基于对抗网络的验证码识别方法
2020-04-24曹廷荣龚燕红贾惠珍
曹廷荣,陆 玲,龚燕红,贾惠珍
1.东华理工大学 信息工程学院,南昌330013
2.南昌大学 信息工程学院,南昌330031
1 绪论
验证码是为防止计算机恶意注册、刷票和论坛灌水的一种自动响应程序,在2003年由Ahn等[1]提出后一直被广泛使用。文本验证码由多个随机产生的字符组生成。为了增加识别难度通常会使字符扭曲、形变并且加入干扰噪声。现阶段虽然有很多文本验证码替代方案,但许多网站和应用程序仍然使用其作为安全和身份验证的主要手段。
验证码从出现开始,人们对其识别和破解从未停止。目前已经提出了很多识别方法。对于文本型验证码的识别主要步骤如下:首先,通过二值化、空间滤波、变换等图像处理技术去除验证码中的干扰信息。其次,使用投影、类聚或目标检测等方法确定字符在图像中的位置并进行分割。最后,利用SVM、KNN或卷积神经网络等算法提取字符特征并进行分类识别[2-6]。王专等[7]提出先使用中值滤波去除图像中的噪点,并使用门限算法进行二值化。再通过分析图像二值化矩阵算出验证码的平均宽度,最后利用宽度对验证码进行分割的方法。王璐[8]提出了基于局部极小值和最小投影值的分割法和K-means聚类与竖直投影结合的分割方法。汪洋等[9]提出先使用RGB 三原色去噪法,再采用轮廓差投影法与水滴算法相结合的分割方法。最后利用KNN算法进行识别。研究表明,只要能准确地分割图像中的字符,利用深度神经网络技术就能识别出字符本身。但是文本验证码的安全性也不断提高,新引入的安全特性使得许多传统的识别方法不再适用。对于扭曲、粘贴的验证码这种现象更加明显。
针对文本验证码中字符粘贴、扭曲、干扰信息难以去除、识别准确率低等问题,本文提出一种基于对抗学习[10]的验证码识别方法。对抗训练学习网络在很多方面取得了很好的效果。刘昱等[11]利用对抗训练网络对面部图像进行修复。Wang Z等[12]利用对抗性网络在智能诊断方案及其在行星齿轮箱故障模式识别中的应用。本文中,在预处理阶段利用一个神经网络模型去除干扰信息[13],然后利用对抗训练方法训练一对神经网络模型,即分割网络和识别网络。分割网络对验证码进行分割,同时筛选出分割困难的验证码,识别网络用于识别。通过实验表明该方法适用于各种文本型验证码。与现有方法相比本文使用的方法有以下优势:(1)利用预处理模型去除文本验证码的干扰信息,该方法具有通用性。不同形状的验证码只需重新训练模型而不需重写代码,甚至参数都可以不变。(2)在对抗训练阶段本文引入一个分割网络和一个识别网络,解决验证码在分割过程中因信息丢失而导致识别率不高的问题,同时在训练过程中分割网络会筛选出分割困难的验证码。识别网络也针对这些验证码进行训练。
