一种基于lightGBM框架改进的GBDT风力发电机叶片开裂预测方法
2020-04-09刘钰宸
刘钰宸, 安 静
(上海应用技术大学 电气与电子工程学院,上海 201418)
随着社会经济的不断发展,在生产过程中所需要的电力资源也越来越多,传统的火力发电消耗较多的不可再生能源,能源消耗的问题变得更加严重。因此,在世界范围内都在进行可再生能源的开发与探索。其中,风能是比较容易进行利用的一种可再生资源,风力发电机作为一种风力发电的主要设备也被广泛的使用[1]。由于低温、潮湿和机械振动容易造成风力发电机叶片的裂纹损伤,在风力发电机设备损坏问题中,叶片开裂问题是最为严重的。叶片振动产生的弯扭力会使原有裂纹不断加深、加长、扩张,最后导致发电机叶片开裂甚至断裂。而叶片开裂的维修也非常困难,需要托运到厂家进行维修,维修的费用和时间成本都非常高昂。定期检测和预测风力发电机叶片开裂情况,是保障运转的重要因素。使用机器学习算法对风力发电机叶片数据进行分析具有重要的现实意义。
在预测领域,梯度提升决策树(gradient boosting decision tree,GBDT)算法是一种应用最为广泛的预测算法,能够在大部分的预测任务上取得比其他方法更为优秀的预测结果。GBDT算法最初由Friedman[2]提出,并将其应用于分类和回归任务。众多研究人员对GBDT算法进行了研究,其中Chen等[3]提出的XGBoost算法取得了较好的效果。刘宇等[4]将XGBoost算法应用于心脏病的预测,赵洪山等[5]使用XGBoost算法结合深度自编码网络对GBDT风电机组发电机故障进行诊断。
本文针对XGBoost算法占用较大内存,并且训练速度较慢的不足,提出了一种皮尔森相关性系数以及模型特征重要性筛选特征结合基于lightGBM改进的GBDT算法。首先对风力发电机叶片数据进行分析,其次,提取较为重要的特征进行训练,最后分别使用基于LightGBM的GBDT算法和GBDT算法构建预测模型,并将这2种模型的预测结果进行对比分析。
1 特征提取
风机叶片开裂故障主要是由于共振,主要与风力发电机的机械特性有关[6]。共振的特点是能够在非常短的时间内对风机叶片造成巨大破坏[7-9]。但是叶片的数据在开裂之前都是正常的,只有在发生故障这段时间数据有异常,所以很多数据都是无效的。因此,需要对数据进行特征提取。
由于数据是从真实场景下获取的,数据集不完整,存在少量数据缺失,不能直接用于训练,所以本文通过求最大值、最小值、均值和标准差的方式,同时进行对数据的去空和去噪处理[10],保持训练模型的精准性等操作对所选取的数据进行预处理。
1.1 皮尔森相关性系数分析
皮尔森相关性系数也称皮尔森积矩相关系数,是一种线性相关系数,能够体现出变量之间的线性相关程度,是最常用的一种相关系数[11]。运用皮尔森相关性系数分析风力发电机运行的数据特征,确定特征之间是否紧密相关,如果相关就属于重复特征,可以去除,从而降低机器学习数据维度,得到更好的模型。
