采用时间序列的高校后勤报修量预测
2020-05-11肖香梅林志兴
肖香梅,林志兴,余 建
(三明学院 网络中心(信息化建设办公室),福建 三明 365004)
随着高校信息化的发展,为及时解决师生报修诉求,后勤报修系统应运而生。通过对报修数据进行分析,预测报修量发生的高峰期,能够精准地为高校维修零件采购、人员安排等提供决策,提高高校的管理服务水平,具有重要的现实意义。
目前一些学者也对故障报修数据进行了相关研究,孙芳[1]利用决策树算法对网络故障报修数据进行挖掘和分析,实现了对故障原因和故障类别的分类挖掘。张明杰等[2]从统计学角度出发,分类别建模,对电力客户服务报修业务量进行预测分析。蔡冬阳等[3]运用多元线性回归方法,构建故障报修受理数量分时段预测模型。邹墨[4]对故障报修工单进行大数据挖掘,重点分析数据之间的联系,找到报修过程中的薄弱环节,对故障报修进行精细化管理。但他们的研究更多的是从静态的方法进行分析,未考虑到时间的相关度,无法从动态的角度描述报修数据的内在关系和变化规律。如果考虑到时间的相关分析,那么可以使用时间序列的相关方法。本文提出基于时间序列的方法对高校后勤报修量进行预测,对历史数据时间序列进行分析研究,精准的预测报修量,为高校管理服务提供决策依据。
1 时间序列基本理论
1.1 时间序列
时间序列是按时间次序排列的随机序列 X1,X2,…,记为{Xt,t∈T}或{Xt},T 为离散的指标集[5]。时间序列预测分析是一种回归预测方法,目的是从历史数据中挖掘出变化规律,对未来数据进行预测,为决策者提供决策依据。判断序列是否可以使用时间序列预测,首先从时间的角度可以把一个序列基本分为3类。
(1)纯随机序列(白噪声序列),这类序列毫无规律,无法进行预测;
(2)平稳非白噪声序列,这类序列的均值和方差为常数,可以用成熟的模型来拟合;
(3)非平稳序列,这类序列需要通过差分处理转化为平稳序列后按照平稳序列的模型进行拟合。
时间序列模型的预测方法主要包括自回归模型 (auto regressive moving,AR)、移动平均模型(moving average,MA)、自回归移动平均模型(auto regressive moving average,ARMA)、自回归求积移动平均模型(auto regressive integrated moving average,ARIMA)等。其中,AR模型、MA模型和ARMA模型常用于对平稳序列的预测分析,而ARIMA模型则用于对非平稳序列的预测分析。
时间序列预测方法近年来被广泛运用于多个研究领域,并且能够取得很好的预测结果。该方法不依赖外部变量,可以在一定程度克服影响因素考虑不周导致模型的精度不足问题。高校后勤报修量受天气、季节、设备年限等较多不确定因素影响,故采用时间序列方法进行预测。
郑琰[6]等通过应用ARMA模型,对阿里巴巴旗下电商企业未来一周内的部分商品进行需求预测,对电商企业的经营、管理提供决策支持。钟彬文等[7]通过建立ARMA模型,对未来3年浙江省城镇人均可支配收入进行预测,对了解人们生活水平具有重要参考价值。罗利等[8]利用ARMA模型对肾脏内科入院量数据进行预测,为医院制定相关决策提供依据。邵艳君[9]通过建立ARMA模型,对我国油菜籽单产量进行预测,为油菜的留种和播种提供调控依据。张改红[10]采用ARIMA模型对渭南市降水量进行预测分析,为水资源合理调配提供依据。
1.2 ARMA模型
ARMA模型是时间序列分析的重要方法,由AR模型和MA模型结合而成。如果一个系统在t时刻的观测值为 Xt,不仅和它之前的观测值 Xt-1,Xt-2,…相关,还和它之前时刻的扰动εt-1,εt-2,…以及t时刻的扰动εt相关,那么这个系统就叫做自回归移动平均系统。
ARMA模型基本形式为φ