2 对抗训练网络简介
文本型验证码识别通常需要预处理、字符切割、字符特征提取和识别。这个过程中,预处理一般先进行灰度化,然后经过卷积和滤波等处理,最后再进行二值化等。但是,不同的图片使用的卷积大小不同,二值化阈值也不同。
文中提出的文本验证码识别方法是基于最近提出的GAN架构。GAN模型由生成式模型(Generative model)和判别式模型(Discriminative model)组成。生成模型G 捕捉样本数据的分布,用服从某一分布(均匀分布、高斯分布等)的噪声z 生成一个类似真实训练数据的样本,其效果是生成的图像越接近真实样本越好;判别模型D 是一个二分类器,用于估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。GANs在图像和自然语言处理方面都展示出令人印象深刻的结果。因此,本文利用GANs 为基础,提出通用的文本验证码识别解决方案。
本文使用一个相对灵活并且通用的识别方法。该方法流程如图1 所示。先利用网络爬虫或验证码生成程序获取一定数量的验证码,然后用预处理模型对验证码进行预处理,接着将预处理后的验证码放入神经网络训练识别。最后得到结果。

图1 验证码识别流程图
3 对抗训练网络实现步骤
3.1 预处理
为提高文本型验证码的安全性,通常会在验证码中加入干扰信息。对验证码识别时,如果不去除干扰信息就无法突出验证码的文本字符特征,从而影响验证码识别的准确率。验证码预处理就是去除验证码的干扰信息并且最大可能保留文本字符特征。验证码可以看作是由文本字符和带有噪声及干扰线的背景图片通过一系列的变换而来。如图2所示。

图2 验证码合成图
图中验证码C 是由左边的A 和B 两个图片而得的。图像C 到图像A 的过程称为去噪或者“翻译”。本文验证码预处理使用的Pix2pix神经网络模型是一种完全监督的方法,即利用完全配对的输入图像C 和输出图像A 训练模型,通过训练好的模型将输入的图像C 生成指定任务的目标图像A。目前该方法是图像翻译任务中完全监督方法里面效果和通用性最好的一个模型。
Pix2pix是一种GAN对抗神经网络,它由一个生成网络和一个识别网络组成。Pix2pix的网络结构如图3所示。
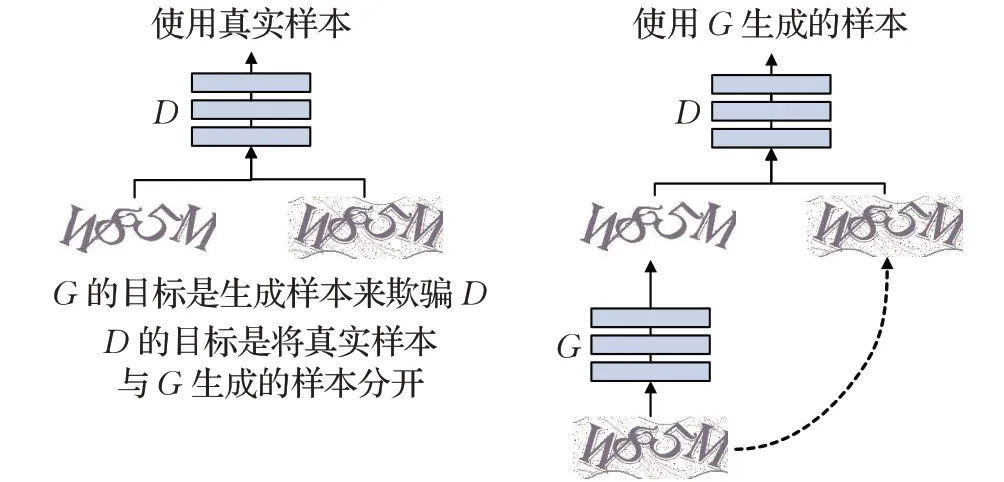
图3 预处理模型结构