首先,计算出原始数据中的皮尔森相关性系数,皮尔森相关性系数的公式定义如下:
(1)
式中:两个连续变量(X,Y)的皮尔森相关性系数PX,Y等于它们之间的协方差cov(X,Y)除以它们各自标准差σX、σY的乘积。
对真实场景下获得的数据集运用皮尔森相关性系数的方法进行分析,对相关性较大的数据进行特征提取。本文取皮尔森相关性系数前5的特征,如图1所示。
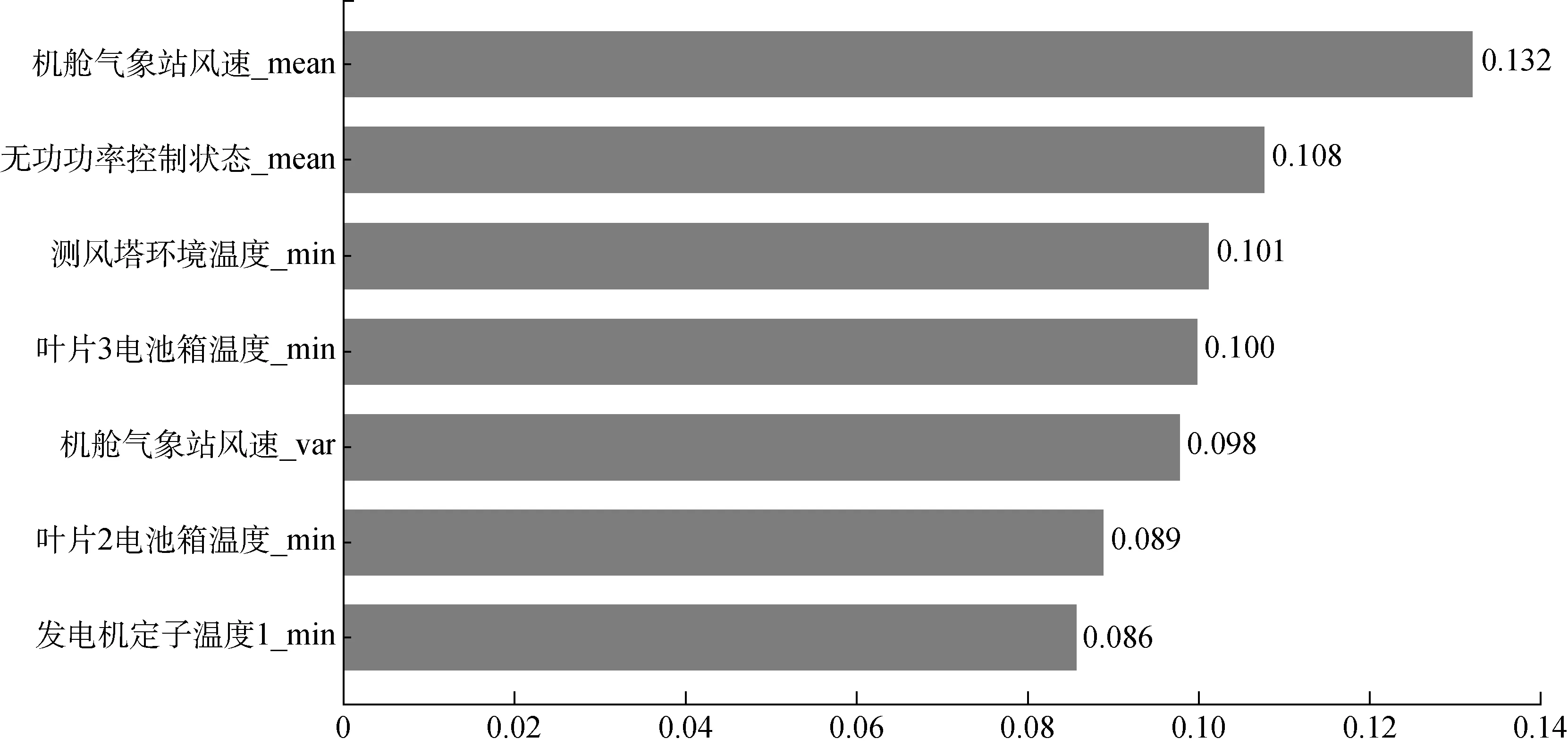
图1 皮尔森相关性系数分析
1.2 模型特征重要性分析
本文使用的是树模型,因此可以通过计算特征重要性来进行特征提取,特征重要性的计算方法是,基于单棵树计算每个特征的重要性,探究每个特征在每棵树上做了多少的贡献,最后再计算出平均值(见图2)。
本文通过基尼指数计算特征重要性。基尼指数定义如下:
(2)

模型重要性评分定义如下:
(3)
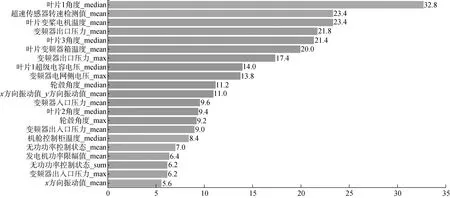
图2 模型特征重要性分析
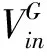
本文取模型相关性系数前45的特征。
2 算法模型
2.1 GBDT算法
GBDT算法主要步骤:利用训练数据集迭代计算目标与实际值的残差,每次更新弱学习器参数最终得到符合要求的强学习器,同时得到拟合出的回归树。预测时将所有树的结果进行累计作为最终的预测结果,即通过多个弱学习器组成一个强学习器。采用GBDT算法预测风力发电机叶片开裂过程是先利用风力发电机运行数据集的一部分数据作为训练数据集,迭代计算更新弱分类器,最后得到拟合完成的回归树,利用剩余的风力发电机运行数据验证强学习器预测准确度。计算过程如下:
设回归树为
(4)
式中:l(x∈Rj)为指示函数;bj为回归树结点上的数值。
定义回归树模型为
(5)
式(5)整理为
(6)
式中,γjm=ρmbjm。
2.2 基于lightGBM改进的GBDT算法
Guo等[12]提出的lightGBM算法是一种新的梯度提升框架,对于其他的GBDT算法来说,基于lightGBM改进的GBDT算法,主要2个关键步骤:① 对训练样本数据利用数据梯度变化和设定梯度阈值来进行采样,保证数据的同时减少数据以降低计算量,提高生成的强分类器的预测准确率;② 遍历训练样本所有特征进行特征绑定冲突率计算,根据设定的绑定冲突阈值进行特征选择,对低于绑定冲突率的特征进行独立特征合并,使不同维度数据合并在一起,由此特征空间有稀疏状态变成稠密状态。通过数据采样与独立特征合并之后再进行初始化弱学习器、更新弱分类器和生成强学习器。通过以上2个步骤能够提高风力发电机叶片开裂预测准确性,同时具有更快的运算速度,更小的内存占用,以及更高的效率。
数据集T,定义回归树模型为
(7)
损失函数为
(8)
采用牛顿法对上式进行拟合
(9)
式中:gi为损失函数的一阶梯度;hi为损失函数的二阶梯度。
