面向非平衡数据分类的概率过抽样过滤方法
2020-06-05孟庆鹏田开严
孟庆鹏,田开严,张 恒
(1.海军装备部驻南京地区第二军事代表室,南京 211153;2.中国船舶集团有限公司第八研究院,南京 211153)
0 引 言
非平衡数据分类问题是机器学习和数据挖掘领域的一个重要研究方向,近年来越来越受到研究者的关注,如自然灾害、癌症基因表达、虚假信用卡交易、电信诈骗、雷达干扰识别、雷达孤立杂波点剔除等。非平衡数据集中某些类样本数量显著多于另外一些类样本数量,在二分类问题中常把数据量较多的类称作多数类数据(负类),数据量较少的类称作少数类数据(正类)。这类问题有一个共同的特点,即少数类样本信息才是关注的重点。关于类不平衡问题的解决方法可以分为3类,它们分别是数据预处理方法、代价敏感方法和算法级方法。
本文提出面向非平衡数据分类的概率过抽样过滤方法。通过概率过抽样方法处理非平衡数据集,考虑数据真实概率分布,使得重抽样的数据更具代表性,符合数据规律。再通过基于非合作博弈理论的过滤方法将获得的少数类合成数据进行预识别,使其获得最可能的类标签,进而去除非本类数据,消除数据重叠,获得更高质量的少数类合成数据。最后,建立模型的分类性能得到有效提高。
1 快速收敛吉布斯抽样
快速收敛吉布斯[1](RApidy COnverging Gibbs ,RACOG)抽样通过Chow-Liu[2]算法近似少数类数据的概率分布,使用吉布斯(Gibbs)抽样生成新的少数类数据。RACOG通过赋值随机变量的初始值来加强标准的吉布斯抽样。一般情况下,吉布斯抽样的随机变量初始值是从属性的状态空间随机选择。RACOG将少数类数据点作为初始样本的集合,然后为每个少数类数据执行吉布斯抽样。它产生多个马尔科夫链(Markov Chains)。每个链由不同的少数类样本开始,不像传统的吉布斯抽样产生一个很长的马尔科夫链。它的初始值从少数类样本直接选择,在产生新数据时实现更快的收敛。
