基于滑动窗口的CP-nets增量式学习研究
2020-04-29何新新
何新新, 朱 阳
(烟台大学 计算机与控制工程学院, 山东 烟台 264005)
0 引 言
在现代社会各专业领域的发展中,实时数据的研究与处理已经比较成熟,其中包括推荐系统中数据流的偏好信息挖掘和决策的生成等方面的数据处理[1]。多数的偏好数据处理工作都是在静态时刻场景中进行,并不能排除随着时间逐渐推移甚至其他因素的不确定性对用户的数据偏好会产生不容忽视的影响[2]。某个静态时刻场景的数据库只能判断用户静态的偏好信息。并不能有效地处理动态性比较强的数据流挖掘,例如在金融市场的银行交易[3]。
本篇论文主要集中研究的是时间因素对用户偏好演化的影响。在现实社会的应用中,用户偏好大多是动态性的,也就是说能够随着时间的推移而产生偏好的变化[4]。传感网络发展潜力下的网页随时间推移能够动态地批量变换,商务网站提供的产品广告因为客户需求和企业计划的改变而做出动态的调整,这都属于动态的数据流偏好模式。要得到用户动态的偏好信息帮助判断用户的购买需要和模拟用户的购买过程,就要运用动态的数据流处理模型、即CP-nets的增量式学习研究确定偏好信息[5]。这种模型下的推荐系统具有的优点就是动态地获取用户的偏好信息,然后根据用户的偏好推荐合适的个性化产品信息[6]。
用户的某个静态时刻场景中的偏好在现实社会中的合理性和实用性都是较低的外界环境中的各种因素随着时间前进的改变导致用户的偏好是动态变动的,例如在头条的新闻网站或者是社交网站中的热门新闻和热门搜索都是随着时间的变化在不断地改变,这是因为用户的偏好在不断地改变,兴趣在不断地更新,因此数据挖掘技术就要提出新的偏好挖掘模型来应对这种基于时间的动态数据流[7]。
动态的偏好数据挖掘在人工智能领域更具有挑战性,虽然动态的偏好数据挖掘在数据存储和数据流的海量增加两方面都具有优势[8-9],但也存在以下两方面困难:
(1)数据没有储存,在需要时也无法获得,每个数据元组在到达时必须被接受,一旦被丢弃,不可能再次被检查。
(2)在静态数据处理中,连续增加的数据将成为海量数据,由于存储空间的增加使得CPU负荷过高。
在本文中提出的基于滑动窗口的CP-nets增量式学习方法将数据流进行动态挖掘处理,本文的主要贡献如下:
(1)基于滑动窗口的CP-nets增量式学习方法解决了静态数据存储以及运算上存在的存储空间占用大,算法耗时长等困难。
(2) 基于滑动窗口的CP-nets增量式学习方法不仅可以处理可扩展的累积偏好数据,还可以处理不断增加流式偏好数据。
(3)实验证明,CP-nets增量式学习方法可以学习得到一个准确的CP-net。对于同一个数据集,该方法得到的实验结果与传统学习方法得到的结果大体一致,支持任意的结果比较。
1 相关工作
随着社会的发展,数据的产生逐渐趋于流式化,数据流中偏好数据挖掘研究在近年得到广泛发展。Papini等人[10-11]提出2种从数据流中挖掘偏好关系的算法,允许指定一些特定属性取值在所有数据中优先可取,即提前定义不同属性的重要性,而不是计算属性之间的依赖关系。从现实意义上说一个数据模式里面属性的偏好关系更体现在属性的依赖关系,即同一属性不同取值在约束相同的条件下对其他属性取值偏好产生的重要影响。本文的工作是从偏好问题的紧凑关系定义角度看,属性之间的依赖关系大于属性之间的优先关系。 与 Papini 等人的研究不同的是,本文提出的算法不是研究属性之间的优先级,而是主要研究属性之间的依赖关系,并且是在动态的偏好数据流中学习CP-nets。
