够更好地识别词汇匹配和释义。但由于数据的创建方法和一些其他误差,数据集有噪声限制了进一步的发展。
为了解决这些限制,斯坦福大学Rajpurkar等人[10]收集了Stanford Question Answering Dataset(SQuAD)数据集。数据集包含536 篇维基百科文章的10 万个问答题,每个问题的答案都是对应阅读段落的文本。该数据集质量高且能够可靠地评估,成为了领域的中心基准。推动了一系列新的阅读理解模式,截至2018年10月,表现最好的单一的BERT[11]模型系统实现了91.8%的F1值,已经超过人类的成绩91.2%。
随着GPT[12]、BERT等预训练模型的出现,以及在阅读理解任务上的强大性能提升,诞生了一批优秀的预训练语言模型。在SQuAD 数据集之后,斯坦福大学又发布了SQuAD2.0[13]数据集,相比之前增加了一些不存在答案的问题,增加了难度。微软亚洲研究院发布了来源于真实应用场景的数据集MS MARCO[14],国内百度公司发布了基于百度搜索和百度知道的中文DuReader数据集[15]。近年来国内也出现了在法律、军事等方面的阅读理解数据集,扩宽了阅读理解的应用,也增加了一些难度。
2 基于预训练模型的MRC
2.1 问题定义
传统的阅读理解是通过阅读给定的文章来回答相关的问题。随着机器学习与深度学习的技术发展,近年来将机器阅读理解作为一个有监督任务来进行学习训练,训练样本集D 可以用三元组的形式定义如下:
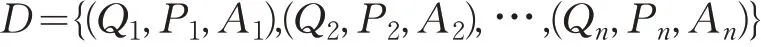
具体的任务是给定一个三元组(Qi,Pi,Ai),根据问题Qi={q1,q2,…,qm}和与其对应的文章Pi={p1,p2,…,pn}进行自然语言理解,推理预测得到答案Ai。其中,qj与pj分别是问题与文章的字或者词的表示,m 与n分别代表问题与文章的长度。根据数据集及机器阅读理解任务的不同,答案Ai的形式也有所区别,抽取型任务的答案一般出现在原文Pi中,而描述型任务的答案可以是整个字典中的任意字符。
在预训练语言模型出现之前,基于深度学习的机器阅读理解可以分为多个模块[16],主要包括词嵌入层、编码层、匹配层以及答案选择层,机器阅读理解的发展依靠各个模块的结合。然而,这种方式的组合存在一定的缺点,传统的词向量无法解析一词多义的问题,注意力模块的网络结构比较复杂,且对长文本的处理比较吃力,即使ELMO[17]等动态词向量的出现,对模型的效果提升也比较有限。
