基于深度学习的高分辨率遥感图像建筑物识别
2020-04-24宋廷强李继旭张信耶
宋廷强,李继旭,张信耶
1.青岛科技大学 信息科学技术学院,山东 青岛266100
2.珠海欧比特宇航科技股份有限公司 人工智能研究院,广东 珠海519000
1 引言
遥感图像分割技术在城市规划、精准农业、土地测绘覆盖与监测[1]、自动道路检测[2]、环境保护、气候变化和植被覆盖等领域发挥着关键作用。遥感图像的语义分割旨在将每个像素分类为给定的类别,它是理解和推断对象以及场景中空间对象之间关系的重要任务[3]。
常规的图像分割方法主要基于光谱统计特征,如最小距离、最大似然和K 均值聚类[4-5]。虽然这些方法取得了良好的效果,但随着遥感图像分辨率的提高,分割和识别精度已不能满足需求。近年来深度卷积神经网络是深度学习应用到遥感图像和其他图像分割等方面的重大成果。翁飘等人提出了一种改进的全卷积神经网络的分割方法,从而融入更多的局部信息[6]。根据建立的数据集训练优化后的FCN,能够对一些光照不均匀、背景复杂的裂缝图像进行较好的分割,然而,这类方法对图像小目标识别效果差一些。刘辰等人提出了一种基于改进卷积神经网络的医学图像分割方法,其中卷积神经网络由编码、双向卷积长短记忆网络(BDCLSTM)和解码部分组成[7]。这类方法能够充分挖掘单视图下切片序列间的相关信息,从而提高分割精度,然而,也存在过度分割问题。王振等人提出了一种基于改进全卷积神经网络玉米叶片病斑分割方法,编码网络结构是在传统VGG16 网络的基础上进行改进,解码网络主要是对编码网络中的下采样层进行反卷积操作[8]。通过对解码网络不断地进行训练,可以恢复编码网络输出特征图的分辨率,得到更为精确的分割效果,但也同样存在过度使用低级特征的问题。Yang 等人提出了一种基于HSPCNN的自适应图像区域分割方法,适合执行图像多区域分割,然而,对于具有正态分布密度的图像,难以通过非交互方法获得期望的分割结果[9]。在经典卷积神经网络CNN[10]中,由像素点及其相邻像素组成的图像块输入到网络中以提取特征,用于每个像素的分类[11]。但这种方法在批处理操作中引入了大量冗余计算,并导致大量内存消耗和低分区效率。Long等人提出FCN[12],它可以接受任何大小的图像作为输入,通过卷积层提取特征,然后进行反卷积上采样,并输出具有相同大小的分割图像,具有准确的目标对象边缘并分配标签。目前,FCN模型已被广泛应用于图像分割[13]。另外,由于在卷积和池化过程中,图像分辨率降低,因此最后一层产生的分割结果通常分辨率比较低。许多后续的图像分割模型进一步扩展了FCN 的思想,代表模型有U_Net[14]、SegNet[15]和DeepLabv3[16]。在DeepLabv3 中,金字塔池化模块用于提取多个尺度的特征图。其他先进的方法包括处理不同尺度信息,类似于在判别特征[17]网络中学习;细化残差块[18],可以跨不同渠道聚合信息;细化特征图,提高各阶段的识别能力。最大融合策略,结合深层和浅层信息,避免由于FCN 中的下采样而丢失详细信息;并使用多线程控制网络训练策略[19]。
