基于BP_K-C4.5算法的高血脂辅助诊断系统
2020-04-29方克邦张云华
方克邦, 张云华
(浙江理工大学 信息学院, 杭州 310018)
0 引 言
随着社会的发展和人们生活方式的转变,高血脂症的发病率在逐渐升高,给人们的健康带来极大困扰。因此必须对高血脂症做到早发现、早治疗、早预防[1]。而在进行疾病诊断时医生却由于受到专业限制或主观因素影响,容易造成疾病的误诊或更严重的后果。结合现代计算机技术的快速发展,若能将计算机数据分析技术应用到疾病诊断,将大大提高诊断准确率和效率。
海量的医疗数据中蕴藏的知识,是现代计算机和医学分析的巨大资源宝库。针对这些数据分析前通常都要进行数据的特征处理,找出最优的特征子集以便数据的分析处理,这也是数据分析的重要前提。因此本文以高血脂为研究对象,首先改进BP神经网络算法,考虑到其具有的对数据自适应、容错性和自组织性强等优点,在此基础上进行数据特征选择。然后把这些数据使用K-C4.5分类算法模型进行预测分析。最后根据特征选择和分类预测算法模型设计了一套高血脂辅助诊断系统,此系统能帮助医生进行更加全面和准确的诊断。
1 BP神经网络算法对数据进行特征选择
BP神经网络中可以借助信息的正向传播和反向传播,来提高接受信息的准确程度。输入层各神经元接收来自外界的输入信息,并传递给中间层各神经元[2]。中间层是内部信息处理层,用于信息变换,根据信息变化能力的需求,中间层可以设计为单隐层或多隐层结构[3]。最后一个隐层传递到输出层各神经元的信息,经过进一步处理后,完成一次正向的传播过程,由输出层向外界输出信息处理的结果[4]。当实际输出与期望输出不同时,进入误差的反向传播阶段。误差通过输出层,按误差梯度下降的方式修正各层权值,向隐层、输入层、逐层反传[5]。周而复始的信息正向传播和误差反向传播过程,是各层权值不断调整的过程,也是神经网络学习训练的过程[6],此过程一直进行到网络输出的误差减少到可以接受的程度或者预先设定的学习次数为止。综上论述可知,BP网络由3部分组成:输入层、隐藏层和输出层[7]。BP算法的定义公式如下:
(1)
分析可知,其输出是输入的非线性函数,范围是0-1。BP网络的示意图如图1所示。

图1 BP神经网络模型图
1.1 前向传播
数据进行前向传播的过程根据如下公式计算得出:
(2)
第一层网络参数为:
(3)
第二层网络参数为:
(4)
第三层网络参数为:
W(3)=[w(4,6),w(5,6)],b(3)=[b6],
(5)
第一层隐藏层有3个神经元:neu1、neu2、neu3,该层的输入为:
(6)
以神经元neu1为例,则其输入为:
z1=w(x1,1)*x1+w(x2,1)*x2+b1,
(7)
同理有:
z2=w(x1,2)*x1+w(x2,2)*x2+b2,
z3=w(x1,3)*x1+w(x2,3)*x2+b3.
(8)
假设研究选择函数f(x)作为该层的激活函数,那么该层的输出为:f1(z1)、f2(z2)、f3(z3)。
1.2 反向传播

假设要对第k层的参数W(k)和b(k)求偏导数,设z(k)表示第k层神经元的输入,即:z(k)=W(k)*n(k-1)+b(k),其中n(k-1)为前一层神经元的输出,则根据链式法则有:
(9)
本次研究中利用了BP算法的前向传播和反向传播,首先通过前向传播对数据进行降维处理,充分利用了其传播的特性,使得最后得到的数据能够更加接近准确值,但是传播过程难免会有一定的误差,采用BP算法的后向传播来解决这个问题。
2 改进的 K-C4.5算法进行数据分类
2.1 改进的分类算法模型
通过BP算法得到的低维数据,再构建C4.5决策得到更加准确的分类数据。分类技术是数据挖掘领域中一种常用的基本研究方法[10]。决策树技术是数据挖掘的重要分支,由于其具有简单直观,易于理解,分类效率高等特点[11],被广泛应用。C4.5算法构造决策树时选择分支节点属性的依据是信息增益率[12]。C4.5算法以信息增益率为属性节点的选择依据,克服了ID3算法的倾向于选择取值较多的属性的不足[13]。
经典的ID3算法由于不具备对连续属性的处理策略,以及其信息增益度偏向于具有大量的属性[14]。针对这些缺点,改进衍生出C4.5算法。在ID3算法中算法的属性选择计算公式为:

