语音情感识别综述
2020-06-09孙晓虎李洪均
孙晓虎,李洪均,2,3,4
1.南通大学 信息科学技术学院,江苏 南通226019
2.计算机软件新技术国家重点实验室(南京大学),南京210093
3.南通大学 智能信息技术研究中心,江苏 南通226019
4.南通大学 通科微电子学院,江苏 南通226019
1 引言
语音作为语言符号系统的载体,是由人的生理发声器官发出的。语音作为语言的第一属性,在语言中起决定性的支撑作用,不仅包含说话人所要表达的文本内容,也包含说话人所要表达的情感信息。情感与人态度中的内向感受、意向具有协调一致性,是态度在生理上一种较复杂而又稳定的评价和体验。心理学把情感定义为人对客观现实的一种特殊反映,是人对于客观事物是否符合人的需要而产生的态度体验,其本质就是人脑对于客观事物价值的主观反映。
语音情感识别是指通过计算机处理,以帧为单位对情感信号进行特征提取,模拟人类感知并理解人类的情感,进而推断出语音情感类型的一种技术。其任务是从说话人的语音中提取出与情感有关的相关特征,并找出这些特征与人类情感的映射关系。1972年,Williams和Stevens发现人的情感变化对语音的基音轮廓有很大影响[1];1987 年,美国麻省理工学院的人工智能创始人Minsky 教授在The Society of Mind 一书中提出“计算机的情感能力”这一概念[2];20世纪90年代初,美国的麻省理工学院多媒体实验室构造了一个“情感编辑器”对外界各种情感信号进行采集,用人体的生理信号、面部表情信号、语音信号等来识别各种情感,并让机器对各种情感做出适当的反映[3];1995 年,美国MIT 媒体实验室的Picard教授提出了情感计算的概念,并于1997年正式出版专著Affective Computing;1999 年,Moriyama 提出语音情感的线性关联模型并将其初步应用到电子商务中[4];2003 年,Hozjan V 等研究了基于多种语言的具体情感特征的语音情感识别[5]。
国内语音情感识别研究起步相对较晚,2003 年,北京科技大学、微软亚洲研究院以及部分大学和研究所进行了机器人的语音情感识别技术的研究;2004年以来,东南大学、江苏大学也都启动了语音情感方面的研究。近年来,在人工智能飞速发展的背景下[6-7],语音情感识别正逐渐成为一个新的研究热点,Zheng 等人[8]基于有效语音的特征集和模型对情感识别的影响,提出一种多级语音情感识别的集成模型且从三方面验证了该方法的有效性;Chen等人[9]提出一种人机交互中的两层模糊多随机森林算法,融合个性化和非个性化特征,对情绪社交机器人系统进行了初步的应用实验。
本文在回顾国内外语音情感识别发展的基础上,分别从语音情感特征、语音情感数据库、语音情感识别算法、语音情感识别的应用以及语音情感识别的挑战这几个方面对其进行了总结分析,最后基于研究现状对语音情感技术的未来发展方向进行了展望。