GPT、BERT 等预训练模型提升了机器阅读理解的性能,在某些数据集上超越了人类的表现。预训练模型前期通过语言建模在大量自然语言上进行半监督训练,如掩码预测、句子关系的预测,以及自然语言的多任务训练等。通过在大量文本上进行预训练,得到强健的语言模型,可以捕获句子间更深层次的关联关系。在做机器阅读理解任务时,只需要设计适合具体任务的网络拼接到预训练模型网络上进行微调即可,基于预训练模型的机器阅读理解与传统结构对比如图1所示。
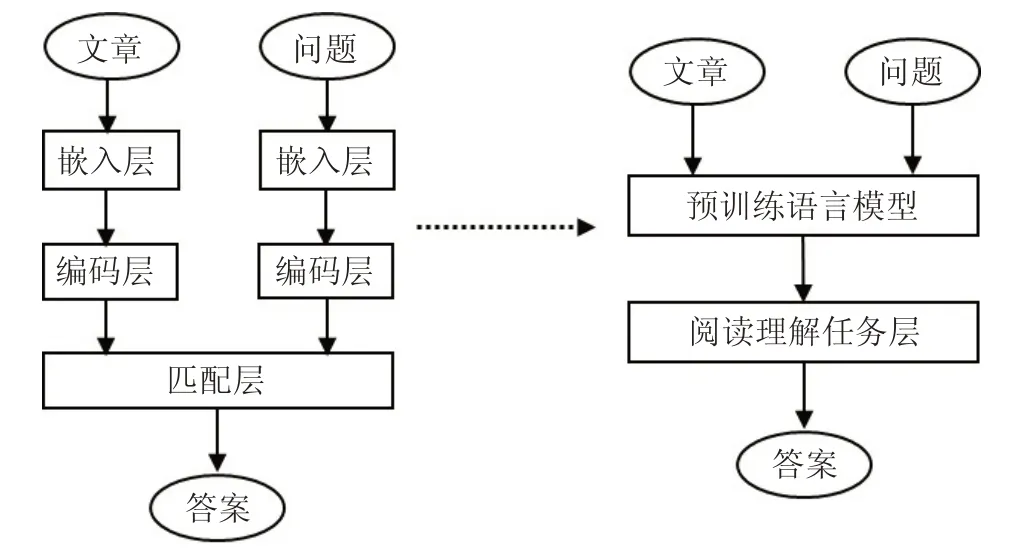
图1 机器阅读理解模型结构对比
2.2 预训练模型
预训练语言模型属于迁移学习,迁移学习在计算机视觉领域中已经很流行,因为它可以建立精确的模型,耗时更短。利用迁移学习,不是从零开始学习,而是从之前解决各种问题时学到的模式开始。这样就可以利用以前的学习成果(例如VGG[18]、MobileNet[19]等图像处理模型),避免从零开始,可以把它看作是站在巨人的肩膀上。
近年来NLP 领域的一些研究者也尝试通过迁移学习的方式建立预训练语言模型,将在通用领域通过无监督方法学到的知识迁移到有监督任务上,诞生了一批优秀的预训练语言模型。由于NLP 领域本身无监督数据存在很多,具有天然优势。只需要设计合适的语言模型,在无监督数据集上进行大量训练,即可得到健壮的语言模型。在做具体的有监督任务时,可以将学到的语言知识迁移到各个NLP任务上。
常见的预训练语言模型结构如图2 所示[11],有编码输入层、网络结构层、编码输出层。预训练语言模型的区别主要体现在网络结构层以及预训练时对语言建模的任务。如ELMO使用双向LSTM结构,BERT、GPT使用Transformer[20]结构。与LSTM相比,Transformer中引入self-attention 结构与多头注意力机制,可以捕获更多的文本信息,同时Transformer 可以做到并行化计算以及设计更深的神经网络。本文将近年来出现的预训练语言模型根据建模方式、模型结构、模型介绍等进行整理,如表1所示。
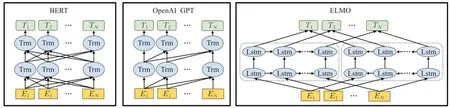
图2 常见预训练语言模型结构
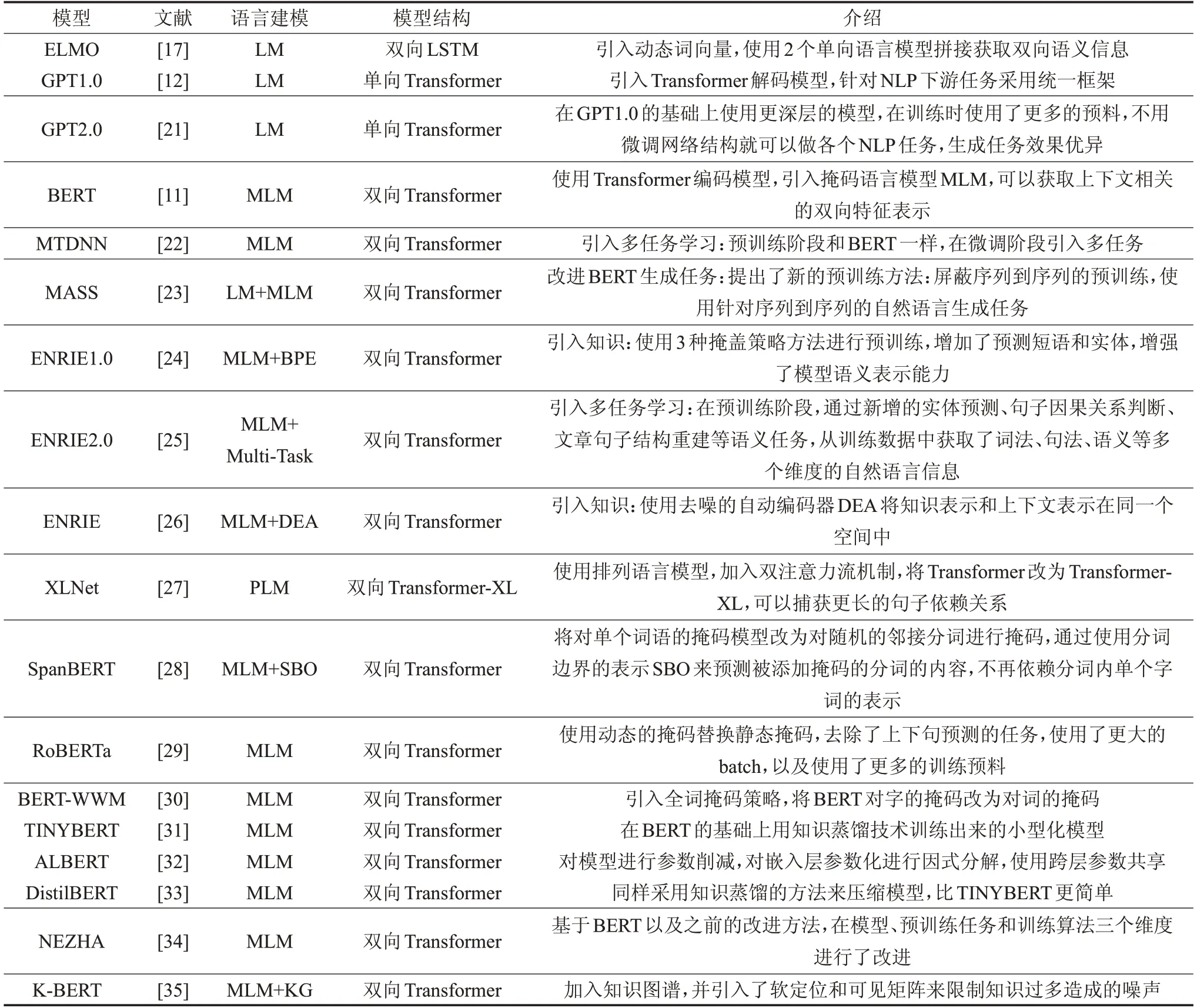
表1 预训练语言模型对比
在ELMO以前解决阅读理解的思路是通过Word2Vec等获取固定的词向量,或者随机初始化词向量,将字词的表征送入神经网络。ELMO 将通过预训练得到的字词表征以及网络结构信息保存,在具体的阅读理解任务时,把学到的句子特征信息也能应用到具体的任务。GPT 引入Transformer 解码模型,并使用单向的语言模型,针对NLP下游任务采用统一框架。BERT结合GPT与ELMO的优势,引入Transformer编码模型,采用双向的语言模型,训练时增加了掩码语言模型MLM[11]以及判断句子顺序的任务,可以获取更多的语言表征。