基于氢核磁共振与偏最小二乘法对酸枣仁及其掺伪品的鉴别
2020-04-25申晨曦杜晨晖李震宇李爱平秦雪梅
申晨曦,杜晨晖,李震宇,李爱平,秦雪梅,闫 艳,
(1.山西大学中医药现代研究中心,山西 太原 030006;2.山西中医药大学中药学院,山西 太原 030619)
酸枣仁(Ziziphi spinosae Semen)为鼠李科植物酸枣(Ziziphus jujubaMill. var.spinosa(Bunge) Hu ex H. F.Chou)的干燥成熟种子[1],具有“养心补肝,宁心安神,敛汗,生津”的功效,是中医临床养心安神的首选药物[2]。酸枣仁是国家卫生和计划生育委员会最早颁布的“既是食品又是中药材物质”的中药材之一。由于其采收成本高,临床需求量大,价格不断攀升。市场上利用同科同属植物滇刺枣(Ziziphus mauritianaLam.)的干燥成熟种子——理枣仁(Ziziphi mauritianae Semen)冒充酸枣仁和掺伪现象越来越多。作为酸枣仁最常见的伪品,理枣仁亦“具有宁心安神、除烦敛汗之功效”,作为云南地方习用品,早在1974年已被收入《云南省药品标准》[3]。
近年来,学术界对酸枣仁和理枣仁的鉴别方法也进行了大量研究,如性状鉴别[4]、显微鉴别[5]、理化鉴别[6-8]和DNA分子生物鉴别[9]等方法。以上方法为酸枣仁与理枣仁的真伪鉴别提供了科学基础,但存在一定局限性,如性状鉴别只适用于外观未破损的样品鉴别,显微鉴别需要具有丰富鉴别经验的专业人员进行真伪品的鉴别。然而理枣仁的外观与酸枣仁极相似,不易区别,特别是打粉后或入中成药后,难以区分和鉴定。为避免将廉价的理枣仁混入酸枣仁,以次充好,亟需建立一种快速、灵敏、准确的以理枣仁粉末形式掺伪酸枣仁粉末的鉴别方法。
植物代谢组学是代谢组学的一个重要分支。氢核磁共振(1H nuclear magnetic resonance,1H NMR)是植物代谢组学中常用的研究测试工具[10],具有样品预处理简单,对样品无损害、检测时间短、重复性好等优势。1H NMR代谢组学技术可获得复杂混合体系中高通量的化学成分信息,包括化学位移和信号响应等,但是,同时各种化学成分信号的重叠也使得图谱变得十分复杂,仅靠肉眼观察只能获得有限的数据信息。多元统计分析能够从复杂的数据中最大限度的提取信息,反映样本分组的整体差异性[11],具有很好的应用性。