注意机制是提取输入信号最有用信息的有效工具[20-21]。通过使用过滤器功能(例如softmax或Sigmoid)和顺序技术可以实现注意力机制。注意机制最近已广泛用于图像字幕[22]、图像分类[23]、视觉问答[24]、图像识别[25]及其他领域。在这些应用中,他们使用过滤器功能来激活收集的顶部信息,以按通道或在空间上对激活进行加权,并引入反馈连接。例如,Wang等人使用软掩膜结构来生成注意力机制[26]的特征,其中注意力是使用图像分割来捕获视觉关注焦点区域。Hu等人设计了一个挤压和激励模块来重新校准通道[27]功能。Wang等人建立了一个熵控制模块来选择低特征图进行语义分割[28]。Li等人引入了一个全球关注的上采样模块,以指导语义细分中低级和高级功能的集成[29]。研究表明注意力机制可以增强目标所具有的某些神经元,并改善其性能。因此,在设计遥感影像建筑物提取网络时,构建了一个注意机制模块,将低级和高级特征进行语义分割,避免了对低级特征的过度使用。
由于遥感图像分辨率的提高,高分辨率遥感图像包含大量的信息,这扩展了遥感图像的应用范围,并且所识别的感兴趣区域对象的尺寸较小。现有的深度学习神经网络SegNet 直接应用于遥感影像分割,存在小物体分割效果差和过度分割问题。基于SegNet网络和遥感图像数据属性,提出了一种新的高分辨率图像分割方法,本文的方法为:(1)增加增强型空洞金字塔模块A-ASPP,A-ASPP结构中的平行扩张卷积采用不同的扩张因子,得到更密集的采样,收集更高层次的局部信息,提高小物体的分割性能;(2)增加注意力融合模块,增强有用的低级特征信息并消除噪声以避免过度使用低级特征,避免过度分割及进一步提高分割精度。
2 研究方法
高分辨率遥感影像分割技术流程如图1 所示。初始化的模型经过训练、调整模型的权重,使模型能够从大量数据中学到遥感影像目标特征,模型核心是数据集制作与网络结构设计。
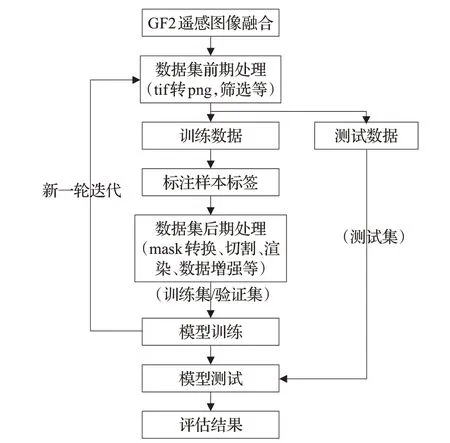
图1 高分辨率影像语义分割技术流程图
2.1 空洞卷积
在经典网络CNN 中,卷积核可以通过池化操作获得更大的感受野。遥感图像分割的输入和输出大小是相同的。因此,池化后尺寸较小的图像需要通过反卷积操作扩展回原始尺寸。但是,如果下采样过程中池化太大,则反卷积过程中图像信息的丢失将会增多。扩张卷积可以通过控制扩张率获得不同大小的感受野。假设在二维情况下,对于每个位置i,相应的输出是y 并且特征的权重是w,输入特征层x 的卷积被计算为:

其中,k 是卷积核的大小,r 是扩张速率。
在扩展卷积中,卷积核由扩张因子扩展,并沿着相邻权重之间的空间维度放置r-1 个零,以创建稀疏滤波器。检查扩张卷积以输入传统卷积的特征x。不同扩展速率的卷积如图2所示。
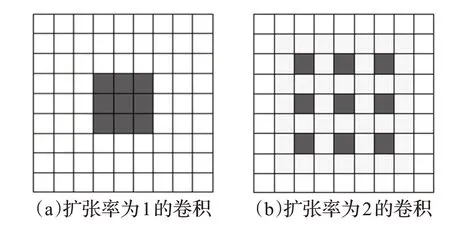
图2 内核大小为3×3且扩张率不同的卷积
图2(a)显示了一个标准的3×3卷积,一种特殊形式的扩张卷积率=1,每次覆盖一个3×3 尺寸的视野;图2(b)中显示了一个速率=2的3×3扩张卷积。卷积核的大小仍为3×3,但卷积核的计算视野增加到7×7,而实际参数仍为3×3。感受野的大小可以表示为:

因此,通过调整稀疏卷积中的膨胀率,可以扩展感受野而无需添加额外的参数。
2.2 原始SegNet体系结构
深度卷积神经网络的语义分割模型SegNet 原始架构主要由两部分组成,架构如图3所示。第一部分是编码网络,包括卷积层、批标准化、激活函数和池化层,用于提取输入数据的多尺度特征。第二部分是解码网络,包括卷积层、批标准化、上采样和激活函数,旨在恢复特征图的空间分辨率并使用这些特征图提取目标物。解码网络利用编码器下采样时保存的相应特征层的最大池化索引信息将低分辨率的特征图映射到高空间分辨率的特征图,实现低维向量到高维向量的重构。
2.3 AA-SegNet体系结构
基于SegNet 结构改进的AA-SegNet 网络模型主要结构由三部分组成,架构如图4所示。第一部分是编码网络。结构改变为在编码器末端,加入增强型空洞金字塔池化模块A-ASPP,A-ASPP结构中的平行扩张卷积采用不同的扩张因子,得到更密集的采样,收集更高层次的局部信息,提高小物体的分割性能旨在精准提取小目标。
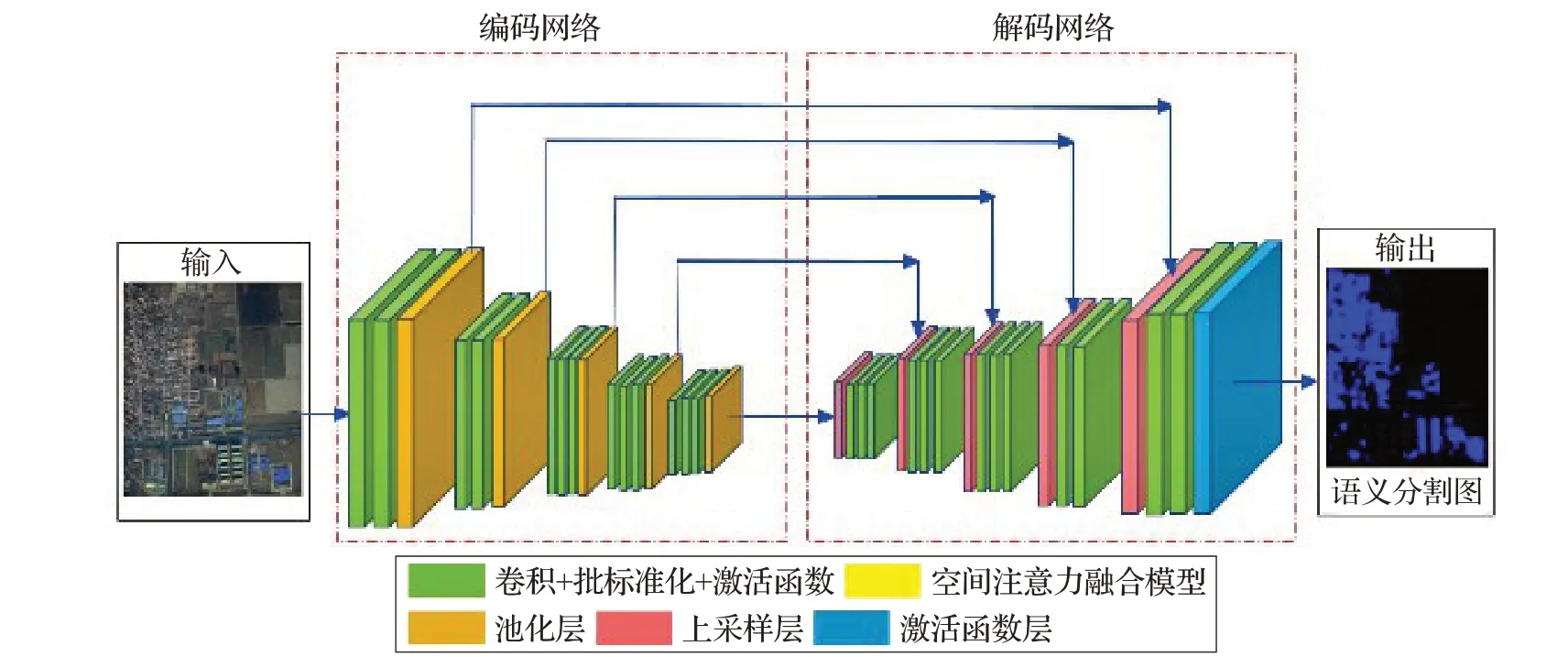
图3 SegNet网络模型体系结构
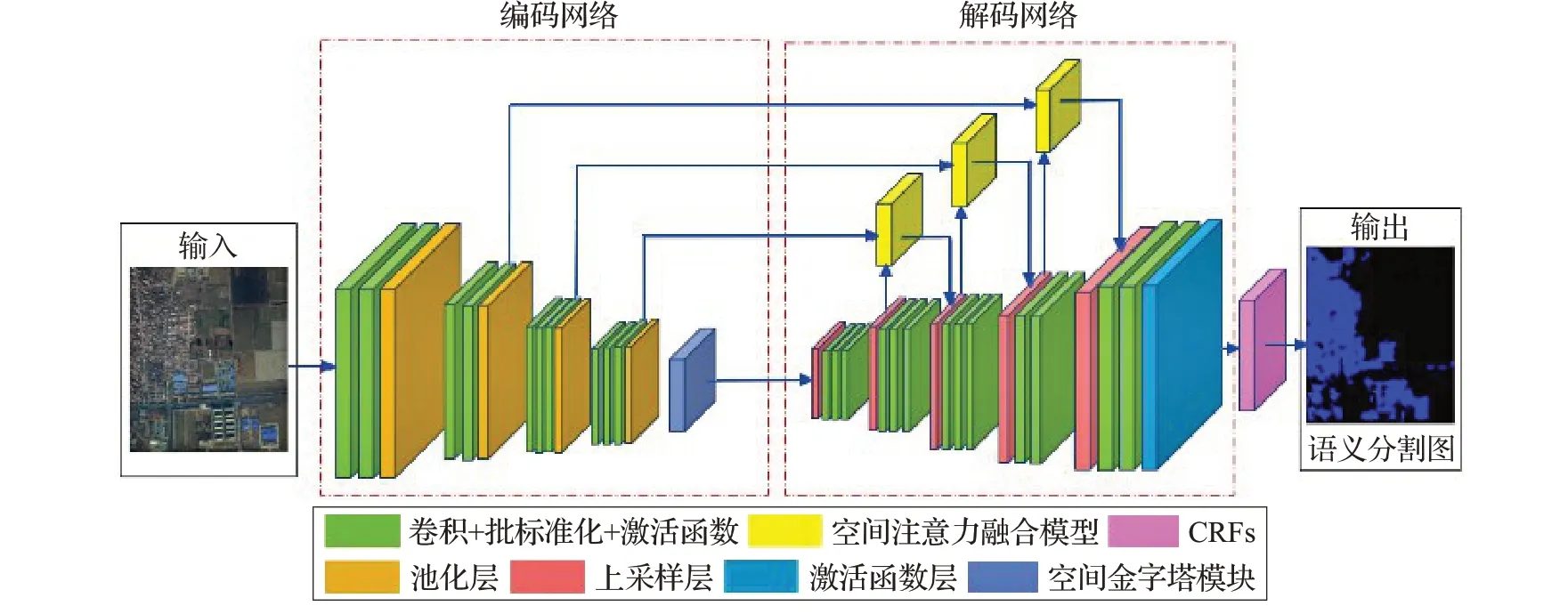
图4 AA-SegNet网络模型体系结构
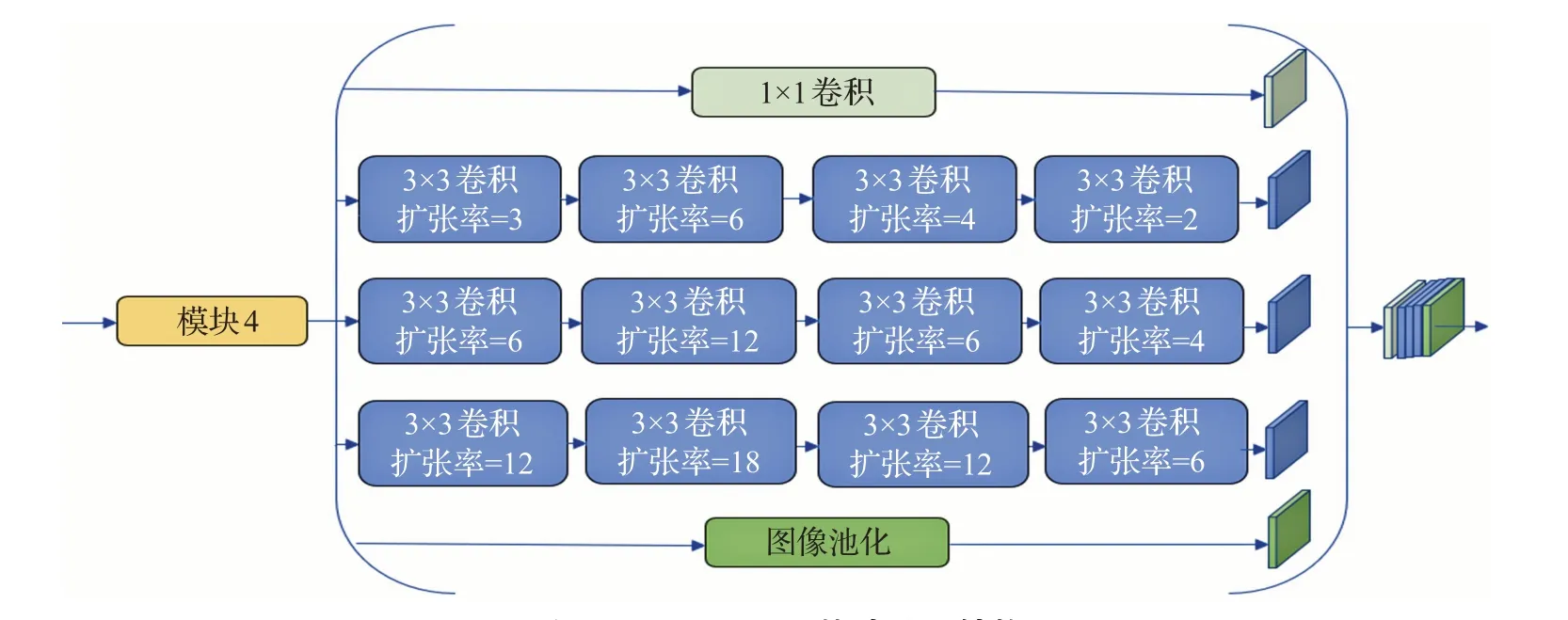
图5 A-ASPP网络基础模块结构
第二部分是解码网络,解码网络进行非线性上采样,结构改变为编码网络卷积层与上采样之间建立空间注意力融合模块,空间注意力融合模块用于引导低级特征图,来帮助高级特征恢复像素定位细节,减少识别图像过度分割。
第三部分是后期处理模块CRFs(Conditional Random Fields),CRFs[30]有助于在给定网络识别结果和原始图像的RGB特征时,估计模型识别结果的后验分布.通过对用户定义的能量函数的最小化来实现,类似于双边滤波器(bilateral filter)的效果。另外,CRFs也对小分割区域进行惩罚。
