基于数据驱动建模的气化炉配煤成本优化研究
2020-05-12袁晨博贾风军
杨 鹏,张 勇,袁晨博,贾风军
(内蒙古科技大学,内蒙古 包头014010)
引 言
中国是以煤炭为基本能源和主要工业原料的国家。20 世纪中期,煤炭在我国能源消费结构中所占比例在90%左右;20 世纪中后期,随着新石油基地的发现和开采,石油在能源消费结构中的比例有所上升,目前,煤炭在我国能源消费结构中所占比例仍在60%左右。化学工业作为我国煤炭的主要用户之一,每年的消费量占煤炭总消费量的11.5%左右[1]。因此,对煤炭资源的高效合理利用有着重要的意义。
多煤种动力配煤[2]可以改变煤的物理特性和燃烧特性,使之达到燃烧设备对煤质的要求,提高燃煤效率、降低生产成本和减少污染物排放。
目前不少企业都是按照经验或者平均法对不同煤种进行配煤,多数为两种煤掺配,这样虽然可以达到一定的配煤效果,但是配煤方法理论性指导不强,对配成煤质指标(灰分、挥发分、固定碳含量、全水分、硫含量、发热量等)没有数值上的直观体现,不能直接看出配煤能否满足气化炉对煤质的要求,也很难达到配煤的最优化。因此,内蒙古自治区流程工业综合自动化重点实验室复杂系统建模优化与控制研究课题组通过数学建模的方法来优化配煤过程,为企业降低配煤成本、优化配煤煤质提供了理论方法。
1 数学模型的建立
以鄂尔多斯地区某煤化工企业为研究对象,该企业气化炉可用煤共5 种,企业可以直接选取一种符合要求的煤作为原料煤进行气化生产,为降低生产成本,充分利用当地煤炭资源,可按照气化炉要求进行多煤种线性掺配[3],在解决单煤库存不足问题的同时,降低企业生产成本。目前该企业现场配煤大多数是根据经验或者平均法控制各煤种的比例,通过混煤提高气化炉效益来降低生产成本。该企业可用5 种煤的煤质分析及价格情况见表1,其中宏一煤为该企业的常用煤种。通过数学建模来优化配煤的模型整体流程示意图见图1。
利用线性配煤方法,以入炉煤质要求和成本最低为约束,对4 种煤与常用宏一煤进行线性配煤,得到4 种煤的配煤比例;通过4 种煤煤质参数的线性计算得到配好的煤的煤质数据;以气化炉实际生产过程中的配煤煤质和耗煤量数据为输入,产出的合成气数据为输出,利用神经网络建立数据驱动模型进行产气量预测;通过预测的产气量进一步分析配好后的煤的经济效益,并进行配煤比例的微调,达到成本最低的目的。
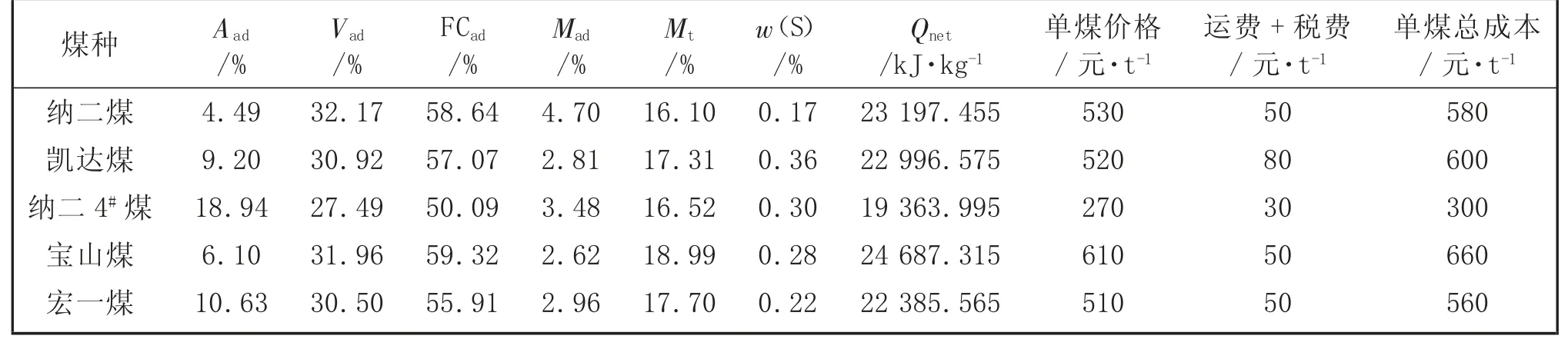
表1 5 种煤的煤质分析及价格
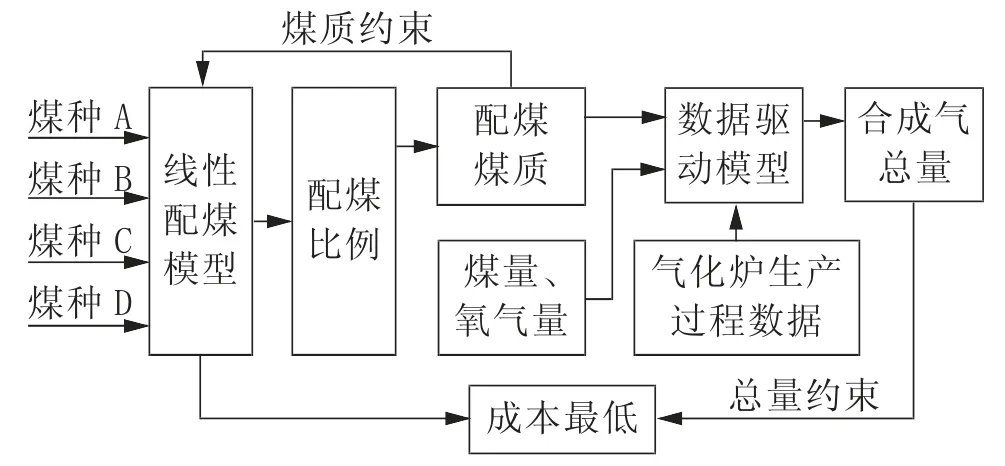
图1 配煤模型整体流程示意图
2 主要煤质参数及约束范围的选取
根据气化炉的燃烧性能,配煤的限制因素主要指标包括水分(Mad)、灰分(Aad)、挥发分(Vad)、固定碳(FCad)含量、硫(S)含量、灰熔融性温度(ST)、低位发热量(Qnet)等[2]。在配煤过程中,这些限制因素作为约束条件,被应用于各类配煤优化模型[4]之中。大量的约束条件增加了其模型计算的复杂性,甚至可能因为约束条件过于冗余而导致模型无法满足全部约束条件的情况。为此,通过挖掘频繁项集的关联规则算法Apriori 算法[5]简化模型。
Apriori 算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。项集是项的集合,项集的出现频率是所有包含项集的事务计数,又称作支持度或支持度计数。所有支持度大于最小支持度的项集称为频繁项集,简称频集。
对煤质参数进行关联规则挖掘主要包括两个过程,首先是找出所有频繁项集,然后由频繁项集Lk产生强关联规则。
Apriori 算法是一种寻找频繁项集的基本算法,通过逐层搜索的迭代方法,即将k项集用于探查(k+1)项集,来穷尽数据集中所有的频繁项集,也就是利用频繁项集的先验知识,首先找出频繁1 项集的集合,记为L1,然后利用L1项集找出频繁L2项集的集合,以此类推直到找不出频繁L(k+1)项集为止。
采用Apriori 算法对鄂尔多斯地区收集到的39种煤种进行分析,按煤质参数是否满足入炉煤煤质要求,将煤质归为满足要求和不满足要求两类,满足要求的设为1,不满足要求的设为0。设最小支持度为0.4,最小置信度为0.8。通过上述算法计算各频繁项集的支持度和置信度,39 种煤煤质参数关联规则计算结果见表2。