对于生成器G 的输入是一个Y 类图像y,输出为生成的图像G(y)。判别器D 的输入为一个X 类的图像x和一个Y 类图像y。D 需要判断x 图像是否是真正的y 对应的图像,并输出一个概率。设(x,y)是一对真实的图像,G 生成的图像G(y)就应该很接近真实的图像x。
Pix2pix是一种条件神经网络(Conditional Generative Adversarial Networks)。它除了具有cGAN[15]一样的损失函数LcGAN外,还在生成图像和真实图像之间加上了L1损失函数。记y 为输入的图像,x 为真实图像(输出图像),G 为生成器,D 为判别器,则标准的GAN 网络的损失函数为:

对G 施加惩罚,即:

因此,最终GAN网络的损失函数为:

这样一来,标准的GAN 损失负责捕捉图像高频特征,而损失则负责捕捉低频特征,使得生成结果既真实且清晰。
3.2 对抗训练/识别
在对抗训练/识别阶段,文中设计了两个网络:分割网络和识别网络。其中分割网络主要负责对验证码进行切分,而识别网络则进行分类识别,两者相互联系。分割网络的好坏直接决定识别的网络准确率的高低。同时,识别网络的准确率也反映分割网络的质量。因此,在训练时不是对两个网络分别训练,而是进行对抗训练。通过对两个网络同时训练能有效解决网络性能评估问题。特别是分割网络,尽管其分割结果与实际位置有一定差距,只要能正确识别出来都可以认为是有效的。
对抗训练的流程如图4所示。首先,将预处理后的文本验证码使用平均法分割法分割后放入识别网络。识别网络经过训练后得到准确率和Loss值。其次,根据准确率和Loss 值对切割的性能和难易程度进行评估。接着训练分割网络调整验证码分割的位置,再放入识别网络进行训练。如此反复,分割网络就能学会切分验证码,同时选出难以分割的验证码。识别网络也会在这个过程中学会识别验证码。

图4 对抗训练流程图
3.2.1 分割网络
在分割网络中本文参考了在姿态识别中常用的UNet 网络[16],U-Net 是一个端到端的网络模型,它是一种编码器-解码器结构。编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接。因此,它能帮助解码器更好地修复目标的细节。在进行Pooling 的时候采用Maxpooling并且保留了位置信息,使得在进行上采样的时候能够还原其位置信息。
本文中图形验证码是一个条形如图5 所示,在切割调整的时候由原来的图5(a)中的a,b 范围调整到图5(b)中所示的A,B,调整的范围只是在x 反向进行变化,在y 方向上不发生变化,因此为了避免很多无效的计算,本文借鉴了U-Net 网络的思想,使用了一种类U-Net网络。网络结构原理如图6所示。