由于偏好信息在推荐系统等方面具有巨大的应用价值,从CP-nets这一偏好模型的提出,一系列学习该模型的算法被先后提出。学习CP-nets方法可以分为: 主动学习、被动学习、启发式学习和精确学习。
Koriche等人[12]提出的主动学习算法,引导用户通过一系列查询来识别具有二进制值的CP-nets的偏好排序。Aggarawal等人[13]通过启发式学习方法提出了一种不确定数据流的聚类方法,创建了一个不确定性模型。Liu等人[14-15]通过启发式学习方法从含噪声数据样本中学习CP-nets。大多数现有的学习方法忽略了对噪声数据样本的处理,文献[14]介绍了一种从噪声样本中学习CP-nets 的新模型,提出了一种多项式时间内求解偏好问题的算法。 研究中还提出了一种从不一致例子中学习CP-nets的被动学习方法[15],该方法利用分支搜索和界搜索将学习偏好图形问题转化为一个0-1规划问题,然后将得到的偏好图形等价地转化为CP-nets。 Mengin等人[16-17]通过对依赖结构的假设来研究解决了多属性域上的CP-nets学习问题。研究所考虑的假设是属性可分离(属性值之间不依赖,每个属性值的偏好独立于其他属性值)然后采用依赖结构无圈图的形式,求取一组局部偏好关系(CP-nets)。 Guerin等人[18]提出了一种不限于交换比较的启发式在线算法,该算法是一种新的智能体学习用户偏好的算法。 通过算法生成一系列在线查询学习,通过创建节点和初始化CPT来为用户构建一个CP-net。Liu等人[19]从不一致的例子中得到二元和多值变量上一致的CP-net。该方法不能解决数据量增加用户首选项可能会随着新数据的变化而改变的问题。
以上工作都是针对静态时刻场景中的静态数据提出的CP-nets学习算法,本文主要针对动态的数据流中属性之间的依赖关系进行CP-nets学习。
2 CP-nets相关概念
在本节中,主要介绍了CP-nets的表示和性质,并且举例说明了CP-nets在表示属性偏好中的应用。其中,2.1节给出了CP-nets的基本定义和表示,2.2节描述了CP-nets的性质。
2.1 CP-nets的基本定义
定义1 条件偏好关系偏好成对存在,共有3种关系(≻、、≈),用r(v,v')来记录,r(≻v, |v'|)表示属性v'取值不变的情况下属性v取值的偏好。在属性集合Dom(V)中,如果存在关系v≻v',vv',v≈v'分别表示相对于属性v用户更偏好于属性v';相对于v用户更偏好于v';用户在v和v'之间没有偏好。同一属性取值下的所有偏好对的全序关系称为偏好关系。
定义 2 父子关系属性之间的父子关系即依赖关系用pare(vi,vj)表示,vi为父属性,vj为子属性,记为pa(vj)=vi.Dom(vi)表示vi的有限定义域为Dom(vi)={o1,o2,o3,…,om},(A,B)∈V,(a1,a2)∈Dom(A),(b1,b2)∈Dom(B),属性A,B父子关系程度为:
(1)
定义3 条件偏好网络(CP-nets)[17]CP-nets由偏好网络结构和条件偏好表(conditional preference table,CPT)两部分构成,CPT是一个集合(V,E)的图模型G,其中V={v1,v2,v3,...,vn}是构成网络中节点的一组属性变量,而E是一组连接一对属性变量的有向边集合E={(vi,vj)|E(vi,vj),vi,vj∈V}。其中,E(vi,vj)表示属性vi是属性vj的父亲。每个节点都有一个条件偏好表,表示在其他属性取值约束下该节点属性取值的偏好。在CP-nets中,每个DOM(vi)表示vi的有限定义域。对于每个属性vi的父属性集合pa(vi)会影响对vi值的偏好。这定义了一个依赖图,其中每个节点vi与pa(vi)中的每个属性都有一条有向边。