2.4 A-ASPP模块
正如文献[16]中指出的,上下文信息对于检测目标对象很重要。上下文信息(例如道路、汽车或其他建筑物)有助于识别物体。图5展示了所提出的增强型空洞空间金字塔池化(A-ASPP)模块。A-ASPP 模块具有三个平行的扩张卷积分支,每个分支由四个不同的扩张速率扩张卷积层组成。A-ASPP 层旨在使计算更加集中,增强小物体特征的学习,从而覆盖大背景,计算更强的特征,逐步增加扩张因子;然后将扩张因子减少到聚集由扩张因子增加而散射的局部特征。
扩张卷积对于分割任务很重要,虽然它在分辨率和背景上下文方面很有用,但它对高分辨率图像中的小对象分割效果并不完善。普通网络应用扩张卷积会导致两个问题:(1)太大的扩张因子导致稀疏卷积核,并且丢失了大量的计算信息。(2)相邻空间的一致性变弱,并且在上采样层丢失局部信息。
首先,为了解决稀疏卷积引起的稀疏性问题,需要更加集中的计算,并且需要增加扩张因子。从小扩展计算到大扩展,这使得计算和采样更密集,从而允许获得更详细的上下文信息。因此,A-ASPP 网络结构使用逐渐扩展结构。为了解决第二个问题,采用降低膨胀系数。如果在扩张因子增加结构后附加具有减少的膨胀系数的结构,可以再次连接相邻单元的信息金字塔。因次,减少结构逐渐恢复相邻单元之间的一致性并提取更高层中的局部结构。
A-ASPP 的结构显示在图5 部分。A-ASPP 结构使用扩张因子先扩大然后减少以保持信息获取多尺度的优势,提高学习能力。首先,扩张因子逐渐扩大,使感受野更加密集,从而使卷积网络获得更详细的背景信息。然后通过减少扩展因子,聚合局部信息来增强小物体的特征提取。
2.5 空间注意力融合模块
公共编码器、解码器[31-32]网络主要使用不同尺度的特征映射来帮助解码器逐渐恢复对象细节信息。U-Net的跳跃连接是通过重用功能映射将编码器路径恢复对象详细信息的常用方法。但是,这种方法将会过度使用低级特征并导致影像过度分割。注意力机制能够使用更高级别的视觉信息来加权较低级别的信息。受到注意力机制的启发,空间注意力融合模块被设计用于增强有用的低级特征信息并消除噪声以避免过度使用低级特征。
在空间注意力融合模块,首先,高级特征由Sigmoid层激活,激活的输出归一化为[0,1],并用做低级特征的映射。然后,将高低特征输出乘以低级特征以获得加权的低级特征。最后,添加高级特征和加权低级信息作为最后模块的输入,以逐渐恢复对象细节信息。空间注意力融合模块的体系结构如图6所示。
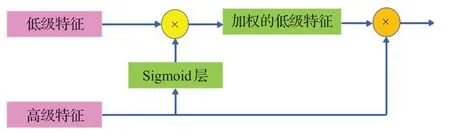
图6 空间注意力融合模块