模型中{εt}是白噪声序列,∀s<t,有 EXtεt=0,记为 ARMA(p,q);若 φ0=0,则称为中心化的 ARMA(p,q)模型。 p 和 q 为非负整数,也称为阶数。 模型可以转化为 α(L)Xt=β(L)εt,一般需假定 α(u)、β(u)无公共根。
α(L)=1-φ1L-…-φpLp,为 p 阶自回归系数多项式。
β(L)=1-θ1L-…-θqLq,为 q 阶移动平均系数多项式。
其中,若q=0,模型退化为AR模型,记为AR(p),若p=0,模型退化为MA模型,记为MA(q)。
2 时间序列建模预测流程
时间序列建模预测流程如图1,具体有如下6个操作步骤。
(1)采集数据,为模型建立做准备;
(2)对数据进行平稳性检验,若该序列为平稳序列,则进行下一步骤模型识别,否则进行差分处理,再对数据进行平稳性检验;
(3)通过自相关系数、偏自相关系数确定适用模型的种类;
(4)确定模型的阶数;
(5)检验已建立的模型用于描述时间序列是否恰当,即检验残差的自相关性,若无法通过检验,则需要对模型进行优化和重构;
(6)若模型通过残差检验,利用建立的模型进行预测分析。
利用MATLAB系统辨识工具箱,采用ADF(augment dickey-fuller test)检验方法对某高校报修量时间序列进行平稳性检验,检验结果为平稳序列,通过分析自相关系数和偏自相关系数确定建立ARMA模型,通过AIC(an information criterion)准则确定模型的阶数,对已建立的模型进行检验,模型通过检验,利用已建立的模型对报修数据进行拟合、预测,并对预测数据和真实数据作对比,证明基于时间序列的高校后勤报修量预测方法可行。

图1 预测流程
3 实例分析
为了解决报修数据的时间相关度,本文提出基于时间序列的高校后勤报修量预测方法。
3.1 数据准备
本文选取2017年9月-2019年10月某高校报修平台数据进行分析,其中2017年9月-2019年8月的680条报修数据为训练集,2019年9月-2019年10月61条报修数据为预测集,验证模型的拟合度,原始数据如图2所示。

图2 原始数据
3.2 数据平稳性检验
如果一个随机时间序列,其基本状态维持不变也就是要求样本数据的本质特征能延续到未来,称这些统计量(均值、方差、协方差)的取值在未来仍能保持不变,则时间序列具有平稳性[11]。平稳性检验的常用方法是单位根检验(dickey-fuller test,DF检验)[12],ADF[13]检验是对DF检验的扩充,本文采用ADF检验方法对数据进行平稳检验。如果时间序列Xt通过d次差分成为一个平稳序列,而这个序列(d-1)次差分却不平稳,则称序列Xt为d阶单整序列,记为Xt~I(d)。ADF检验假设数据由于ARMA模型的动态结构,零假设是Xt为I(1)序列,备择假设Xt是为I(0)序列。无常数项和时间趋势项的ADF检验的回归方程为

其中,p阶滞后差分ΔXt-j用来近似估计误差项的ARMA结构。p值的确定要基于误差项εt是序列无关的,并假设误差项同方差。在零假设条件下,Xt为I(1)序列或者ρ=1。ADF检验的t统计量和ADFn统计量是基于方程(2)的最小二乘法估计得到,表达式如下

如果ADF检验的t统计量拒绝零假设,则说明被检验序列是平稳序列,否则说明被检验序列是非平稳序列,需要对其进行差分处理后再进行进一步检验,直到ADF检验的t统计量拒绝零假设。利用MATLAB工具箱中h=adftest(X)函数,对样本数据进行平稳性检验,得到h=1,表示拒绝有单位根的原假设,说明数据平稳,可以进行下一步骤。
3.3 模型识别
确定样本序列为平稳序列后,可以利用AR、MA、ARMA等三类平稳模型对序列进行拟合。这里考查样本序列的自相关系数和偏自相关系数的拖尾和截尾性质。
(1)对于平稳AR(p)模型,偏自相关函数PACF(partial auto correlation function)在p阶之后应为零,称其具有截尾性;自相关函数ACF(auto correlation function)不能在某一步之后为零(截尾),而是按指数衰减(或成正弦波形式),称其具有拖尾性。
(2)对于平稳MA(q)模型,自相关函数ACF在q阶之后应为零,称其具有截尾性;偏自相关函数PACF不能在某一步之后为零(截尾),而是按指数衰减(或成正弦波形式),称其具有拖尾性。
综合平稳ARMA(p,q)模型的相关系数和偏自相关系数的拖尾和截尾性质,得到表1的结论