MASS[23]改进BERT 生成任务,提出了屏蔽序列到序列的预训练方法,使用针对序列到序列的自然语言生成任务。百度公司提出的ENRIE1.0[24]和清华大学提出的ENRIE[26]模型引入外部知识到预训练过程,MTDNN[22]以及ENRIE2.0[25]引入多任务学习到预训练过程。XLNet[27]使用排列语言模型,加入双注意力流机制,将Transformer改为Transformer-XL[36],可以捕获更长的句子依赖关系。RoBERTa[29]使用动态的掩码替换静态掩码,去除了上下句预测的任务,使用了更大的batch,以及使用了更多的训练预料。BERT-WWM[30]引入全词掩码策略,将BERT对字的掩码改为对词的掩码。TINYBERT、ALBERT以及DistilBERT等[31-33]通过对模型进行蒸馏获取小型化模型,方便模型的部署。NEZHA[34]通过对在模型、预训练任务和训练算法三个维度进行了改进,K-BERT[35]加入知识图谱,并引入了软定位和可见矩阵来限制知识过多造成的噪声。
2.3 模型使用方法
经过预训练得到的语言模型具有强大的语言表征能力,但应用到机器阅读理解任务上还需要进行领域微调、任务微调等方法。将预训练语言模型迁移到机器阅读理解任务上有以下几种方法:
(1)领域微调
由于具体的机器阅读理解任务与通用领域的数据存在差别,在具体任务之前,可以在任务数据上进行领域增量学习,使得最终的语言模型更靠近目标任务。具体做法,可以将目标任务的数据进行处理,处理为预训练任务需要的输入格式,然后进行增量训练。
ELMO 以及GPT 系列[12,21]等采用自回归语言模型的预训练方法,BERT 采用基于去噪自编码器方法进行训练,构建掩码预测与上下句预测任务,MASS 需要构建序列到序列的自然语言生成任务,ERNIE与BERT衍生系列[24-35]进行领域微调时可参考具体的预训练任务进行设计。XLNet 加入了排列语言模型通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息,用自回归本身的特点克服BERT 的缺点。设计好任务后将数据送入模型,设置好模型基本参数,当模型的损失降下来时即代表模型在目标领域微调完成。通过领域微调可以较好地应对目标数据集较小的情况,在公共领域数据集上获取较好的语言模型,然后在目标数据集上进行微调获取与数据集相关的特征。
(2)解决长度限制
由于机器阅读理解任务很多篇章都会超过预训练模型的最大长度限制,如BERT模型单条最大处理文本长度为512个字符,因此绝大多数情况下需要做截断或者更换模型结构等操作。
①筛选最相关段落