为了更形象地说明CP-nets结构,图1是以客人选择晚宴菜单的CP-net结构图。集合V={W,M,S}分别代表菜单中的饮品、点心和主菜。DOM(W)={w1,w2}表示饮品,包括红酒和茶,DOM(M)={m1,m2}表示点心,包括酥饼和蛋糕,DOM(S)={s1,s2}表示主菜,包括牛排和鱼。这位客人更喜欢红酒和蛋糕,而对于主菜的选择取决于饮品和点心的选择。

图1 晚宴菜单的CP-net
2.2 CP-nets的性质
设N为任意一个CP-net,其所能表达的条件偏好关系为≻ ,o1,o2,...,om∈O为决策空间O中的任意m个结果.如果在N的导出图中,总存在包含一个或多个边的路径,从任意顶点oi出发均能到达oj,则说明oi和oj之间的占优测试成立,即oj≻oi。若结果序列(o1,o2,...,om)的如下关系:o1≻o2≻o3,oi-1≻oi,...,om≻o1不成立,即o1,o2,...,om不构成环形序列,则称CP-nets是一致的。任意一个无环的CP-net都是一致的。有环CP-nets的一致性不确定,当导出的结构图CPT没有出现环路时,则其满足一致性,当导出的结构图CPT出现环路时则不满足一致性。
若结果集O上任何两个结果之间的占优关系都能被≻所表达,总有oi≻oj或oj≻oi成立,则称 CP-nets满足完备性条件。如果N的属性集的大小为n,属性阈值Dom(Xi)=k,则属性结果集O的个数为kn,若结果之间的偏好关系个数满足kn-1(kn-1),则N为完备的CP-net[20]。
3 基于滑动窗口的增量式学习方法
为了提高数据处理的效率和速度,本文提出的基于滑动窗口的增量式学习方法主要是将偏好数据以部分滑动的形式输入到数据处理窗口中,将数据进行一种位序列形式的计数表示,再进行属性之间的依赖关系学习、即CP-nets的学习。
3.1 基本定义
定义4 偏好数据流P被称为偏好数据流,表示为P=(p1,p2,p3,...,pv),偏好数据流目前的偏好表达式个数记为|P|=v。设属性V={v1,v2,v3,...,vn},属性个数记为|V|=n。属性vi取值的有限定义域表示为Dom(vi)={o1,o2,o3,...,om},属性vi的一个取值表示为Dom(vi)=oi;属性vi的取值个数记为|Oi|=m。偏好表达式表示为:
pi=r(Dom(v1)×Dom(v2)×Dom(v3)×,...,×Dom(vn)),
(2)
定义5 偏好表达项式xj被称为偏好表达项式,表示为:
xj=r(Dom(v1)×Dom(v1)×,...,Dom(vz)),z≤n,
(3)
偏好表达项式xj与数据流中原有的偏好表达式pi存在被包含关系xj⊂pi(其中i,j为任意取值)。
定义6 偏好事务序列TDS被称为是一个连续的偏好事务序列,表示为TDS=(T1,T2,T3,...,Tn)。 其中,n表示最新传入偏好数据流Tn。事务Ti=(p1,p2,p3,...,pw)包含w个偏好表达式, 事务Ti表示为|Ti|=w。每窗口TransSWi包含固定的事务数量|TransSWi|=m。滑动粒度大小表示为s。滑动窗口表示为:
TransSWi=[TN-m+s,TN-m+2s,TN-m+3s,...,TN].
