基于网络爬虫的网络平台用户数据获取与分析
2020-04-20李世杰高雅蓉
李世杰 高雅蓉
摘要:社交网络平台拥有海量的用户数据,为了更好地实现这些数据的价值,设计了一个基于Java的网络爬虫系統,用来获取和分析某大型社交网络平台上的用户数据。该系统通过特定用户的URL来获取基本信息,不断裂变获取相关用户的数据信息。同时将该用户信息以记录的形式存储在用户明细表中,利用系统对记录信息的分析,得出不同类别的图表分析图,并直观地进行展示。该系统具有针对性强、数据采集速度快和分析结果直观等优点,为社会关系和舆情分析等研究提供了新方法。
关键词:网络爬虫;用户数据;Java;裂变
中图分类号:TP391文献标志码:A文章编号:1008-1739(2020)01-68-4

0引言
近年来,社交网络平台的发展极为迅速,目前已经出现多个用户突破1亿的平台,拥有非常庞大的用户数据,所以有效获取和分析这些数据对于研究人类社会和经济的潜在规律至关重要。传统的数据收集是通过搜索引擎来进行的,但是对具体平台进行特定数据抓取时,通过搜索引擎就无法有效完成,需要设计专门的网络爬虫系统来获取特定数据。Python语言常被用于爬虫程序编写,但相比Java而言,Python的执行效率低,而且Java语言对多线程的支持更加完善[1]。针对某大型社交网络平台设计了基于Java语言的网络爬虫系统,爬取该平台用户的相关信息。同时为了更好地进行数据分析,系统可以从多角度对所获得的用户数据进行统计,并以直观的图表形式呈现。
1网络爬虫技术
网络爬虫技术是数据信息采集的常用手段,由于其自动化、拓展性强和开发相对简单等优势,被普遍应用于各行各业的数据模型分析[2]。通过网页的链接地址,获取其中传递的数据信息,自动检索页面数据模型,根据定义好的字段筛选数据获得数据资源。网络爬虫将每一条链接存储在队列中,一个个调用,当链接被使用后自动废弃,同时将每条链接上爬取的数据存储在数据库中,供用户使用。
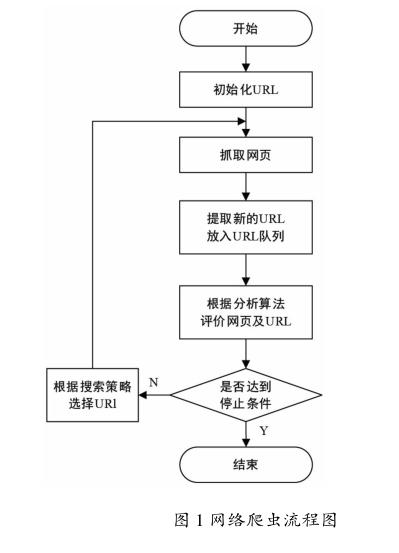
通过算法来优化数据爬取的方式,如广度优先搜索策略,以最短的路径爬取深层次的资源数据,减少数据搜集成本[3]。具体过程是首先确定少部分URL作为子结点,存储在待抓取的URL队列中,然后到对应的URL站点下载相应的页面数据信息,当这些URL被抓取成功后,把它们放入已经抓取的URL队列中,然后再抽出新的链接地址,进行页面数据挖掘。流程如图1所示。
2 WebMagic
WebMagic是基于Java的一个爬虫框架,核心部分主要是爬虫的具体逻辑实现,除此以外还有一部分拓展功能,帮助用户实现个性化需求[4]。WebMagicp爬虫框架主要有四大组件,由Spider进行串联,网络爬虫中的下载、处理和管理等功能都是由四大组件来负责,彼此之间交叉联系,整体功能设计更趋向流程化的规范[5]。而Spider可以被认为是该框架的一个大容器,保存最核心的模块。
3反反爬虫机制
为了防止用户数据被用于非法用途,许多网站都采取反爬机制,阻止别人批量获取网站信息,并且反爬机制也在不断完善。为了能够成功获取平台上的用户数据,提出以下几种反反爬策略:
①动态更改user-agent,通过用户代理让服务器认为每次请求是来自不同的浏览器。
②通过获取一定数量的代理IP地址,达到每次请求连接服务器都是来自不同的IP地址的目的,这样可以迷惑服务器,让服务器无法确定具体的访问IP[6]。
③对系统的数据爬取频率过快的话,容易造成账户被封禁,所以要对爬取速率进行控制[7]。
④建立并维护cookie池,所以更保险的方法是多获取几个cookie,每次请求随机设定一个cookie[8]。