表2 39 种煤煤质参数关联规则计算结果
表2 中支持度表示几个关联的煤质参数数据在数据集中出现的次数占数据集的比重,置信度表示一个数据出现后,另一个数据出现的概率,关联规则表示参数的对应关系。例如:Vad→FCad,支持度81.818 2%表示39 种煤中挥发分和固定碳满足要求的煤的比例为81.818 2%;置信度100%表示39 种煤中,如果挥发分满足要求,则固定碳满足要求的概率为100%。由表2可知,灰分、全水分、固定碳和挥发分是强关联关系,一个参数满足条件,则其他参数也满足条件。选灰分作为目标函数的约束条件,灰分满足要求时,可推出其他参数也满足要求。从而确定目标函数的约束参数:灰分、低位发热量、硫含量、水分、各煤种供给量。
约束参数确定以后,需要确定其具体范围:(1)参数应该符合气化炉的设计要求;(2)根据某气化炉456组生产过程数据,以产出合成气与耗煤量的比例(气煤比)作为参照标准,气煤比越高,则产能越高,煤质越好,运用聚类的方法,对生产数据进行聚类分析,选出参数最好的约束范围。
根据生产参数过程数据在一定范围内波动的规律,选择运用划分方法中的K-Means(K-均值)算法[5],对煤质和操作变量进行聚类分析。并用欧几里得距离作为相似性度量标准,欧几里得距离表达式见式(1):