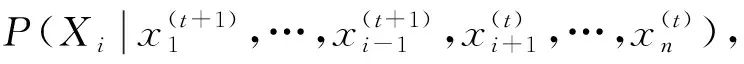
(1)
吉布斯抽样取决于两个重要因素,一个是为了实现稳定的分布来生成样本的迭代数量,另一个是从马尔科夫链丢弃的连续样本的数量。
2 面向非平衡数据分类的概率过抽样过滤方法
博弈理论是关于策略决策或相互作用的决策研究。博弈分为多种类型,如合作的和非合作的、对称的和非对称等类型。非合作类型的博弈用于处理单个理性决策者之间的相互作用。博弈包括玩家(Players)的集合,对于每个玩家可用策略集合以及每个组合策略的收益(Payoffs)。
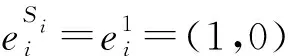
(2)
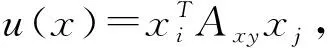
(3)
其中,α是控制增长率的常量,将具有最高概率的策略作为其类标签。
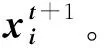

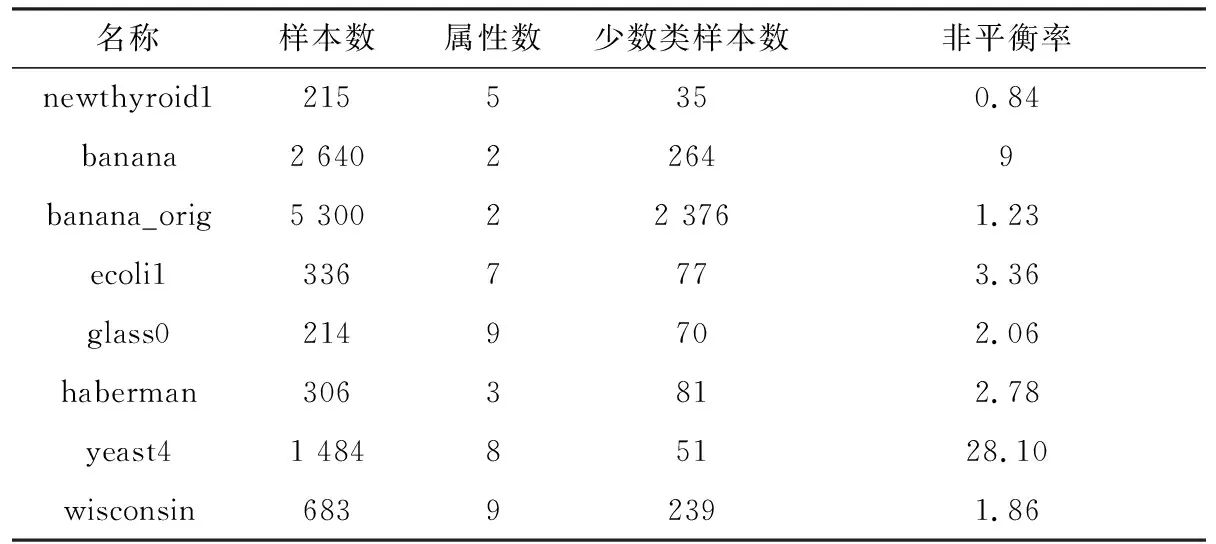
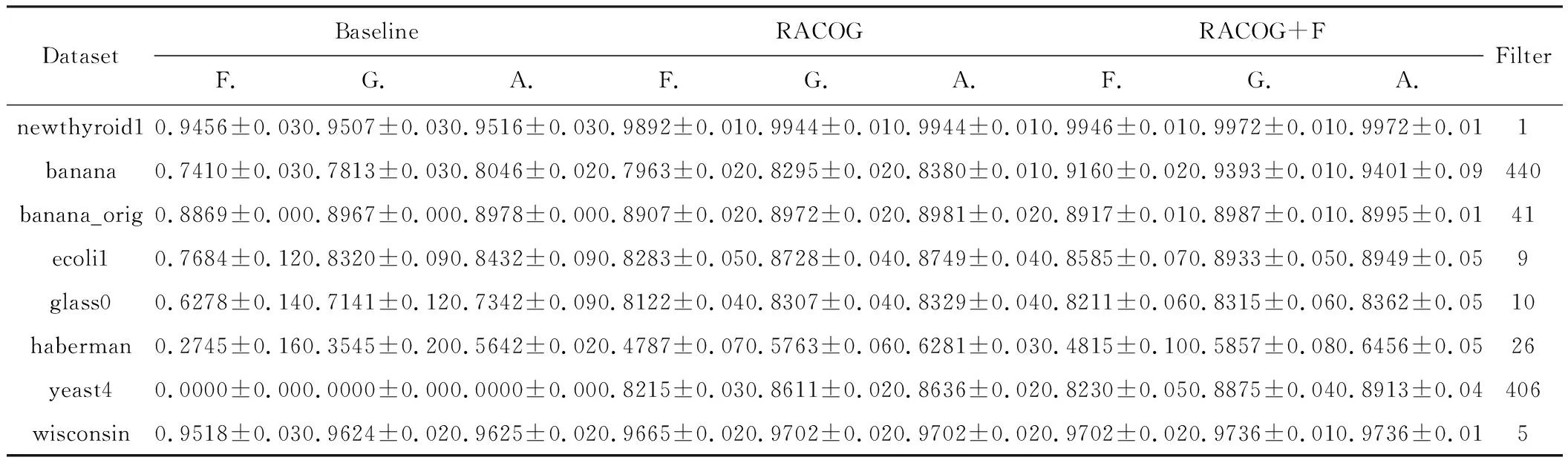
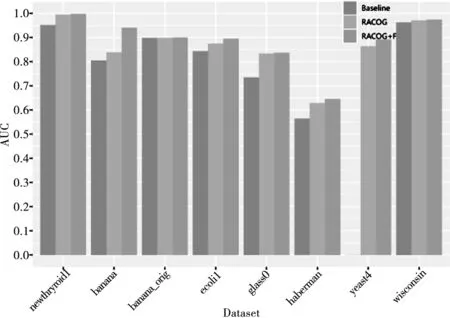
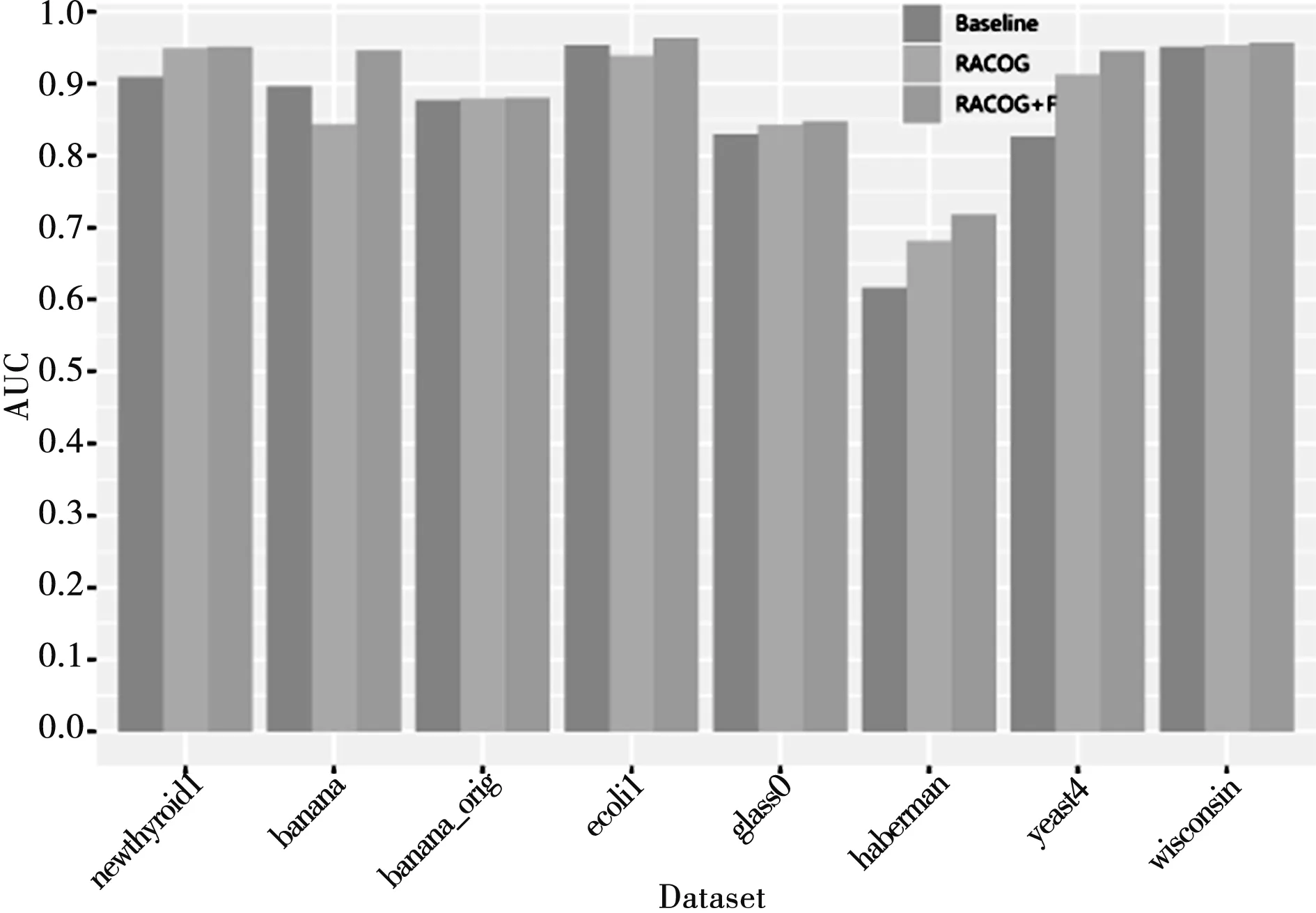
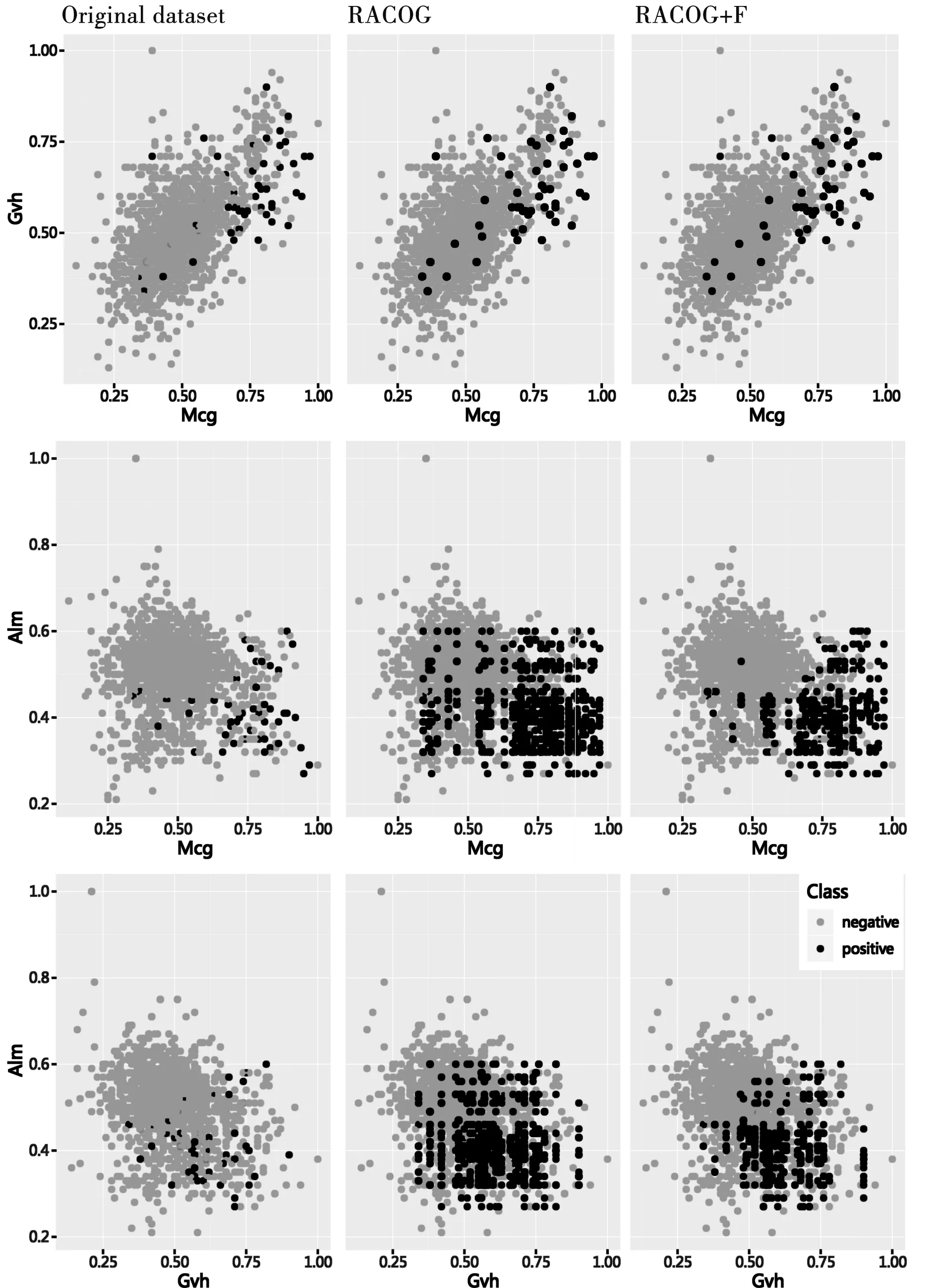