常用的多元统计分析方法包括无监督识别模式的主成分分析(principal component analysis,PCA)、有监督模式的偏最小二乘法-判别分析(partial least squares-discriminant analysis,PLS-DA)和PLS回归分析[12-13]。特别是应用多元统计分析方法建立的数学模型,能从未知样品的1H NMR图谱中预测样品的性质等信息,适合于中药材及饮片掺假的判别。
课题组前期采用1H NMR代谢组学技术对黄芪、款冬等中药材[14-17]进行了质量评价。另有研究采用1H NMR代谢组学技术对茶油、老陈醋、咖啡、蜂蜜和啤酒等食品进行了质量优劣评价[18-28]。本研究利用1H NMR代谢组学技术获得酸枣仁和理枣仁的化学信息,并结合PLS法对酸枣仁粉末掺伪比例进行鉴别研究。首先表征和分析酸枣仁、理枣仁和酸枣仁粉末掺假样品的1H NMR谱图。然后利用PLS对谱图的分段积分数据矩阵进行分析,建立酸枣仁粉末掺伪定量模型,进而对模型进行检验。最后,通过PLS模型预测未知样本的掺伪比例。该方法从整体的角度出发,以1H NMR结合多元统计分析应用于酸枣仁粉末掺伪的鉴别工作中,旨在为酸枣仁的定性分析提供一种新的思路,同时也为酸枣仁及以酸枣仁粉末入药的保健食品的质量评价提供一条新途径。
1 材料与方法
1.1 材料与试剂
酸枣仁和理枣仁分别采购于河北安国药材市场、昆明菊花村药材市场和山西振东道地药材有限公司,经山西中医药大学杜晨晖副教授鉴定酸枣仁为Z. jujubavar.spinosa的干燥成熟种子,理枣仁为Z. mauritianaLam.的干燥成熟种子。共收集50 批样品,酸枣仁(25 批)和理枣仁(25 批),样品保存于山西大学中医药现代研究中心。
重水 美国Norell公司;氘代甲醇、三甲基硅烷丙酸钠盐 青岛腾龙微波科技有限公司;氘代氢氧化钠瑞士Armar公司。
1.2 仪器与设备
600 MHz Avance III1H NMR 瑞士Bruker公司;Neofuge 13R高速冷冻离心机 上海力申科学仪器有限公司;RE-52A旋转蒸发仪 上海亚荣生化仪器厂;pH计 奥豪斯仪器有限公司。
1.3 方法
1.3.1 样品制备
