DAPC:结合双注意力和指针覆盖的文本摘要模型
2020-04-24曾碧卿韩旭丽徐如阳
张 敏,曾碧卿,韩旭丽,徐如阳
1.华南师范大学 计算机学院,广州510631
2.华南师范大学 软件学院,广东 佛山528225
1 引言
自动文本摘要技术对给定源文本内容进行压缩、提炼与总结,并产生简洁、流畅且保留关键信息的文本来概括用户所关注的主要内容[1]。今天,人们普遍面临着信息过载的问题,自动文本摘要技术可以对文本信息进行压缩,同时,提取出其中的重要信息,这无疑能有效地降低用户的信息负载,帮助用户更好地从互联网中获取想要的情报信息。
自动文本摘要方法根据生成摘要覆盖的文档范围,可以分为单文档摘要和多文档摘要。根据摘要内容的来源可以分为抽取式摘要(Extractive Summarization)和生成式摘要(Abstractive Summarization)[2]两类。其中,抽取式摘要生成的摘要内容是按一定规则从原文本中抽取出来的词、短语或句子组成的。生成式摘要产生的摘要文本则是通过理解文本内容,用简练的文字将原文本的内容表达出来。由于此过程与人类做摘要的过程相似,所以生成式摘要方法在文本摘要模型中得到了广泛使用[3-7]。
近年来,随着计算机软硬件不断升级,深度学习和神经网络技术得到快速发展,并广泛应用于自然语言处理(Natural Language Processing,NLP)任务,比如,机器翻译[8-9]、情感分析[10]、自动问答[11]、文本摘要[12]等,同时,取得显著的研究成果。其中,以序列到序列(Sequenceto-Sequence,Seq2Seq)神经网络模型(有时又被称为编码器-解码器,encoder-decoder模型)为代表,其结合卷积神经网络(Convolutional Neural Network,CNN)或循环神经网络(Recurrent Neural Network,RNN)和注意力机制,能更好地提取文本中蕴含的隐藏特征信息,相比传统自然语言处理方法有更明显的优势。
然而,现有基于神经网络的文本摘要方法生成的摘要普遍存在以下问题:其一,这些方法由于忽略了之前解码步生成的文本信息,从而导致生成摘要存在语义无关、语句不通顺、词句重复问题;其二,受词表大小的限制以及生成式摘要模型可能产生不在文本中的词等原因影响,生成的摘要存在未登录词(Out-Of-Vocabulary,OOV)问题,使得生成摘要的可读性受到影响;第三,在模型的训练及验证的解码阶段,会把真实的摘要输入decoder,但在测试阶段,decoder部分当前时刻的输入摘要内容是上一解码步的输出,这样由于训练和测试阶段的不同输入,会导致一个偏差,这个偏差随着序列长度的增加会越来越大,这就会产生exposure bias问题。
为了解决以上问题,本文提出一个结合双注意力(dual attention)和指针覆盖机制(pointer-generator network and coverage mechanism)的生成式摘要新方法DAPC 模型。模型使用词嵌入(word embedding)、局部注意力及CNN 作为隐藏特征提取器,使用双向长短期记忆(Long Short-Term Memory,LSTM)作为encoder,单向LSTM作为decoder,最后,加入pointer-generator网络和coverage机制。基于CNN/Daily Mail数据集(https://cs.nyu.edu/~kcho/DMQA/)的实验结果表明,该模型既可以提取文本高层次的n-gram 语言特征,避免生成重复文本,同时,也能解决受词表大小影响而产生的OOV问题,进而提升摘要质量。
本文的主要贡献体现在以下三个方面:
(1)针对文本摘要存在的语义无关、语句不通顺问题,提出一种隐藏特征提取器,该特征器由词嵌入、局部注意力以及CNN 三个部分组成,实验表明该机制对摘要质量有较好的表现。
(2)在摘要解码阶段,加入OOV 扩展词表,将指针机制与注意力机制结合集成到decoder中,提升摘要质量。
(3)采用coverage机制解决文本摘要任务中产生的句内重复的问题,实验表明模型DAPC 在ROUGE-2 指标上相比最好的模型高0.87个百分点。
2 相关工作
2.1 序列到序列模型
