识别运动声源的时域波束形成技术研究
2020-04-08张永斌朱德富张小正
张永斌, 朱德富, 张小正
(合肥工业大学 机械工程学院,安徽 合肥 230009)
汽车、火车和飞机等交通工具在运动过程中向外辐射噪声,并对环境造成噪声污染,准确识别这些运动物体的噪声源对于从声源的角度控制噪声污染具有重要的指导意义。波束形成(Beamforming)技术是识别运动声源的一种重要手段。文献[1-2]使用Beamforming技术识别运动汽车的噪声源,并对比了不同形式传声器阵列的识别效果,之后进一步将Beamforming技术与标准的通过(Pass-by)噪声测试过程相结合,来可视化汽车的Pass-by噪声。国内很多学者也在利用Beamforming技术识别运动汽车噪声源方面开展了大量的研究工作[3-13]。在识别轨道列车噪声源方面,文献[14-17]进行了大量的实验测试工作,基于实验结果分析了火车噪声源的位置和频谱分布特性,还深入研究了Doppler效应消除和阵列形式设计等关键问题;文献[18]将Beamforming技术用于城市轨道交通列车的噪声源识别。在识别飞机起飞和着陆过程中的噪声源时,Beamforming技术同样发挥了重要作用[19-25],如文献[20-22]采用Beamforming技术对飞机进场着陆过程噪声、起落架噪声和机翼脱落涡噪声进行了测量和识别。
在上述研究工作中,虽然运动声源的类型不同,但是用于识别这些声源的Beamforming方法是类似的。这些方法多是基于运动点源模型,且包含2个主要步骤:① 以发射时刻为基准,对测量的时域声压信号进行插值,消除由于声源运动导致的不同传声器在同一时刻的测量声压对应于声源在不同发射位置的问题;该问题是产生Doppler效应的根源,因此在时域将不同传声器的测量信号以相同发射时刻为基准进行对齐的过程也被认为是消除Doppler效应的过程[2];② 以插值后的时域声压为输入,采用延时求和这种经典的Beamforming算法识别噪声源。在采样率足够的情况下,第①步容易实现,例如采用拉格朗日插值就足以保证时域声压的插值精度。但是,在第②步中,因为上述延时求和算法中都忽略了运动声源辐射中近场项(也被称为次级项)的影响,所以只能用于小马赫数条件下的运动声源识别;随着声源运动速度的增加,上述方法会产生较大的识别误差;另外,上述延时求和方法得到的结果是声源源强时域导数的近似量,与声源源强的量级不同。