算法1 RACOG+F算法Input: 非平衡数据集D,迭代的数量hOutput: 非平衡数据集分类指标1 初始化相关参数;2 通过Chow-Liu算法构建相依树来近似少数类样本DI的离散概率分布;3 while{t 将近似概率分布中抽样合成的新少数类数据合并到DN中。为了实现对合成数据DN的进一步过滤故将其作为未带标签数据。将未带标签数据DN和原始数据D作为两种不同类型的玩家,数据的类标签作为每个玩家的可用策略Si={I,A}。对于DN中的i玩家来说,通过欧氏距离从数据集{D∪DN}中计算它的k个最近邻居Dk。为了既不丢失算法精度又使算法快速执行,本文将最近邻数量k设定为5,即每个玩家的5个邻居玩家。将i和它的5个邻居玩家相互作用通过公式(2)计算收益ui(x),收益为i与每个邻居玩家作用收益的总和是玩家i的总体收益。 (4) 将具有最高概率的策略作为i玩家选择的策略,即最可能的类标签。将此过程迭代进行,找到DN中所有样本的最可能类标签,将非本类样本去除,以此来过滤合成数据DN,得到高质量的合成数据。将过滤后的DN合并到原始数据集D={DI∪DA∪DN},分别通过CART和SVM为D建立模型获得分类性能。基于非合作博弈理论的过滤方法可以对合成少数类数据进行预识别,进化学习获得合成少数类数据最可能的类标签,找到合成数据中的非本类数据,将其去除获得“纯净”的合成少数类数据DN,减少数据重叠。 为了评估提出的RACOG+F与原始过抽样方法的分类性能,实验采取了CART和SVM作为基分类器。全部的实验采取5折交叉验证作为验证和测试方法,每个数据集的分类结果用这5次的均值和标准差表示。 实验所用数据来自KEEL数据库。表1展示了实验所用数据集的特征,包括数据集名称、样本数、属性数、少数类样本数和非平衡率。 表1 数据集 为了在评价性能时更多地关注少数类数据,本文使用F-measure(精度和召回率的调和均值)、G-mean(灵敏度和特效性积的平方根)、AUC(真正率相对于假正率的差异)3个评价指标来验证和比较各个算法。通过表2展示的混淆矩阵可以得到正确或错误分类某类数据的情况。 