(10)
其中,Pi为数据集T(类属性值的个数为n)中任意元组属于类Ci(i=1,2,…,n)的不为0的概率,并用|Tci|/|T|进行估算得到;而Info(TAj)是按属性A(属性值个数为m)划分T的元组分类的信息熵。
C4.5算法用信息增益率的计算代表ID3算法中的信息增益公式,其计算公式如式(11)所示:
(11)
其中,SplitInfoA(T)是在数据集T中,属性A的分裂信息,具体计算公式为:
(12)
在对C4.5算法进行使用分析中,采用改进算法执行过程的计算公式来优化算法,针对信息增益的计算公式结合泰勒公式和对数换底公式,可以将信息增益公式简化为式(11)。泰勒公式和对数换底公式分别表示为:
(13)
(14)
这样变换是为了简化数据运算,省去了对数运算,如此一来就避免了对数运算时的函数调用,大大缩短了运算时间。采用泰勒公式进行变换的原因是,泰勒公式是用一个函数在某点的信息,描述其附近取值的公式。如果函数足够平滑,当已知函数在某一点的不同阶导数值的情况下,泰勒公式可以利用这些导数值来做系数,构建一个多项式近似函数,求得在这一点的邻域中的值。也就是说,用一个多项式函数从函数图像上的某个点去逼近一个给定的函数。变换后的公式如下所示:
(15)
在数据集中有些条件的属性值是相对稳定的,这类条件属性的信息增益率就会比较大;但有些信息增益率比较小的条件属性在理论情况下是不稳定的属性值,但如果这些属性是比较重要的属性,一旦被舍弃将会造成分类不准确,为了避免这一问题,采用描述属性值变化率的平均值的平均波动率[15]来解决,同时还引入一个描述属性重要程度的属性“应用权重[15]”来平衡数据集在具体应用中对于某些属性关注程度。
引入这两个参数之后, C4.5 的信息增益率计算公式则变成:

ApliWeight,
(16)
公式(16) 即为最终的属性选择的度量公式,这样改进后的度量公式,不仅消除了由于属性值的影响,而且不存在对属性的倚重程度而带来的不合理的划分问题。
此后,就对数据进行KNN算法的数据表预测,分别对分类出来的每类样本进行预测,每类的70%的样本用于训练,而剩下的30%样本则作为预测,样本预测的步骤可分为下面几步:
Step1随机挑选出70%的样本作为训练集S,输入训练集S。
Step2确定K值,在训练集S中随机挑选出n个样本xt进行预测,t=1,2,…n,在训练集S中找到与样本xt距离最近的k个样本yi组成集合Stk,其中i=1,2,…,k。
Step3利用高斯函数计算权值,权值计算公式为:
(17)
其中,wti为集合Stk中第i个样本的权值;Li为集合Stk中第i个样本到样本Xt的距离;c为标准差;a取值为1。

Step5计算准确度。计算时将用到如下数学公式:
(18)
Step6若准确度R达到要求,则训练完成,并对剩余的30%的样本进行预测,得出预测结果,计算准确度;若准确度达不到R要求,则返回Step 2重新确定k值。
2.2 实验分析
本实验是在2个数据库的混合数据上进行的,共2 000个特征属性,选用单隐含层的BP神经网络,隐含层激活函数使用Sigmoid函数,输出层激活函数为线性函数。为了得到较好的神经网络结构,实验中分别对当隐含节点为1~50时的网络分类情况来判断哪个隐含节点数较好。将每个隐层节点数下的网络训练10次,由此得到这10次实验中的测试集识别率,并求出和的平均值,得到如图2所示的结果。

图2 隐层节点平均识别率图
由图2可知,当隐层单元节点为25时,其测试集平均识别率为95.12%,此时的网络结构分类能力最强。所以本实验最终选择隐层节点数为25的BP神经网络进行实验。
以上步骤是对数据的特征选择,选择出来的最优特征子集是后续分类预测的重要基础。在综合测试中为了减少分类结果的误差,提高分类精度,本分类模型共进行10次实验,并且为了突出实验的有效性,这部分采用UCI数据集做验证。最终的相关实验结果指标参数,都采用多次实验结果取平均值的做法。实验分类的结果绘制如图3、图4所示,实验分类结果数据详见表1。
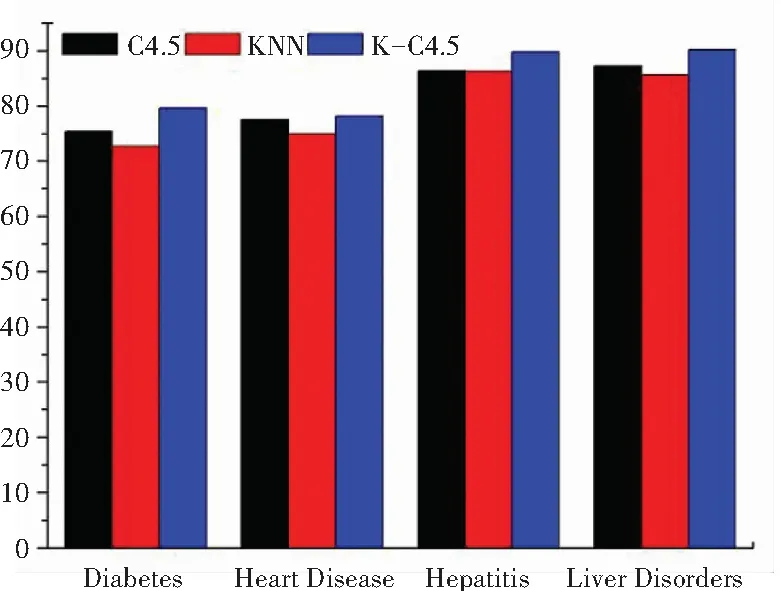
图3 算法的分类准确率比较图