2 语音情感特征
根据语音情感特征具有普遍性和差异性,可将语音情感特征分为个性化情感特征和非个性化情感特征。其中,非个性化情感特征不易受说话者个人特征的影响,具有普遍性。个性化情感特征携带了大量的个人情感信息,具有差异性。目前,国内外对于语音情感特征种类还没有一个统一的划分,比较典型并且受欢迎的划分方法是将情感特征分为基于声学的情感特征和基于语义的情感特征。其中,基于声学的情感特征又划分为韵律学特征、基于谱的相关特征和音质特征。下面对这几种常见的语言情感特征进行详细分析。
2.1 韵律学特征
韵律特征又称超音段特征[10],在语音学中表现为语调、音高、音长和节奏等可以被人类感知的特征。在声学信号中,韵律特征对不同语言的语音情感识别具有较好的泛化性能,其中使用最广泛的韵律特征是基频、语音能量和持续时间。
基频即基音的频率,决定整段语音的音高,它的生理学定义是一段复杂语音中最低且通常情况下最强的频率。基频是由声带的振动产生的,其在语音变化过程中产生的基频等值线的统计特征可作为情感特征。除此之外,基频中还包含了大量表征语音情感的特征,在语音情感识别中起着至关重要的作用。其中自相关函数法、平均幅度差法和小波法为常用的基频特征提取方法。语音能量又称音强,反映了语音信号的振幅随时间的变化强弱。振幅能量是一种重要的韵律特征,包括短时能量和平均幅度。研究表明,不同情感的声音信号的振幅能量不尽相同,惊讶、高兴等情绪会导致能量增加,而悲伤、厌恶等情绪会导致能量减少。语音持续时间是表征语音信号时间的物理量,使用最广泛的持续时间特征有语音速率、清浊音持续时间等。文献[11]提出了一种基于韵律特征参数的语音情感合成算法,通过对情感数据库中生气、无聊、悲伤和高兴4 种情感的韵律参数分析,取得了78%的正确识别率;文献[12]通过构造基于韵律段特征的多重Elman网络模型,比使用定长语段特征相比有了较大的提高,取得了67.9%的识别率;文献[13]将柏林情感数据库的韵律特征和音质特征进行混合并通过多层感知器进行情感分类,取得了75.51%的识别率;文献[14]通过识别语音/非语音区间后提取韵律特征,再进行音节分割,利用深度神经网络对德语的Emo-DB 情感数据库进行情感分类。虽然基于韵律学特征对语音情感识别的作用不可忽视,但其仅从时域或频域对语音情感信息的变化进行描述,利用情感参数和区分情感的能力有限。
2.2 基于谱的相关特征
基于谱的相关特征描述了声道形状变化和发声运动之间的相关性,能够反映出信号的短时谱特性。它主要包括线性谱[15-16]和倒谱[17-18],其中线性谱包括线性预测系数、对数频率功率系数和单边自相关线性预测系数等;倒谱包括线性预测倒谱系数、单边自相关线性预测倒谱系数、感知线性预测和梅尔频率倒谱系数(Mel-Frequency Cepstrum Coefficients,MFCC)等,在倒谱中MFCC最为经典。