训练启动后,原始图像进入神经网络的输入端,在神经网络中使用卷积操作进行特征抽取,卷积操作中,卷积过滤器尺寸为3×3×64,步长为1,零填充,激活函数为relu。由于网络较为庞大,在每个卷积层之后增加一个BatchNormalization 进行归一化操作,防止过拟合和梯度爆炸。利用Maxpool 对输入的原始图像进行五次下采样;池化操作中,过滤器尺寸均为2×2;在编码器最后加入增强型的空洞金字塔池化,来进行多尺度信息聚合。在解码器部分,加入3 个空间注意力融合模块,注意力机制模块由编码器中的卷积和解码器中的上采样层连接,采集高级和低级特征后,然后传到上采样阶段,完成信息融合。
3 实验
在本章中,对所提AA-SegNet 网络模型进行训练、测试与优化,所有网络都在GPU 上基于Tensorflow+Kears框架进行训练和测试。
3.1 训练过程
3.1.1 数据集
本实验所用数据源为高分二号,数据为2019年7月中国山东省潍坊市的高分辨率遥感影像。图像的空间分辨率为亚米级,光谱可见光频端(R、G、B)。实验样本集包括训练样本、测试样本。从遥感影像中分别截10幅5 000×5 000 像素大小的影像切片(7 幅作为训练样本,3幅作为测试样本)。
3.1.2 数据集处理
数据集处理包括:数据集前期处理、数据集后期处理。数据集前期处理:首先,将GF2 遥感图像经过多光谱和全色数据融合后的tif格式数据,转换为网络模型常用的png 格式;然后,筛选出适合网络模型训练的训练数据、测试数据。数据集后期处理包括数据标注、生成掩码、样本切割、降采样、数据增强五个阶段。鉴于GPU的内存有限并获取更多的训练样本,平均大小为5 000×5 000 的图像被切割成尺寸为512×512。为了增加样本量,可以从不同的偏移量开始切割(见图7),每幅大图可以生成81×3 个样本,要对原图和标签图进行相同的切割。
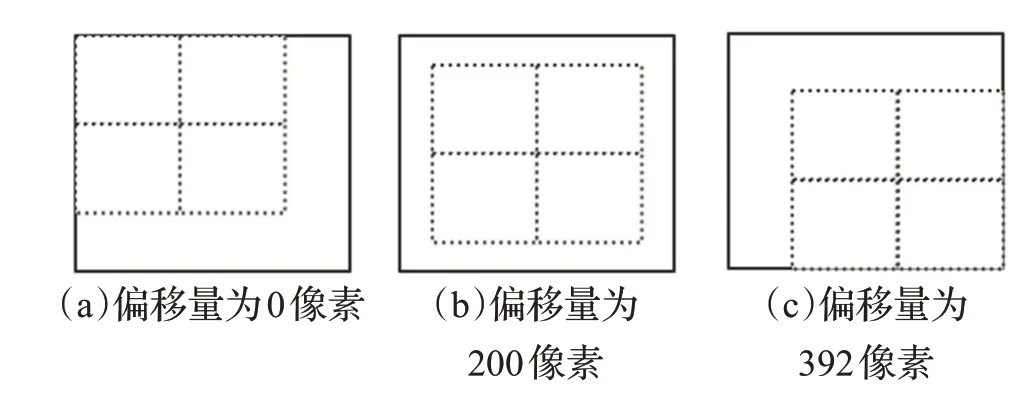
图7 以不同的偏移量切割生成多批样本
由于高分辨率遥感影像地物纹理信息太多,会影响网络模型的判断,降低分割准确度。因此将尺寸512×512 样本降采样为256×256。为丰富图像训练集,更好提取训练特征,泛化模型(防止过拟合),对图像块旋转、扭曲、增加噪声等方式进行图像增强。具体地,对于原图进行90°、180°、270°翻转、上下和左右镜像操作,生成另外5份数据,加上原有数据,数据量增加为原来的6倍(对标签进行相同操作),如图8 所示。通过以上操作,新的训练集包含46 267 幅256×256 的子图像。为评估所提网络模型在不同数据集合上的训练效果,数据集分为数据集1(8 867 幅,256×256)、数据集2(18 700 幅,256×256),数据集3(18 700幅,512×512)。