(4)
滑动窗口示例如图2所示。

图2 滑动窗口示例
举例说明:偏好数据库见表1,属性个数|V|=3,分别为V={A,B,C},属性取值|O|=2,分别为:A=(a1,a2),B=(b1,b2),C=(c1,c2)。TDS=T1,T2,T3,T4是当前时间一个连续的偏好事务序列,当w=3时Ti表示为Ti=(p1,p2,p3)。窗口大小表示为|m|=3,滑动粒度S=1的滑动窗口表示为:
TransSW1=[T1,T2,T3] ,TransSW2= [T2,T3,T4]。

表1 偏好数据库表
3.2 偏好关系的位序列表示
在基于滑动窗口的增量式CP-nets学习算法中,对于当前偏好事务序列TSD的滑动窗口TransSWi中偏好关系pi的子集xj,构造了一个二进制位序列,表示为Bit(xj)。如果偏好表达项式xj在传输中对于当前的窗口TransSWn存在,第i位xj被设置为1,否则,将被设置为0。
例如根据表1的偏好数据库可得到事务T1中偏好关系p1存在偏好表达项式x:a1b1≻a1b2。于是在窗口TransSW1中Bit(a1b1≻a1b2)=(100)。采用位序列的表示方法得到属性A,B的偏好关系的位序列表见表2。

表2 属性A,B的偏好关系的位序列表
3.3 初始窗口和滑动窗口
由表2可知,TransSW1表示初始窗口,TransSW1=[T1,T2,T3]。TransSW1中将偏好关系xi(xi⊂p)的二进制位序列相加,计算偏好表达项式xj的支持数,即窗口TransSWi中偏好表达项式xj的个数记为sup(xj)。例如表3中:
Bit(a2b2≻a1b2)=(100100001),偏好关系的计数值sup(a2b2≻a1b2)=3。由TransSW1在滑动粒度s=1时滑动得到TransSW2。根据表2中每个事务Ti中偏好表达项式xj的支持数sup(xj)|Ti将表3 中初始窗口TransSW1中的sup(xj)|T1删除并加上事务T4中偏好表达项式xj的支持数sup(xj)|T4得到滑动窗口TransSW2。属性A,B偏好关系的位序列见表4。

表3 初始窗口TransSW1中属性A, B偏好关系的位序列表

表4 TransSW2中属性A, B偏好关系的位序列表
4 CP-nets学习算法
针对属性偏好的本质,本文提出通过设置阈值变量对属性偏好关系进行定量判断后近似为定性偏好信息,该定性信息体现在CP-nets中能够描述属性之间的偏好关系。
4.1 基本定理
定理1比较2个属性之间的偏好关系时,可以理论上完全产生S=|O||O|×(|O||O|-1)对偏好关系,只有一个属性固定取值,另一个属性取值存在偏好关系时,即满足r(≻vn|vm=oi)或者r(≻vm|vn=oj)才是有效偏好关系。理论上产生有效偏好关系的个数为S'=|O|3×(|O|-1)。在偏好数据流中有效偏好关系的数量占总数量一定比例,才能判定属性之间是否可能存在父子系。公式(5)和公式(6)可分别表示为:
(5)
(6)
公式(5)、(6)中设置一个用户自定义的阈值α来约束存在父子关系的可能性。阈值α的取值根据窗口数据流的大小、偏好数据量以及用户对偏好关系的精确度确定。
举例说明:假设属性A与B取值分别是(a1,a2),(b1,b2),产生22×(22-1)=12对偏好关系。理论上有效的偏好关系有|2|3×(|2|-1)=8对。实际数据中有效偏好的关系随着数据的改变而改变。
定理1中假设S1>α(或者S2>α)成立,说明vn,vm可能存在偏好关系vn≻vm,(或者有偏好关系vm≻vn)即Pa(vn)=vm(Pa(vm)=vn)成立,S(vn|vm)≤α说明vm,vn不可能存在偏好关系vn≻vm(或者偏好关系vm≻vn),即Pa(vm)≠vn(Pa(vn)≠vm)。如果公式(5)、(6)同时成立则比较S1与S2的取值大小,如果S1>S2≥α,则vn≻vm关系成立存在最大可能性,否则vm≻vn。