2014 年,Sutskever 等[13]采用Seq2Seq 模型实现基于神经网络的英-法互译的机器翻译。同年,Bahdanau等[14]提出encoder-decoder与注意力机制结合的模型,应用在机器翻译任务中,取得当时最好的效果,为Seq2Seq 任务提供了一种全新的深度学习模型架构。2015 年,Rush等人[15]对Bahdanau等[14]提出的模型进行改进,并将其应用到文本摘要任务中,取得突破性的进展。Chopra等[16]在ABS 模型[15]基础上进行改进,他们保留原模型中encoder 部分的神经网络为CNN,并将decoder 部分的前馈神经网络语言模型修改为RNN,实验结果表明该模 型 在DUC 数 据 集(http://duc.nist.gov/data.html)上ROUGE-1得分有相对提高。更进一步地,Nallapati等[17]将encoder 和decoder 部分的神经网络模型都改成为RNN,即模型是完全由RNN 组成的Seq2Seq 模型。除此之外,他们还在编码器中引入词汇和统计特征(如词性、命名实体等特征)来提高模型的表现,其在ROUGE-2、ROUGE-L两个评价标准下的表现相对Chopra等[16]提出的模型效果又有提升。Hu等[18]利用新浪微博数据构建了一个大规模、高质量中文短文本摘要数据集LCSTS(Large Scale Chinese Short Text Summarization)(http://icrc.hitsz.edu.cn/Article/show/139.html),数据集弥补了在文本摘要领域没有中文摘要数据集的空缺,并且在数据集的基础上采用简单Seq2Seq 模型给出了一个baseline,为以后的学者提供相关研究基础。2017 年,Vaswani 等[8]提出一个不用RNN 也不用CNN,而完全依赖注意力实现的翻译模型,引入自注意力(self-attention),有时也被称为内注意力(inner-attention),在序列内部做注意力寻找序列内部的联系,不仅降低模型计算复杂度,同时在机器翻译任务中取得不错的成绩。
给定一个长文本并生成其摘要是文本摘要领域一项比较困难的任务,已有的深度神经网络模型在处理这项任务时,会出现生成摘要语句不通顺、词句重复等问题。Nema等[6]采用正交化上下文向量的方法,应用于基于查询的生成式摘要任务中,有效减少了生成摘要句内重复问题的发生。另外,Paulus 等[19]首次将强化学习引入文本摘要任务中,并提出一个新的模型,该模型引入内嵌注意力机制(intra-attention mechanism)和新的训练方法,有效地提升了自动文本摘要的生成质量。同时,引入强化学习的训练方法对摘要结果进行优化,减轻exposure bias问题,更进一步地提升摘要表现。但基于强化学习的训练方法的参数调整过程相对其他方法更难,且其训练时间更长,因此本文没有实现强化学习训练方法。
2.2 神经网络
近年来,CNN 在许多自然语言处理任务中取得了巨大成功,例如文本分类[20]、情感分析[21]和神经语言模型[22]等。CNN 进行窗口式遍历,方便并行计算,通过层叠方法增大感受野,能从输入文本中提取更多的语境特征,获取抽象特征信息[8,23]。RNN 神经网络结构相对CNN 来说更简单,常见的RNN 包括LSTM 和门控循环单元(Gated Recurrent Unit,GRU)。由于RNN 某一时刻的隐藏状态与它前一时刻的隐藏状态相关,导致其无法进行并行计算,因此训练速度相对CNN来说更慢;但也正是因为这个原因,RNN 可以保留长序列的隐藏信息,扩展到更长的序列,很适合序列建模,适用于许多NLP任务,比如:语言建模、机器翻译、语音识别等[24]。
2.3 拷贝机制
文本摘要由于受词表大小的影响,会出现OOV 问题。为了解决这个问题,Gu 等[25]提出了COPYNET 模型,模型在基于注意力的Seq2Seq 模型基础上,准确地组合选择使用COPY 模式和generate 模式,生成语义连贯的摘要,且摘要在ROUGE评估上的表现相对Hu等[18]提出的RNN、RNN content 模型有较大的提升。此外,See 等[26]提出Pointer-Generator 网络模型。该模型在标准的Seq2Seq 加注意力机制模型的基础上,通过指向(pointing)和生成(generating)两种模式把抽取式摘要和生成式摘要结合起来,并加入coverage 机制,在文本摘要领域取得较好的表现。Wang 等[4]提出Reinforced-Topic-ConvS2S 模型,该模型在基于卷积神经网络的Seq2Seq 框架(ConvS2S)[9]基础上引入主题模型注意力机制,并通过使用强化学习方法进行优化,使得通过模型产生的摘要具有更好的连贯性和多样性。
基于上述研究,本文结合CNN 与RNN 的优势,提出一种结合双注意力和指针覆盖机制的生成式摘要序列到序列模型。
3 双注意力和指针覆盖机制的生成式摘要模型
本文提出双注意力与指针覆盖结合的生成式摘要模型,其主要框架如图1所示。模型主要包含四个部分:隐藏特征提取器、编码器、解码器以及Pointer-Generator网络。