针对现有方法的第②步中存在的问题,本文提出一种新的时域Beamforming方法。采用该方法不但可以突破现有方法在声源运动速度方面的限制,而且可以直接获得声源的时域源强信号。本文还通过数值仿真对提出的方法进行了验证,并与现有方法进行了对比。
1 理 论
Beamforming技术的测量和计算过程如图1所示。一个声源Q平行x轴做匀速直线运动,速度为v,且马赫数M=v/c<1,其中c为声速;采用一个静止的传声阵列H测量该运动声源的辐射声场,阵列中第k个传声器的坐标rk=(xk,yk,zk),其中k=1,2,…,K,K为阵列包含的传声器数目。假设一个聚焦面S包含声源Q并与声源以相同的速度运动,该面上分布多个聚焦点rs(rs与时间有关),N为聚焦点的个数。Beamforming技术的功能就是基于传声器阵列测量的声压信号重建每个聚焦点的源信号或者重建源信号的等效参量,当聚焦点与真实声源Q重合时,重建结果聚焦成峰值,从而达到识别声源的目的。采用Beamforming技术识别运动声源的过程主要包含测量信号时域插值和声源信号聚焦2个步骤。
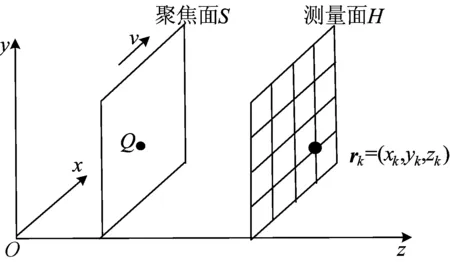
图1 Beamforming技术测量过程示意图
1.1 测量信号时域插值
假设第s个聚焦点的发声时刻为τ,则发声时的位置rs=(xs(τ),ys,zs)。聚焦点与测量点之间的位置关系如图2所示。由于声源是运动的,该聚焦点在τ时刻发出的声信号在t时刻到达测量点rk处,并且t和τ满足:
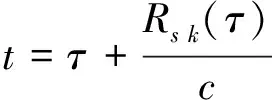
(1)
其中,Rs k(τ)={[xk-xs(τ)]2+(yk-ys)2+(zk-zs)2}1/2,表示在τ时刻该聚焦点与第k个传声器之间的距离。
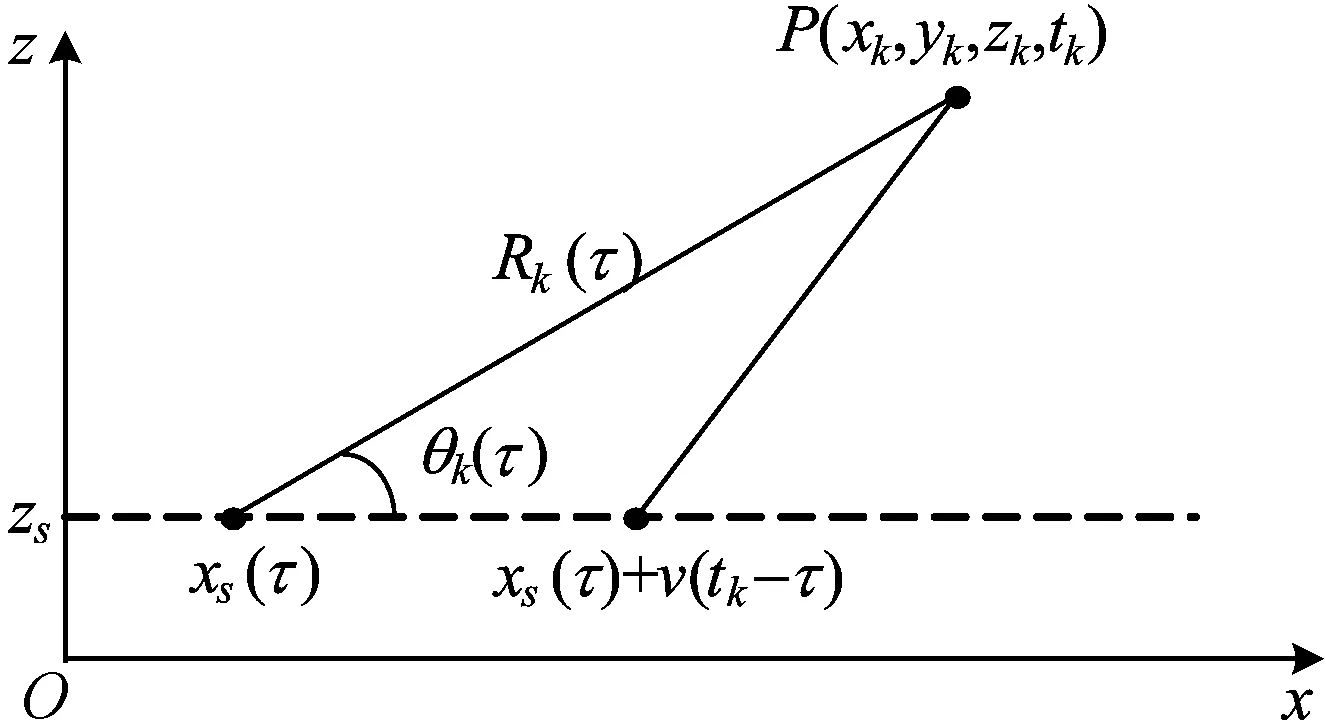
图2 聚焦点与测量点之间的位置关系
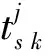
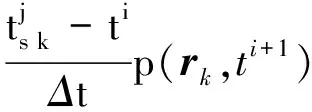