4系统实现
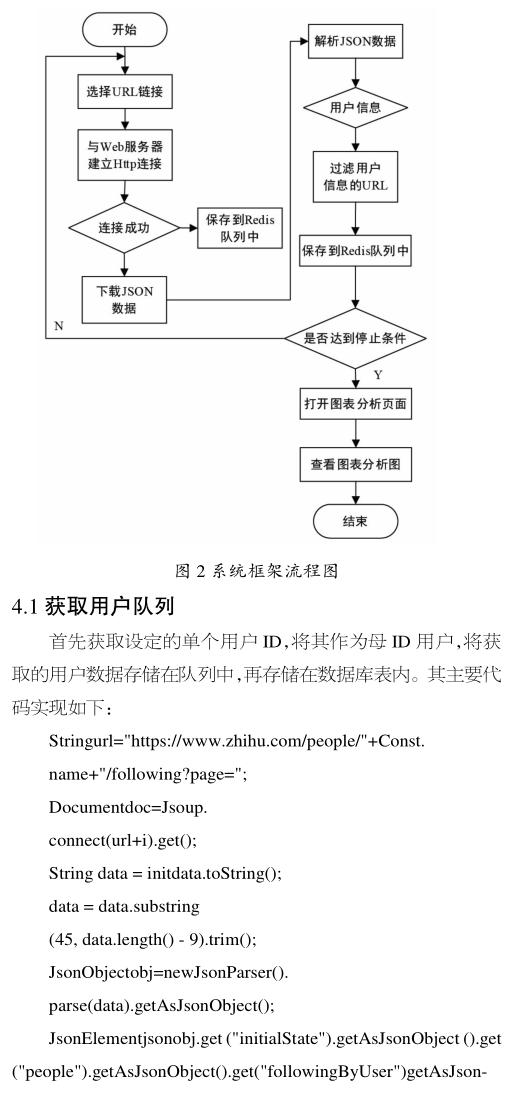
本文所设计的爬虫系统是针对社交网络平台的用户数据,目的是对用户个人数据的获取与分析。实现过程是以一个用户为基准,然后不断进行裂变,再对所爬取数据统计以直观图的形式呈现,进而得到有效合理的分析,系统框架流程图如图2所示。

从图3可以看出,系统可以有效地爬取社交网络平台用户的各项数据,包括性别、地域、从事行业以及毕业学校等信息,而且信息都清楚地进行分类展示,为下一步数据分析提供了极大的便利。
4.4对用户数据进行统计分析
由于获取到的数据庞大且复杂,为了更好地进行数据分析,系统可以从多角度对所获得的用户数据进行统计,比如男女比例、地域分布和从事的行业等,并以直观的图表形式呈现,以性别为例,如图4所示。
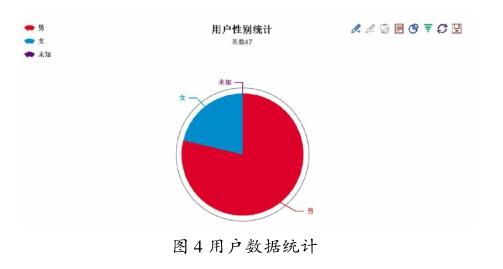
通过数据结果可以看出,目前该社交网络平台的大部分用户在北上两地,男性居多,行业都是目前主流的行当,例如互联网、金融及计算机等,同时人群的普遍学历较高。这些数据可以作为该社交网络平台发布广告的一个侧重点,发布符合年轻化、学历高并且处于热门的一些广告内容,同时一些大数据分析公司可以借此获取更多的数据,进而分析当前年轻人的喜好,为用户提供更精准和优质的服务。
5结束语
本文研究网絡爬虫的广度优先搜索策略,通过一个用户的关注信息来裂变,不断进行新用户的数据信息挖掘,并利用Java语言实现对社交网络平台用户数据的获取和分析。通过获取到的该平台用户信息,包括男女比例、地域分布以及学历程度等,不仅可以作为社交网络平台对其用户精准定位,提供更优质服务,同时可以为一些大数据分析公司服务,为舆情分析和促进社会关系等研究提供便利。
参考文献
[1]邵晓文.多线程并发网络爬虫的设计与实现[J].现代计算机(专业版),2019(1):97-100.
[2]蔡创.计算机软件开发中JAVA编程语言的分析和思考[J].信息技术与信息化,2017(12):80-81.
[3] HERNANDEZI, RIVERO CR, RUIZD, et al. AnArchitecture for Efficient Web Crawling[J].Lecture Notes in Business Information Processing,2012: 228-234.
[4] RAFAEL P L,PEDRO B V,OTTO C M B.A Generalized Bloom Filter to Secure Distributed Network Applications[J]. Computer Networks,2011, 55(8):1804-1819.
[5] KAUSAR M A,DHAKA V S,SINGH S K.Web Crawler:A Review[J].International Journal of Computer Applications, 2013,63(2):31-36.
[6]罗咪.基于Python的新浪微博用户数据获取技术[J].电子世界,2018(5):138-139.
[7] FAN Y.Design and Implementation of Distributed Crawler System Based on Scrapy[J].Journal of Hubei University for Nationalities,2017:78-85.
[8]董博,翀李,刘学敏,等.基于爬虫的数据监控系统[J].计算机系统应用,2017,26(10):53-60.