定理2如果满足定理1即说明两属性之间可能存在一种偏好关系,确立了子属性的待定父亲属性,待定父亲属性的不同取值对于子属性取值偏好关系产生的影响大体一致,这里设计一个自定义的阈值β来容纳父属性对子属性的影响存在一定偏差。阈值变量β可以根据用户对于属性依赖度的需求自行定义。该定理的公式(7)、 (8)可分别表示为:
(7)
(8)
公式(7)、(8)能够进一步确定偏好关系,确定定理1中筛选出的父子关系是否成立。
进一步考虑vn的不同取值对vm取值的偏好关系产生的影响在允许偏差内一致,当定理1满足表达式S1>α,S1>S2≥α,定理2满足表达式N1=1±β时属性vn与属性vm之间存在偏好关系vn≻vm,vn=pa(vm)成立;同理,当定理1满足表达式S2>α,S2>S1≥α,定理2满足表达式N2=1±β时属性vn与属性vm之间存在偏好关系vm≻vn,vm=pa(vn)成立。
基于以上定理分析,可以得到算法1所示的伪代码和图3所示的算法流程图。
算法1 基于滑动窗口的CP-nets增量式学习算法
输入TDS(偏好事务序列), 阈值α, 阈值β
输出a CP-net
TransSW= null;
/* TransSW 由m个TDS 组成*/
repeat:
for each incoming transactionTiinTransSW
dobit-sequence(x)
ifbit-sequence(x)≠0, then
doSub(xi)
for
ifS(vn|vm)≥α, then
ifS*(vn|vm)=1±βthen
draw the dependenciesvn≻vmin existence
else error
end if
elseS(vm|vn)≥α,then
ifS*(vn|vm)=1±βthen
draw the dependenciesvm≻vnin existence
else error
end if
end if
end for
end for

图3 增量式算法流程图
算法1的计算复杂度首先从扫描数据库进行单个比较数据时算起,单个比较数据的属性个数为n,这时的算法复杂度为O(n),一对属性之间依赖程度的计算复杂性为O(n2)。计算一个偏好事务序列的长度为w,所以计算每个事务的计算复杂度是O(n2)w,每滑动窗口的长度为T=m, 所以计算每个窗口中数据偏好的计算复杂度是O(n2)wm。
定理3定理1中的S(vn,vm)表示父属性对子属性的影响度,Min(S(vn,vm))表示影响度最小的两属性之间的边E(vn,vm)。
为了满足CP-nets的一致性,CP-nets结构中不允许环的存在,在一个CP-net中每个属性都至少有一个父属性的存在则说明该CP-net是有环CP-net,即存在环的CPT结构中不存在边入度(V-in-degree)为0的属性。根据定理3,设计算法Dedge(C,C')进行去环。如果C不存在边入度为0的属性节点,则说明C存在环路;若C中存在边入度为0的属性节点vi,在其副本C'中删除当前节点以及与其相连的边,并重新更新节点的边入度值后删除新的边入度为0 的节点。如果所有节点都被删除则说明C中不存在环,如果存在未被删除的节点则说明C中存在环,删除定理3中影响度最小的两属性之间的有向边E(vn,vm),重新进行Dedge(C,C')算法直至结构C不存在环。至此,给出算法2的伪代码详见如下。
算法2 无环CP-nets结构学习算法