(2)
1.2 Beamforming聚焦
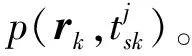
(3)
但是上述聚焦公式并未考虑到运动声源与静止声源的区别。
由Morse的理论声学[26]可知:
(4)
其中,q、q′分别为该聚焦点处的源强及其时间导数;cos[θs k(τj)]=[xk-x(τj)]/Rs k(τj)。从(4)式可以看出,当声源静止时,v=0,此时(3)式给出的Beamforming输出为聚焦点源强信号的时间导数q′(τj)。但是当声源运动时,(3)式的Beamforming输出不但忽略了(4)式右边的第2项(也就是通常所说的近场项或次级项),还忽略第1项分母中的{1-Mcos[θs k(τj)]}2。
有的学者把声源运动导致的θs k(τj)角度的变化考虑进来[16],获得的Beamforming输出为:
(5)
对比(4)式和(5)式可以看出,在忽略近场项的情况下,(5)式中的Beamforming输出同样为聚焦点源强信号的时间导数q′(τj)。相比于(3)式,(5)式考虑了运动声源与静止声源的区别,在速度较低时,定位效果会有所提高。但是(5)式仍然忽略了近场项的影响,因此在运动速度较高时,该方法的定位效果也会变差。另外,(3)式和(5)式得到的结果都是聚焦点处源强的时间导数,并不是时域源强。针对上述问题,本文提出了一种基于时域差分的Beamforming聚焦方法。
从(4)式可以看出,由于同时包含了q、q′两项,采用常规的加权(把传播距离视为加权系数)求和方式无法在包含近场项的情况下获得源强,为此,采用时域差分近似q′,使得(4)式中只包含q项。可以使用的差分方式包含向后差分、向前差分和中心差分3种,表达式分别为:
(6)
(7)
(8)
将(6)~(8)式分别代入(4)式中,得到关于q(τj)的方程,但此时方程中包含了2个或3个时刻的源强,仅从单个方程无法直接求解。为此,将代入差分后的(4)式扩展到所有τj时刻,形成线性方程组后一起求解。该方程组可以表示为:
Pk=Gs kQs k
(9)
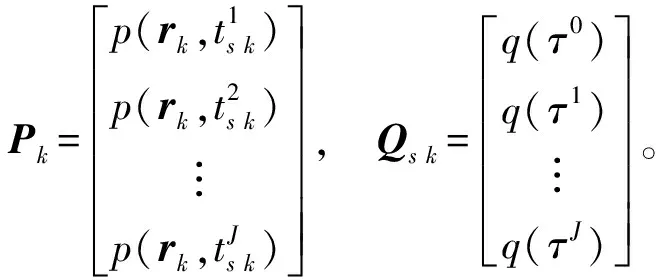
当分别采用(6)式、(7)式给出的向后、向前差分格式时有:
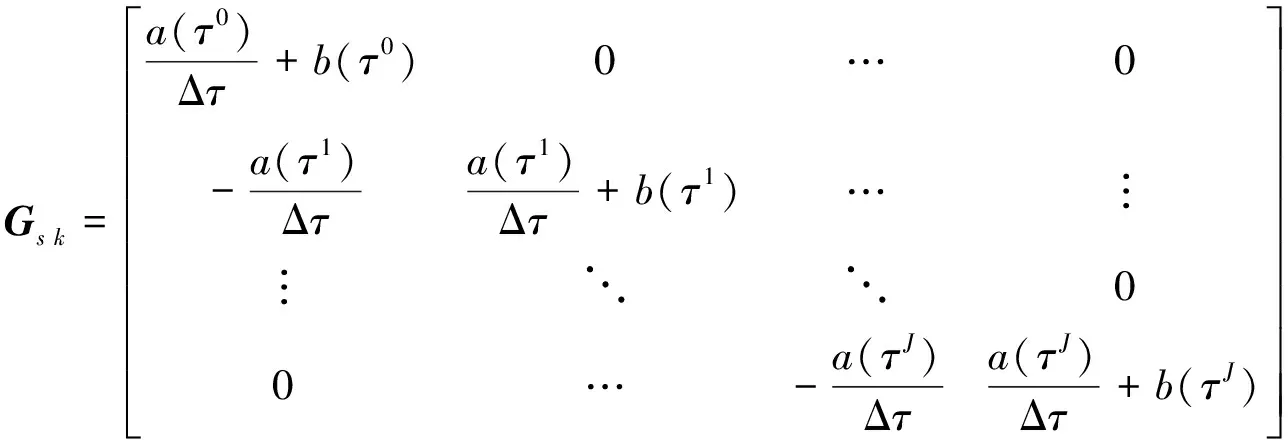
(10)
(11)
当采用(8)式给出的中心差分格式时有:
(12)
其中
求解(9)式,可以得到对应第k个传声器时域测量声压的第s个聚焦点源强信号Qs k,即
(13)
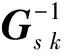
将所有传声器在第s个聚焦点求得的源强信号进行求和平均,得到针对该聚焦点的Beamforming输出为:
(14)
其中,B=[B(τ0)B(τ1) …B(τJ)]。由(3)式、(5)式、(14)式得到的是单个聚焦点处的与源强相关的时域信号,其中(3)式和(5)式得到的是近似的源强时间导数,而(14)式得到的是源强。这些源强信息对于分析运动声源辐射的噪声特性以及运动声源的故障诊断和健康监测具有指导作用。
为了实现运动声源的识别,通常将Beamforming的时域输出结果在时间上进行平均,在每个聚焦点得到1个等效值,即
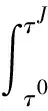
(15)
将上述计算过程应用到每个聚焦点,可以得到整个聚焦面S上如(15)式所示的E值分布图,从该图中可以识别运动声源的分布。
2 数值仿真
对比本文所提出的3种基于有限差分的Beamforming算法的效果,确定效果较好的Beamforming算法后,分别在运动速度较低(100 km/h)和较高(800 km/h)2种情况下,对比(5)式、(14)式2种考虑和不考虑近场项的Beamforming算法的声源识别效果。数值仿真中,声源位于xoy平面内,源信号为1 000 Hz的正弦信号,起始位置位于(-0.5, 0, 0) m处,并以一定的速度沿着x轴正方向匀速直线运动;测量面位于z=0.2 m处,且平行于xoy平面,大小为1 m×1 m,测量点间距0.1 m,因此测量面内可均匀布置121个测量点。在每个测量点,传声器的时域采样频率为10 kHz。声源距离测量面越远,传声器采集到的声音信号的信噪比越低,测量误差就会越大。因此,仿真中每个测量点的声压值为声源从测量面一侧运动到另一侧这段时间内辐射的声压值,即声源在测量面的覆盖范围内运动。在已知声源速度v、运动距离L和采样频率fs的条件下就可以计算出采样点数SN,即
