基于形状特征和SVM多分类的铜仁地区茶叶病害识别研究
2020-04-23黄太远李旺邱亚西余小波
黄太远 李旺 邱亚西 余小波

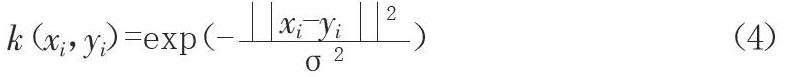

摘 要:针对茶叶常见叶部病斑图像的形状特点,将机器学习应用于茶叶病害识别当中。以茶叶3种常见病害作为研究对象,运用支持向量机方法进行分类识别研究,对有病害的茶叶图像进行处理和特征提取,利用径向基核函数进行分类来提高茶叶病害识别率。运用分类识别方法对茶叶病害进行研究,使茶叶在发病初期就能得到更好的预防以及后期能保证茶叶的质量和产量,提高当地茶叶的销量,促进经济发展。
关键词:形状特征;SVM多分类;茶叶病害;识别
文章编号: 1005-2690(2020)06-0007-02 中图分类号: TP391.41;S435.711 文献标志码: B
目前,铜仁市在栽茶和茶叶的病害处理方面还很薄弱,小部分做得较好一些的只有私人茶园,且采摘量只占全年总产量的40%左右[1],大多数茶叶在树上老化或被虫子、病菌感染发生了病变,茶叶的利用率低。而茶叶作为铜仁茶农的主要经济来源,以茶叶病害为研究对象,对茶叶叶部病斑进行图像预处理,然后提取其病斑部分的形状特征,对提取的特征数据利用支持向量机分类方法训练得出分类模型,对茶叶的常见病害进行分类识别,以提高识别率,可促进计算机智能识别在农业中的应用。
1 支持向量
支持向量机[2-4](Support Vector Machine,SVM)是一种将数据进行分类后的算法,而SVM通常用于二元分类学习,对于多元的主要是将其分为多个二元来解决数据分类。
数据的分类主要有线性可分、非线性可分两类。为了能让两类正确分离且它们距离最大的分类平面成为最佳超平面,其方程为:
式中,ω表示分离超平面的法向量,b表示截距,位于分离超平面之上的样本为正样本,之下的为负样本。
本文利用径向基核函数[5-7](Radial Basis Function Kernel)将提取出来的数据进行分类识别,RBF函数具有很强的灵活性,与其他的核函数相比参数较少。因此,大多数情况下,通过计算机计算时会比其他核函数的效率更高、运算速度更快、性能更好。下面就是径向基RBF核函数形式:
2 茶叶病害图像特征提取
茶叶病害图像包含了丰富的特征信息,如图1所示。例如,形状特征和纹理特征[8-10],按照形状分类的现有技术,本文利用茶叶病害部位的轮廓、凸凸和最小包围盒得到形状描述[11-12],利用这些形状的相關数据计算出面积、矩形度、周长凹凸比、面积凹凸比、茶叶病害部位的伸长度和茶叶病害部位的圆度6种相对形态参数来提取所需的数据。
本文先提取茶叶病害部位的外部轮廓,通过采用轮廓跟踪法对茶叶病害图像进行轮廓提取,具体算法步骤如下。
(1)对图像预处理后的茶叶病害二值化图像采用自顶向下、从左到右的顺序进行扫描,得到第一个像素点为1的点,此时将其作为起始点。
(2)通过步骤(1)得到起始点后,反方向查找此时该像素点在其8个方向上的领域点,若查找到该像素值为1的点且领域上包含0像素点,若该像素点在之前没有被查找过,则将这个像素点作为当前点,并记下对应的链码值。
(3)重复步骤(2),直到回到起始点。
(4)根据步骤(2)和(3)所记录的链码值,得到茶叶病害部位的形状轮廓。
根据以上步骤提取茶叶病斑的数据见表1和表2。
3 试验过程及结果分析
试验环境是MATLAB2017b,利用SVM进行分类。在试验过程中用到libsvm工具包进行测试和分类,先建立分类模型,然后利用得到的这个模型进行分类。本次试验总共选取了102个特征数据样本,然后随机抽取部分特征数据作为训练数据,再用剩下的特征数据作为测试数据。分析过程如下。试验结果如图2所示。
利用训练数据建立模型:
Model=svmtrain(trains_label,Trains_matrix,cmd)
其中svmtrain是模型训练函数,trains_label为训练样本类别,Trains_matrix为归一化后的训练样本的特征值,cmd为返回的模型值。
利用建立好的模型放在训练数据上的分类效果:
[predicts_label_1,accuracys_1,acc]=svmpredict(trains_label,Trains_matrix,Model)
result_1=[trains_label,predicts_label_1]