MFCC是Davis和Mermelstein于1980年提出来的,它基于人耳耳蜗和基底膜的特性,与实际频率成非线性对应关系。
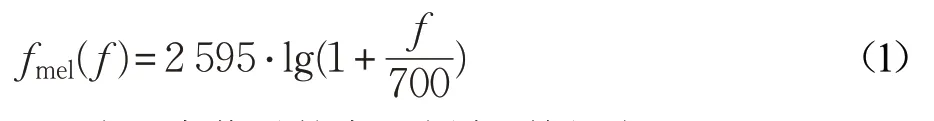
其中,f 为语音信号的实际频率,单位为Hz。
近年来,基于谱的相关特征被广泛地用于语音情感识别方法,文献[19]提出了一种基于Mel 尺度滤波器并加以改进的语音情感识别方法,在用径向基网络作为分类器的基础上,与传统的MFCC 滤波器组比较,该方法的分类精度提高了6.3%。文献[20]从心电图中提取基于Mel-频率倒谱系数对心脏类疾病进行自动分类,利用具有径向核的支持向量机对时间和频率倒谱系数特征进行分析,得到了最佳的结果。文献[21]利用MFCC技术对说话者的快乐、悲伤和愤怒这三种情绪进行测试,测试效率为80%。语谱图充分利用了语音信号中的低频信息,但存在高频信息泄露,不能充分利用上下文帧间动态信息的问题。
2.3 音质特征
音质特征用于衡量语音的纯净度、清晰度和辨识度。主要包括带宽[22]、共振峰频率[23]、振幅扰动[24]等。文献[25]为提高情感识别率,提取了18 个韵律参数和59个音质参数对5男5女的4种情感进行训练和测试。音质参数对情感识别起着有效的补充作用,文献[26]基于最小语音质量特征,采用ANN分类器分别对2 765份英语和2 240 份印地语中的7 种不同的情绪进行分类,得到了64.8%和83.3%的识别率,表明语音的音质特征是一种有效的情感特征参数。音质特征作为一种有效的情感特征参数,声音质量的变化与语音情感的表达有着密切的联系,但因特征参数维度较大而导致冗余信息干扰,无法准确获取其声门参数,仍需进一步估算。
除上述特征外,比较典型的还有基于Teager Enger算子(TEO)的特征和多模态融合特征等。TEO 能量算子是一个非线性算子,能够跟踪信号的瞬时能量,可以与基频、共振峰特征相结合形成新的语音特征。文献[27]将EMD 分解与Teager 能量算子相结合用于语音情感识别,采用SVM 分类器对不同语音语种的语音情感进行识别,取得了很好的识别结果。文献[28]利用Teager-MFCC(T-MFCC)特征提取技术从语音信号中识别出被强调的情绪,使用高斯混合模型对这些不同的强调情绪进行分类,与MFCC 特征提取技术相比,该方法具有更好的性能。目前,单模态情感识别具有识别率低、稳定性差等局限性。基于此问题,“多模态”这一概念于1997年被Bigün等人提出[29],并被成功地运用到情感识别领域。多模态融合的目的是通过对多种特征进行聚合,提高语音情感的识别率和鲁棒性。文献[30]为区分愤怒和开心这两种语音情感,结合文本信息对这两种情感进行识别,有效地解决了情感的误判情况,提高了情感识别率。为提高传统语音识别系统在噪声环境下的准确性和性能,文献[31]提出了一种新的、非传统的多模态语音识别系统。多模态情感识别已经成为研究的热点。