式中:i、j分别表示两个数据集,xin和xjn分别为数据集中的数据。
运用聚类算法,设定聚类类别数k为3(按照气煤比分为优秀、良好、一般),最大迭代次数500 次,得到的煤质聚类输出结果,见表3。

表3 煤质聚类输出结果
根据气化炉的特性,煤质参数应该在满足气化炉参数要求的同时,气煤比也在较高的合理范围内,通过对表3 和气化炉燃煤特性的分析,确定煤质参数的约束条件如下:

其中,配煤比例总和X=X1+X2+X3+X4=1,0<Xi<1(i=1,2,3,4),Xi为第i种煤的配煤比例;单煤供应量mi=M×Xi≤M(i=1,2,3,4),M为企业每天平均耗煤总量,t;m为各种煤每天最大供给量,t。
3 目标函数的建立及求解
对于煤化工企业而言,降低原料成本至关重要,也是企业不断追求的目标。根据实际情况,4 种单煤参与配煤,第i种单煤的成本(运输成本与单价总和)为Ai,其配煤比例为Xi,配得煤总成本为F(x)。约束条件及范围确定后,模型目标函数[6]可由式(2)表示:

企业可用的4 种单煤的煤质参数见表1,以价格最低为优化目标,此函数为极小值问题,帕累托(Pareto)最优算法能有效解决最小值最大值问题。Pareto 最优[7]的定义为:在设计变量组的取值范围U内,对于所有设计变量组X∈U,仅存在一个设计变量组X′在约束范围内满足:(1)F(iX)≤F(iX′);(2)至少有一个X使Fi(X)<Fi(X′),则设计变量组X′为Pareto 最优解。考虑到遗传算法较好的性能,以下采用Pareto 的遗传算法对目标函数求解,选取种群个数为100,Pareto 前沿面解比例为0.3,迭代次数为100 进行计算,通过该方法计算得到最终最优价格为498.78 元/t。配煤优化算法流程示意图见图2。

图2 配煤优化算法流程示意图
对企业可用的4 种不同煤质的单煤,运用文中建模及优化算法进行仿真求解,得到优化后煤质配比为纳二煤20.49%,凯达煤14.90%,纳二4#煤37.93%,宝山煤26.78%,配成煤的总单价为498.78 元/t。优化配煤后和企业平均配煤方法得到煤的煤质参数见表4。对比表4 和表1 可以看出,优化配煤配出的煤与所用单煤宏一煤煤质差距很小,但是在价格上要比单煤和平均配煤都更便宜,比直接用宏一煤便宜了10.90%。

表4 优化配煤后煤和企业平均配煤方法得到煤的煤质参数
鄂尔多斯不少煤化工企业也在进行配煤研究,目前主流的配煤方式有两种。一种是按照经验和对气化炉的深入认识进行试验配煤,一般是按照平均比例进行初步分配(平均值法),然后不断试验找到最好的配煤比例。与这种平均值法相比,文中的方法可以比较准确地获得煤质的参数和配出煤的成本价格,并且配煤便宜了6.77%。另一种方法是以一种煤质较好的煤为主煤,以另一种价格便宜的煤为辅煤进行混配,以主煤比例从100%阶梯式的下降进行配煤,然后进行入炉燃烧试验,最后得出一个主煤的最小比例,主煤越少,成本越低。但是这种方法试验周期比较长,配煤过程需要耗费较多的人力物力,得到的最佳比例也是比较模糊的比例,同时不能摆脱对主煤的依赖,每次主煤或者辅煤发生变化就要进行新的配比掺烧试验,适用条件受到限制。
实验和分析表明,文中优化配煤的方法可以解决煤产量不足问题以及达到降低生产成本的目的。对比文献[8]王鹏的配煤最优化方法,文中所述的方法能在其优化过后的基础上每吨再降低7 元,这对于大型煤化工企业来说,一天就可以节省成本7 万元左右。对比文献[9]中直接使用遗传算法进行4 种煤的配比,用文中方法进行计算,可以降低成本到223 元/t,比文献中230 元/t 减少了7 元/t。
混配煤得到煤质参数以后,为了对所配煤质进行全面的了解和分析,采用BP 神经网络建模,进行所配煤产气量的预测。
人工神经网络简称为神经网络(NNs)或称作连接模型,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型[10]。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,达到处理信息的目的。BP 神经网络是一种按误差反向传播的多层前馈神经网络,根据误差反复调整网络的权值和阈值,达到预测输出值不断逼近期望输出值的目的。使用BP 神经网络,通过设置合适的隐层节点数和训练学习函数等参数,便可以在误差范围内得到准确的预测模型。产气量预测BP 神经网络结构图见图3,其输入参数为煤质、装煤量、耗氧量,输出参数为产气量。