图1 双注意力和指针覆盖结合的生成式摘要模型
模型的隐藏特征提取器由词嵌入层、局部注意力层以及CNN 三个部分组成,抽取输入文本更高层次隐藏特征后输入编码器进行编码,然后将编码器最后一个RNN 单元的隐藏状态作为解码器的输入,进行解码工作,解码器最后一个解码步的输出作为模型的输出。各层主要说明如下:
(1)输入层:该层的输入是原文本序列,词与词之间通过空格分隔开来。
(2)词嵌入层:将输入层输入的文本转换为相应的词向量表示。
(3)局部注意力层:采用局部注意力机制,获取一定窗口范围内给定文本序列中相应词语的重要性,并根据其重要性赋予不同的权重值。在计算权重的过程中,为保证不丢失输入文本首尾两端的上下文信息,需要对首尾两端进行全0补齐(padding)操作。然后,输出输入序列通过局部注意力加权后的词向量表示。
(4)卷积层:卷积层将局部注意力层的输出词向量作为输入,与局部注意力层类似,卷积层也需要对词向量进行padding 来避免首尾两端文本的上下文信息丢失。同时,卷积层通过多个不同大小的卷积核,获取输入文本更深层次的n-gram 特征。最后,将各个特征映射串接起来,作为输入文本最终的词向量表示。
(5)编码器:编码器由双向LSTM神经网络组成,在t 时刻LSTM单元输出的隐藏状态为ht。
(6)具有注意力机制的解码器:解码器由单向LSTM组成,每个解码单元有两个输入:上一解码步的隐藏状态以及当前时间步文本序列的输入。解码器最初的隐藏状态通过编码器最后一个编码单元的隐藏状态hn进行初始化。“EOS”表示原文本终止符,同时也代表解码开始符。st表示第t 个解码步LSTM单元的隐藏状态,表示预测文本,yt-1则表示输入文本,在训练阶段,该文本是参考摘要的第t 个词,而在测试阶段由于没有参考摘要作为输入,则用前一解码步的预测输入代替,即在测试阶段
(7)Pointer-Generator网络:该网络是解码器中的一部分,attention weighted matrix 表示注意力加权矩阵,context vector 表示带注意力的上下文向量。 P( )w 表示当前时刻预测词为w 的概率,pgen是一个生成概率,表示该目标词是给定词表中词w 的概率,表示目标词是OOV词表中词w 的概率。
下面,将对模型各组成部分进行详细介绍。
3.1 隐藏特征提取器
3.1.1 词嵌入
对于输入文本s={w1,w2,…,wi,…,wn-1,wn},wi表示文本中第i 个词,n 表示文本长度。经过词嵌入层处理后,可以得到该文本的词嵌入表示矩阵X={x1,x2,…,xi,…,xn-1,xn},其中,xi∈ℝd,d 表示词嵌入的维度。
3.1.2 局部注意力
模型中的局部注意力模块可以学习给定词序列窗口中所有词提供的信息量的特征[27],使用局部注意力后,可以获得给定窗口范围内相对更重要的词的信息,并且保持输入序列中重要词语的相对位置不变。记表示长度为n 的文本的词嵌入。通过滑动内核将注意力应用到这个序列,用xi表示中心词,w 表示内核宽度,即局部注意力的窗口大小。最后,计算每个词的加权分数,Wl-att∈ℝw×d表示注意力权重,bl-att表示偏置,其均为学习参数。