设Ij为回归树结点j上的样本集合,则上述损失函数可以变为
(10)
式中:ω为权重;j表示叶节点数。求解上式:
(11)
(12)
则得到的最优弱学习器
(13)
3 风力发电机叶片开裂预测及结果分析
3.1 预测分析风力发电机叶片开裂的GBDT算法伪代码
(2)Form=1~M,M为生成树的个数。
① Fori=1,2,3,…,N。N为训练样本数量
(14)
② 计算梯度、依据特征梯度划分数据集分割数据产生节点,Rjm,j=1,2,…,Jm
③ Forj=1,2,3,…,Jm
(15)
xi∈Rjm
④ 更新
(16)
(3)输出f(x)=fM(x)得到强学习器提升回归树。
(4)依据训练结果输入测试集中风力发电机运行数据中的特征值预测未来风力发电机发生叶片开裂的可能性。
3.2 预测分析风力发电机叶片开裂的基于 light-GBM改进的GBDT算法伪代码
(1)输入训练数据I,最大梯度d,大梯度采样比例系数a,小梯度采样比例系数b,初始化损失函数loss以及弱学习器L。

(4)将(3)步获得的大梯度风力发电机运行数据样本与小梯度风力发电机运行数据样本拼接,对于小梯度样本乘以fact。
(5)独立特征绑定输入特征F,最大冲突率K,绑定bundles={ }(表示绑定后的合并特征数组),绑定冲突bundlesConflict={ }(表示每一个特征绑定后的冲突率组成的数组)。对每一个特征进行计算是否小于绑定冲突,若否需要绑定,运行所有特征。最后,合并独立特征,输出合并后的独立特征。
(6)通过将采样后的风力发电机运行数据和独立特征合并后的特征输入原始的GBDT算法进行弱学习器反复迭代,最终得到能够预测风力发电机叶片开裂的强学习器,并利用25%的风力发电机运行数据做叶片开裂预测与验证。
3.3 风力发电机叶片开裂预测
本文采用的数据来源于国际电力投资集团有限公司,发布的5万条采集于300台风力发电机连续两个月的运行数据,其中包含风力发电机叶片开裂故障30次。风力发电机运行数据共有75个特征,全部特征如下表1所示。其中,75%的风力发电机运行数据(其包含风力发电机叶片开裂故障数据)用来训练GBDT算法与lightGBM改进的GBDT算法的强学习器,25%的运行数据用来做风力发电机叶片开裂预测验证。
对训练数据集分别采用了GBDT算法与lightGBM改进的GBDT算法进行训练,通过初始化残差生成弱学习器,计算残差寻找最佳划分点并利用数据特征划分数据生成叶子节点,之后更新弱学习器反复迭代最终获得具有预测能力的强学习器。但由于两种算法的差异使得训练数据时的计算量、风力发电机叶片开裂预测结果出现不同。风力发电机运行数据采用GBDT算法预测时,由于该算法不进行数据与特征处理,使用所有特征数据进行全局弱学习器更新使得计算量非常大,具有75个特征的风力发电机运行数据在一棵树一次迭代时计算次数至少需要275以上,生成数量庞大的叶子节点,进行多棵树多次运行数据迭代后计算量将更大。

表1 风力发电机运行数据特征列表
