基于IAGA+M-SVR的岩土参数反分析方法及其工程应用
2020-05-28孙振华杨天鸿辛全明
孙振华 杨天鸿 安 琦 辛全明
(1.东北大学资源与土木工程学院,辽宁沈阳110000;2.中国建筑东北设计研究院有限公司,辽宁沈阳110000)
随着经济的发展,城市中的基坑工程规模和深度越来越大,而且基坑工程大多紧邻对变形敏感的老建筑和市政管线等,基坑的施工必然对这些建(构)筑物产生不良影响,尤其是软土地区,在这种情况下,基坑支护结构除满足自身强度外,还必须满足变形的要求,以保护周边环境。由于问题的复杂性,传统的分析方法很难有效对其予以解决,计算机技术的迅猛发展为利用数值方法解决该问题奠定了基础[1-3]。做好数值分析有3个主要条件[4]:选取符合实际的岩土材料特性参数,假定合理的边界、接触面条件以及选择合适的单元本构关系。通常,岩土体材料特性参数的选择是数值分析中最难的一部分[5-8],一般的土体材料特性参数的选取主要根据岩土工程勘察报告中的数据,但是我国国内标准、行业标准对土的抗剪强度确定存在不同的方法,对影响基坑变形数值分析结果的重要参数弹性模量和泊松比[9],只能根据压缩模量(变形模量)凭经验或者参考资料进行确定,造成数值分析结果与现场实际结果有较大误差,限制了有限元在基坑工程计算分析中的应用,而通过位移反分析求取这些岩土参数成为一种有效的方法,因为它不仅能够反映岩土体本身的性质,而且还反映了本构模型中未体现因素的影响。
位移反分析法求解种类丰富,包括逆反分析方法、图谱法、直接反分析方法等。其中直接反分析法是目前应用最为广泛的反分析方法,这种方法把参数反演问题转化为一个目标函数优化求解问题,但是此方法需要进行几十次甚至上百次的数值计算,特别是做三维数值模拟,需要耗费大量的时间,限制了直接反分析法的应用。近些年,直接反分析法中引入人工神经网络方法、支持向量机(M-SVR)等仿生智能分析方法代替数值计算,引入遗传算法、粒子群搜索算法等新兴优化算法来搜索最优参数取得了很好的效果,不仅可以学习和表示位移与岩土参数之间高度非线性关系,而且能够求得全局最优解[10]。但是这些智能反分析算法在计算效率和精度上也都或多或少地存在一定的问题[11]。
在前人的研究基础之上,为克服传统遗传算法在复杂函数优化的寻优搜索中容易陷入局部极值、搜索效率低、不稳定以及利用单输出支持向量机建立多测点模型时计算量大、精度不高等缺点,本研究提出一种改进自适应遗传算法(IAGA)+多输出支持向量机(M-SVR)位移直接反分析法,通过有限元正交试验的方法获得学习样本,以多输出支持向量机(M-SVR)建立反演参数与多个位移点之间的映射关系,以改进自适应遗传算法(IAGA)搜索多输出支持向量机模型的超参数及与实际位移最吻合的岩土参数,该方法充分发挥了遗传算法全局寻优以及支持向量机的小样本数据建模方面的优势。并将该方法用于营口兴隆大厦桩撑支护基坑的岩土参数位移反分析中,该方法然后将所得岩土参数与实验结果及以往经验值进行对比,给出基于现有试验结果的该种支护类型基坑初始数值计算的岩土参数建议值。
1 理论基础
1.1 正交试验
正交试验设计是利用正交表来安排与分析多因素试验的一种设计方法。它是由试验因素的全部水平组合中,挑选部分有代表性的水平组合进行试验的,通过对这部分试验结果的分析了解全面试验的情况,找出最优的水平组合。
正交试验法的理论基础是正交拉丁方理论与群论,科研中普遍采用该方法,因其具有如下优点:①按表格安排试验,使用方便;②布点均衡、试验次数较少;③在正交试验法中的最好点,虽然不一定是全面试验的最好点,但往往也是相当好的点;④正交试验法提供一种分析结果(包括交互作用)的方法,结果直观易分析;⑤因其具有正交性,易于分析出各因素的主效应。
1.2 多输出支持向量机(M-SVR)
支持向量机(简称SVM)是基于统计学习理论的一种新的通用机器学习方法,其从统计学习理论出发,寻求决策模型的最优泛化性能的同时最小化训练误差,特别适用于小样本学习问题。此外,核函数通过将输入空间变换到另一个高维空间,帮助支持向量机有效地处理非线性问题。但是常规的支持向量机只是一维输出模型,在面对多维输入多维输出回归问题时,目前常常是通过对各测点所代表的输出变量建立独立的一维输出SVM模型来解决,这样不仅大大的增加了计算量,而且由于没有考虑输出数据间的相关性而影响了精度[12]
M-SVR[13]旨在学习多元输入空间到多元输出空间的映射。它同时处理多个输出,从而提高了决策的泛化性能,特别是在只有少量样本点可用的情况下的泛化性能,这些特点非常适用于岩土这种材料力学性质比较复杂的材料工程反演问题。
给定训练样本集合({x1,y1),…,(xn,yn)}⊂Rd×RQ,则多变量支持向量机回归问题转化为下述优化问题:

通过一阶泰勒展开式,得到式(1)的二次型近似:

式中,Ω为与W和b无关的高阶项;
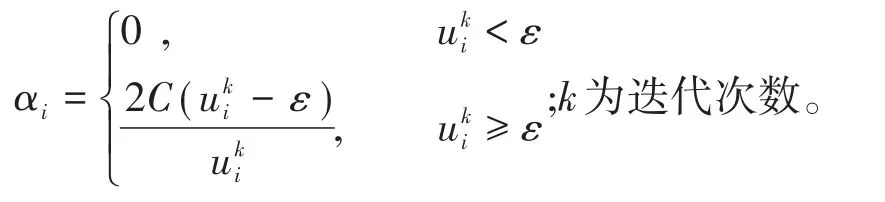
式(2)采用迭代变权最小二乘法(IRWLS)求解,该算法通过在前一次迭代结果的基础上线性搜索变量的下降方向,从而逐次收敛至最优值。由于特征空间因此对式(1)的求解转换为对模型参数β和b的求解,算法见文献[14]
1.3 改进自适应遗传算法(IAGA)
遗传算法[15]是一种全局最优化方法,它模拟了自然界生物进化过程中的“优胜劣汰,适者生存”的法则,将复制、杂交及变异等引入到算法中,通过构造一定规模的初始可行解群体并对其进行遗传操作,直至搜索到最优解。但传统的遗传算法由于采用固定的控制参数,导致全局搜索能力差,存在未成熟收敛等现象,本文基于文献[16]中根据种群适应度的集中分散的程度非线性的自适应调节遗传进化的运算流程和交叉概率、变异概率的值,从而更好地产生新的个体摆脱局部极值搜索到全局最优解,并采取最优保存策略来保证算法的收敛性的思想。其计算流程见图1,交叉概率Pc和变异概率Pm的值自适应选取计算见式(3)、式(4)。
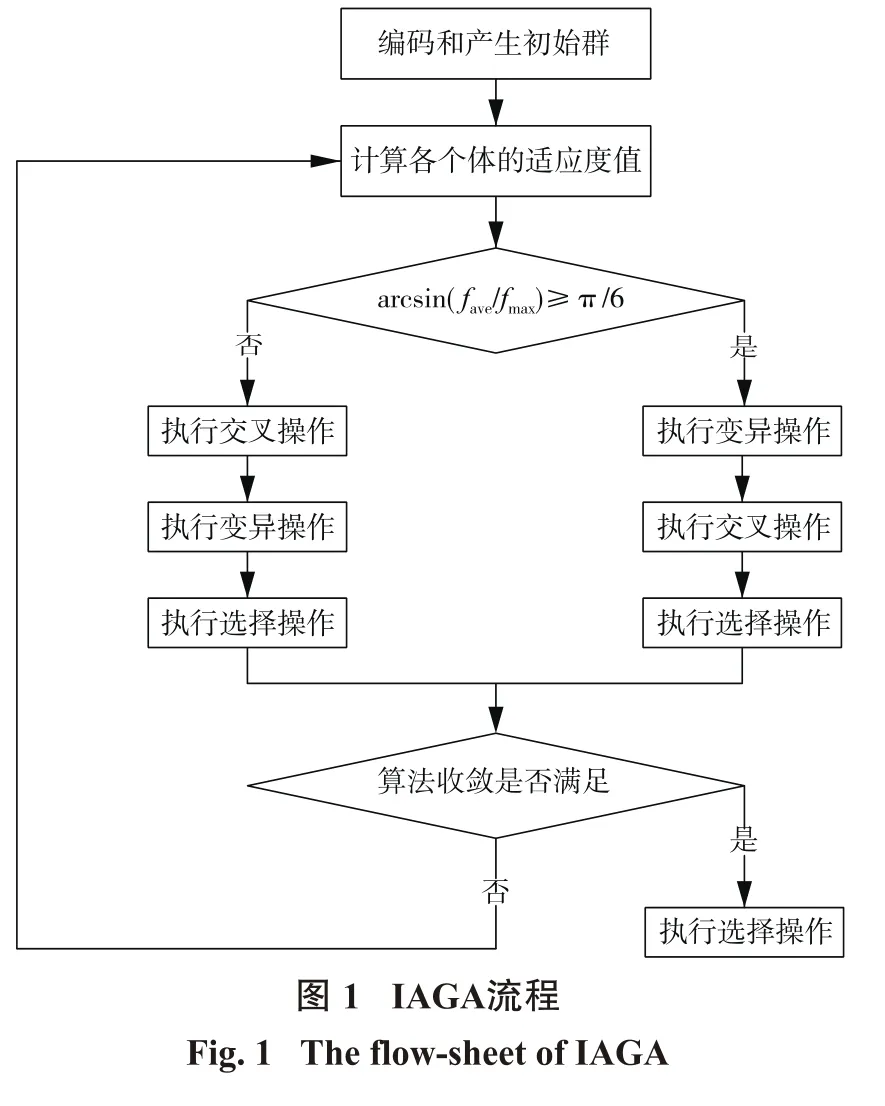