将输入段落根据长度限制进行分段,段和段之间有重叠部分,保证不遗漏重要信息。然后设计一个段落分类网络,输入问题和段落,以答案是否在这个段落里为标签进行训练,针对数据集中篇章比较长的问题有很大帮助。
②滑动窗口
由于预训练模型单次能处理的最大文本长度为512,当输入序列大于这个长度时,设定一个滑动窗口,将超过512的输入序列进行分段,在第二段保留滑动窗口大小的文本长度以便于模型能连续处理上下文信息,不至于把段落信息完全分开。在最终答案选择的时候,选择在包含最大上下文的序列中输出答案。
③使用Transformer-XL
Transformer-XL 架构在Vanilla 提出的Transformer基础上引入了两点创新:循环机制和相对位置编码,以克服Transformer存在难以处理长文本的缺点。Transformer-XL的另一个优势是它可以用于单词级和字符级的语言建模。通过Transformer-XL 可以提升模型在长文本上捕捉信息的能力以及加快模型的推理速度。
(3)任务微调
根据数据集的特点设计不同的微调网络结构,使得模型可以充分利用已训练好的网络参数,加快在有监督任务上的训练速度,提高准确率,基于BERT 模型的预训练任务和机器阅读理解的微调结构如图3所示[11]。左侧是预训练过程,经过预训练得到较好的模型参数。右侧是用于机器阅读理解的微调示意图,将问题与包含答案的上下文经过编码输入神经网络,神经网络的参数由预训练得到的模型进行初始化。
预训练模型中做有监督任务微调时最低层共享一个公共架构,通过调节高层的任务架构来实现不同任务的微调。ELMO 微调时考虑双向LSTM 无监督模型的高层任务架构。GPT系列通过目标任务训练模型后,将参数调整到监督目标任务中。BERT系列任务微调除了输出层之外,在预训练和微调中使用了相同的体系结构,相同的预训练模型参数用于初始化不同下游任务的模型。百度提出的ERNIE模型预训练时构建无监督预训练任务和多任务学习进行增量的更新,微调阶段可以有效地利用预训练学习的知识。由于BERT 预训练过程需要掩码一部分输入,忽略了被掩码位置之间的依赖关系,易出现预训练和微调效果的差异。XLNet用自回归本身的特点克服BERT的缺点,还融合了当前最优自回归模型Transformer-XL。
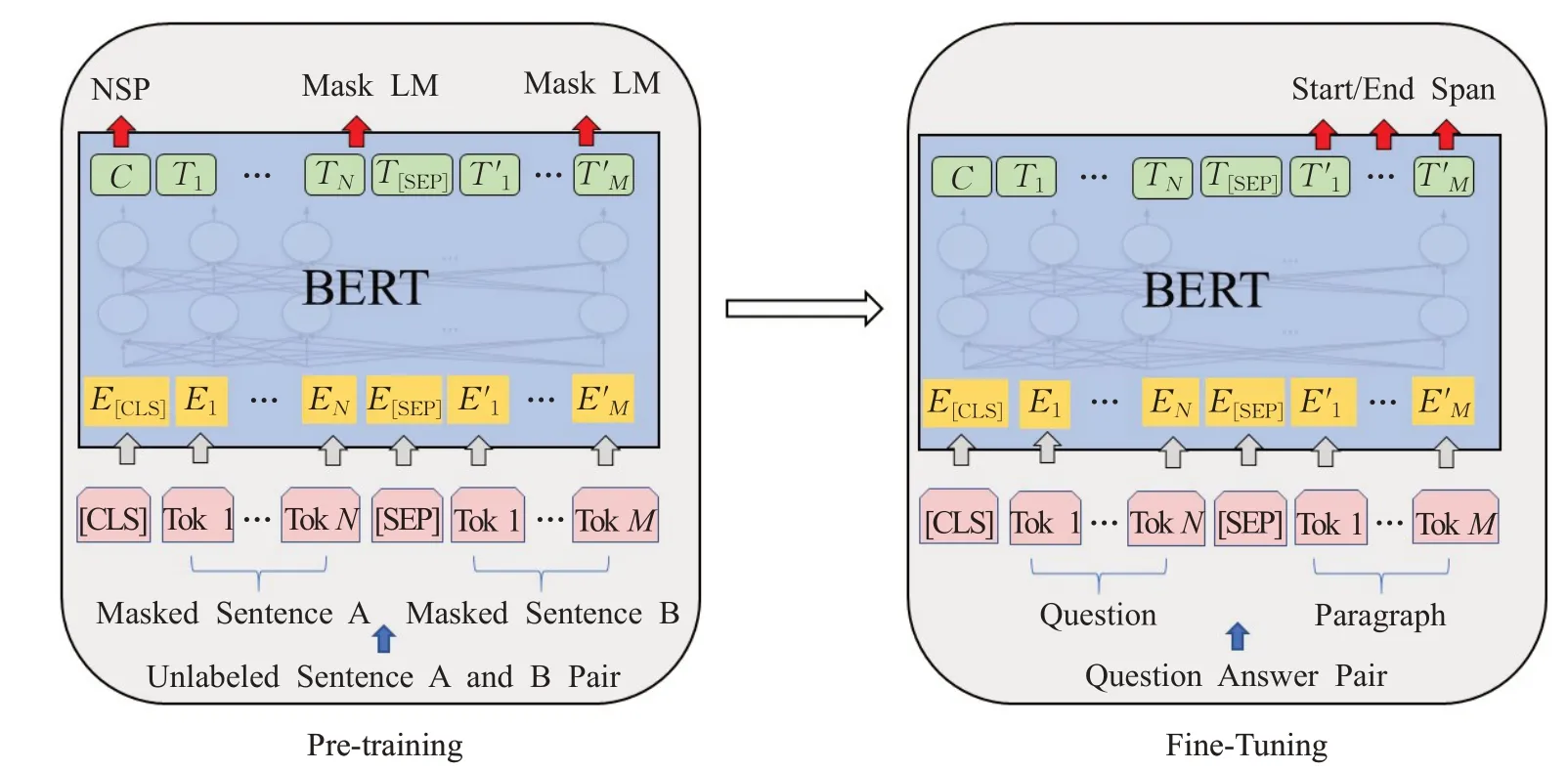
图3 预训练与机器阅读理解任务微调
2.4 数据集