3 语音情感数据库
语音情感数据库作为情感特征提取与情感识别之间的关键环节,是实现情感识别的前提。语音情感数据库有按照获取途径、应用目的、语种差异、描述模型和语音的自然度等多种划分标准,但至今国内外还未将标准进行统一。目前,比较受欢迎的划分方法是按照情感描述模型将其划分为离散情感模型和维度情感模型。
3.1 离散情感模型
离散情感模型将情感定义为人们日常交互中常见的、离散的、特定的几种基本情感。离散情感模型通过判断相邻两帧数据或两个不同时刻的情感变化来衡量情感的属性。目前,离散情感数据库主要有德语的Emo-DB[32]、英语的Belfast[33]、瑞士的RECOLA、汉语的CASIA等,如表1所示。
3.2 维度情感模型
维度情感模型将情感定义为连续情感空间中的不同坐标点,每一个空间维度都代表了不同的心理学属性且其数值大小与其在相应维度上表现出的强度呈映射关系。维度情感模型根据维度的多少可以分别用向量和张量来表示,且不同情感状态彼此间的相似度和差异性可以根据它们在空间中的距离来衡量。维度情感数据库相对离散情感数据库来说只占少数,目前存在的主要有VAM[34]、Semaine[35]等,如表1所示。
维度情感模型的代表性维度理论有一维情感模型、二维情感模型、三维情感模型和其他多维度情感模型。一维情感模型用一根实数轴来量化情感,正半轴表示快乐,负半轴表示不快乐。二维情感模型从极性和强度两个维度区分情感,这种情感描述比较符合人们对客观世界的基本看法。三维情感模型主要有PAD[36],其中PAD三维情感模型是当前受欢迎度较高的一种三维情感模型,能够描述绝大多数的情感,其中P代表愉悦度,A代表唤醒度,D代表优势度。对于多维情感模型主要有Izard四维模型、Krech四维模型和Frijda六维情感模型等。
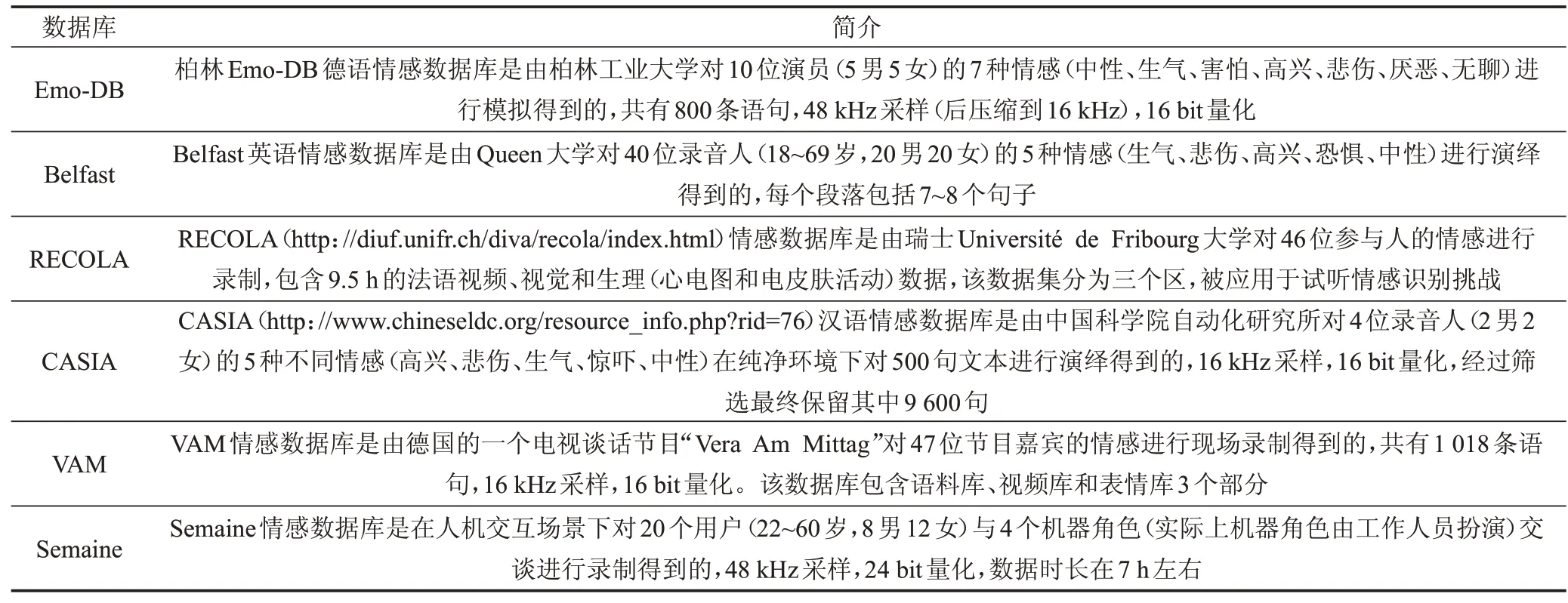
表1 语音情感数据库
3.3 离散-维度情感模型
离散情感模型和维度情感模型各有优劣,前者简洁明确、容易上手,但描述能力有限;后者有更强的描述能力,但模型转换的复杂度较高。基于此问题,为了探索离散情感模型与维度情感模型之间的联系,文献[37]建立了一种离散标签与维度空间结合的汉语情感语音数据库。该数据库由16名说话人对文本语料进行表演录制而得,5 376条语音样本共包含7种情感。通过从情感的一致性、集中性、差异性以及情感识别率这四个方面来分析数据库的情感质量。该数据库的情感一致性较高,且情感之间具有较明显的可区分性。
4 语音情感识别算法
语音情感识别一直是一个备受关注的研究领域。人类情感的表达是通过多种形式同时进行的,如通过脉搏、心率等难以观测到的内在信息和语音、面部表情等易于自然观测到的外在信息。情感计算理论的提出就是赋予计算机感知理解和表达情感的能力,以推动人机交互技术的进一步发展。情感识别算法作为语音情感识别系统中的关键一环,在整个系统中起着举足轻重的作用。为提高语音情感识别的准确率和效率,科研人员在神经网络发展(如图1 所示)的基础上提出了诸多优秀的算法并对其中的一些算法进行了改进。