图3 产气量预测神经网络结构图
气化炉中影响产气量的因素较多,固定温度、压力等变量,只分析入炉煤质和耗煤量、耗氧量对产气量的影响。用气化炉的456 组生产数据的前380 组数据作训练集,后76 组数据作测试集,分别用经典BP神经网络、遗传算法优化及粒子群算法优化的BP 神经网络进行粗煤气预测的建模,3 种预测模型的预测结果见表5。
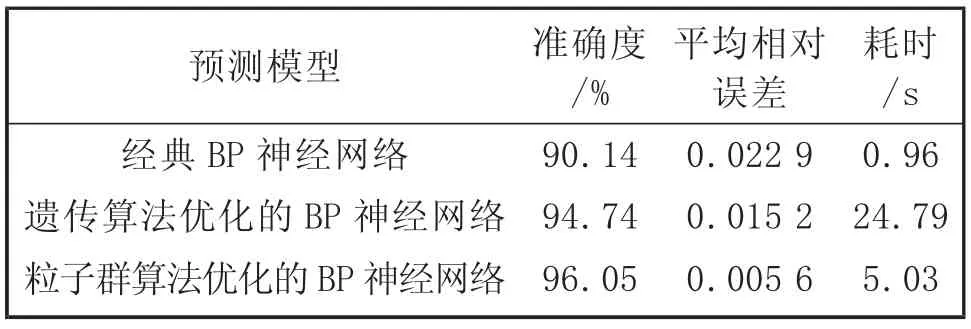
表5 3 种预测模型的预测结果
由表5 可知,3 种BP 神经网络都能够较为准确地建立预测模型,优化过后的BP 神经网络准确度都有所提高,但是用遗传算法优化时耗时太长,而用粒子群优化算法[11]得到的模型最准确,且用时较少,所以采用帕累托算法建立配煤模型、粒子群算法建立预测模型。预测模型建立后,通过配出的煤质与耗煤量、耗氧量能预测产气量,通过产气量的效率分析,再次对配成的煤质进行二次成本评估和配煤优化。
用MATLAB 的GUI 建立可视化配煤系统,对配煤过程进行在线监控。配煤可视化界面中,将配煤分为优化配煤和比例配煤。优化配煤部分先根据需要或者实际情况设置约束条件,包括水分约束、灰分约束、挥发分约束、硫含量约束、低位发热量约束、可磨性约束以及原料煤供应量约束,再输入单煤煤种参数,然后开始优化。系统会根据配煤优化方法进行优化配煤,输出满足约束的成本最低的配煤比例和配比煤质,然后通过微调配煤比例,得到理想价格下的煤质。在按比例配煤之前,首先输入配煤的煤种参数,设置配煤比例,然后开始配煤,系统会根据煤质的物理特性进行比例配煤,配煤结果会显示在配煤参数框内。此外,可以在产气量预测模块中预先设置入炉的煤量和氧气量,在配煤完成后,系统会将配煤煤质作为产气量预测的煤质输入,自动进行计算,将产气量作为输出显示在输出框内,同时评价在此情况下配煤的效果是优秀、良好还是一般。
4 结 语
从企业实际生产中提炼问题,对问题确定约束条件参数范围、建立目标函数并对其进行优化和求解,运用基于数据的方法进行分析。这种方法简洁明了、贴近实际工业生产,能解决某些其它方法不能解决的问题。本文利用数据分析的方法简化了最优配煤的建模过程并进行了优化求解,并对配煤过程进行了可视化仿真,达到降低成本以及优化配煤的目的,可解决单煤厂家停车或者单煤库存不足的问题,提高企业的生产效率,降低生产成本,解决部分企业存在的配煤问题。