25 批酸枣仁样品(酸枣仁1~25)各称取50 g,分别粉碎,过3号筛(50 目),即得25 批酸枣仁粉末样品。25 批理枣仁样品(理枣仁1~25)各称取50 g,分别粉碎,过3号筛,即得25 批理枣仁粉末样品。从25 批酸枣仁粉末样品中随机选取6 批,并从25 批理枣仁粉末样品中随机选取6 批。将所选酸枣仁粉末(n=6)中分别掺入不同质量比(5%、10%、20%、40%、60%、80%)的理枣仁粉末(n=6),共36 个掺伪样品,样品信息见表1。

表 1 实验样品信息Table 1 Information about pure and mixed samples of ZSS and ZMS tested in this study
精密称取以上粉末样品各200 mg,置于10 mL离心管中,分别加蒸馏水及甲醇各1.5 mL,氯仿3 mL;旋涡混匀1 min;超声提取25 min;3 500 r/min离心25 min,上层为甲醇水相(水溶性部分),下层为氯仿相;将甲醇水层移至25 mL圆底烧瓶中,减压浓缩至干,氯仿层弃去。测定前用氘代甲醇400 μL与含有缓冲盐的重水(KH2PO4溶于氘代水中,以1 mol/L氘代氢氧化钠溶液调节pH值至6,含0.01%磷酸三钠(trisodium phosphate,TSP))400 μL进行溶解,移至1.5 mL离心管中,离心10 min(13 000 r/min),移取上清液600 μL于5 mm核磁管中,待测。
1.3.2 样品1H NMR测试条件
样品在25 ℃、600 MHz1H NMR上测定,测定频率600.13 MHz,扫描范围为δ-5~15,扫描次数64 scans,采用Noesygppr1d序列压制水峰,用氘代甲醇进行锁场,内标为TSP。
1.3.3 数据处理
将测得的各样品自由衰减信号导入MestReNova(version 8.0.1, Mestrelab Research, Santiago de Compostlla,Spain)软件并将图谱以TSP(0.00)定标,进行相位调整和基线校正。然后以0.01分段对化学位移区间δ0.72~9.15进行分段积分,其中对水峰区域δ4.68~4.92和残余甲醇峰δ3.34~3.38不进行积分,积分数据采用峰面积归一化处理。
1.3.4 精密度实验和重复性实验
