人工智能能力平台建设思路
2020-04-20山东张誌张延彬邢庆文杨滨
■山东 张誌 张延彬 邢庆文 杨滨
运营商人工智能能力平台应包括如下部分:
1.硬件基础设施,包括各类服务器及网络设备。
2.IaaS 层能力,包括各类资源的虚拟化、租户管理能力、资源调度能力。
3.PaaS 层能力,包括各类基础软件包、运行环境、算法框架等开发环境,以及面向图像识别、人脸识别、语义理解、语音识别、语义理解、语音合成等基础能力服务,以便于上层应用进行调用及集成。
4.SaaS层能力,提供面向智慧营业厅、智能基站巡检等业务场景的成型解决方案,供不同使用单位(租户)按需进行调用。同时,人工智能能力平台还需与外部人工智能开放平台进行衔接,以获取相关训练数据、调用外部既有能力等。人工智能能力平台整体架构如图1 所示。
基础设施层建设思路

图1 人工智能能力平台总体架构
近年来人工智能特别是深度学习的崛起,与计算能力的突飞猛进关系密切。而引领计算能力飞速提升的、则是异构计算的发展。异构计算,主要指不同类型的指令集和体系架构的计算单元组成的系统的计算方式,目前主要的异构计算平台包括“CPU+GPU”、“CPU+FPGA”、“CPU+ASIC”架构。相较于纯CPU 的计算平台,异构计算平台带来了数十甚至上百倍的性能提升、同时带来数十倍的能效提升。各类计算平台特点说明如表1 所示。
考虑到运营商所面对AI 业务场景的多样化,需要根据不同场景选择相应的AI 算法,例如图像识别场景与语义分析场景所适用的AI 算法存在较大差别,因此需要更为通用的硬件计算平台;同时,需考虑运营商现有的自研能力与业界前沿的互联网厂家有较大差距,因此需要优先选择较为成熟的商业化产品,借助业界研发力量、满足自身业务需求。

表1 各类AI 计算平台特点比较
综上考虑,虽然“CPU+FPGA”、“CPU+ASIC”架构在性能、能效比方面具备优势,但也需要非常强的算法甚至芯片级的自研能力,而这些能力并非运营商优势领域,因此建议在计算平台选择时,总体优先考虑“CPU+GPU”架构平台,尤其是在训练场景;随着5G 发展,未来可以在自动驾驶等实时性要求非常高的推理场景考虑引入“CPU+ASIC”等架构,以提供更高的计算性能、降低时延。
就“CPU+GPU”架构平台而言,目前业界产品主要以GPU 服务器方式提供,包括NVIDIA 原厂DGX 服务器,以及服务器厂商采购NVIDIA GPU 卡、并进行OEM 的GPU 服务器。相比较来看,NVIDIA原厂DGX 服务器使用了更高效的NV-Link 总线接口,单服务器内部各GPU 可以做到全线速互连,并随服务器配置了专门优化的操作系统、驱动程序、开发包等软件,性能相比OEM 服务器更高,预置功能也比较全面,但其价格也相应的远超OEM 服务器。运营商在设备选型时,应综合衡量性能与价格,选择适合自身需求的产品。