近年来发布的各种大型、真实的数据集推动了机器阅读理解领域的快速发展。大规模数据集的出现使得端到端神经机器阅读理解模型的训练成为可能。从单词表示、注意力机制到预训练语言模型,神经网络模型发展迅速,甚至在某些数据集上超越了人类的表现。每个机器阅读理解数据集通常由文档和测试文档理解能力的问题组成。问题的答案可以通过从文档中查找或提供的候选答案里来获得。在这里根据答案的格式,可以大致将数据集分为四种类型,即完形填空、多项选择、抽取型、描述型数据集。与此同时,还不断有新的数据集出现,其中包含了更多样化的任务,测试了更复杂的理解和推理能力。
本文将数据集根据语言、数量、来源等特征进行整理,如表2 所示,并将机器阅读理解相关数据集获取方式进行汇总托管于GitHub(https://github.com/crlgdx/MRCDataset)。
2.5 评价方法
对于不同的MRC 任务,有不同的评估指标。要评估完形填空和多项选择任务,最常见的评价指标是准确率。在抽取型任务中通常使用EM(精确匹配)和F1 值进行评价,在描述型任务中,因为自由做答不局限于原始上下文,所以ROUGE-L[48]和BLEU[49]被广泛使用。
EM 算法的思想与准确率类似,用于评估预测的答案是否与参考答案完全匹配。F1值计算方式是一种模糊匹配,将预测的答案短语切成词后与参考答案共同计算准确率与召回率,即便预测答案和参考答案不是完全匹配也可能得分。Rouge 是评估自动文摘以及机器翻译的一组指标。它将通过机器自动生成的摘要或翻译与参考答案进行比较计算,得出相应的分值,以衡量自动生成的摘要或翻译与参考答案之间的“相似度”。BLEU最初用于评估翻译性能。在应用到MRC任务时,BLEU评分主要衡量预测答案与标准答案之间的相似性。
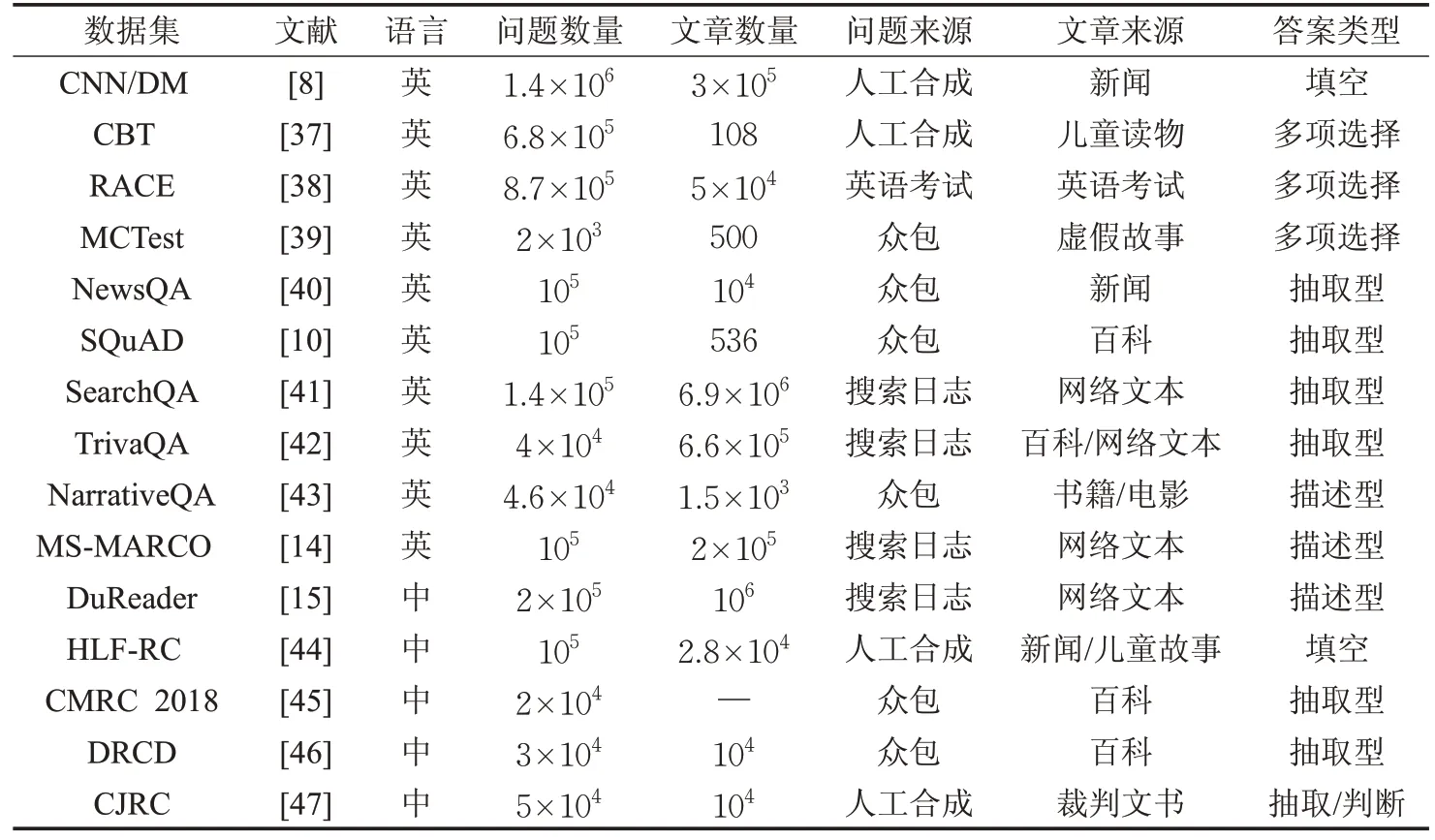
表2 机器阅读理解数据集汇总
3 性能分析
早期的机器阅读理解采用模块分离的方式进行设计,通过词嵌入层、编码层、匹配层以及答案选择层各个模块共同组合进行机器阅读。而早期的词向量技术和网络结构不够成熟,限制了模型的表达与计算能力。预训练语言模型的发展使多个NLP 任务取得了明显的进步,增强了语言表征能力,同时也推动了机器阅读理解的进步。
表3和表4将当下预训练模型相关论文中提到的数据集以及性能得分进行汇总,表3 是目前比较常见的SQuAD 1.1和SQuAD 2.0数据集。通过对比可以看出预训练模型优于传统模块分离方式的性能,带来绝对的效果提升。在XLNet 以及后续的BERT 系列的改进版本中性能逐渐提升,说明预训练模型还需要进一步发展。表4 汇总了预训练模型在相关中文数据集上的表现,由表中CMRC、DRCD、DuReader数据集的表现可以看出描述型任务的数据集比抽取型任务的数据集要更复杂、更困难。再通过CMRC与CJRC数据集的性能对比,可以看出专业性较强的任务也会更复杂。CMRC是通用领域的数据集,而CJRC是法律领域的数据集,预训练模型在专业知识较强的领域上还有很大的提升空间。