表2 二分类问题混淆矩阵 表3和表4展示了以CART和SVM作为基分类器各个算法在不同数据集上的不同性能值,性能评价指标为F-measure、G-mean、AUC(分别简写为F.、G.、A.)。提出的方法RACOG+F的最好结果用粗体表示,每张表最后一列Filter展示了通过过滤方法过滤掉新生成的少数类数据的数量。 表3是以CART作基分类器,RACOG+F相比于RACOG在F-measure、G-mean、AUC平均性能上分别提高了2.6%、2.8%、3%。RACOG+F方法除了在数据集haberman上都获得了最高的性能值,优于原始的RACOG和Baseline。而对于数据集haberman来说,RACOG+F方法的F-measure、G-mean弱于原始的RACOG方法,但AUC结果高于RACOG。在此数据集上RACOG+F虽然过滤掉了噪声数据,但也丢失了更好地建立决策树的样本导致分类结果F-measure、G-mean不好。 表4是以SVM作基分类器,RACOG+F相比于RACOG在F-measure、G-mean、AUC平均性能上分别提高了2.6%、2.6%、2.6%。相比于原始的RACOG和Baseline, RACOG+F方法在所有的8个数据集上都获得了最高的性能值。而对于数据集haberman来说,RACOG+F方法以SVM作为基分类器,各项指标也都高于RACOG。相比于以CART做基分类器,经过过滤处理的数据集haberman使得SVM更能获得较好的分类超平面来分类此数据集。 表3 CART做基分类器的不同性能值 图1和图2展示了以RACOG进行过抽样不同方法在不同数据集上的AUC分类性能图。从图中可以看出,本文提出的方法RACOG+F相比于其他方法取得了较好的分类结果,是一种处理非平衡分类问题的有效方法。 