目前,语音情感识别算法根据模式识别分为模板匹配法、概率统计法和辨别分类器;还可划分为以隐马尔可夫模型[38](Hidden Markov Model,HMM)、高斯混合模型[39](Gaussian Mixed Model,GMM)和K 近邻法[40](K-Nearst Neighbors,KNN)为代表的基于统计的分类器和以人工神经网络[41]、决策树[42]和支持向量机[43](Support Vector Machine,SVM)为代表的基于判别的分类器。本文将分别从基于传统机器学习算法和基于深度学习算法两个方面对语音情感识别算法进行阐述,并且对不同类型的情感识别方法综合性能进行了总结分析,如表2所示。
图1 神经网络的发展示意图
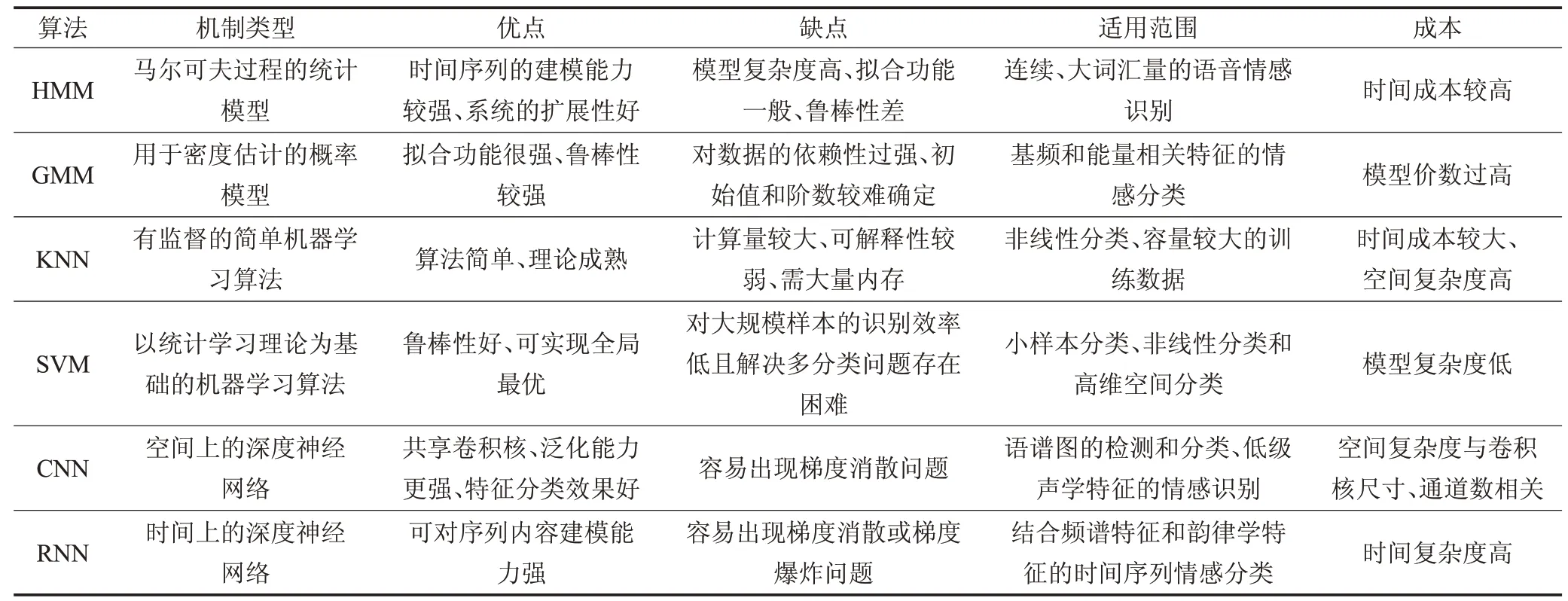
表2 不同类型的情感识别方法综合性能分析
HMM是用来描述一个含有未知参数的马尔可夫过程的统计模型,创立于20 世纪70 年代,并在20 世纪80年代得到了传播和发展,目前已成功地用于语音情感识别。HMM 适合于时序序列的识别且系统的扩展性好,只需对新样本进行训练,但HMM对语音情感数据的拟合功能一般,受音位信息的影响较大且对邻近情感的区分性差。针对HMM 识别语音情感的缺陷,文献[44]提出了一种改进的HMM/RBF混合模型识别方法,将神经预测器引入HMM 计算状态观察概率,使得HMM 能够有效利用帧间信息。
GMM是一种将一个事物分解为若干的基于高斯概率密度函数来描述语音特征矢量的模型,该模型已经在语音识别等领域取得了巨大的成功。GMM的优点是对语音情感数据的拟合能力较高且其鲁棒性高于HMM,缺点是模型的价数过高、对训练数据的依赖性强。基于此缺点,文献[45]提出一种基于改进GMM 模型的语音情感识别方法,通过用矢量量化误差值取代传统的输出概率值来计算模型的得分,使得建模时所需训练数据量减少,并且识别速度有所提高。
KNN是数据挖掘分类技术中最简单的机器学习算法之一,其核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别且具有这个类别上样本的特性。文献[46]基于KNN 比较了四种不同加权函数对情感识别率的影响,最高识别率达到81.4%。KNN 算法易于实现,较符合语音情感数据的分布特性,对语音情感数据的拟合能力较高,但其计算量较大。