取编号为酸枣仁1样品,按照1.3.1节方法制备样品,并按照1.3.2节方法连续测定6 次,将6 次所测图谱分别按照1.3.3节方法进行数据处理,得到6 组积分面积数据,依据夹角余弦法,采用夹角余弦公式,计算6 张谱图之间的夹角余弦值,考察仪器的精密度。取编号为酸枣仁1样品粉末,按照1.3.1节方法平行制备6 份样品,并按照1.3.2节下方法测定,将6 个所测图谱分别按照1.3.3节方法进行数据处理,得到6 组积分面积数据,计算6 份样品之间的夹角余弦值,考察制备方法的精密度[29]。夹角余弦值(cosθ)计算公式如下:
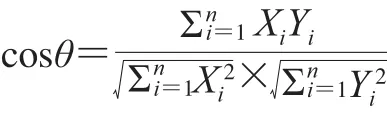
式中:Xi为样品X的第i个峰的相对积分值;Yi为样品Y的第i个峰的相对积分值。1.3.5 多元统计分析
1.3.5.1 PCA和PLS-DA
将归一化后的数据导入SIMCA-P 13.0(Umetrics,瑞典)软件进行PCA和PLS-DA。PCA不能忽略组内误差和消除无关的随机误差,因此需要进一步采用有监督的PLS-DA,减小组内差异,扩大组间差异,以实现酸枣仁及其伪品的准确鉴别。
1.3.5.2 PLS预测模型的构建
在收集的样品中随机选取其中20 批酸枣仁(酸枣仁1、酸枣仁3~21)、21 批理枣仁(理枣仁1~21)及24 批掺伪样品(掺伪1~4、掺伪7~10、掺伪13~16、掺伪19~22、掺伪25~28、掺伪31~34)构成训练集,共65 组强度积分值数据;余下的4 批酸枣仁(酸枣仁22~25)、4 批理枣仁(理枣仁22~25)和12 批酸枣仁掺伪样品(掺伪5~6、掺伪11~12、掺伪17~18、掺伪23~24、掺伪29~30、掺伪35~36)组成测试集,共20 组强度积分值数据。
基于PLS原理[20],按照样本类别特征赋予训练集样本分类变量值,作为因变量(Y变量)。首先将酸枣仁赋值为1,掺伪5%理枣仁赋值1.05,掺伪10%理枣仁赋值1.1,掺伪20%理枣仁赋值1.2,掺伪40%理枣仁赋值1.4,掺伪60%理枣仁赋值1.6,掺伪80%理枣仁赋值1.8,理枣仁赋值为2。然后将训练集数据导入SIMCA-P 13.0软件中,采用pareto(帕雷托)换算对训练集65 个积分强度值数据矩阵进行标准化,归一化的强度积分值作为自变量(X变量)。采用PLS法将标准化的数据矩阵X变量与类别变量(Y变量)进行线性回归,建立预测模型。
将测试集样品的数据代入经过检验的模型,计算得到各样品的类别变量预测值P,并将预测值与训练集得出的鉴别范围比对,对测试集样品进行鉴别。