表1 模型的相关系数和偏自相关系数结论
由表1可知,若样本序列的自相关系数拖尾、偏自相关系数截尾,则建立AR模型;若样本序列的自相关系数截尾、偏自相关系数拖尾,则建立MA模型;若样本序列的相关系数和自相关系数都是拖尾的,则建立ARMA模型。
利用MATLAB工具箱的autocorr(X)和parcorr(X)绘制报修量序列的自相关和偏自相关函数图像,如图3。
由图3,可以看出样本序列的自相关系数和偏自相关系数都表现出拖尾性,故建立ARMA模型。
3.4 模型定阶
阶数p,q的确定过程比较严谨的方法是AIC准则[14-15]定阶法,它适用于AR、MA、ARMA三类模型。AIC准则是一种基于观测数据选择最优参数模型的信息准则,它既要衡量模型对原始数据的拟合程度,又要考虑模型中所含待估参数的个数,即模型复杂度。对于样本长度为N的序列,ARMA模型的AIC定阶过程如下。
(1)设{Xt:1≤t≤N}为一随机事件序列,对其拟合 ARMA(p,q)模型,分别确定(p,q)的上界 p0和 q0,记为;H={(k,l)∣0≤k≤p0,0≤l≤q0};
(2)对于任意的(k,l)∈H,AIC 准则函数定义如下

图3 报修量自相关和偏自相关图像

可以看出,AIC准则函数由两部分构成,第一部分是极大似然估计的对数,反映模型拟合的好坏,第二部分反映模型参数的多少。对于给定观察数据长度N,当模型阶数增高时,第一部分是下降的,第二部分是增长的。当逐次增加模型阶数对数据进行拟合时,AIC的值下降是有趋势的,这时第一部分下降的比较快,起决定作用,当达到某一阶数时,AIC值达到极小。随后,当模型阶数继续增高,第一部分改变很小,这时第二部分起决定作用,AIC值随模型阶数的增长而增长。对于给定的最高阶数M(N)

MATLAB工具箱中,首先利用arima(p,0,q)函数定义不同的ARMA模型,再用estimate(mdl,X)函数对以上模型进行估计,最后通过AICSet=aicbic(logL,numParam)函数计算模型的AIC准则值,MATLAB计算程序如下:


计算结果如下:

AICSet(i,j)1234 1 5.966 9 5.958 8 6.133 6 6.126 8 2 5.953 1 6.314 2 6.375 3 6.326 7 3 5.967 5 6.328 4 6.417 4 6.479 4 4 5.968 4 6.339 0 6.428 1 6.493 3
由以上结果可知,ARMA(1,2)准则值最低,为最优模型。
3.5 模型诊断
模型诊断主要检验残差的自相关性。对于模型ARMA(p,q),残差为:



零假设和备择假设为

Ljung和Box[16]证明,如果ARMA(p,q)模型正确设定,那么等式(8)中统计量服从自由度为K-p-q的卡方分布。如果,则拒绝H0,表明模型是不充分的,否则ARMA(p,q)正确设定。
MATLAB工具箱中,利用hLBQ=lbqtest(res)函数检验残差的自相关性,结果如下
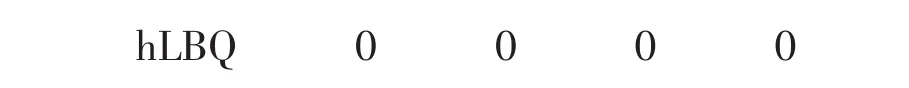
由以上结果可以看出残差不具有相关性,因此模型ARMA(1,2)可以信任,残差图如图4。
3.6 预测分析
本文取2019年9月-2019年10月61条报修数据为预测集,用ARMA(1,2)模型预测这两个月的报修数据,预测结果如图5。

图4 残差图

图5 预测结果
观察图5,预测结果良好,实际数据与预测值误差较小,拟合度高。
3.7 模型比较
分别建立AR模型和MA模型,对预测集数据进行预测,计算复相关系数R和剩余标准差S,见表2。其中复相关系数数值越大表示精度越高,剩余标准差数值越小表示精度越高。由表2可以得出,3种模型在报修量预测上都有较高的精度,但较之AR模型和MA模型,ARMA模型具有更高的精度。

表2 比较3种模型的R和S
4 结论
本文根据高校后勤报修数据的时序特征,采用ARMA建模,对报修量进行分析预测,根据预测结果可以看出数据拟合效果良好,整体相对误差较小。时间序列模型的关键在于模型的正确选择,通过比较发现,选择正确的模型可以提高模型预测的精度。说明本文方法对平稳序列的预测精度较高,能够反映出报修量的变化趋势及高峰期。对高校管理决策来说,使用该方法进行维修工作准备,可以提前采购网络维修零件、设备,做好工作人员安排等工作,方便保障学校正常运行。