其中svmpredict是对测试集进行预测,accuracy_1是分类的预测准确度,通过有监督的测试集值和预测值求百分比。
图2a是在102个特征数据中选取40个进行分类训练及创建模型,再将62个特征数据作为测试样本进行茶叶病害分类识别,得出的结果为87.10%。图2b是在原本的基础上选取50个进行分类训练及创建模型,再将52个特征数据作为测试样本进行茶叶病害分类识别,得出的结果为90.38%。图2c是在图2b的基础上增加了10个特征数据(即选取60个进行分类训练及创建模型),再将42个特征数据作为测试样本进行茶叶病害分类识别,得出的结果为90.48%。图2d同图2c一样,选取70个特征数据进行分类训练及创建模型,再将32个特征数据作为测试样本进行茶叶病害分类识别,最后得出的结果为93.75%。
综上所述,样本数量一定的时候所选取的训练样本越多,识别率就越高。当训练数据和测试的比例达到一定值时,识别率将会在某一范围波动,就像本试验的数据结果,当训练样本达到一定的时候,识别精度就会在90.43%上波动。所以通过SVM分类器识别,具有识别率高、范围广等特点,可以有效地解决人工在监控茶叶的过程中保证了茶叶的质量和控制疾病的感染。
4 结语
由于茶农对茶叶病害识别存在:主要依靠经验(主观、局限、模糊),凭感觉对茶叶病害进行诊断,往往在茶叶的感染程度较严重时肉眼才能识别,很难做到“对症下药”和及时防治,而且可能造成农药超标,影响茶叶的质量。现提供一种基于人工智能(图像处理和SVM分类)对茶叶常见病害进行识别方法研究,以提高识别率。选取适合于茶叶病害的分类识别方法,促进计算机智能识别技术在农业中的应用。
参考文献:
[ 1 ] 徐代刚.铜仁市茶产业发展分析[J].中国茶叶,2018,40(1):29-33.
[ 2 ] 刘衍琦,詹福宇,蒋献文,等.MATLAB计算机视觉与深度学习实战[M].北京:电子工业出版社,2017.
[ 3 ] 卓金武.MATLAB在数学建模中的应用[M].北京:北京航空航天大学出版社,2014.
[ 4 ] Duan Li,Ruizheng Shi,Ni Yao,et al.Real-Time Patient-Specific ECG Arrhythmia Detection by Quantum Genetic Algorithm of Least Squares Twin SVM[J/OL].Journal of Beijing Institute of Technology:1-10[2019-12-22].
[ 5 ] M. Dirbaz,T. Allahviranloo. Fuzzy multiquadric radial basis functions for solving fuzzy partial differential equations[J].Computational and Applied Mathematics,2019,38(4).
[ 6 ] 魏鋒涛,卢凤仪.融合核函数在改进径向基代理模型中的应用[J].计算机工程与应用,2019,55(7):58-65.
[ 7 ] 陈瑶.基于径向基网络和支持向量机算法的板形缺陷识别的研究[D].天津:河北工业大学,2015.
[ 8 ] Jiao Yin,Jinli Cao,Siuly Siuly,et al.An Integrated MCI Detection Framework Based on Spectral-temporal Analysis[J].International Journal of Automation and Computing,2019,16(6):786-799.
[ 9 ] 欧利松.基于SVM的人脸识别系统设计与改进[J].网络安全技术与应用,2019(12):58-60.
[ 10 ] 周凯红,乔新新,李福敏.基于支持向量机的彩色图像分割研究[J].现代电子技术,2019,42(18):103-106,111.
[ 11 ] 郭志强,胡永武,刘鹏,等.基于特征融合的室外天气图像分类[J/OL].计算机应用:1-10[2019-12-22].
[ 12 ] 王艳玲,张宏立,刘庆飞,等.基于迁移学习的番茄叶片病害图像分类[J].中国农业大学学报,2019,24(6):124-130.