2 结果与分析
2.1 仪器精密度与方法精密度实验
图1A为同一样品连续测定6 次所得图谱,按照1.3.3节方法进行数据处理,得到6 组积分面积数据,计算6 张谱图之间的夹角余弦值分别为1.000、0.997、0.999、0.998、0.998、0.997,计算值均在0.99以上,表明仪器精密度良好。图1B为相同条件下同一批次酸枣仁平行制备6 份实验所得图谱,按照1.3.3节方法进行图谱处理,得到6 组积分面积数据,计算6 份样品之间的夹角余弦值分别为1.000、0.998、0.998、0.993、0.998、0.999,计算值均在0.99以上,表明制备方法精密度良好。这为定性鉴别酸枣仁和理枣仁提供了稳定可靠的分析条件。
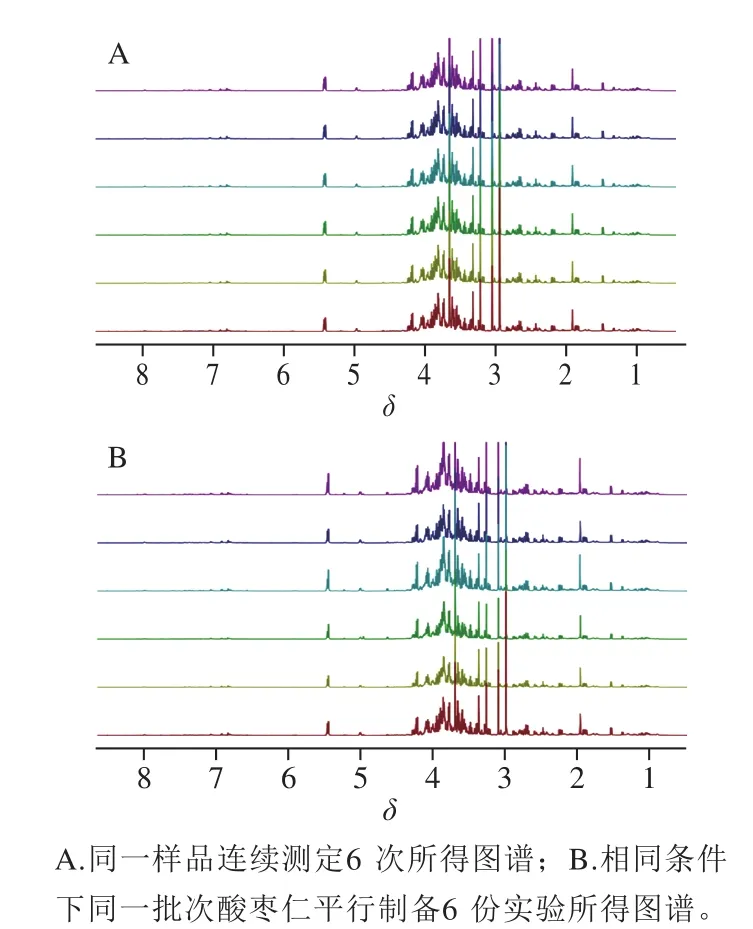
图 1 仪器精密度实验和重复性实验1H NMR谱图Fig. 1 1H NMR spectra showing instrumental precision and repeatability
2.2 1H NMR图谱分析
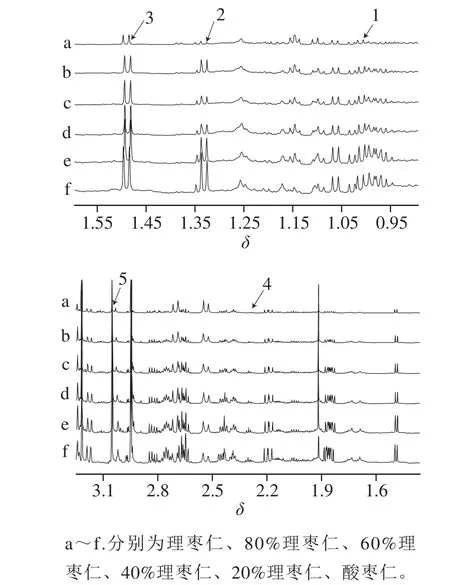
图 2 酸枣仁、掺伪样品及理枣仁1H NMR(δ 0~3)谱图Fig. 2 1H NMR (δ 0–3) spectra of ZSS, ZMS and their mixtures
由图1可知,酸枣仁样品的1H NMR谱图,大致可以分为脂肪区(δ0.00~3.00)、糖类化合物区(δ3.00~6.00)和芳香区(δ6.00~9.00)。通过比较酸枣仁、理枣仁及酸枣仁粉掺伪样品的1H NMR谱图,脂肪区出现变化较大的信号。通过对化学位移、耦合常数J、HMDB数据库和文献数据以及1H-1H化学位移相关谱的分析,鉴定出5 个变化较为明显的物质[30]。分别为化合物1缬氨酸(δ=1.01,d,J=7.2 Hz;δ=1.07,d,J=7.2 Hz)、化合物2乳酸(δ=1.33,d,J=6.6 Hz)、化合物3丙氨酸(δ=1.49,d,J=7.2 Hz)、化合物4γ-氨基丁酸(δ=2.31,t,J=7.2 Hz)、化合物5半胱氨酸(δ=3.05,s)。随着酸枣仁粉掺伪比例的增加,观察到5 个特征峰的信号强度逐渐减弱(图2)。表明酸枣仁粉末较伪品含有更高的氨基酸类成分。