式中,fmax为种群的最大适应度;fave为种群的适应度平均值;k1可取1.0,k2可取0.5。
2 基于IAGA+M-SVR的基坑岩土参数反演
2.1 工程概况
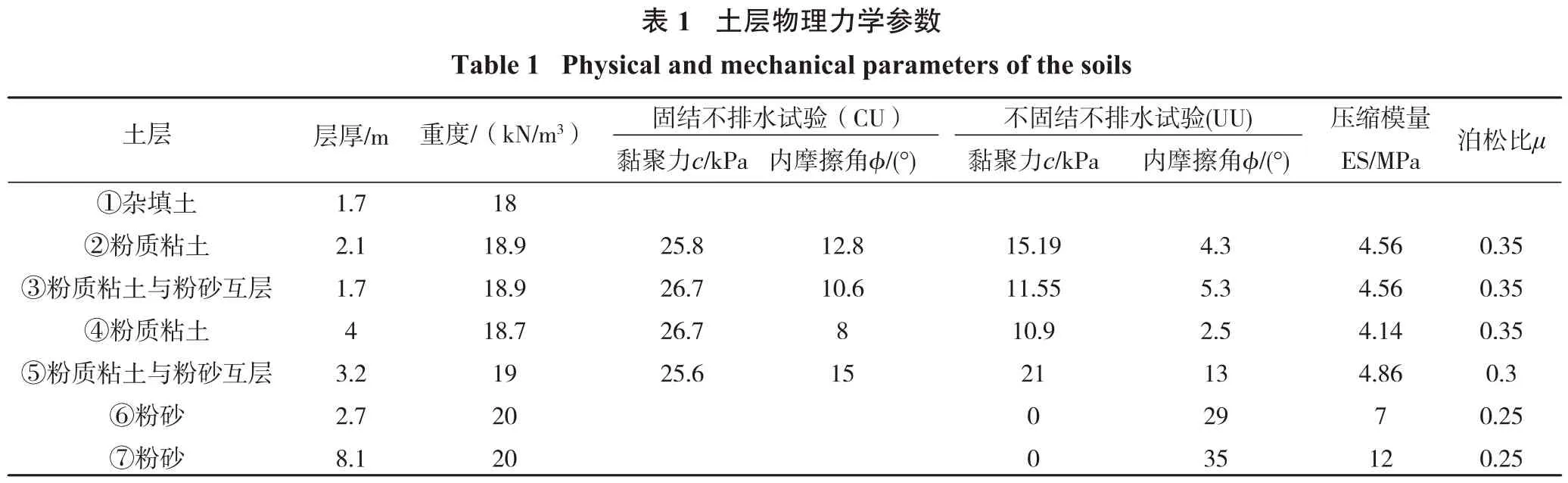
营口兴隆百货大厦位于营口繁华地带,周边建筑物复杂。基坑总长度约90 m,宽度约67 m,深度约8.6~10.95 m。根据本工程岩土工程勘察报告,支护结构影响范围内的地层分布和物理力学参数见表1。
地下水为第四系潜水,补给来源以大气降水为主,排泄以蒸发为主,水位随季节略有变化,勘察期间初见水位埋深1.80 m,稳定水位埋深1.20 m,历史最高水位埋深0.60 m。基坑采用钢筋混凝土灌注桩+桩间旋喷桩止水+一道钢筋混凝土支撑的方案,支护桩φ1 000@1 200,旋喷桩φ600@1 200,支撑主梁800 mm×800 mm,次梁600 mm×600 mm。
2.2 支持向量机(M-SVR)学习样本及测试样本构建
采用有限元正交试验的方法计算不同岩土参数组合下各测点(U1、U2、U3、U4)的最大水平位移值(u1、u2、u3、u4),结合表1所给各层土岩土力学参数及相关经验,将②③层土概化为一层,泊松比采用固定值,将②③④⑤层土的抗剪强度指标及②③④⑤⑥⑦层土的弹性模量作为反演参数,构造3水平12因素(L27(312))正交试验表,并采用GTS-NX软件进行模拟计算。模型x方向291 m,y方向254 m,z方向30 m,支护桩用等刚度板单元,支撑采用梁单元,共划分249 157单元,136 350节点。深基坑开挖模型四周边界采用法向约束,底面采用固端约束。模型采用Mohr-Coulomb(M-C)本构模型,计算模型和位移监测点位置见图2,计算参数水平与结果见表2,其中,序号1~27为正交试验学习样本数据,序号28、29为测试样本数据。
?