图8 数据增强实例
3.1.3 实施细节
对AA-SegNet网络模型,选择18%作为验证集,82%作为训练集。在30 轮(epoch)的训练中,每一个epoch训练结束,会在验证集上计算一次损失和精度,并保存一次模型,最终选取在验证集上表现最好的模型。AASegNet网络模型测试时,需将测试图输入已训练好的模型,从输出得到mask图,观察渲染后的效果。为确保更好的训练结果,根据训练收敛速度手动调整学习率,最终约为0.001。
3.1.4 评估
本研究中使用了基于像素评估标准,能够提取建筑物内部像素的数量并提供严格的评估。在基于像素的评估中,使用总体精度(OA)、F1 分数和联合平均交叉得分(MIOU)来评估定量性能[33]。 F1 分数计算方法如式(3)所示:
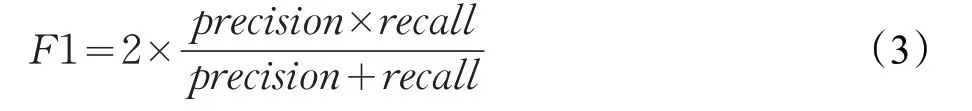
式中,precision=tp/(tp+fp),recall=tp/(tp+fn),其中,tp、fp 和fn 分别表示真正值、假正值和假负值,precision、recall 分别表示精确度、召回率,这些值可以通过每个图块基于像素的混淆矩阵来计算。IOU 是预测区域和地面真实值区域在其联合上相交的平均值,如式(4)所示。MIOU通过取IOU平均可得到:
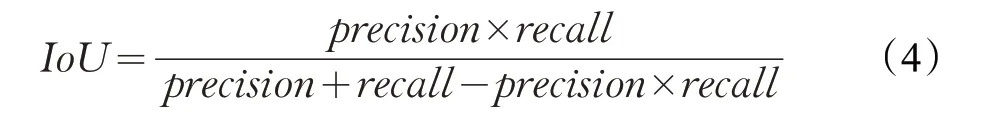
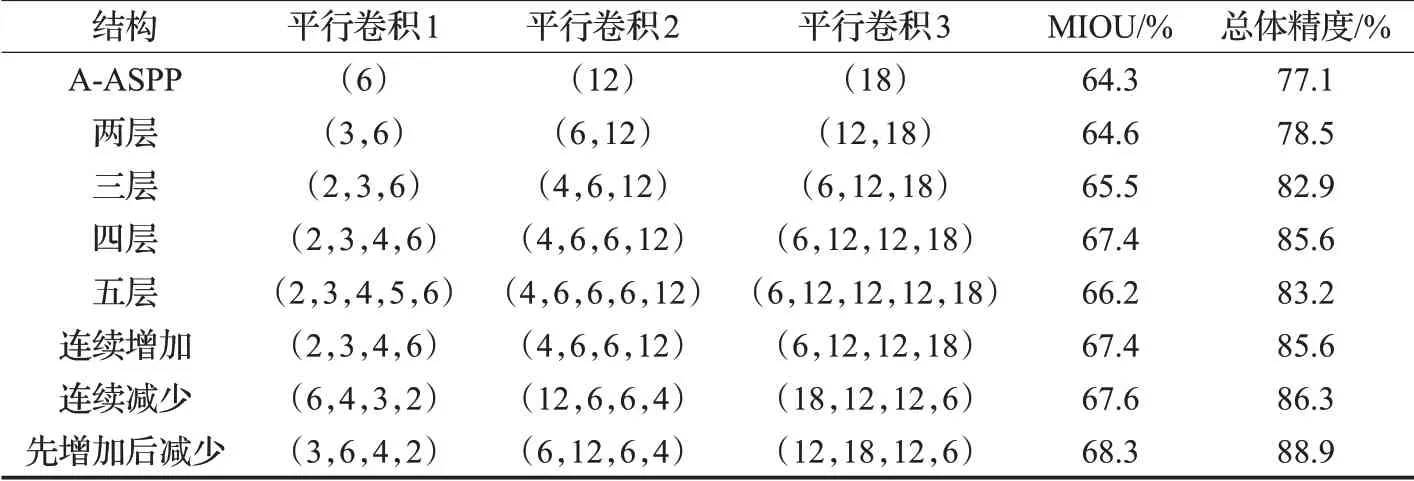
表1 步幅为16的A-ASPP的不同参数结果
3.2 提取结果
首先以AA-SegNet 网络为核心架构,选择A-ASPP模块空洞率但不更改参数的原始模型,因为参数变化太多,则每个变化率都对应于少量的卷积层,这不利于提取更多抽象特征。如表1所示,选择四种不同的扩展速率要好于原始参数基本版本,连续增加和连续减少扩张率的效果明显优于基本实验(A-ASPP、两层、三层、四层、五层),根据表1中MOIU分数以及识别准确率可以得出,先增加后减少扩张率的MIOU和总体精度分数最高。最后,根据选择的变化次数和增加,减少扩张速率的方法,设计了增强型A-ASPP 结构的网络参数,在本次研究中,最优的模型结构参数为(变化率1,变化率2,变化率3,边化率4)=((1),(3,6,4,2),(6,12,6,4),(12,18,12,6))。
经过5 000 次网络模型训练,得到最稳定的结果如表2所示。本实验采用了三个数据集,本网络模型达到了比较高的分数(OA、F1、MIOU、precision 和recall),这表明AA-SegNet网络在提取建筑物方面表现良好。