2.3 酸枣仁粉及掺伪品的PCA
在进行PCA之前,通过Hotelling’sT2Range算法判断异常样本。当T2超过临界值时,说明该样本与其他样本间存在较大的差异。如图3所示,样品中存在一个异常值(酸枣仁2),应作为异常点剔除,剩余85 个样品用于下一步的模型建立。
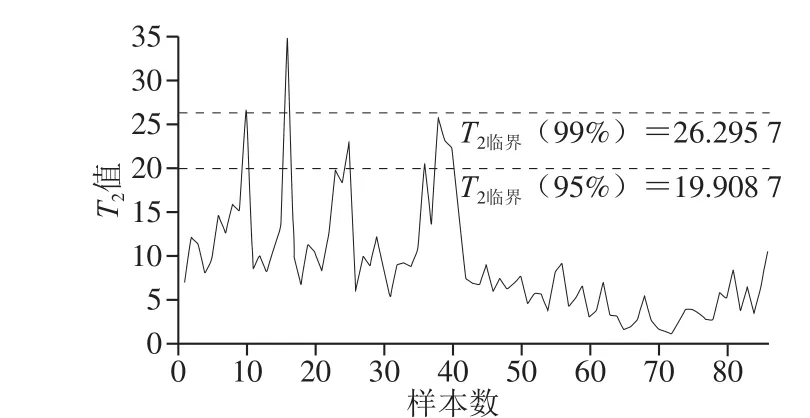
图 3 酸枣仁粉及掺伪样品的Hotelling’s T2 Range图Fig. 3 Hotelling’s T2 Range plots of pure and adulterated samples

图 4 剔除异常点后酸枣仁粉及掺伪样品的PCA得分图Fig. 4 PCA score plot for pure and adulterated samples after elimination of outliers
从图4可知,酸枣仁粉和掺伪样品的分类情况。前5 个主成分共解释了72.4%的方差,酸枣仁和掺伪样品在t[2]轴上有较好区分。大部分酸枣仁样品在t[2]轴的下部,大部分掺伪样品在t[2]轴的上部,由于化学成分的相似性,掺伪比例较低的样品与酸枣仁有部分的重叠,随着掺伪比例的增加,样品的分布在t[1]轴上呈从右到左的分布。
2.4 酸枣仁粉及掺伪品PLS-DA
无监督模式识别的PCA无法判断未知样品,且存在与研究目的无关的组内误差以及随机误差,不利于分组信息的准确性。为确定分组样品的差异,进一步采用有监督模式识别的PLS-DA。其分析过程中可以消除众多化学信息中相互重叠的部分,使得分析数据更加准确可靠[26]。
为准确识别掺伪样品,首先将25 个理枣仁样品和36 个掺伪样品归为一类,酸枣仁作为另一类,建立PLSDA模型。如图5A~C所示,当掺伪比例分别为5%、10%和20%时,酸枣仁粉和掺伪品有部分交叉。当掺伪比例不低于40%时(图5D),酸枣仁粉和掺伪品在t[1]轴上可以完全分开。随着掺伪比例的增加,酸枣仁样品所在区域和掺伪品所在区域间的距离逐渐增加(图5E~G)。为进一步验证该模型的可靠性,采用排列实验法对图5D中对应的PLS-DA模型进行验证。通过200 次随机改变类别变量Y的排列顺序,得到累计贡献率R2和预测能力Q2。其中排列实验模型的R2回归线和Q2回归线与纵轴的截距分别为0.474和-0.483,最右端鉴别模型的原始Q2值大于左边任何一个Y变量随机排列模型的Q2值(图6),说明所构建的PLS-DA模型没有出现过拟合现象,且有较好预测能力,显示模型可靠。