SVM于1964年被提出,在20世纪90年代后得到了迅速发展并衍生出一系列改进和扩展的算法。SVM是建立在结构风险最小化准则的基础上对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM 适合于小样本训练集,对语音情感数据的拟合能力较高,能较好地解决局部值问题以实现全局最优,但SVM 在多分类问题中存在不足。文献[47]提出一种自适应的SVM增量算法,有效解决了增量数据和大规模数据问题;文献[48]提出的基于决策树和改进SVM 混合模型有效地避免了无界泛化误差、分类器数目多、受限优化等问题;文献[49]提出一种基于典型相关性分析的改进模糊支持向量机算法,解决了语音特征参数对某类情感具有不确定性的问题。
随着深度学习的发展,科研人员将更多的注意力转移到直接从原始数据中自动学习最佳特征的研究中。深度学习分为监督学习、半监督学习和无监督学习。大多数情感识别算法都是基于监督学习,且其典型代表算法有深度神经网络[50](Deep Neural Network,DNN)、卷积神经网络[51](Convolutional Neural Network,CNN)和循环神经网络[52](Recurrent Neural Network,RNN)等。
DNN 由机器学习的神经网络发展而来,模仿人脑的机制来解释数据,结构是含多隐层的多层感知器,是深度学习的基础。深度神经网络最早被应用在语音识别领域,近年来,随着模式识别的发展,深度神经网络在语音情感识别方面取得了巨大的突破,并且在情感识别领域衍生出许多新的DNN框架。
CNN 是一类包含卷积计算且具有稀疏连接、参数共享和相等表示特性的前馈神经网络,能够按其阶层结构对输入信息进行平移不变分类,是模式识别中应用最多、最成功的一种前馈神经网络。CNN 的研究始于20世纪80 年代,最早被广泛应用于图像识别领域且取得了巨大的成功。21世纪后,随着深度学习的迅速发展以及GPU 计算能力的提升,CNN 被广泛应用于计算机视觉、模式识别等领域,现已延伸到语音识别领域对情感进行判别。CNN有很强的泛化能力、特征分类效果好,但其容易出现梯度消散问题。文献[53]提出一种改进的CNN的语音情感识别方法,改进了CNN训练过程中卷积核权值的更新算法,使卷积核权值的更新算法与迭代次数相关联,提高了卷积神经网络的表达能力。
RNN 的研究始于20 世纪80 到90 年代,并在21 世纪发展为深度学习算法之一,具有良好的记忆性和参数共享性。除此之外,RNN 对非线性特征学习时具有一定的优势,在处理时序数据时比CNN 有更好的表达能力,但普通的RNN 随着时间的延长可能会出现梯度消失问题。文献[54]采用代价敏感交叉熵损失训练的多任务深双向长短期记忆RNN 对这些标签进行联合建模,证明了提出的方法在RECOLA 数据集上实现了有竞争力的纯音频性能,并为持续的情绪识别提供了一种替代方法。
5 语音情感识别的应用
语音情感识别是一门涉及数字信号处理、数理统计、计算机学科、神经科学、心理学以及情感学等多种学科融合交叉的新兴领域。随着人工智能的兴起,语音情感识别技术取得了巨大的突破且被应用到多种领域,已经走进了人们的生活。