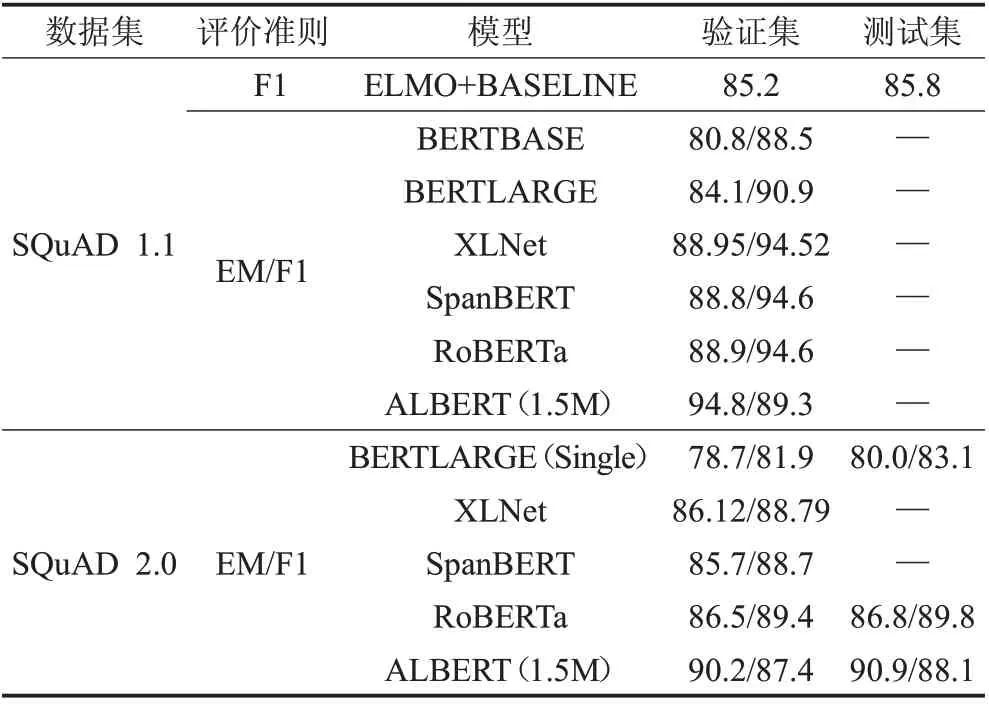
表3 预训练模型在英文数据集上的性能表现 %
4 研究趋势
(1)模型轻量化
在预训练模型技术的推动下,模型的网络结构越来越复杂,参数也越来越多。复杂的网络带来了性能提升的同时,也带来了应用的困难。首先模型需要在大量的无监督数据集上进行预训练,需要大量的时间以及巨大的运算资源。按照BERT论文里描述的参数,其基础版模型的设定在消费级的显卡Titan x 或GTX 1080ti(11 GB RAM)上,需要近几个月的时间进行预训练,同时还会面临显存不足的问题。其次,复杂的网络结构很难做到实时的响应,而用户的需求一般需要在秒级内进行响应,这对服务器的性能也提出很大的要求。
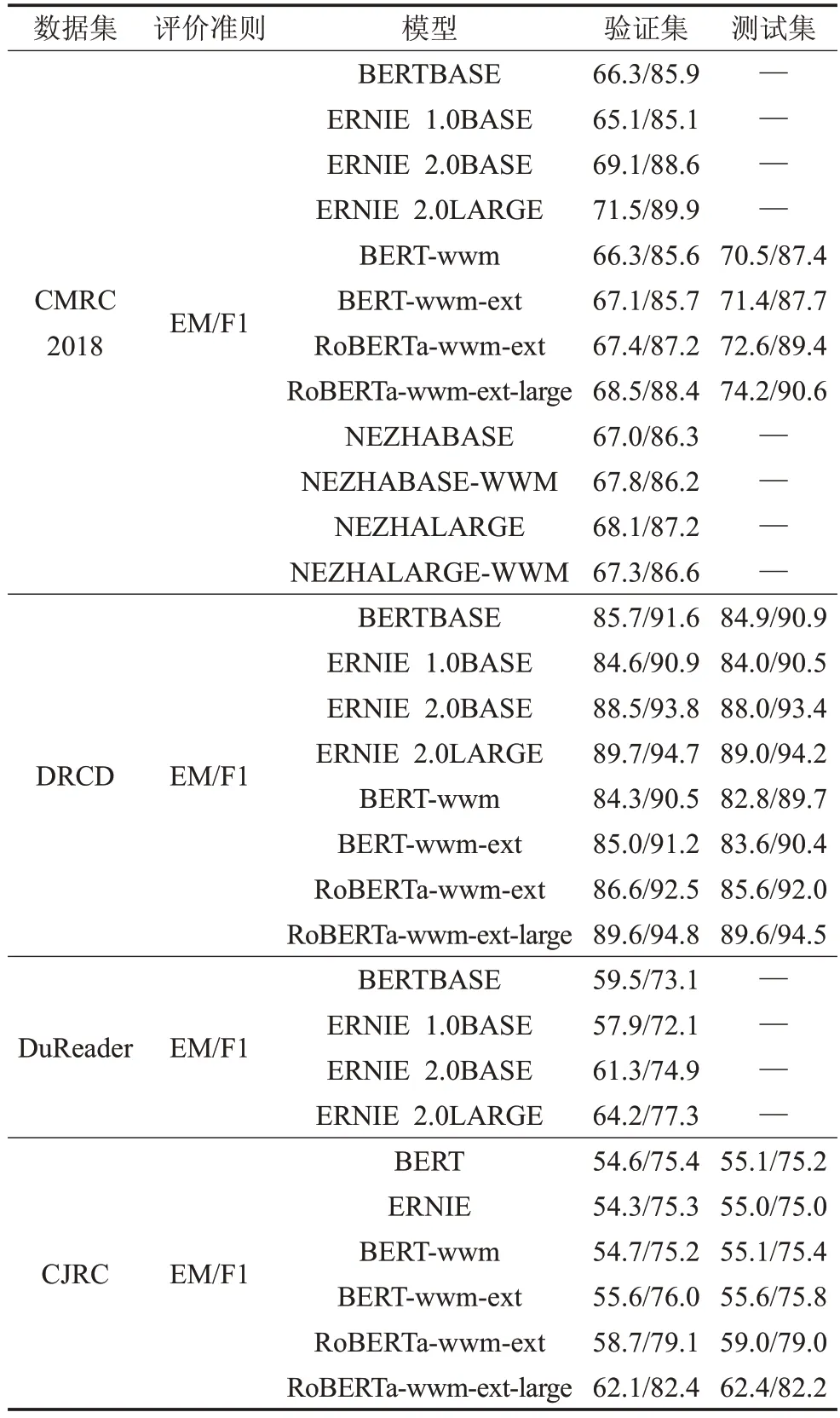
表4 预训练模型在中文数据集上的性能表现%
针对模型参数较大,网络复杂的情况,研究员也提出了一些新的模型,如对网络蒸馏、嵌入层因式分解、跨层网络参数共享等。
ERNIE Tiny 是一个小型化ERNIE[24],通过采用浅层模型,将12层的ERNIE Base模型压缩为3层,线性提速4 倍,但效果也会有较大幅度的下降;增加隐藏层的数量,模型变浅带来的损失可通过隐藏层的增大来弥补。由于ERNIE采用的框架对于通用矩阵运算的最后一维参数的不同取值会有深度的优化,因此增加将隐藏层大小不会带来速度线性的增加;缩短输入文本长度,ERNIE Tiny 是首个开源的中文词粒度的预训练模型。这里的短是指通过词粒度替换字粒度,能够明显地缩短输入文本的长度,而输入文本长度是和预测速度有线性相关;为了进一步提升模型的效果,ERNIE Tiny扮演学生角色,利用模型蒸馏的方式在Transformer 层和Prediction层去学习教师模型ERNIE模型对应层的分布或输出,这种方式能够缩近ERNIE Tiny 和ERNIE 的效果差异。
在ALBERT[32]中通过对Embedding层进行因式分解,缩减网络参数,由于在BERT 中,字词Embedding 与Encoder输出的Embedding维度是一样的。但是ALBERT作者认为,词级别的Embedding是没有上下文依赖的表述,而隐藏层的输出值不仅包括了词本身的意思还包括一些上下文信息,理论上来说隐藏层的表述包含的信息应该更多一些,因此应该让隐藏层大于嵌入层,所以ALBERT的词向量的维度小于Encoder输出维度。跨网络层的参数共享是提高参数使用效率的另一种方法,共享参数的方法有多种,例如只跨层共享前馈网络参数,或只共享注意力参数。
(2)结合外部知识