图4 算法灵敏度实验对比图
Fig. 4 Comparison of experimental sensitivity of the algorithm

表1 BP_K-C4.5算法模型分类结果
通过实验数据可以清晰地观测到,改进后的算法模型相较传统的分类算法,在精度、准确度、效率上都有所提升。
3 高血压预诊系统设计
本次研究中,前端部分使用vue框架进行开发设计,并兼容主流的浏览器。服务端开发使用Java语言,使用Spring Boot作为后台框架、数据库使用MySQL、缓存使用Redis、消息中间件使用kafka等。
3.1 系统总体设计
3.1.1 功能模块
高血脂辅助诊疗系统如图5所示,主要分为系统设置模块、数据维护模块、辅助诊断模块、患者管理模块。系统的核心模块为辅助诊断模块。该模块重点是对数据集进行主成分分析,提取出数据集中的主要成分,达到降低数据复杂度和维度的效果,再对主成分数据集进行分类预测,最终根据不同的分析结果参数,进行信息提示。数据维护模块主要包括电子病历管理、历史数据维护、统计报表功能;患者管理模块主要包括自主诊断分析、预约挂号、病情跟踪等功能。基础服务模块主要包括权限设置、日志管理、帮助服务、数据字典维护等功能。

图5 高血脂辅助诊断和信息管理系统功能模块
Fig. 5 Functional module of hyperlipidemia-assisted diagnosis and information management system
3.1.2 系统架构
系统设计架构见图6,对此拟做研究论述如下。
(1)调用方:系统设计可调用的前端应用平台包括:响应式Web网页、移动端等。
(2)分布式微服务:该部分采用的是分布式微服务系统Spring Boot。具体分为网关层、代理层、服务层。网关层主要负责统一请求入口,配合前端完成权限验证,对外提供restful API,并对API进行动态限流。 代理层负责抽象出公共的服务接口,在代理层将请求路由到具体的服务。

图6 高血脂分类挖掘系统框架
Fig. 6 Framework of a hyperlipidemia classification and mining system
3.1.3 系统流程
系统的详细使用流程如图7所示,主要包括数据录入、主成分分析提取模块、模型构建、预测分析等模块。对此流程可做阐释分述如下。

图7 系统使用流程图
(1)特征选择:首先将请求发送到网关层进行权限校验,校验通过则由代理层将请求路由到具体的服务。服务层首先需要对数据进行清洗,然后利用PCA主成分分析算法提取出数据集中的主要成分并保存到数据库。
(2)数据录入:在客户端进行电子病历的录入等操作时,请求在网关层进行安全校验,然后代理层将数据中的各项指标请求路由到具体的服务,服务层会将有效的数据保存至数据库。
(3)模型构建:首先请求会在网关层进行权限的校验,校验通过后会通过代理层将具体的请求路由到具体的服务。然后具体的服务将对数据进行量化处理,再使用C4.5分类算法对数据进行分类挖掘,找出高血脂相关的关联规则,此后将该关联规则保存在数据库。
(4)预测分析:点击预测分析按钮后,请求经校验通过后,由代理层将请求路由到服务层后,对数据进行关联分析,并返回分析结果及信息提示。
3.2 系统功能模块展示
在经过模块调试、系统整体功能调试以及兼容性测试等一系列工作后,系统达到预期目标。系统可正常完成页面设计功能。这里将撷选系统核心功能部分页面进行展示。对此可描述为:
辅助诊断模块首先是选择需要分析的数据,进行特征选择,特征处理结果如8所示,在此可以选择需要分析的特征,默认为全选。执行分析页面可以编辑要分析的特征以及权重和阈值,如图9所示。在执行分析后分析结果如图10所示,将详细展现患者基本信息和分析结果的图标展示,以及分析意见与建议。
图8 特征选择页面

图9 执行分析图

图10 分析结果图
4 结束语
高血脂症是一种常见的发病率极高的慢性病,因此高血脂的防治显得尤为重要。本文首先改进特征选择算法BP神经网络算法的反馈网络的权值、阈值,使神经网络修正更加精确高效,然后对最优特征子集使用改进的K-C4.5算法进行分类预测,该改进的分类模型综合C4.5算法和K阶最近邻算法的优点,并改进C4.5算法的数据读取方式,最终改进的算法模型相较传统算法,有着更高的分类精度和效率。基于改进后的算法模型设计的高血脂辅助诊断系统,能够有效地辅助医护人员的工作,具有较强的使用价值。