图5 字符分割范围调整情况

图6 U-Net网络结构图
通过对识别网络和分割网络的联合训练,识别网络不仅保留了传统切割方法的识别率,而且通过分割网络对抗学习也使性能得到提高。
3.2.2 识别网络
这里采用一个多尺寸通道图像输入方法[17]。图7(a)所示,假设a,b 分别是验证码中字母E的位置,本文中将{a-δ,b+δ},{a,b+δ},{a-δ,b},{a,b}四个部分的内容作为网络的输入,识别网络的设计思想如图7(b)所示:第一行为卷积路,由三个核尺度不同的卷积层(白色)串联而成,间插有Batch Normalization(浅蓝)和ReLU(浅紫);第二行为跳级路,只包含一个核尺度为1的卷积层;如果跳级路的输入输出通道数相同,则这一路为单位映射。所有卷积层的步长为1,padding为1,不改变数据尺寸,只对数据深度(channel)进行变更。整个模块由两个参数控制:输入深度M 和输出深度N 。可以对任意尺寸图像操作。这样的设计很好地解决了验证码切割过程中信息丢失的问题,最大可能地保留验证码信息,从而提高识别准确率。

图7 字符分割及识别网络残差模块图
在深度学习训练中为了增强模型的泛化性通常会使用数据增强和正则化方法(如dropout、BN)。一般的数据增强方法有:随机裁剪、水平翻转、平移、旋转、增加噪音等。其中前两个方法用得最多,也最有效。Zhong Z等[18]提出了很简单且实用的无参数数据增强方法即随机遮挡。该方法被证明在多个CNN架构和不同领域中都可以提升模型的性能,并且与随机裁剪、水平翻转(还有正则化方法)具有一定的互补性。因此,本文中引入该方法能有效解决验证码中的字符在预处理和分割过程中局部信息丢失问题,具有更好的鲁棒性。在实验中本文参考了Devries T 等[19]提出的方法,随机遮挡不是直接作用于原始输入验证码字符图像,而是作用于feature map 层上。通过在训练过程中对深度特征进行随机遮挡。相当于建立每个因子特征与相应类别的权重关系,减弱背景(或噪音)因子的权重,可以产生更好的学习效果,增加识别网络的稳定性。
3.2.3 联合训练
联合训练分割网络和识别网络是一个很关键也比较复杂的过程。为了能够保证网络的正常进行,文中引入一个奖赏机制,即分割网络的预测是根据识别网络的状态进行更新的。首先,利用平均分割的方法将文本验证码放入识别网络进行训练得到一个模型A。然后,训练分割网络调整分割的位置,并利用模型A 来验证。同时更新分割信息。第二轮训练的时候,用新的分割信息放入识别网络训练更新模型A。接着训练分割网络再用新的模型A 验证,如此反复,直到训练结束,这样就得到分割网络模型和识别网络模型。