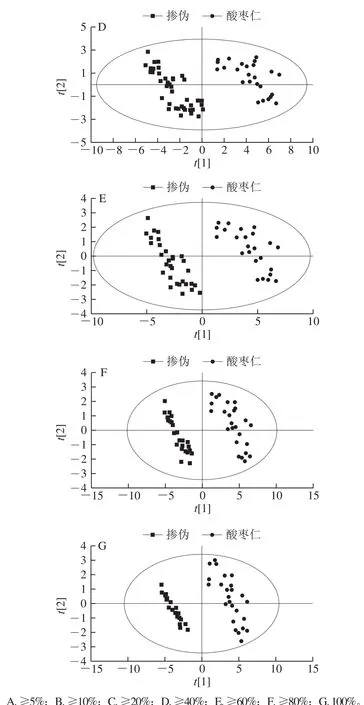
图 5 酸枣仁和不同比例掺伪品的PLS-DA图Fig. 5 Score plots of PLS-DA for pure ZSS and adulterated samples
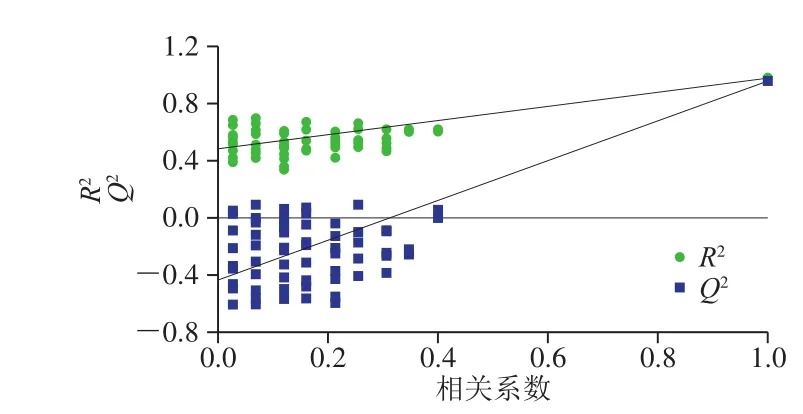
图 6 排列实验对PLS-DA模型的可靠性验证Fig. 6 Validation of PLS-DA model by permutation test
2.5 基于PLS的酸枣仁粉及掺伪品的定量分析
为更准确地检测实际掺伪比例,进一步采用PLS法,建立掺假量预测回归模型。训练集均方根误差(root mean square error of estimation,RMSEE)、预测集均方根误差(root mean square error of prediction,RMSEP)和训练集相关系数(R2)可以评价PLS模型,R2越大,RMSEE和RMSEP越小,说明模型的准确性和精确度越高。本研究训练集由65 个样品构成(酸枣仁样品20 个、理枣仁样品21 个,掺伪样品24 个),共获得802 个强度积分变量,构成65×802的数据矩阵。利用PLS对其进行分析,建立模型。以训练集的真实值为横坐标,预测值为纵坐标,绘制的散点图(图7)。训练集模型中R2为0.986 5,大于0.98,RMSEE为0.077 0。利用PLS预测模型对训练集的类别变量进行计算。由表2可知,酸枣仁粉的计算值范围为0.86≤P≤1.15;掺伪5%理枣仁的预测值范围为1.00≤P≤1.18;掺伪10%理枣仁的预测值范围为1.06≤P≤1.18;掺伪20%理枣仁的预测值范围为1.15≤P≤1.33;掺伪40%理枣仁的预测值为1.39≤P≤1.47;掺伪60%理枣仁的预测值为1.51≤P≤1.69;掺伪80%理枣仁的预测值范围为1.68≤P≤1.75,理枣仁粉的计算值范围为1.93≤P≤2.07。
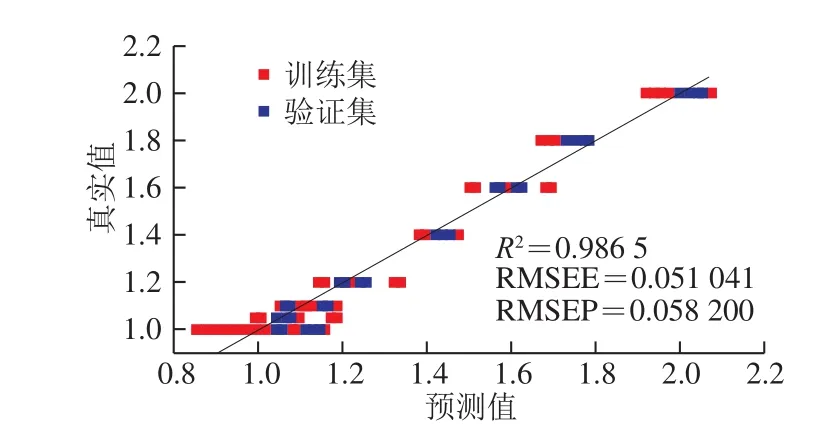