基于lightGBM改进的GBDT算法在第一次弱学习器迭代前,首先利用风力发电机运行数据中样本的梯度与初始化后产生的误差对训练样本数据进行采样,对运行数据中梯度绝对值大的保留,梯度绝对值小的数据集采样一部分子集,同时给该数据子集权重,使得这部分子集能够近似代替梯度小的数据全集,采样后的风力发电机运行数据集不会丢失梯度大的训练样本,不改变样本数据的分布状态,同时能够减少训练样本数量和降低计算量,训练速度大大加快。采用基于lightGBM改进的GBDT算法预测风力发电机叶片开裂的另一优势在于该算法能够降低特征维度,对于具有75个特征的风力发电机运行数据其特征空间是稀疏的,利用算法的独立特征合并能够使不同维度数据合并在一起,使特征空间有稀疏状态变成稠密状态,进行了数据采样与独立特征合并之后进行GBDT算法初始化弱学习器、更新弱分类器和生成强学习器,最后使用剩余风力发电机运行数据预测叶片开裂,验证预测结果。
图3所示为GBDT算法与基于lightGBM改进的GBDT算法进行第一次迭代前输入弱学习器的数据量,经过采样后数据量减少,因此更新弱学习器时输入样本减少,计算量降低。
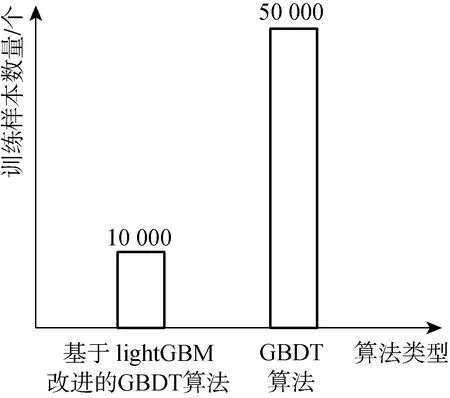
图3 基于lightGBM改进的GBDT算法对输入样本采样后数据与GBDT算法输入样本数据量对比
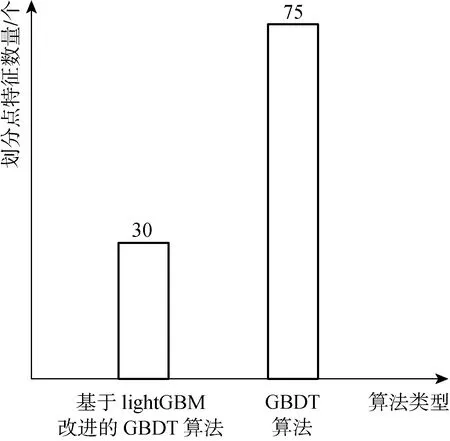
图4 基于lightGBM改进的GBDT算法对输入样本特征与GBDT算法输入样本特征对比
图4所示为GBDT算法与基于lightGBM改进的GBDT算法更新迭代弱学习器前特征数量对比,通过独立特征合并使得特征数量减少。图中基于lightGBM改进的GBDT算法的特征合并后数量降为30个特征大大减少了计算叶子结点时最佳划分点的计算消耗,通过实验发现合并的的特征中轮毂转速和角度、叶片1、2、3角度、变桨电机1、2、3电流、x、y方向振动值、机舱气象站风速、大气压力、风向绝对值、无功功率控制状态、额定的轮毂转速、机舱气象站风速、变频器电网侧电流、电压、有功功率、无功率、变频器入口、出口温度,入口、出口压力等被分类合并,而与温度相关的测风塔环境温度发电机定子1、2、3、4、5、6温度、发电机空气温度、主轴承温度、机舱、控制柜温度、变频器INU、ISU温度等特征没有被合并,这说明被合并的特征相互之间相关性小,相互独立,未被合并的特征相互之间相关性大。对于功率转矩电流电压等特征是相互产生影响,而风力发电机处于开放空间中由于热传导的原因距离较近的多台设备,其温度必然会相互影响温度,进而在测量得到的风力发电机运行数据中相互关联。
表2中对比了采用2种算法对风力发电机运行数据中用于训练的数据集,进行预测验证,2种算法都具有非常高的准确率,将训练数据集中的22处风力发电机叶片开裂故障准确检测。这表明通过两种算法训练的弱学习器和强学习器具有基本的预测能力,之后将训练得到的2个强学习器用于风力发电机运行数据的剩余数据集验证,检测强学习器预测风力发电机叶片开裂的能力。