4 实验步骤
4.1 数据准备
验证码数据的来源有很多方法,如通过网络爬虫、利用代码生成或者参加比赛获得。本文实验中使用了5类样本。其中2 类利用网络爬虫在一些流行的网站中获取,2类利用代码随机生成,1类来源于比赛项目。每一类验证码大约有5 000个并且都做好标记。然后将每一类样本按照7∶2∶1的比例进行随机拆分。其中的70%作为训练样本,20%作为验证样本,还有10%作为测试样本。
4.1.1 预处理数据集制作
图8(b)所示的是预处理数据集Pre-dataset,由去除干扰信息的验证码和与之对应的原始验证码组成。实验中每一类验证码制作500对预处理数据。在制作时,首先使用数字图像处理方法得到图8(a)中的二值化验证码图像(Bin-dataset),然后通过人工的方法使用图像处理软件对Bin-dataset进行筛选和矫正,最后编写程序处理、合成预处理数据集。

图8 预处理数据集样例
4.1.2 分割数据集制作
接下来制作分割数据集Split-dataset,五类验证码每一种100对。制作时,首先采用连通区域标记法对Bindataset进行处理(其中第五类对Bin-dataset进行形态学变换后再处理),生成标记数据Tag-dataset。然后使用lableme 软件对Tag-dataset 数据进行人工校正。最后利用脚本程序合成分割数据集。

图9 分割数据集样例
4.2 训练预处理模型
在python3.6环境下利用pytorch深度神经网络框架完成整个算法流程。正如前面所说预处理模型是一个Pix2pix 转 换 框 架。Pro-model 包 含GeneratorUNet 和Discriminator 两个部分。在GeneratorUNet 部分中有两个主要步骤UNetDown 和UNetUp。在UNetDown 中使用Conv2d、InstanceNorm2d和LeakyReLU,而在UNetUp中 采 用 一 次ConvTranspose2d、InstanceNorm2d 和ReLU。GeneratorUNet 部分先进行5 次UNetDown 和4次UNetUp。对于Discriminator使用了4个discriminator_block,每个discriminator_block 包含1 个Conv2d、1 个InstanceNorm2d和1个LeakyReLU。在训练的时候使用学习率为0.000 2,batch-size为1,对模型训练2 100 epoch。