其中,xni表示长度为n 的序列中第i 个词xi的加权词嵌入。
3.1.3 卷积神经网络
CNN 具有从输入文本中提取更多语境特征,获取文本局部信息的优点。为减轻生成摘要语句不通顺、语义不相关的问题,模型加入了CNN,并通过设置不同的卷积核大小来获取文本更多的n-gram特征。卷积神经网络一般有两个核心层,即卷积层和池化层。考虑到CNN 的池化层会丢失文本的位置信息,所以本模型中的CNN只采用卷积层,而没有使用池化层。图2展示了卷积神经网络对文本的处理过程。

图2 卷积神经网络对文本的处理
卷积层的输入是上一个局部注意力层的输出。输入文本经过局部注意力处理后,得到注意力加权嵌入矩阵Xn∈ℝn×d。假设用xi:i+j表示向量xi,xi+1,…,xj的串接,卷积过滤器用k ∈ℝh×d表示,h 为一个卷积窗口中词的个数,那么使用词xi:i+h-1生成的特征ci可由如下公式表示:

其中,b ∈ℝ 是一个偏置项,f 是一个非线性激活函数tanh。将过滤器应用到整个嵌入矩阵,得到文本在该过滤器下的特征映射C。

在局部注意力层和卷积层,为了确保嵌入尺寸大小不变,所以在每层矩阵的边界上进行了全0 填充(zeropadding)的操作,以保证各层向前传播结果的矩阵大小与当前层的矩阵大小一致。
为了获得文本更多层次的n-gram 特征,模型采用了多个不同大小的卷积核,最后串接各个特征映射并将其作为输入文本的特征表示。假设共有j 个不同大小的卷积核,则最终的特征矩阵F 可记作:

3.2 结合注意力的序列到序列模型
模型的encoder-decoder部分以Nallapati等[17]提出模型作为baseline,其中,encoder 部分使用双向LSTM,decoder部分使用单向LSTM。
LSTM 在简单RNN 模型的基础上添加了一个遗忘门(forget gate),使其更易于学习长期依赖[28]。它由输入门(input gate)、遗忘门和输出门(output gate)三个部分组成,并通过下面等式组合这三个门来计算t 时刻隐藏状态:
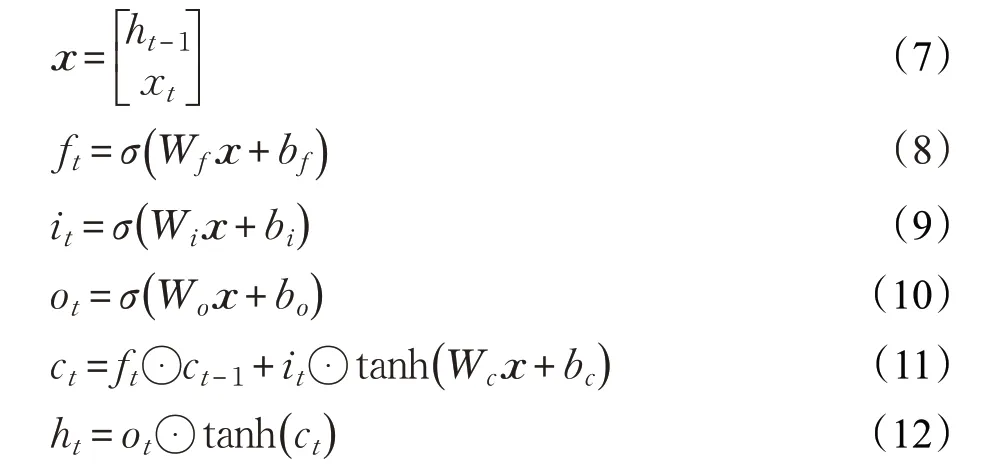
ft代表遗忘门,it代表输入门,ot代表输出门,ct表示上下文,ht表示LSTM 当前时刻的输出。Wf、Wi、Wo、Wc分别是遗忘门、输入门、输出门、上下文权重,bf、bi、bo、bc分别是遗忘门、输入门、输出门、上下文偏置,σ 是sigmoid非线性函数。
在编码阶段,模型使用双向的LSTM计算输入序列的隐藏状态h ,记输入序列的第t 个词的隐藏状态为ht,其前向和反向隐藏状态分别用, 表示向量连接运算符,则t 时刻隐藏状态为因此,每个解码器的隐藏状态ht是对文本中第t 个词和其上下文信息编码后的结果[29]。
在解码器中,模型加入注意力机制并使用单向的LSTM。在每个解码时间步t ,编码器隐藏状态hj与第t 个目标词相关性权重etj由解码器前一时刻的隐藏状态st-1,当前时刻的输入文本yt-1(在模型的训练阶段,yt-1是参考摘要中相应的词;在测试阶段,则是解码器t-1 时刻的输出,见图1 中解码器部分)和hj共同计算得出:

其中f 是一个非线性函数。然后,使用softmax 回归处理etj,得到第j 个词的注意力权重:

由atj可以计算得到第t 个目标词的带注意力的上下文向量ct:

通过LSTM 单元计算出当前时刻解码器的隐藏状态st:

生成目标词的概率计算如下:
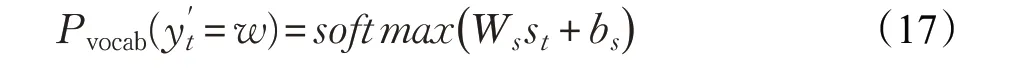
3.3 pointer-generator网络
生成式摘要模型对输入文本进行编码,将文本中的词转换为向量形式提取语言特征,然后再进行解码将词嵌入转换为文本。在这个过程中,模型可能会生成新词,这些词既不在词表中,也没有在原文本中出现过,或者在原文本中出现过,但由于受词表大小的限制,不在模型使用的词汇表中,这就导致OOV 问题的形成。为了解决受词表大小影响而产生的OOV 问题,模型采用了pointer-generator 网络,该网络可以通过pointing 机制从原文本中复制词,同时,也可以从给定的词表中生成词。对于解码时间步t 来说,它的生成概率是由当前时刻解码器输入xt、隐藏状态st以及上下文向量ct计算得出:

其中,Wc、Ws、Wx分别是上下文权重、隐藏状态权重、输入权重,bgen为偏置项,σ 是sigmoid 非线性函数。pgen可以看成是生成一个词表中的词,或通过注意力分布at从输入文本中复制一个词的软开关。对于每一个输入文本都有一个OOV 扩展词表,该词表用于存储该文本所有不在给定词表中的未登录词。引入OOV词表后,解码时间步t 生成目标词w 的概率计算公式如下:

在生成目标词概率计算中,假如当前时刻的生成词是一个未登录词,则Pvocab( )w =0;类似的,假如生成词没有在原文本中出现过,且不在词表中则P这时,生成词用“[UNK]”表示。
3.4 覆盖机制
句内重复是Seq2Seq模型中常见的问题,特别是在生成多句子的长文本任务中尤为常见[26],为解决这个问题,模型引入coverage机制。
首先,记第t 个解码步之前所有解码步的注意力分布之和为覆盖向量covt:

covt表示到第t 个解码步为止,已经被注意力机制覆盖到的源文本的向量表示。由于在解码步t=0 时还没有文本被读取覆盖,所以,在这个解码步的覆盖向量cov0是一个0向量。
随后,将covt作为注意力机制的一个附加的输入内容,因此,公式(13)被更新为:

最后,为了避免在同一个摘要句子中生成重复的词,模型采用如下的方式来更新计算t 时刻的总损失losst:

其中,cov_losst表示覆盖损失,用来惩罚同一位置反复出现的情况,wt表示第t 个时间步的目标词,表示在当前时刻的目标损失值,λ 参数的默认值为1.0。
4 实验分析
4.1 数据集
本文使用近年来广泛应用于自动文本摘要任务的CNN/Daily Mail 数据集作为评测数据集。该数据集最初应用在机器阅读理解任务中[30],后由Nallapati 等[17]整理并应用于文本摘要任务。它包含286 817 对训练集,13 368 对验证集,以及11 487 对测试集,每个原文本对应多个摘要句子。训练集中的源文档平均每个文档包含766个词,29.74个句子;相对应的摘要平均包含53个词和3.72 个句子。文献[26]提供了该数据集的处理脚本(https://github.com/abisee/cnn-dailymail),为了与之具有可比性,所以本文也采用了该脚本进行CNN/Daily Mail数据集预处理,并获得数据的未标记版本。
4.2 评价标准
与Nallapati等人[17]在论文中采用的评价标准相同,本文的文本摘要质量采用ROUGE[31]评估中ROUGE-1、ROUGE-2 和ROUGE-L 的F1 值进行评估,分值由ROUGE 摘要评估包的Python 包装器pyrouge(https://pypi.org/project/pyrouge/)计算得到,该包装器为官方的ROUGE评估提供了一个简单可用的接口。
4.3 参数设置
文献[32]指出,模型使用词表大小为150 000 相对词表大小为50 000 来说,时间成本增加了一倍,但其测试表现分数却略有下降。另外,由于模型使用了两个编码器,所以最终模型使用词表大小为40 000,模型表现相对baseline 仍有提升。综上,考虑到本文模型使用了局部注意力和卷积神经网络,本模型的词表大小也设置为40 000。
此外,在模型的实验过程中,其他参数设置如下:词向量的维度为128,编码器隐藏层维度为200,解码器隐藏层维度大小为400。模型使用AdagradOptimizer优化器,学习率的初始值设置为0.03,增量器初始值(initial_accumulator_value)设为0.1。局部注意力窗口大小为5,卷积神经网络相关参数如表1。