目前GPU 服务器单台最多支持16 块NVIDIA V100 GPU 卡,如存在超出单台GPU服务器处理能力的需求,可考虑将多台GPU 服务器通过外部网络进行互连、组成计算集群。外部互连网络可选择40Gbps 以上高速以太网、或Infiniband 网络。从集群总体性能来看,同一GPU板卡内通信速率在1000Gbps级别、同一服务器内速率在300Gbps 级别,而服务器间通信速率在100Gbps 以下,因此网络接口为GPU 服务器集群的主要性能瓶颈;同时,网络协议的处理也将占用大量的系统资源、造成相应的延迟,因此需要选择端口速率高、网络协议简单的组网方案。
对比以太网与Infiniband 网络,后者协议更加简单,且在主流商用网卡产品情况下端口速率更高,在构建GPU 服务器集群时应优先选择Infiniband网络进行组网。
IaaS 层建设思路
IaaS 层主要提供对GPU服务器资源的管理及分配能力,从资源层面对GPU 服务器进行虚拟化,供多个租户按需使用,并对租户进行资源的分配、管理以及资源的回收。
在构建IaaS 能力时,可考虑与运营商现有云管平台进行融合复用,即将GPU 服务器部署于企业现有私有云资源池内,通过资源池的OpenStack 平台进行统一管理,主要通过Nova 进行资源的分配、管理、调度、回收等工作。管理过程如图2 所示。
其中GPU 资源将作为PCI 设备随虚拟机分配过程一并分配给租户使用。从虚拟化对PCI 的模拟分配方式来说,为虚拟机配置GPU 包括直通、分享、GPU 虚拟化三种方式。
1.直通模式:通过PCI的透传由客户机进行GPU 独占。
2.共享模式:PCI 设备由客户虚拟机和物理机共享。

图2 云管平台统一纳管GPU 服务器
3.GPU 虚拟化:类似于CPU 的虚拟化功能、GPU 自身支持虚拟化功能,例如NVIDIA 最新推出的vComputeServer 功能,与VMWare、KVM 等虚拟化软件进行结合,在做到资源细粒度分享的同时、还提供vGPU 随虚拟机迁移的能力。
从性能来说,直通模式性能接近于GPU服务器裸机性能,性能损耗低于5%,是目前主要的资源配置方式;NVIDIA 最新的GPU 虚拟化方式目前尚未大规模商用,根据其宣称性能也接近于裸机模式,但需要额外采购其vComputeServer 软件;而共享模式由于存在设备模拟和转换的过程,性能损耗较大,不建议使用。
从配置灵活性来说,直通模式只能提供板卡级资源粒度划分,即只能将1 块或多块GPU 分配给单个虚拟机;GPU 虚拟化模式则可以提供更细粒度的资源,相对来说更贴合客户需求、资源利用率更高。
从业务场景来说,深度学习的训练过程因计算量较大,一般采用GPU 服务器裸机模式、或虚拟机GPU 直通模式;而推理过程则可使用GPU 虚拟化模式,将GPU 资源尽量分配给更多租户使用,以提升资源利用率,并增强资源配置的灵活性。
引入虚拟化能力更多是为了给租户提供资源隔离能力、并提升管理便利性。在IaaS 构建时,还需要考虑引入容器技术,用于算法库、算法框架等开发环境的封装,IaaS 需提供对容器镜像的管理能力,包括镜像制作、下发,容器的启动、运行、管理、回收等能力。