表2 采用GBDT算法与基于lightGBM改进的GBDT算法在风力发电机运行数据训练集中预测结果
Tab.2 GBDT algorithm and improved GBDT algorithm based on lightGBM are used to predict the results of wind turbine operation data training set

算法预测风力发电机叶片开裂故障/次数验证训练样本风力发电机叶片开裂故障/次数GBDT算法2222lightGBM改进的GBDT算法2222
由表3、表4可以得到对于含有相同的叶片开裂故障的风力发电机运行数据集,2种算法的预测结果有较大差异。基于lightGBM改进的GBDT算法的算法预测效果显著优于未改进的GBDT算法,这说明对风力发电机运行数据进行采样和独立特征合并不仅提高了计算速度,而且利用部分特征之间的互斥性在降低特征维度的同时提高了风力发电机叶片开裂预测的准确性。但基于lightGBM改进的GBDT算法仍然不能完全预测出风力发电机叶片开裂,这是由于在采样系数的选择中,对于大梯度和小梯度选择的取舍,小梯度的系数过于小会造成数据集中丢失一部分有用信息,大梯度系数太大会造成数据集中包含的特征过于集中于某些特征丢失一些特征信息。独立特征合并时也会造成一些信息损失,对于选取合适的最大冲突率,使得特征合并适量也非常重要。对于不同的风力发电机运行数据其参数设置往往不同。因此,基于lightGBM改进的GBDT算法采样系数、最大冲突率参数选择十分关键。GBDT算法没有进行数据采样以及独立特征合并,但预测能力较低的重要原因,一方面是由于未进行独立特征合并不能充分发挥特征特性,另一方面是由于对于风力发电机叶片开裂预测问题,所采集的数据并不能够非常完整的描述风力发电机运行状态特征,使得不同的叶片开裂时所具有的真实特征不一致,用于GBDT算法与基于lightGBM改进的GBDT算法不能从获得的风力发电机运行数据中分析出另外特殊情况下风力发电机叶片开裂的故障。这是预测算法必须面临的问题,在风力发电机运行数据训练集中从来为出现的叶片开裂状况,是不能准确预测到的只能表示叶片开裂发生的可能性。
表3 采用GBDT算法预测风力发电机叶片开裂情况以及样本验证
Tab.3 The wind turbine blade cracking and sample verification were predicted by GBDT algorithm

数据索引编号风力发电机叶片开裂与否验证样本风力发电机叶片开裂数据索引编号预测正确与否21100开裂21100正确23232开裂23232正确无未检测数出25002错误25890开裂25890正确无未检测出26785错误无未检测出32106错误43567开裂43567正确48982开裂48982正确