表1 卷积神经网络相关参数设置
在训练阶段batch 大小设置为32;为减少验证过程所需的内存空间,并使训练和验证在同一个GPU 中运行,在验证阶段,将批次大小设置为8,但对于每个验证步,都迭代验证数据100次,这类似于在批次大小为800的数据基础上寻找验证误差。集束搜索(beam search)大小设置为4。对于所有随机初始化的参数变量,都满足标准差为1E-4的正态分布。
CNN/Daily Mail 数据集中的每一对数据由一篇文章和一个多句子的摘要组成。在实验过程中,只取文章的前400 个词,并将摘要限制到100 个词。在测试模式下,采用beam search算法生成至少40个词。
4.4 模型说明
本文以基于注意力的Seq2Seq模型为baseline,结合局部注意力、卷积神经网络、pointer-generator网络,以及coverage 机制来解决现有文本摘要模型存在的句内重复、OOV 问题。为验证模型的效果,在实验中,与多个目前表现较好的模型效果进行了验证比较。
4.4.1 对比模型
Seq2Seq+Attn:融合注意力与encoder-decoder 的基线模型。
abstractive model[17]:模型在基线模型的基础上加入时空注意力(Temporal Attention),防止解码器重复关注已生成文本内容,解决在长文本的多句子摘要中生成重复句子的问题。
pointer-generator[26]:模型将基线模型与指针网络结合,允许通过指向从原文本中复制词,也可以从一个定长词汇表中生成词。
pointer-generator+coverage[26]:该模型在pointer-generator基础上加入coverage机制,对解码器重复关注同一位置信息的情况进行惩罚,生成重复的文本。
WordNet+Dual-attn+PGN+Cov[32]:模型基于WordNet句子排名算法抽取重要句子,融合抽取式摘要与生成式摘要方法,并引入pointer-generator 网络和coverage 机制,在CNN/Daily Mail数据集上进行实验,取得良好的效果。
ML+RL+Intra-attn[19]:模型在最初的encoder-decoder模型基础上引入内注意力(intra-attention)机制,并首次将强化学习应用到长文本摘要任务中,结合监督学习方法对目标函数进行混合训练。
RL+Intra-attn[19]:在序列到序列模型中使用内部注意力机制,采用强化学习方法训练目标函数。
4.4.2 本文提出的模型
DAPC-1:模型以pointer-generator 模型为基础,在词嵌入层后,encoder之前加入一个局部注意力层,提取文本的局部重要性特征信息。
DAPC-2:模型以pointer-generator 模型为基础,在词嵌入层后,encoder之前加入一个卷积层,以获取输入文本更深层次的隐藏n-gram语言特征。
DAPC-3:在DAPC-1模型基础上,局部注意力层之后,encoder层之前加入卷积层,综合考虑文本信息的重要性和深层隐藏特征,对输入文本进行建模。