图 7 训练集和验证集真实值和预测值关系图Fig. 7 Plot of true values versus estimated values for training set and validation set
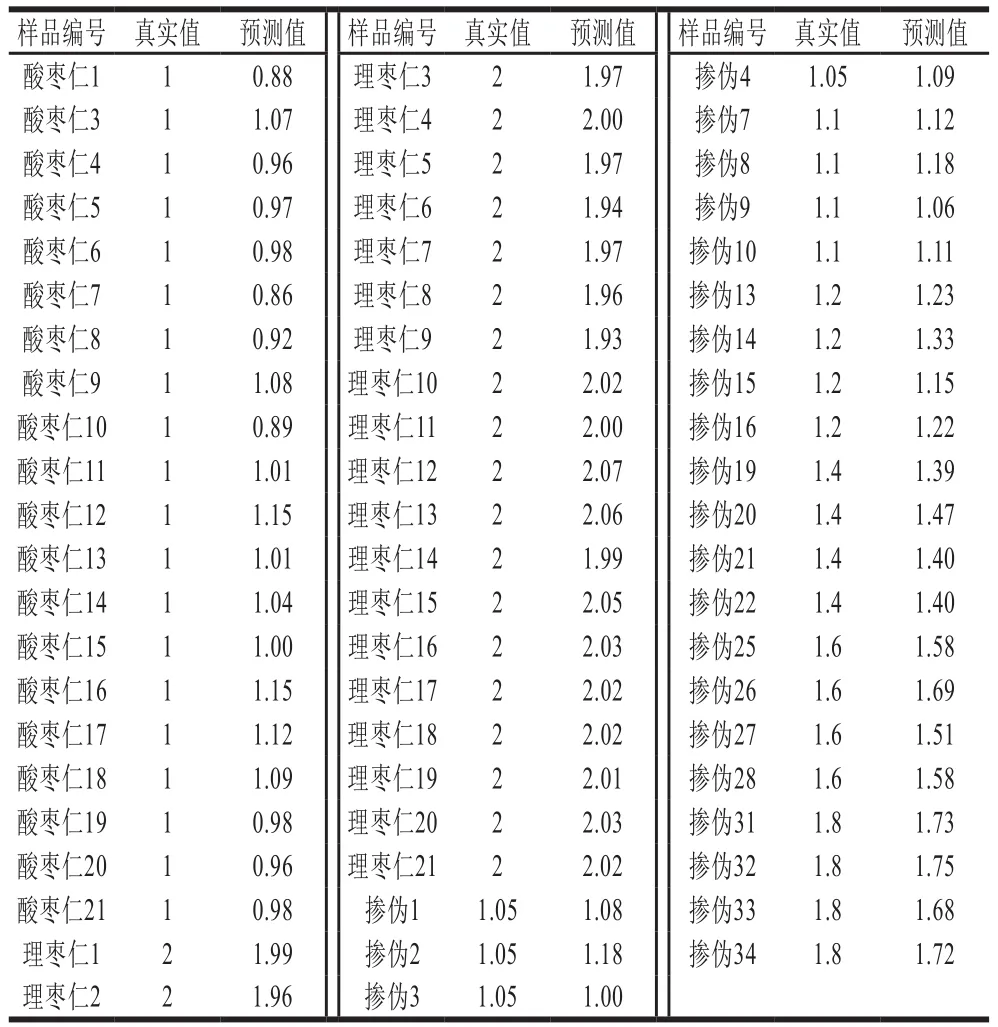
表 2 训练集的真实值和预测值Table 2 True values and estimated values for training set samples
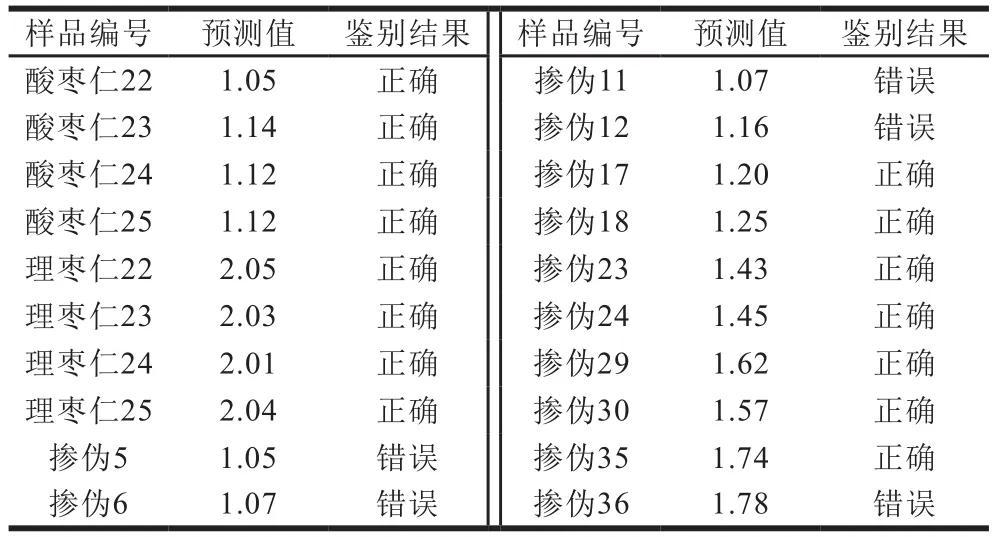
表 3 测试集的真实值和预测值Table 3 True values and estimated values for validation set samples
为进一步检验PLS模型,将酸枣仁粉及不同比例掺伪品的测试集样品代入训练集创建的PLS模型中(图7),预测结果见表3。测试集RMSEP为0.058 200。RMSEE和RMSEP值均接近于0,说明模型可靠,可准确预测掺假理枣仁的量。测试集的预测结果P值表明,酸枣仁粉掺伪5%和10%时,与酸枣仁粉预测值有交叉,无法准确预测其含量。当掺伪比例达到20%时,样品计算所得P值除掺伪36号样品稍有偏差其余样本的P值均在在所建立模型的P值范围之内。说明该模型具有较好的预测和评价未知样品掺伪量的能力。掺伪36号样品为掺伪80%,与模型中的P值较为接近。
3 结 论
本研究利用1H NMR代谢组学技术获得了酸枣仁粉及不同比例掺伪品的化学信息。直观分析显示缬氨酸、乳酸、丙氨酸、γ-氨基丁酸、半胱氨酸5 个氨基酸成分随着掺伪比例的增加表现出信号强度逐渐减弱的趋势。PCA表明掺伪比例较低的样品与酸枣仁有部分的重叠。PLS-DA显示,当掺伪比例不低于40%时,酸枣仁粉和掺伪品沿t[1]轴完全分开。在此基础上,通过PLS模型可准确预测掺假酸枣仁粉中理枣仁的掺入量。1H NMR结合PLS-DA和PLS可以预测酸枣仁粉掺假量,具有分析时间短、可控性强、准确性高等优点,可实现未知样本的准确判别,对于酸枣仁和理枣仁的鉴别及掺伪区分有明显优势。该方法特别适合于性状鉴别和薄层色谱等方法难以实现的酸枣仁药材真伪鉴别。在后续研究中,应增加样本量,对本鉴别模型数据扩充,使鉴别结果具有代表性,为酸枣仁及含酸枣仁的复方制剂质量评价提供一种新方法和新途径。
