基于FastText的新闻文本多分类研究
2020-05-28张超超卢新明
张超超 卢新明

摘 要:在迅速增加的海量数据中,文本形式的数据占很大比重。文本分类作为最常见的文本挖掘技术,可在大量杂乱的文本数据中发现有价值的信息,具有重要意义。文本分类面临的首要问题是如何在确保分类准确率的同时缩短分类时间。提出使用分类模型FastText学习单词特征以解决该问题,同时在数据集上使用停用词处理方法降低噪声数据对分类模型的影响。实验结果表明,使用FastText文本分类模型在数据集上准确率达到96.11%,比传统模型提高近4%,且模型处理每条文本的平均时间为1.5ms,缩短了约1/3。
关键词:文本分类;词向量;FastText;停用词;噪声数据
DOI:10. 11907/rjdk. 192499
中图分类号:TP301 文献标识码:A 文章编号:1672-7800(2020)003-0044-04
Research on News Text Classification Based on FastText
ZHANG Chao-chao, LU Xin-ming
(College of Computer Science and Engineering, Shandong University of Science and Technology,Qingdao 266590,China)
Abstract: With the rapid increase of the amount of data, textual data accounts for a large proportion. Text classification, as the most common text mining technology, is of great significance for finding valuable information in a large amount of messy text data. In the field of text classification, the primary goal is to reduce the classification time while ensuring the classification accuracy. Therefore, this paper uses the classification model FastText to learn the word features to solve the current problem. In addition, a stop word processing method is used to reduce the influence of noise data on the classification model. The experimental results show that the accuracy rate of FastText text classification model is 96.11%, which is nearly 4% higher than the traditional model. Furthermore the time spent by the model in processing each text was 1.5m/s on average, which was reduced by about 1/3.
Key Words: text classification; term vectors; FastText; stop words; noise data
0 引言
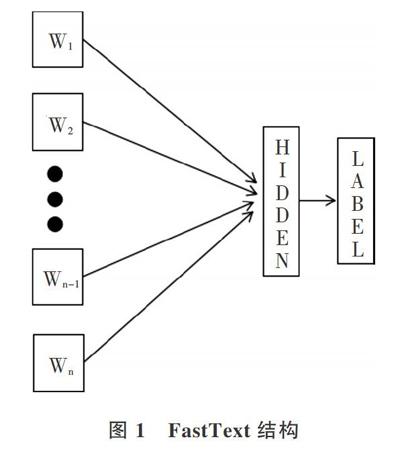
文本分類最初使用基于特定规则[1]的方法。先收集关于待分类文本领域内专家知识和经验,将其组织成一系列分类规则[2],然后根据这些分类规则进行文本分类。文献[3]使用基于降噪自动编码器的中文文本分类方法;文献[4]提出一种基于维基百科的文本分类规则。虽然这些分类方法处理特定领域的文本有很好的效果,但概括分类领域所有知识并制定相关分类规则需消耗大量人力成本,所以该类方法适用性较差。此外,当文本无法依照现有规则进行分类时,需重新获取文本并归纳规则再进行分类,因此该类方法泛化性也较差。相比而言,本文FastText模型无需较多人工训练模型,仅对训练数据集作简单的预处理后即可放入模型进行训练,且在新分类任务出现时,模型只需更新迭代训练之后即可完成新任务,大幅降低了人力、物力成本。
随着人工智能的飞速发展,机器学习算法在文本分类中的应用成为自然语言处理研究热点。文献[5]提出将Word2vec应用于文本分类研究;文献[6]采用LDA与SVM算法结合的文本分类。这些方法将文本数据改为以向量的形式输入,所有数据被分为一定比例的训练集和测试集,利用分类模型进行训练和测试,并将模型分类结果与原有类别对比作为分类算法效果的证明。目前已有多种机器学习算法应用于文本分类。赵刚等[7]在基于机器学习的商品评论情感分析模型研究中,通过集群技术删除数据集中的正面例子以得到更多负面例子,使用改进的词频率逆文档频率(tf-idf)进行特征提取,与支持向量机相结合改进Rocchio分类器构建,以提高分类准确性。但是这类方法大都忽略了词与词之间的句法形态,导致最终分类效果只能在90%左右。本文FastText模型通过学习单词特征,关联上下文单词词义并将其作为分类结果,使词频不同但相互之间有所联系的单词在分类任务中发挥一定作用。
其中σ(?)表示 Sigmoid 函数[4],LC(n)表示 n 节点的左孩子,[x]是一个特殊函数,其定义如式(5)所示。
[θn(yj,l)]为节点[n(yj,l)]的参数。X是输入。从根节点到[y2]的路径长度为[L(y2)=4]。这样在经过分层Softmax处理之后,模型计算复杂度从[O(k)]降低至[O(log(k))],资源耗费大幅降低。
3 实验与分析
3.1 实验数据
本文数据集包括来自搜狗新闻的50 000条训练集与10 000条测试集,分别有体育、财经、房产、家居、教育、科技、时尚、时政、游戏和娱乐10个类别。
因为新闻数据集为中文文本,分词工具为Python中jieba分词工具,jieba分詞有3种模式,本文根据实际文本序列长度,采用其中的精确模式,jieba分词前后文本样例如图3所示。