DAPC-4:在DAPC-3 模型基础上,加入coverage 机制,在每个解码步防止重复关注相同信息。
4.5 实验结果
实验结果如表2 所示。表中部分模型带有下标“a”,表示该模型的数据集采用的是具有命名实体和数字标注处理的CNN/Daily Mail 数据集;其他则是在未标注处理的数据集进行实验的结果。黑色加粗数字表明模型的最好效果。
表2 的实验结果表明,在本文提出的四个模型中,DAPC-4 模型在ROUGE-1、ROUGE-2、ROUGE-L 三项指标中都取得最好的效果。
本文提出的四个模型表现效果,相对Seq2Seq+Attn及abstractive model 均有大幅提升;DAPC-1、DAPC-2、DAPC-3、DAPC-4四个模型在pointer-generator模型基础上进行改进,从ROUGE评分来看,相对pointer-generator模型来说,DAPC-2 模型的ROUGE-1 指标得分提高了0.35 个百分点,ROUGE-2 评分提高了0.18 个百分点,DAPC-1、DAPC-3、DAPC-4三个模型在三个指标上的得分均有不同程度提升。
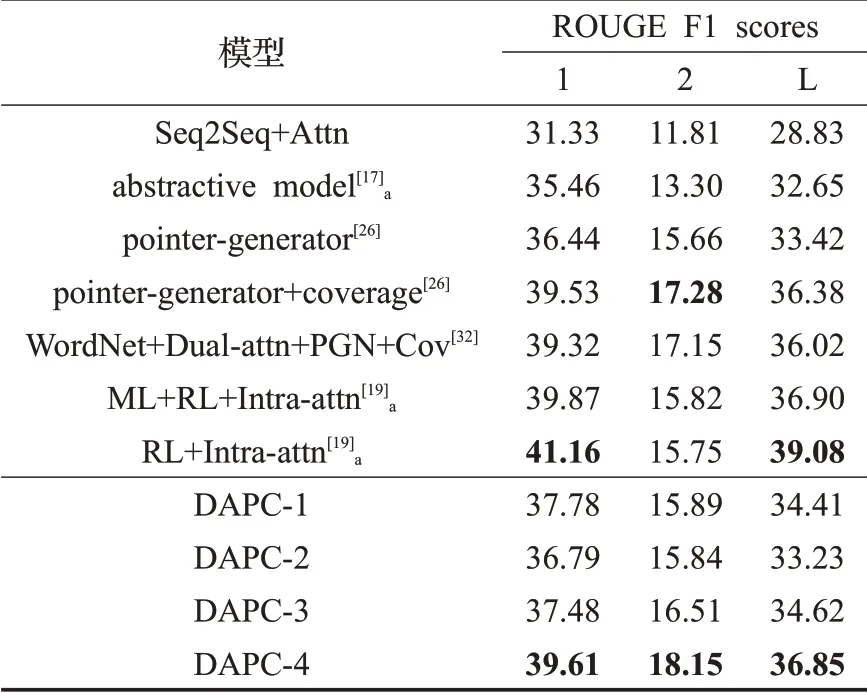
表2 实验结果对比
与文献[19]中提出的引入强化学习训练方法的模型结果相比,尽管本文提出模型在ROUGE-1、ROUGE-L标准下没有其表现效果好,但在ROUGE-2评价指标上,本文提出的模型表现效果均比其表现效果好,特别是DAPC-4 模型在ROUGE-2 评价指标下相比其最好得分提升了2.33 个百分点。分析原因,可能与RL 模型使用的是带有标注处理的CNN/Daily Mail数据集有关。
与文献[32]中的模型相比,DAPC-4模型在ROUGE-1、ROUGE-2、ROUGE-L三个指标上分别提升0.29%、1%、0.83%。数据表明,使用局部注意力与卷积相结合相对先对文本做抽取式摘要再编码的方法而言,其能更有效地提取原文本的重点信息和深层语言特征,减轻非重点信息对重要信息的稀释作用,从而提升文本摘要质量。值得注意的是,与文献[17,19,26,32]模型相比,本文提出的DAPC-4 模型具有最好的ROUGE-2 表现,相比之前最好的模型提升了0.87个百分点。
4.6 案例分析
图3展示了模型生成的一个摘要样例。从图3可以看出,模型生成的摘要文本语义连贯,没有句内重复及OOV 词,且生成了新词“beat”,对原文内容方面有较好的覆盖,与参考摘要相似,总体表现良好。
5 结语

图3 生成摘要案例
针对目前基于深度学习的生成式文本摘要方法存在语句不通顺、句内重复以及未登录词问题,研究提出了基于双层注意力的Seq2Seq 文本摘要模型。该模型集成了注意力机制、CNN 以及RNN 在处理文本方面的优势,与pointer-generator 网络和coverage 机制相结合,在不带标签的CNN/Daily Mail数据集上进行文本摘要任务,取得了良好的效果。下一步,将进一步对模型进行改进,引入强化学习机制,解决exposure bias问题;此外,还考虑将该模型在中文数据集中进行实验验证,提升对多语言的通用性。