输入增量式学习得到的CP-netC
输出最优CP-net
Dedge(C,C')
/* C'表示记录结构学习的副本*/
while(existenceV-in-degree=0) do
for eachvi⊂C
Ifvi-in-degree=0
Deletevi,edgevi->vi,
C'←new in-degree table; /*将新的边入度信息更新到副本C'*/
end if
end for
end while
ifC' !=null
deleteMin(S(vn,vm))edgefromC;
Dedge(C,C')
end if
ifC'=null
returnC
end if
4.2 算法举例
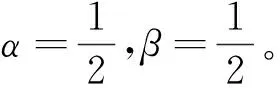

图4 属性A, B的偏好网络结构图

在得到滑动窗口TransSW1中属性A与属性B的依赖关系后,根据表1偏好数据库表分别求属性B与属性C,属性A与属性C之间的偏好关系。属性B与属性C偏好关系最后的位序列表,即TransSW1中得到的sup(≻(Dom(B)×Dom(C)))计数如下:
根据定理可得属性B与属性C之间存在偏好关系B≻C。属性A与属性C偏好关系最后的位序列表,即TransSW1中得到的sup(≻(Dom(A)×Dom(B)))计数如下:
sup(a1c1≻a2c1)=1
sup(a2c2≻a1c2)=1
根据定理可得属性A与属性C的关系为C≻A即Pa(A)=C。 属性之间的偏好关系是A≻B≻C≻A,每个属性的入度都不为0,Min(S(A,C))=2,所以删除edge(A,C)。根据表1的偏好数据库表可得属性A,B,C的偏好网络结构图如图5所示。

图5 属性A, B, C的偏好网络结构图
5 实验与结果
5.1 数据来源
本文在 Matlab上进行实验测试,实验数据分别是合成的随机数据集和真实数据集。对合成的随机数据集进行测试的目的是评估算法处理大数据的能力,对真实数据集进行测试是为了评估算法在真实数据集上的可应用性。其中真实数据集来自于Kamishima收集的寿司数据集[21]。
5.2 实验结果分析
本文在合成数据集上的测试目的是将CP-nets增量式学习与CP-nets传统学习[14-15]的运行时间进行对比。合成数据集包含用户的4 500对偏好关系,其中数据集包含30个属性。分别将随机用户U1,U2做CP-nets增量式学习与CP-nets传统学习[14-15]运行时间的平均值进行对比。
图6中水平轴表示成对属性比较的次数,垂直轴表示用户U1,U2运行时间的平均值。 图6(a)是用户输入15个属性的200对偏好数据时CP-nets增量式学习与CP-nets传统学习[14-15]运行时间的平均值进行对比;图6(b)是用户输入15个属性的4 500对偏好数据时CP-nets增量式学习与CP-nets传统学习[14-15]运行时间的平均值进行对比;图6(c)是用户输入30个属性的4 500对偏好数据时CP-net增量式学习与CP-net传统学习[14-15]运行时间的平均值进行对比。实验结果表示本文提出的CP-nets增量式学习算法在运行时间上少于CP-net传统学习的运行时间。
在真实数据集的测试目的是将CP-nets增量式学习与CP-nets传统学习[14-15]的运行结果和运行时间进行对比。研究考虑2个随机用户U1,U2与寿司选择相关的偏好数据集[21],寿司的5个属性分别表示为A1,A2,A3,A4,A5。文中分别求了用户U1,U2以每次20对偏好数据增量从100对数据增加到200对数据的偏好网络结构图。