为降低文本分类器计算复杂度、提高分类器分类效率,需在将文本语料转化为特征向量前对文本作降维处理,方法为去掉文本中对分类没有意义的停用词和低频词,同时去掉文本中的表情、网址、特殊符号,以减小特征词典大小,减少噪音数据对分类模型的影响。
3.2 实验结果
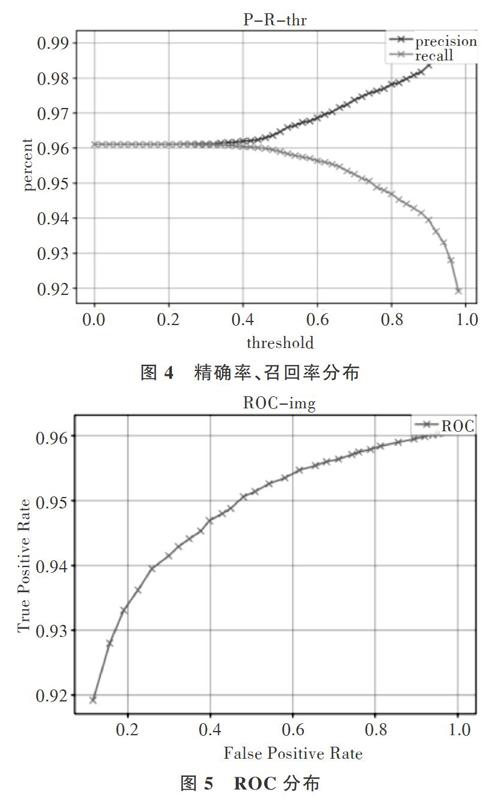
由图4、图5可知,分类器在测试集上的测试结果比较理想,精确率为96.11%,阈值为60%时,精确率为 0.985 2%,召回率为0.966 1%,F1分数为0.975 6%。本文数据集文本质量相对较好,所以训练后的分类器在测试集上的表现比较好,测试集每条文本对应的测试label打分均相对较高。
4 结语
本文首先简要介绍了常用文本分类方法,然后阐述了文本分类理论与技术。根据新闻文本特点,在新闻文本预处理过程中,将地点名词加入到常用停用词表中,去除了更多对文本表达无意义的词,分类效果得以改进。通过实验数据综合对比,可以观察到本文提出的FastText算法模型与传统机器学习算法相比,在训练速度、预测速度和准确率上均有明显提升,证明本文模型具有较高的使用价值。
参考文献:
[1]段旭磊,张仰森,孙祎卓. 微博文本的句向量表示及相似度计算方法研究[J]. 计算机工程,2017, 43(5): 143-148.
[2]范云杰,刘怀亮. 基于维基百科的中文短文本分类研究[J]. 现代图书情报技术,2012(3):47-52.
[3]刘红光,马双刚,刘桂锋. 基于降噪自动编码器的中文新闻文本分类方法研究[J]. 现代图书情报技术, 2016(6): 12-19.
[4]赵辉,刘怀亮. 一种基于维基百科的中文短文本分类算法[J]. 图书情报工作,2013,57(11): 120-124.
[5]张谦,高章敏,刘嘉勇. 基于Word2vec的微博短文本分类研究[J]. 信息网络安全, 2017(1): 57-62.
[6]宋钰婷,徐德华. 基于LDA和SVM 的中文文本分类研究[J]. 现代计算机(专业版),2016(5): 18-23.
[7]赵刚,徐赞. 基于机器学习的商品评论情感分析模型研究[J]. 信息安全研究, 2017, 3(2): 166-170.
[8]金志刚,韩玥,朱琦. 一种结合深度学习和集成学习的情感分析模型[J]. 哈尔滨工业大学学报,2018, 50(11): 32-39.
[9]梁喜涛,顾磊. 中文分词与词性标注研究[J]. 计算机技术与发展,2015,25(2):175-180.
[10]徐戈,王厚峰. 自然语言处理中主题模型的发展[J]. 计算机学报,2011,34(8):1423-1436.
[11]刘德喜,聂建云,张晶,等. 中文微博情感词提取:N-Gram为特征的分类方法[J]. 中文信息学报, 2016, 30(4): 193-205, 212.
[12]万红新,彭云,郑睿颖. 时序化LDA的舆情文本动态主题提取[J]. 计算机与现代化, 2016(7): 91-94.
[13]李鹏,于岩,李英乐,等. 基于权重微博链的改进LDA微博主题模型[J]. 计算机应用研究,2016, 33(7):2018-2021.
[14]KORDE V,MAHENDER C N. Text classification and classifiers: a survey[J]. International Journal of Artificial Intelligence & Applications (IJAIA), 2012,3(2):86-99.
[15]CARPENTER B. Integrating out multinomial parameters in latent Dirichlet allocation and naive Bayes for collapsed Gibbs sampling[R]. ALIAS:2010.
[16]GOUDJIL M, KOUDIL M, BEDDA M, et al. A novel active learning method using SVM for text classification[J]. International Journal of Automation & Computing, 2015(1): 1-9.
[17]TONG S,KOLLER D. Support vector machine active learning with applications to text classification[J]. Journal of Machine Learning Research,2001,2(11):45-66.
[18]BAHASSINE S, MADANI A, KISSI M. An improved Chi-sqaure feature selection for Arabic text classification using decision tree[C]. International Conference on Intelligent Systems: Theories and Applications,2016: 2378-2536.
[19]SCHAPIRE R E,SINGER Y. Machine learning[M]. Cambridge:MIT Press,2000.
[20]MARUF S, JAVED K, BABRI H A. Improving text classification performance with random forests-based feature selection[J]. Arabian Journal for Science & Engineering, 2016, 41(3): 951-964.
(责任编辑:江 艳)
收稿日期:2019-11-14
基金项目:国家重点研发计划项目(2017YFC0804406);山东省重点研发计划项目(2016ZDJS02A05)
作者简介:张超超(1994-),男,山东科技大学计算机科学与工程学院硕士研究生,研究方向为自然语言处理;卢新明(1961-),男,博士,山东科技大学计算机科学与工程学院教授、博士生导师,研究方向为数字矿山软件、CAD、计算机图形学。