2.3 支持向量机(M-SVR)模型的训练及验证
待反演参数与位移之间的非线性关系可用MSVR(x1,x2,…,xn)来描述:

式中,X为待反演的岩土力学参数,如弹性模量E、黏聚力c和内摩擦角φ等;y为现场量测的关键点计算位移值。
本项目选用Python语言进行程序编写,对所论述的问题进行求解。程序的主要过程如下:
(1)数据分离。将表2中序号1~27号数据作为学习样本,28、29号作为测试样本。
(2)数据归一化。不同的影响因素有着不同的量纲和单位,为了解决数据之间的可比性,消除各因素之间的量纲影响,需要对数据进行归一化处理。本项目选用标准差归一化方式对数据进行归一化处理,经过处理后的数据符合标准正态分布,即均值为0,标准差为1。量化后的特征将分布在[-1,1]区间。
(3)建立M-SVR学习模型,遗传算法搜索超参数。为了防止对土体参数进行搜索时出现多解的情况,本项目在模型的4个方向选取4点U1、U2、U3、U4(见图2),利用不同的土体参数与该点对应的水平位移值,建立M-SVR模型。M-SVR核函数选用高斯核函数,模型的超参数包括C、ε、γ。使用改进自适应遗传算法(IAGA)对3项超参数进行搜索,种群数量为500。当最佳个体基因保持400代无变化时,将该组基因的解码作为最优解。
M-SVR采用交叉验证的方式进行学习(见图3),将27组数据分为A、B、C3份,以2组数据组合学习,另一组数据验证的方式进行排列组合,取验证数据的均方误差MSE作为评价指标,将各组均方误差的均值的负数作为单个位移点的评价指标,取4个位移点中评价指标最低的数值作为个体的适应度,以保证在进化过程中所有位移点适应度的优异性。
遗传算法适应度函数:
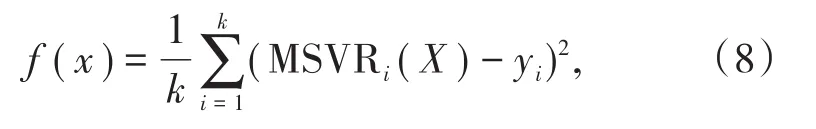
式中,MSVRi(X)是M-SVR计算得到的测点i处的位移值;yi为测点的计算位移值;k为监测点的个数。
经过遗传算法的搜索,将种群中适应度最大的个体进行解码,得出模型的超参数为C=40.412,γ=0.061,ε=1.344。将测试样本代入M-SVR学习模型,验证结果如表3,从表3中可知28号测试样本计算位移与M-SVR预测位移平均相对误差为5.73%,29号测试样本计算位移与M-SVR预测位移平均相对误差为5.24%,M-SVR学习模型精度满足要求。
2.4 改进自适应遗传算法(IAGA)反演土体参数
用学习好的M-SVR模型表示反演参数与位移之间的映射关系,在表2的岩土参数水平范围内,用改进自适应遗传算法(IAGA)搜索最优岩土参数,种群数量为1 000,适应度函数同样以平均的均方误差作为返回值,并对所搜的参数加以限制条件,对解码后参数不合要求的个体直接淘汰,当最佳个体基因保持800代无变化时,将该组基因的解码作为最优解,表4给出了各反演参数的最优解。