4.3 对抗训练
在对抗训练阶段包含了两个网络。即分割网络(SegmentNet)和识别网络(IdentifyNet)。
在SegmentNet中使用了一个类U-Net网络。类U-Net网络的左侧是convolution layers,右侧则是upsamping layers,convolutions layers 中每个pooling layer 前一刻的activation 值会concatenate 到对应的upsamping 层的activation 值中。因为U-Net 左侧部分和resnet、vgg、inception 等模型一样,都是通过卷积层来提取图像特征,所以U-Net可以采用resnet/vgg/inception+upsampling的形式来实现,另外验证码数据并不是非常复杂,这个项目中采用的是最简单的LeNet-5+upsampling的架构。
IdentifyNet 就是一个完全的分类器,常用的有resnet/vgg/inception等,由于验证码图像比较简单,而且经过预处理后数据识别更加简单,根据图7 所示的设计,每一个尺寸通道使用一个Residual bloack模块。一共有4个尺寸通道。
5 实验结果
5.1 预处理结果
在预处理阶段中每一类验证码都使用了500 个样本进行训练,同时也利用传统的数字图像处理方法对每一类进行处理比较,如表1所示。第一列是输入文本验证码图片,第二列是使用传统数字图像处理方法预处理结果,第三列是本文方法处理的结果,第四列是预处理的目标效果。第二列中,每一类都使用不同的代码。表1中的第四类,首先将图像二值化,然后用一个大小为5的方块对其腐蚀去除干扰线条,最后再用大小为5的方块进行膨胀。而处理第五类时不能使用腐蚀或者膨胀的方法。因为汉字的细节太多,而干扰信息的宽度大多都和汉字的宽度相同。根据实验结果得出:(1)传统预处理方法在去除干扰信息的同时也会丢失部分字符信息。特别是干扰线条的宽度长度与字符接近的时候这种现象最为明显,例如表1 中的第二类和第五类验证码。(2)利用GAN神经网络作为预处理模型不仅能够很好除去验证码中的干扰信息,而且还能保留原彩色图片的颜色信息。对于有颜色信息的验证码(如表1中的第三行验证码)又提供了更加有用的分割信息。对于这类文本验证码可以根据不同颜色快速进行分割。(3)这样的预处理模型还有通用性,本文中所处理的五类验证码在预处理时都使用同一个网络模型,甚至它的超参数都是一样的,只需要把数据导入模型进行训练就能得到结果。