像BERT 这样的无监督预训练语言表示模型已经在多个NLP 任务中取得了最先进的结果。这些模型是在大型开放域语料库上预先训练的,以获得一般的语言表示,然后在特定的下游任务中进行微调,以吸收特定领域的知识。然而,由于训练过程与微调领域的数据集存在差异,对于某些需要相关领域知识很强的问题,在公共领域训练的模型将会比较吃力。
针对预训练与微调差异较大的问题可以结合外部知识进行辅助微调,如结合专家知识,结合领域内已有的知识图谱帮助模型获取更多领域相关的知识。当阅读一个特定领域的文本时,普通人只能根据上下文来理解单词,而专家则可以用相关的领域知识进行推理。
为了使模型充分利用外部知识,清华大学Zhang等人[26]认为知识结构中的信息实体可以通过外部知识增强语言表征,利用大规模的文本语料库和知识库来训练一个增强的语言表示模型。百度公司Sun等人[24]提出的ERNIE 1.0 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识,增强了模型语义表示能力。后来提出基于持续学习的语义理解预训练框架ERNIE 2.0[25],使用多任务学习增量式构建预训练任务。通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。北京大学Liu等人提出了一种基于知识图谱的语言表示模型K-BERT[35],该模型将三元组作为领域知识注入到句子中。基于知识图谱的阅读理解突破了回答问题所需的知识范围仅限于给定上下文的限制。因此,借助外部世界的知识,可以在一定程度上缩小机器理解与人类理解之间的差距,提高系统的可解释性。
(3)任务数据多样性
由于预训练时通常在有限的语料库下进行训练,因此,通过进一步对其他语料库进行预训练,增加多样性可以提高通用性,在微调阶段使用来自不同的语料库可以作为辅助任务。向MRC添加语言建模目标的好处是它可以避免灾难性的遗忘,并保持从培训前任务中学到的最有用的功能。此外,通过合并其他NLP任务(例如自然语言推理和段落排名)的监督数据集可以学习到更好的语言表示形式。
近年来,随着机器阅读理解的发展,相关的中文数据集也逐渐增多。人们对各种信息的需求也日益增加,数据集逐渐扩展到各个领域,出现了针对法律案件[47]、军事信息等相关的数据集。数据集的多样性可以丰富机器阅读理解任务,同时也带来更多可能。
现有的模型对于存在噪声的例子还很脆弱,这将成为在现实世界中部署这些模型时所面临的一个严重问题。而且目前的大多数工作都是对同一个数据集分割进行训练和评估,如果在一个数据集上训练模型,并在另一个数据集上进行评估,由于它们的文本来源和构造方法不同,性能将显著下降。需要考虑如何创造更好的对抗训练示例并且将它们加入到训练过程中对迁移学习和多任务学习进行更多深入的研究,建立跨数据集的高性能模型。