?

表5为将反演参数的最优解输入至GTS-NX软件及M-SVR模型中所得的4点U1、U2、U3、U4的计算位移值和预测值,其对比见图4。从表5中可知MSVR模型预测值与实际监测位移值的平均相对误差为2.25%,GTS-NX软件计算位移值与实际监测位移值的平均相对误差为2.83%,验证了反演参数的准确性。
3 反演岩土力学参数分析及应用

?
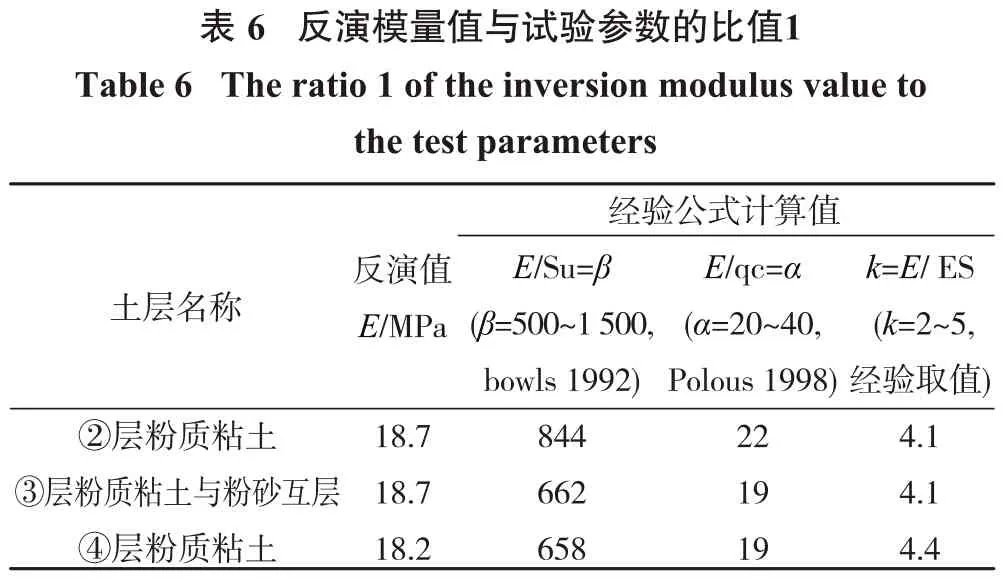
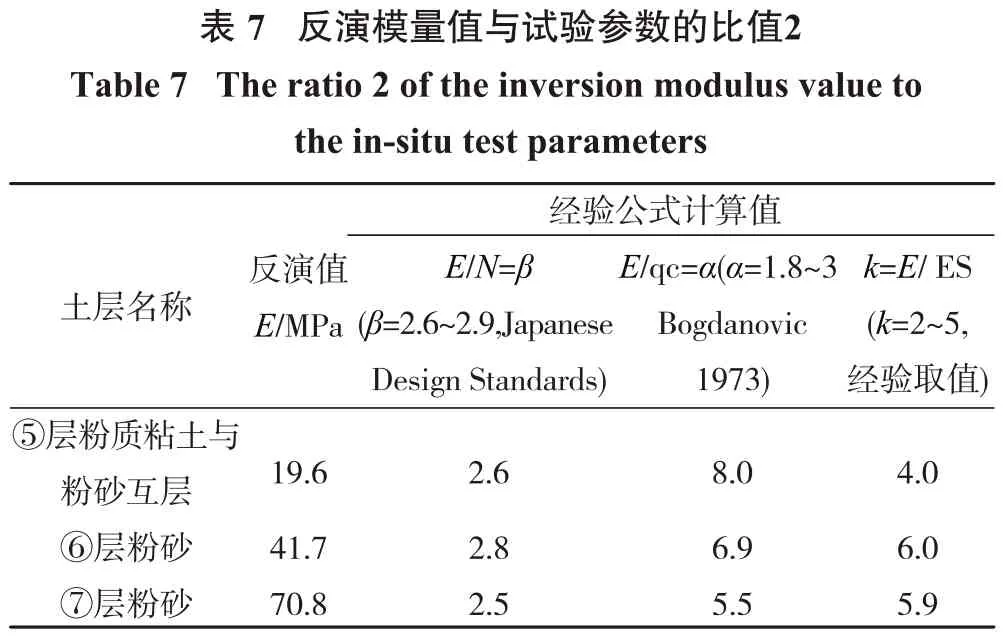
很多学者建立了土体弹性模量与室内试验和现场试验参数的经验关系式,表6给出了②③④软土层反演弹性模量与不排水剪切强度Su、静力触探锥尖阻力qc、压缩模量ES的比值,由表6可知比值都在经验区间范围内,反演结果比较合理。表7给出了⑤⑥⑦层土反演弹性模量与标贯击数N、静力触探锥尖阻力qc、压缩模量ES的比值,从中可知反演值与标贯击数的比值在经验值范围内,而与静力触探锥尖阻力qc比值要大于经验值范围,砂土的模量反演值与压缩模量ES的比值也超出经验比值范围。另外由表6、表7还可知弹性模量与静力触探锥尖阻力qc比值粉质粘土大于砂土,弹性模量与压缩模量ES的比值砂土要大于粉质粘土。