AA-SegNet 网络基于数据集2,不同阶段的训练结果(见表3),在数据集使用样本扩充后,可提高训练精度、增加泛化能力。根据表3 给出的训练结果,可以看出使用512尺寸进行训练会增加不稳定因素,因为遥感影像建筑用地存在”同物异谱”现象,会影响模型训练时收敛。
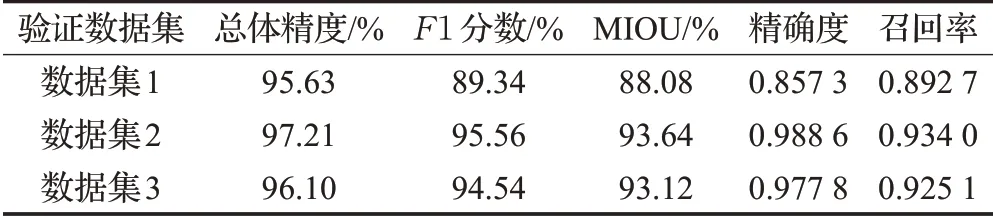
表2 基于像素的网络模型评估结果
在未加注意力机制和增强型AA-ASPP 模块之前,SegNet网络识别结果存在许多空洞、碎片以及小目标识别差,加入空间注意融合模块之后,由于空间注意力融合模块,加强了低级特征的和高级特征的融合,能够避免结果被过度分割,并且可减少分割区域噪点。图9给出了AA-SegNet、SegNet 网络模型识别结果,参见图9(b)、(c)中黄色框标识。

图9 SegNet、AA-SegNet网络模型建筑识别结果
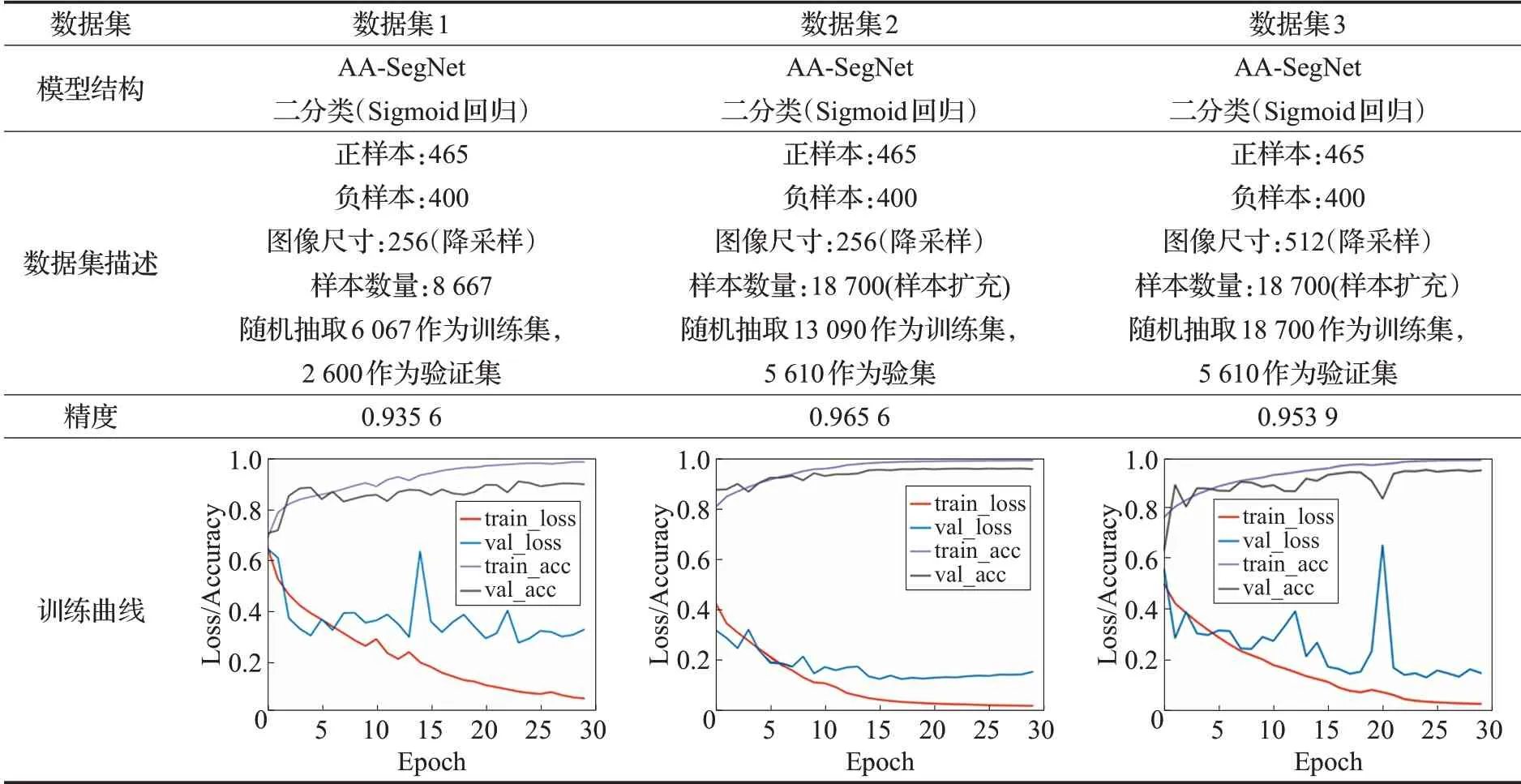
表3 AA-SegNet网络模型训练结果

图10 AA-SegNet、SegNet、DeepLabv3、U-Net网络预测建筑结果
3.3 与相关网络比较
对比其他深度学习算法模型,将相同的数据集应用于SegNet、DeepLabv3、U-Net 和改进的AA-SegNet 网络进行实验。SegNet 网络的解码器是使用上采样与卷积的过程,过度使用低级特征进行目标提取,会导致分割影像结果出现过度分割、小目标识别差现象。U_Net网络采用通道维度拼接融合方式,来增加特征的描述信息,存在过度使用低级特征的问题。DeepLabv3网络编码器采用空洞卷积生成任意维度的特征,并采用空间金字塔池化策略,在级联解码器进而恢复边界细节信息,也过度融合了低级特征。由于SegNet、DeepLabv3、UNet 缺乏注意力机制融合模块、增强型空间金字塔池化模块,一些低级特征被过度使用,导致识别图像结果建筑物过度分割并且小目标识别效果差,分割结果建筑物出现碎片化,参见图10(c)、(d)、(e)红框标示部分。在图10(c)中的红框标示中,AA-SegNet 网络结果明显改善,说明空间注意力机制可以改善性能,降低碎片化,A-ASPP 精准提取小目标。为定量比较所提出的AASegNet 网络,在表4(测试集,包括4 张尺寸为5 000×5 000图像)中分别给出了OA、F1 得分、训练时间TT和识别时间RT,可以看出,AA-SegNet 网络OA 得分明显优于SegNet、DeepLabv3和U-net网络,其网络训练时间和识别时间都优于DeepLabv3 和U-net 网络(TT:15<21<25<55,RT:6<8<12<50),具有比较高的效率。总的来说,尽管存在很少一部分错误的建筑分类,见图11(b)和(d)红色框标示部分,但总体来说,AA-SegNet网络从高分辨率遥感影像中能够实现更好的建筑用地提取效果。