在教育领域[55],可以通过语音情感识别系统实时掌握学生的情感状态,利用其对情感特有的分析辨别能力,实时分析系统接收到的学生回复,及时地了解和把握学生的真实情感状态,从而迅速做出反馈并进行调整,大大增强了课堂效果和提高了学生的学习效率。例如,传统的授课方式无法让教师时刻了解学生的课堂状态,而语音情感识别系统可以通过学生在课堂回答问题时的语音情感推断出其处于积极、自信、消极或者紧张等情感状态并将其进行情感分类,然后教师可针对其情感状态进行一对一的情感互动,鼓励并促进学生进行高效的学习。文献[56]面向本科教育进行了一次语音情感识别实验,结果表明语音情感识别有助于激发学生的学习兴趣,加深学生对知识的理解并有助于开拓学生和科研工作者的思路。目前,腾讯、百度和科大讯飞等公司都将基于情感识别的智能化教育作为其未来发展方向之一。
在医学领域[57],面对诸多医患之间无法沟通交流的现象,语音情感识别系统发挥了极其重要的作用。当遇到情绪波动、抗拒交谈或是精神受创、难以沟通的患者,语音情感识别系统将会迅速做出反应并分析患者此刻的心理状态,与患者进行情感的互动,平复患者的情绪;对于独自居家的老人,语音情感系统同样会自动识别老人的情绪波动,与其进行有效地沟通,通过精神的慰藉和力所能及的帮助,尽量为老人们营造健康的生活环境。南通市肿瘤医院[58]设计了一种基于语音分析的肿瘤病人心理情感的判断系统,针对不同病人的不同心理特点进行不同的护理干预以促进肿瘤病人的身心健康恢复,同时也减轻了护理人员的工作负担。文献[59]针对心理咨询和性格分析进行了语音情感研究,有助于专家及时给出性格分析结果和心理咨询建议。由此可见,无论是病患还是老人,亦或是精神障碍患者等,语音情感识别的存在,在很大程度上改善了这些问题。
在服务领域[60],许多企业、平台、商家等,为节约成本,很早便采用了人工客服的方式。普通的人工客服只会机械性、重复性地回答客户的问题和需求,不能做到灵活变通,从而致使部分客户产生抵触的情绪,导致客源的损失。而语音情感识别将会对此采取针对性的分析,当监测出客户情绪有负面波动时,则及时切换人工客服进行协调,有效地减少了客源损失量。同样的,语音情感识别会在适当情况下提醒服务人员,帮助其调节情绪,诸如人工客服、出租车司机、导游等,在面对蛮横无礼的服务对象时,情绪易产生较大的波动,语音情感识别的提醒和帮助会让其在工作减少许多冲突,从而使服务人员尽快调整恢复情绪。例如通过问卷调查或者访谈的方式不仅耗费大量的人力物力而且不一定能恢复顾客的满意度,文献[61]设计了一种情感服务交互系统,通过与顾客的交谈及时判断出顾客的情感状态并及时作出适当的多元化的服务补救措施以提高客户对服务的满意度。除上述领域外,语音情感识别在智能娱乐[62]、电子商务[63]、汽车驾驶[64]、辅助测谎[65]和人机交互[66]等应用程序非常重要。
6 语音情感识别的挑战