(a) 对比结果1 (b) 对比结果2 (c) 对比结果3
图7表示CP-nets增量式学习算法中用户U1以每次20对偏好数据增量从100对数据增加到200对数据得到的偏好网络结构图。用户U1在数据增加的每个阶段得到偏好网络结构图不同,该结果表明偏好数据增量会对用户的CP-nets、即用户偏好产生影响。图8表示的是传统学习CP-nets算法中用户U1以每次20对偏好数据增量从100对数据增加到200对数据得到的偏好网络结构图。对比与图7所得的结果图,图8展示的所有属性偏好包含于图7所示的属性偏好中,该实验结果表示CP-nets增量式学习与CP-nets传统学习得到的偏好结果大体一致,本文提到的增量式学习CP-nets算法得到的偏好关系是准确的。
综上所述,CP-nets增量式学习算法能够得到用户属性的动态性偏好网络结构图,并且得到的属性之间的偏好关系是准确的。
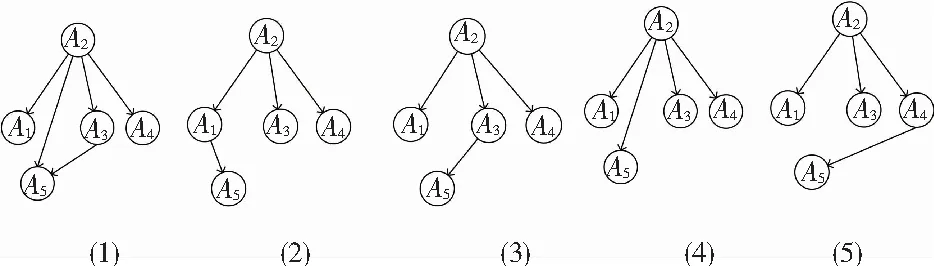
图7 CP-nets增量式学习算法中用户U1的实验结果
Fig. 7 Experimental results of userU1in incremental learning algorithm
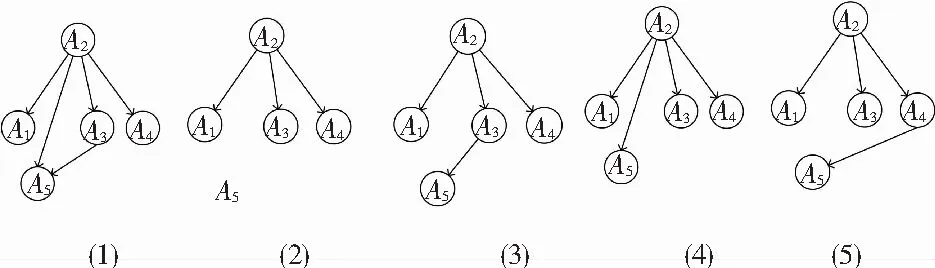
图8 传统学习CP-nets算法中用户U1的实验结果
Fig. 8 Experimental results of userU1in traditional learning algorithm
图8分别表示用户U1,U2以每次20对的增量从100对偏好数据增加到200偏好数据,CP-nets增量式学习与CP-nets传统学习[14-15]在得到某一时刻的CP-nets所用的确定时间进行了比较。图9(a)表示用户U1的增量学习与传统学习运行时间的比较;图9(b)表示用户U2的增量学习与传统学习运行时间的比较。图9中,用户U1,U2做CP-nets增量式学习的运行时间在数据增加过程中大致相同并且耗时随着数据增量的逐渐增加大幅度少于同时刻传统学习CP-nets的运行时间,而CP-nets传统学习的运行时间随着数据增量的增加逐渐呈线性增加。实验表明,本文提出的CP-nets增量式学习方法对于随机用户都是适用且高效的。

(a) 用户U1学习CP-nets确定运行时间变化
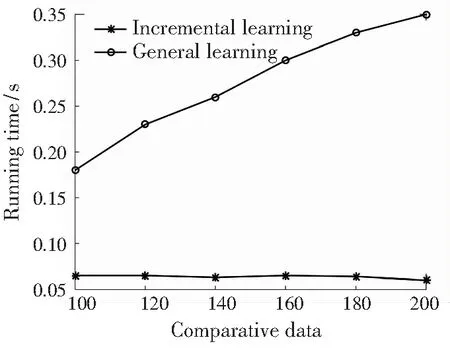
(b) 用户U2学习CP-nets确定运行时间对比
Fig. 9 UserU1,U2learning CP-nets determine runtime comparison
6 结束语
本文主要设计了一种从偏好数据流中学习CP-nets的增量方法。通过在合成数据和真实数据上进行的一系列广泛的实验表明,本文提出的算法可以用于处理大数据集,并且可以输出一个表示对应用户属性偏好依赖关系的无环CP-nets。对于不同时间段的偏好信息,也可以根据增量数据求出特定时刻用户的CP-nets,有效利用偏好信息的即时性价值。同时,实验表明本文的算法相较于其它算法能够得到一个大致相同的CP-nets,并且该算法可以有效地节省存储空间和减少运行时间[22]。
在今后的学习研究中主要有2部分工作。 一方面是,提高CP-nets模型性能的学习方法是进一步研究的主要方向。并计划研究其他分类的CP-nets学习方法。希望能够进一步更准确高效地学习CP-nets模型。后续还考虑将CP-nets模型与模糊集学习相结合,研究模糊条件偏好网络的可行性[23]。另一方面是计划学习比CP-nets更具有拓展性和研究性的TCP-nets[24]和PCP-nets[25]。