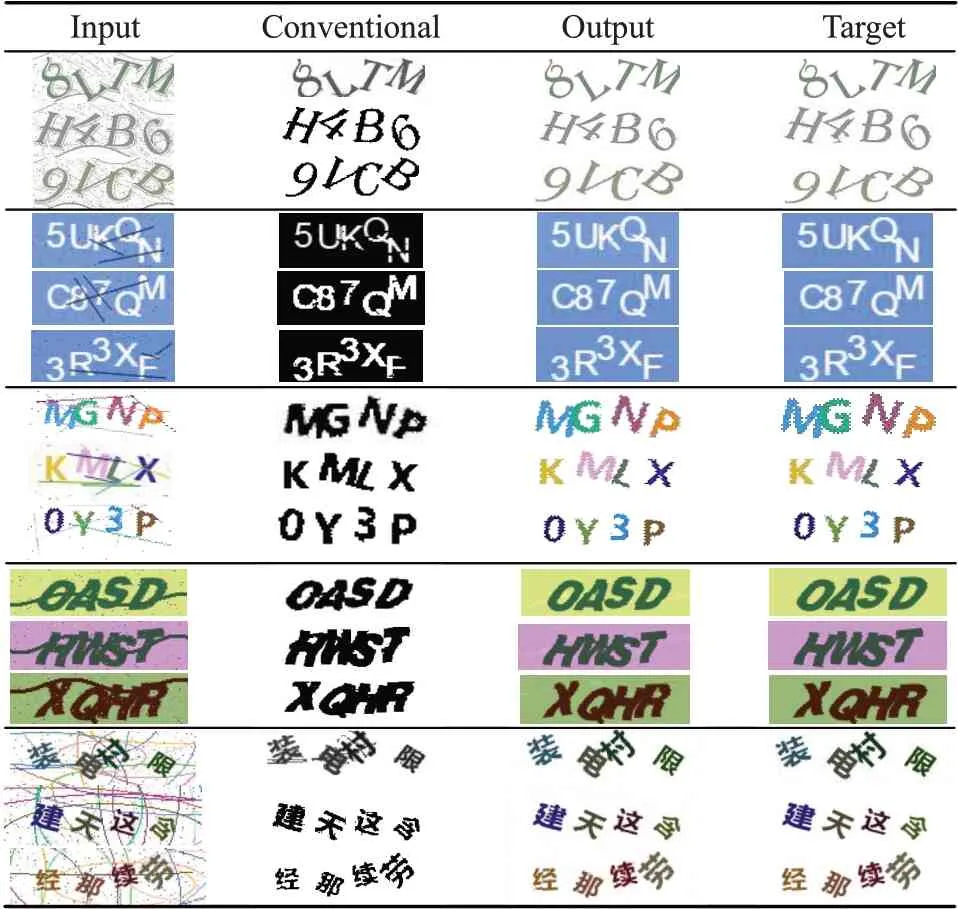
表1 预处理得到的结果
5.2 对抗训练/识别结果
在对抗训练/识别阶段,经过对抗训练后得到两个网络模型,分割网络G 和识别网络D。
5.2.1 分割结果
使用分割网络G 分别对这五类验证码进行训练后得到结果如图10 所示。第一类准确率为0.926,第二类准确率为0.933,第三类准确率为0.953,第四类准确率为0.892,第五类准确率为0.924。
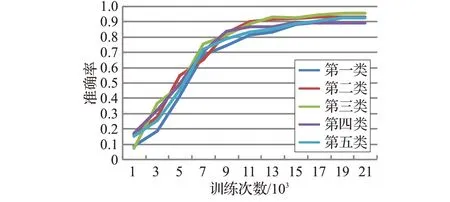
图10 分割网络结果
5.2.2 识别结果
表2 是文本验证码在不同阶段的输出结果。验证码经过分割网络分割后不同字符会被标记成不颜色,通过颜色就能快速进行分割。然后利用识别网络进行分类得到最后结果。
表3显示的是最终识别结果。在实验A中,首先使用传统方法对文本验证码进行预处理,然后利用连通域分割法(CFS)对图像进行分割(有粘贴情况使用平均宽度分割),最后使用卷积神经网络进行分类(在实验过程中首先使用了VGG16 模型,但是由于验证码图像是经过预处理后的图像很容易过拟合,因此使用简单的LeNet5 模型)。在实验B 中使用本文提出的识别方法。通过对比发现:(1)如果文本验证码的干扰线条和字符线条宽度相差很大时,分割是影响准确率的主要因素。如表3中第1、3、4类验证码。(2)当干扰线条宽度和字符线条宽度接近时,预处理和分割都是很关键的步骤,如表3 中第5 类验证码。在整个实验中,不管是预处理还是分割和识别,本文的方法在通用性和准确性方面都能够取得很好的效果。
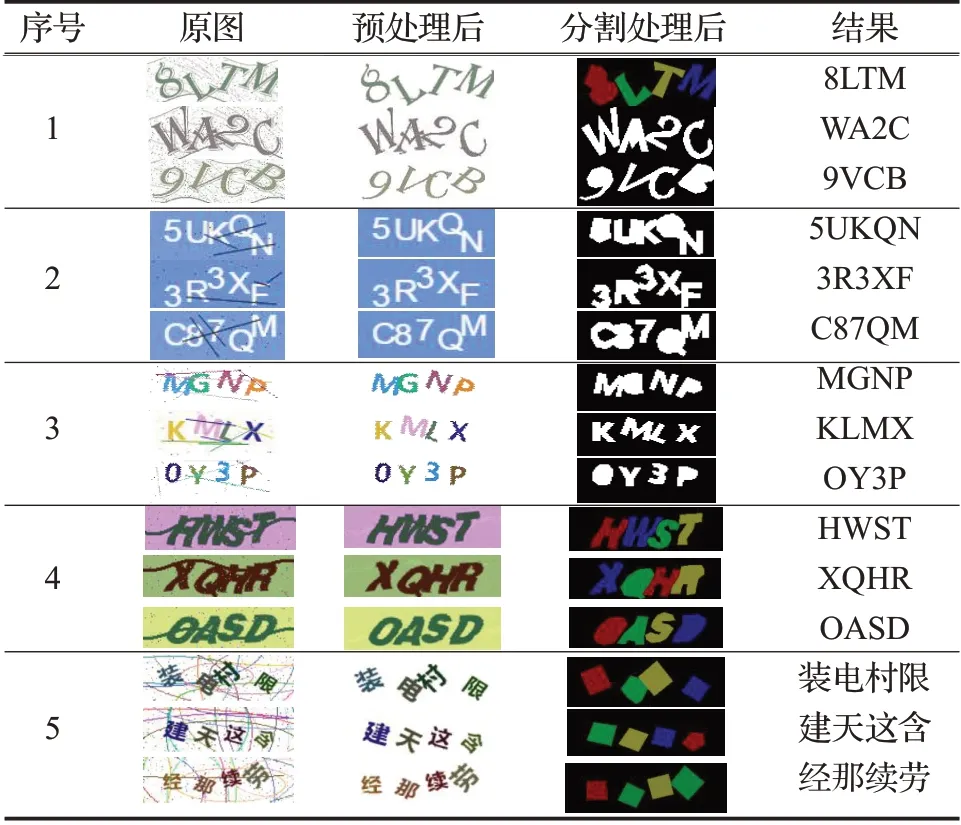
表2 不同阶段的处理结果
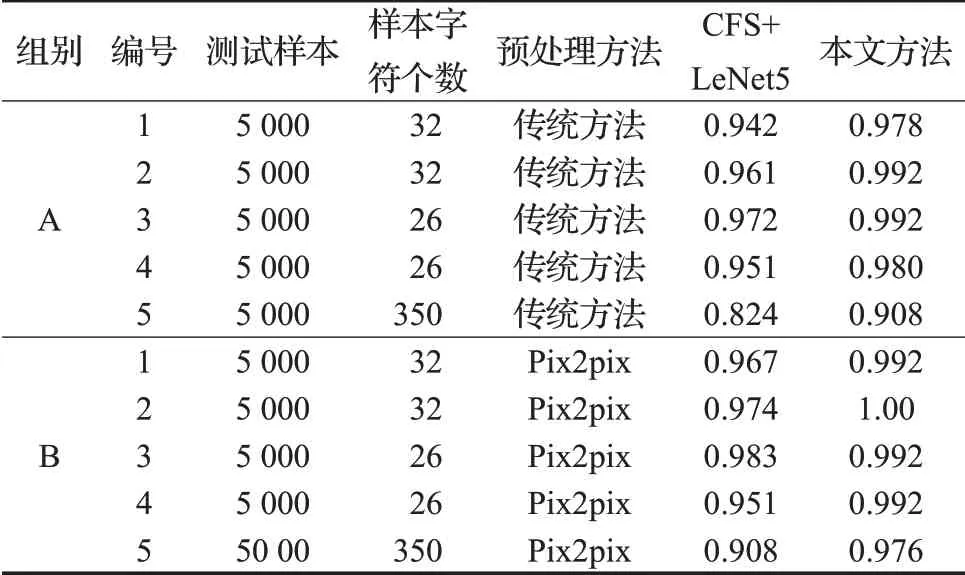
表3 测试结果比较
6 结语
本文提出基于对抗学习的验证码识别方法与以往的方法相比无论是在通用性和准确率上都有明显的提高。但也存在一些不足,首先,文本验证码在收集和预处理阶段需要大量人工参与。在未来工作中将尝试使用超参数优化合成的方式直接生成预处理数据集和分割数据集以减少人工干预,汤战勇等[20]做了类似的工作。其次,本文提出的方法是基于文本型验证码的识别,希望在未来工作能运用到其他相关领域。最后,虽然本文是文本验证码识别,从安全的角度来说,尽管目前文本验证码都有了很多的替代方案,但是文本型验证码依然是最流行的方法。希望能引起更多的注意,在未来提出更加安全的文本验证码。