语音情感识别技术在社会发展的浪潮中不断前行,人工智能的发展带动着语音情感识别逐步达到更高的水平,然而同其他高端科技一样,在到达一定阶段后,语音情感识别终究是迎来了技术的“瓶颈期”。从语音情感识别的预处理阶段到特征提取阶段,再到情感识别阶段,每个阶段都面临着一些全新的挑战。
在预处理阶段,语音情感识别系统的数据采集系统还不够完善,带有噪声的语音信号会极大地改变声学特征的分布规律且无法长期精准地对情绪状态进行追踪,不同性别、不同年龄的说话者以及不同的采集方式带来的声学变异均会对特征选择的结果造成一定的影响。人类的情感是通过多种形式同时进行的,单模态的数据采集会影响最终的情感识别率,而多模态的数据采集又会造成维度的“爆炸式”增长,对下一步的特征提取带来麻烦。
在特征提取阶段,语音信号中含有丰富的情感信息,目前还不清楚什么种类的特征对情感的差异性最具有区分性且特征提取手段极其局限;其次,无法找到与识别目标有明确相关的、深层次的情感特征;此外,由于不同国家的文化和语言特色的差异等,情感的表达特征也不尽相同,对于样本较少的数据集,其提取到的特征数量有限,最终导致无法达到满意的识别效果。
在情感识别阶段,同样无法明确地找到有效的情感识别方法。除了缺乏统一规范的汉语情感语料库,如何有效地对语言障碍、方言障碍以及远程通话中的语音情感进行识别也是情感识别领域面临的一大挑战,当被观察者意识到自己正在接受语音情感识别的实验时,往往会因为各种因素或隐私问题,刻意调整或试图抑制自己的真实情绪,从而在一定程度上影响识别的真实有效性。除此之外,随着深度学习的广泛应用,如何利用该方法对语音情感进行更加精准、系统的识别,将成为研究人员又一大关注要点和需要攻克的难题。除上面所述,缺乏一个统一、权威的语音情感数据库的建设标准也是人机交互领域面临的一大难题。
7 研究展望
语音情感识别经过几十年的发展已经取得了长足的发展,但距离真正的自然人机交互还有很长的路要走。首先是高质量情感语料库的缺乏。截止目前虽有不少语料库被建立,但它们往往局限于某种单一语言且数量较少,并且由于情感本身的复杂性,这些语料往往质量不高。但众所周知,一个质量和数量兼备的语料库是语言情感识别技术研究必不可少的基础。由此可见,无论语言情感识别技术向何处发展,建立一个经过系统整合、内容丰富且高质量的语料库是必然要求。其次是情感识别建模的问题。由于语言符号和语言思维之间具有一种天然的不对称性,建立一个高效合理的语言情感识别模型是研究的重点。这个模型以语料库为基础进行大数据式的训练,建立一种联通声学特征和情感状态的映射通路,进而实现对语料情感状态的判断和识别。但是由于情感的复杂性,人类对大脑的情感处理机制认识有限,尚未有一种高效可靠的情感识别模型被建立[67-69]。因而,脑学科和计算机的交融研究也就成为一种必然趋势,没有对人脑的高度认识就不可能有高效的情感识别建模。总之,建立系统高质量的语料库和可靠的情感识别模式是未来语音情感识别发展的必然方向。