图3展示yeast4数据集的原始散点图:RACOG过抽样方法处理数据的散点图以及过滤方法RACOG+F处理数据的散点图。通过散点图可以明显看出,原始数据集通过概率过抽样方法近似其概率分布,抽样增加了少数类数据数量,使得数据倾斜情况得到较大改善,同时也使得数据产生了一些“噪声”,如少数类数据重叠在多数类数据上,使得分类边界变得模糊。再将新的合成数据进行过滤后,可以明显发现数据分类的边界更加清晰,类之间重叠减少。实验也证实,用CART和SVM建立模型,过滤方法RACOG+F相比于基分类器分类和RACOG过抽样方法明显提高了F-measure、G-mean、AUC性能值。图3从数据形态层面可以得出,使用过滤的概率过抽样方法可以较为明显地获得高质量的分类边界,提高分类性能,这在数据指标评价层面也得到了很好的验证。 图1 CART作基分类器的AUC值 图2 SVM作基分类器的AUC值 图3 各方法处理yeast4数据集的散点图 将概率过抽样方法合成的新少数类数据进一步过滤,去除其中“噪声”数据(非本类数据),得到高质量的分类边界,提高了非平衡数据的分类性能。概率过抽样方法RACOG虽然近似了少数类数据原始概率分布,使得新生成的数据更能反映其真实数据规律,优于通过简单复制或样本特征空间相似性来增加少数类数据数量的方法。但是,新合成的少数类数据依然存在数据重叠现象,将其通过基于非合作博弈理论的方法进行预识别,去除非本类数据,与原始概率过抽样方法相比得到了更高质量的合成数据,有效提高了非平衡数据集分类性能。此方法不仅使数据集数据形态上获得了高质量的分类边界,在数据结果上也得到了很好的验证。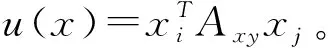
3 实验设计与结果分析
3.1 数据集
3.2 评价标准

3.3 实验结果及分析
4 结束语