?

?

?
?
表8给出了②③④⑤层土的反演抗剪强度指标与CU和UU试验值的比较结果,其中CU试验值与反演值比较,各层土c值平均相对误差为10%,φ值平均相对误差为9.4%;UU试验值与反演值比较,各层土c值平均相对误差为37.4%,φ值平均相对误差为46.2%,反演抗剪强度指标与CU实验值较接近。

?
由于现有数值计算的参数取值只能基于勘察报告中提供的指标,为了便于实际工程应用,现将固结不排水(CU)指标,粉质粘土及粉质粘土与粉砂互层(②③④⑤)的弹性模量取4倍压缩模量,粉砂层(⑥⑦)的弹性模量取6倍压缩模量,泊松比μ按表1取值进行3D有限元计算。表9为其计算位移值与实际位移值相对误差分析表,从中可知,采用建议指标值进行三维数值模拟计算完全满足工程精度要求。

?
4 结 论
(1)综合IAGA和M-SVR而提出的基坑岩土参数反演方法充分利用遗传算法全局寻优以及支持向量机的小样本数据建模方面的优势,并且克服了传统遗传算法在复杂函数优化的寻优搜索中容易陷入局部极值、搜索效率低、不稳定以及利用单输出支持向量机建立多测点模型时计算量大、精度不高等缺点。该方法可以利用多测点的监测数据,反演的岩土参数更能综合反应岩土参数的复杂性和不确定性,更适用于岩土参数反演分析。通过营口兴隆大厦基坑的岩土参数反分析,并将结果与试验结果和经验计算值进行了对比,验证了该方法的有效性和正确性。
(2)为了便于实际工程应用,本研究给出了该地区与本工程类似的基坑支护系统的初始数值模拟计算的初始输入参数建议值:②③④⑤层土的弹性模量可取为4倍压缩模量,抗剪强度指标推荐采用固结不排水试验指标,⑥⑦层粉砂的弹性模量可取6倍压缩模量。