表4 采用基于lightGBM改进的GBDT算法预测风力发电机叶片开裂以及样本验证
Tab.4 The wind turbine blade cracking and sample verification were predicted by the improved GBDT algorithm based on lightGBM

数据索引编号风力发电机叶片开裂与否验证样本风力发电机叶片开裂数据索引编号预测正确与否21100开裂21100正确无未检测数出23232错误25002开裂25002正确25890开裂25890正确26785开裂26785正确32106开裂32106正确43567开裂43567正确48982开裂48982正确
3.4 模型预测结果
本文采用F1-score进行模型的评价
(17)
式中:P表示精准度;R表示召回率;F1-score表示预测的准确度其值在0~1之间。
本文采用了GBDT算法和基于lightGBM改进的GBDT算法,并对这2种算法预测风力发电机叶片是否开裂的结果进行了比较,如表5所示。由表5得出GBDT算法预测的风力发电机叶片开裂准确性低于基于lightGBM改进的GBDT算法。未改进的GBDT算法对于风力发电价叶片开裂预测准确性只有62.3%,而基于lightGBM改进的GBDT算法对于风力发电价叶片开裂预测准确性达到了87.5%,其具有更高的可信度。
表5 变参数模型参数点选取
Tab.5 Select parameter points of the variable parameter model

算法F1-scoreGBDT0.625基于lightGBM改进的GBDT0.875
4 结 语
本文通过使用基于lightGBM改进的梯度提升决策树算法与lightGBM梯度提升决策树算法,建立了风力发电机叶片开裂预测模型。对采集于风力发电机的运行数据进行分析准确预测出了风力发电机叶片开裂故障。同时,将lightGBM梯度提升决策树算法和基于lightGBM改进的梯度提升决策树算法建立的预测模型进行了比较,预测结果表明,基于lightGBM改进的梯度提升决策树算法的模型拥有得更好的预测性能,能够为风力发电机开裂提供较为准确的预测信息。采用基于lightGBM改进的梯度提升决策树算法通过对样本数据的采样,删减了样本中梯度变化较小的样本,从而降低了样本数量,此外,对于每一个特征该算法计算特征之间的相关性,对相关性小的相互独立的特征进行捆绑,使得划分点特征数量减少降低计算量的同时能够提高风力发电机预测的准确性。但基于lightGBM改进的梯度提升决策树算法并不能每次都完全预测风力发电机叶片开裂故障,因为对于预测问题始终存在训练样本是否完全包含风力发电机叶片开裂的所有相关特征,显然在现实环境中不可能满足。基于lightGBM改进的梯度提升决策树算法也存在样本采样时的最小梯度选取、独立特征合并时最大冲突率选取等问题需要完善。