(4)合适的评估指标
评估指标是衡量机器阅读理解水平的清晰指标,但是目前对模型性能的评价大多在比较单一的任务上。模型在某一个数据集上性能比较好时,在其他数据集上效果往往会比较差。在单一任务或者单一数据集上性能的提升是否意味着模型取得了真正的进步?如何判断阅读理解模型与真正的人类阅读理解水平之间的差距是一个比较有挑战的问题。
评价模型性能时可以参考人类的阅读理解考试[50],因为这些问题通常是由专家学者共同策划和设计,以测试人类阅读理解能力的不同水平。在构建自然语言理解系统时,使计算机系统与人类评价系统保持一致是一种正确的方法。在未来,对模型的评价不能只在一个数据集上进行测试,需要将许多阅读理解数据集结合起来,作为一个通用的标准进行评估,这将有助于更好地区分哪些模型是对阅读理解真正的进步。
5 机器阅读理解应用
(1)辅助决策
机器阅读理解技术作为人工智能领域重要的研究方向,主要是让机器读懂文本、理解语义、挖掘推理出关键信息,帮助人类从海量碎片信息中获取所需知识。在数据大爆炸的时代,如何快速地获取用户关心的信息帮助用户进行决策是一个有挑战的任务。尤其是面对专业性比较强的领域,如医生的诊断记录,金融行业的历史数据,法院的判决书等,这些都需要用户具备较多的相关知识储备,需要前期大量的准备工作,消耗大量的人力物力。在知识赋能的信息化时代,通过机器阅读理解可以快速地搜集用户所关心的资料,帮助用户分析问题解决问题,并给出合理的建议。因此,将机器阅读理解引入专业性较强的领域,可以帮助用户更好地决策,更有效地工作。
(2)社区问答
网络技术的飞速发展推动了互联网中的用户生成内容的规模不断增长,作为一种新的网络信息资源,高质量的用户生成内容的研究和应用价值正逐渐显现。由问题和其答案组成的问答对是用户生成内容的典型代表,是用户之间以互联网为媒介的知识分享行为的直接产物。传统的社区问答主要基于检索去匹配用户的问题并寻找答案,这样得到的答案往往包含大量的噪声,而通过与机器阅读理解相结合的方式可以从包含着大量噪声信息的网络社区内容中自动识别和抽取问答信息,快速精准地得到用户所关心的答案。
(3)聊天机器人
智能聊天机器人,是一种通过自然语言模拟人类进行对话的程序,可以对外提供客户服务、对内进行业务辅助,实现全方位的效能提升,降本增效。目前,特定场景和领域的聊天机器人已经展现出了很高的自然语言理解与处理能力,例如:小度、Siri、小爱同学等。智能聊天机器人除了可以闲聊以外,还可以用在问答作为问答机器人,回答专业领域的问题。未来,与机器阅读理解相结合的技术将使得聊天机器人能够更准确地识别用户的问题和意图。