PaaS 层建设思路
PaaS 层应提供两大类能力,即提供快速、实时服务能力的AI 能力,以及用于非实时、大数据量训练的算法框架。前者主要是将成熟的语音、语义、视觉能力进行固化、服务化,为前端应用提供标准的程序接口、开发包,供各业务场景快速调用、集成,形成相应的AI 能力;后者则主要负责深度神经网络模型的训练,基于运营商自有的海量数据,提供针对业务场景定制的深度神经网络模型训练算法,并将训练成型的模型输出给前者,供前台应用调用。
在算法框架选择方面,既需要提供GPU 底层的CUDA等编程框架、cuDNN 等加速库,也需要提供深度学习相关算法框架,以降低开发门槛、加速业务实现进度。目前主流的深度学习算法框架包括TensorFlow、Caffe 等,各类框架对比如表2 所示。其中TensorFlow 已成为近年最为流行的算法框架,但不同的框架适用的领域不完全一致,各有优劣,因此在平台构建时,应考虑多种主流模型的预置,并根据后续实际需求不断补充。
接口层建设思路
主要包括PaaS 层对外提供AI 服务能力的相关接口、与运营商大数据平台对接接口,以及与外部优势AI 厂家合作的程序或数据接口。
PaaS 层对外提供AI 服务能力的相关接口包括多种形式接口,例如可供上层应用直接调用的应用程序开发接口,接收外部数据输入的接口等。该接口是最终使用用户与人工智能能力平台交互的接口。
大数据平台对接接口则用于从运营商自建大数据平台获取相关训练用原始数据,例如长期存储的账单、详单、网管记录信息等反应用户画像的相关数据,业务受理单、用户身份证等图像数据,客服受理记录等原始语音数据,以及集中性能平台等网络类大数据平台存储的网元相关性能、故障、配置、优化等数据,通过训练得到相应模型,用于客户服务、市场营销、网络智能化运维及优化等业务场景。
此外,运营商人工智能能力平台还需要与科大讯飞、百度等各领域领先的AI 企业建立接口,通过使用外部平台进行训练、自有资源池部署外部应用等多种途径集成第三方人工智能开放平台。与外部平台采用何种合作方式需根据数据的保密等级、建设进度、建设成本等多方面因素综合考量。
SaaS 层建设思路
SaaS 层主要考虑对于一些通用性较强的AI 应用进行产品化,在全网或全省统一部署,由各省、各地市、各业务部门等作为租户进行调用,实现AI 能力的快速推广和使用。
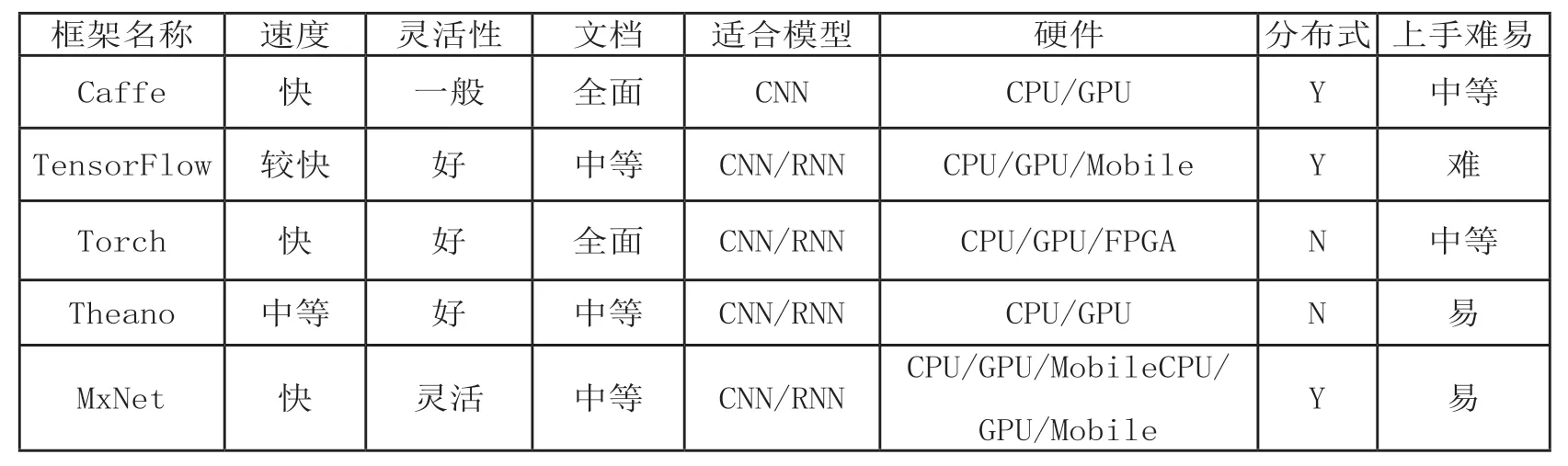
表2 各类深度学习算法框架特点比较
目前可考虑引入的SaaS服务包括智能客服、智慧营业厅、智慧运维、自动化巡检、产品智能推荐以及智能家居产品推广等,后续可根据业务需求不断丰富SaaS服务种类。
结束语
目前人工智能技术在基础硬件(GPU 加速异构计算)、关键算法(图像、语音、语义识别)等领域已逐步进入成熟期、正在快速迭代演进,运营商应抓住机遇,及早构建自有人工智能能力平台,力求在5G 时代发力自动驾驶、远程医疗、虚拟现实等业务领域,形成核心竞争力,并为社会提供智慧服务能力。