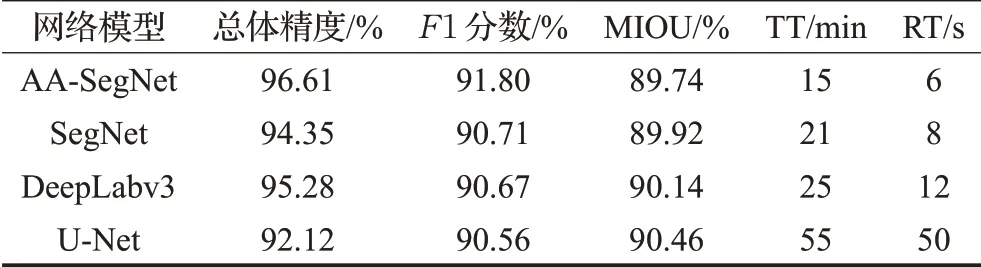
表4 相同数据集上对比相关网络测试结果

图11 某些因素导致建筑物提取中错误检测和漏检
4 讨论
AA-SegNet 优越性的主要性能是通过组合增强型空间金字塔池化和空间注意力融合模块,合理利用不同级别的特征,提高小目标识别。另外,公共编码器-解码器[31-32]网络主要使用跳跃连接来帮助解码器逐渐恢复对象细节。然而,通过跳跃连接将这些特征映射与更高级别的特征映射融合可以增加最终结果的模糊性,这将导致过度使用低级特征并导致过度分割。注意力机制可以使用更高级别的视觉信息来加权较低级别的信息以抑制背景和噪声。因此,基于注意力机制的空间注意力融合模块可以更好地指导低级特征图,以帮助高级特征恢复影像的细节并减少过度分割。
但是,高分二号遥感影像建筑用地提取准确性可能会受到某些因素的影响,如图11所示。
复杂的背景。虽然水,裸露和稀疏植被在一些测试样本中占少数,但由于与前景物体(建筑物用地)色调相似,它们也被监测为建筑物用地,见图11(a)、(b)红色方框。复杂背景可能会导致精度低于召回,参见表2中数据集1 的评估结果。错误分类可能是所提AA-SegNet网络的主要限制。
特殊建筑物。一些训练样本中,一些建筑物屋顶的特征(如颜色、纹理和材料),与大多数建筑物完全不同。另外,一些树木覆盖的建筑物的形状无法准确检测出来,一些模糊的和不规则的边界难以分类。因此,很难检测出这类建筑物,见图11(c)、(d)红色方框。
为削弱上述因素的影像,需要更加完善的深度学习网络来提高特殊建筑用地提取的效率和准确率。另外,预处理方法在区分建筑用地与复杂背景方面也起着重要作用。例如,使用归一化植被指数(NDVI)或归一化差异水指数(NDWI)[34-35]来增强边缘,则可能不会将水体误判断为建筑物。此外,目前关于多模态遥感数据融合技术[36]也可能提高建筑用地的准确性。预处理[37]方法和数据融合技术在将来的研究中进一步解决。
5 结论
本文提出的基于深度学习SegNet 结构改进的AASegNet网络模型,能够较好地解决高分辨率遥感影像中小物体分类效果差和过度分割问题。该网络使用增强型空间金字塔池化模块进行小目标提取,空间注意力融合模块用于指导低特征图,以帮助高特征图恢复图像的细节,减少过度分割。与深度学习方法SegNet、Deep-Labv3 和U-Net 进行比较,AA-SegNet 网络在图像识别率、OA、MIOU、F1 得分、TT和RT(基于像素)方面有更好的表现,展示了在识别遥感图像建筑性能方面的有效性和可行性。