SN=Lfs/v
(16)
由(16)式可得,运动速度为100 km/h(M=0.08)时时域采样点数为360,运动速度为800 km/h(M=0.65)时时域采样点数为45。仿真中给出的声源识别结果均是按照(15)式计算的时域平均结果。
基于(6)~(8)式3种时域差分格式,考虑了近场项的声源识别结果如图3、图4所示。从图3、图4可以看出,不管是在低速运动还是高速运动的情况下,采用向前差分算法都可以准确识别出声源位置,而向后差分和中心差分识别的声源位置不正确。
由(6)~(8)式可以看出,在计算q′(τ0)时,向后差分和中心差分都用到了q(τ0)前面的时刻。由于q(τ0)前面时刻的值是未知的,只能假设为0,这样的假设会对后续求解产生影响;但是向前差分算法并没有用到q(τ0)前面的时刻,因此不存在该问题,对初始时刻的取值不敏感。
综上所述,基于时域向前差分的计算效果最好且最为稳定。
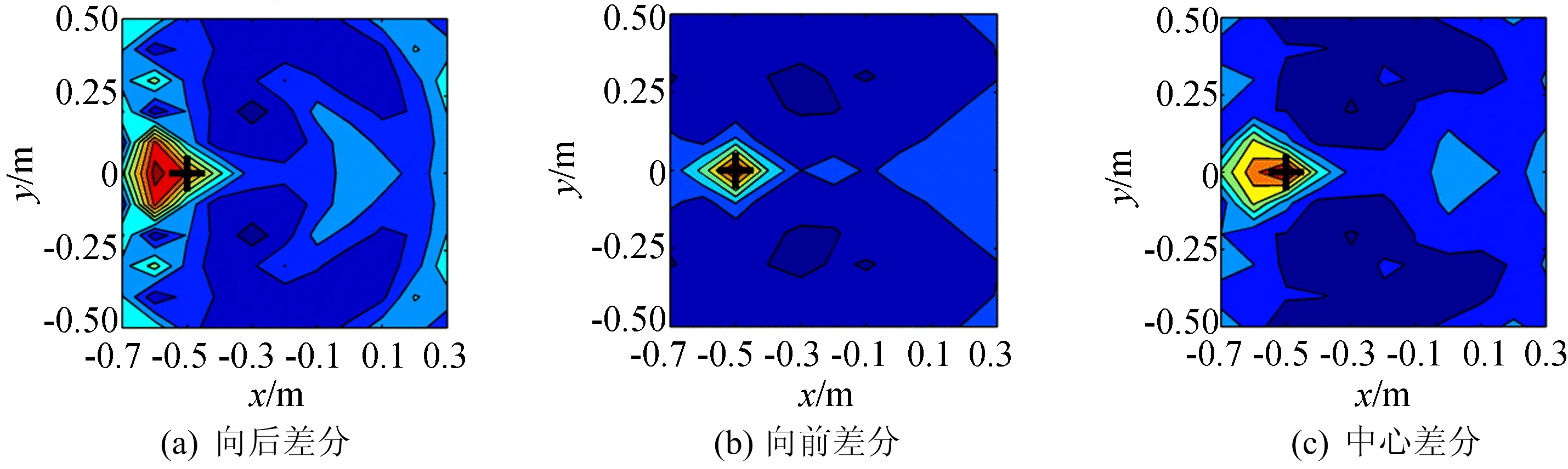
图3 基于3种时域差分格式的声源识别结果(100 km/h)
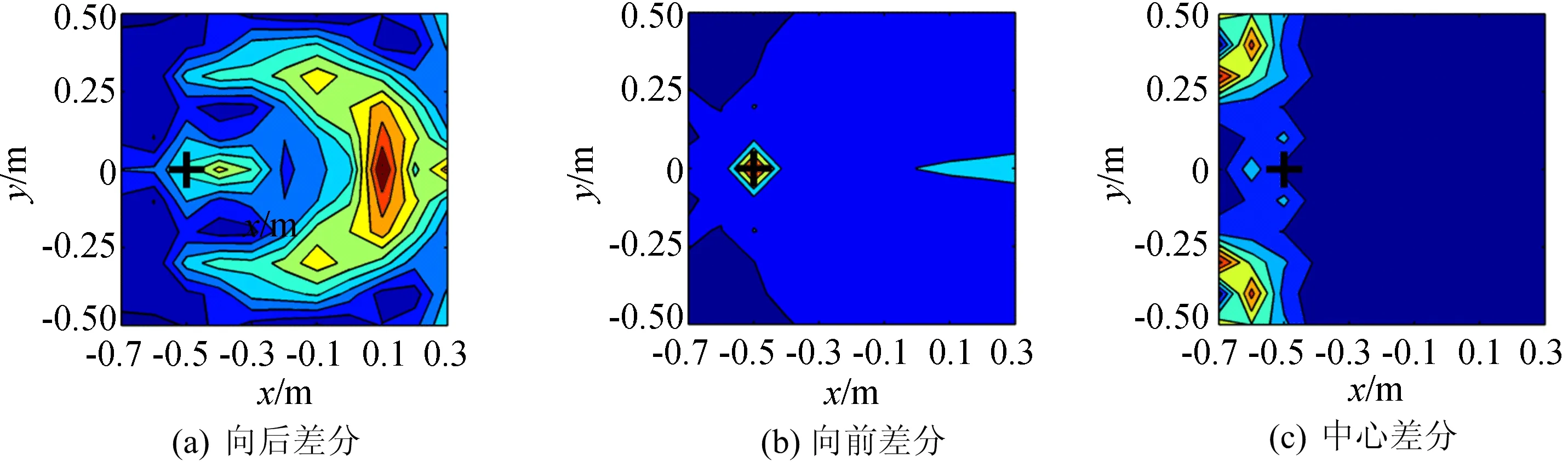
图4 基于3种时域差分格式的声源识别结果(800 km/h)
采用忽略近场项的(5)式得到的声源识别结果如图5所示。对比图3b与图5a可以看出,在声源低速运动时,不管是考虑或忽略近场项,都可以准确识别出运动声源的位置。对比图4b与图5b可以看出,在声源运动速度较高时,本文提出的时域差分算法可以准确识别出运动声源,而忽略近场项的结果中出现了另外一个与真实声源强度接近的错误声源,导致识别效果较差。
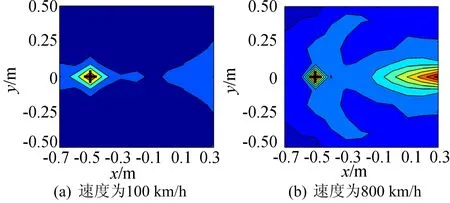
图5 基于(5)式忽略近场项的声源识别结果
采用考虑近场项的(14)式求解得到的源强时域信号与理论源强时域信号的对比如图6所示。从图6可以看出,在声源低速和高速运动时,采用本文方法得到的源强信号都与理论信号吻合得较好。通过上述数值仿真可以看出,在声源低速运动时,近场项对声源识别结果影响很小,因此可以忽略近场项以简化运算。当声源高速运动时,近场项对声源识别结果的影响不可忽略。另外,采用本文提出的方法可以获得声源的时域源强信号。
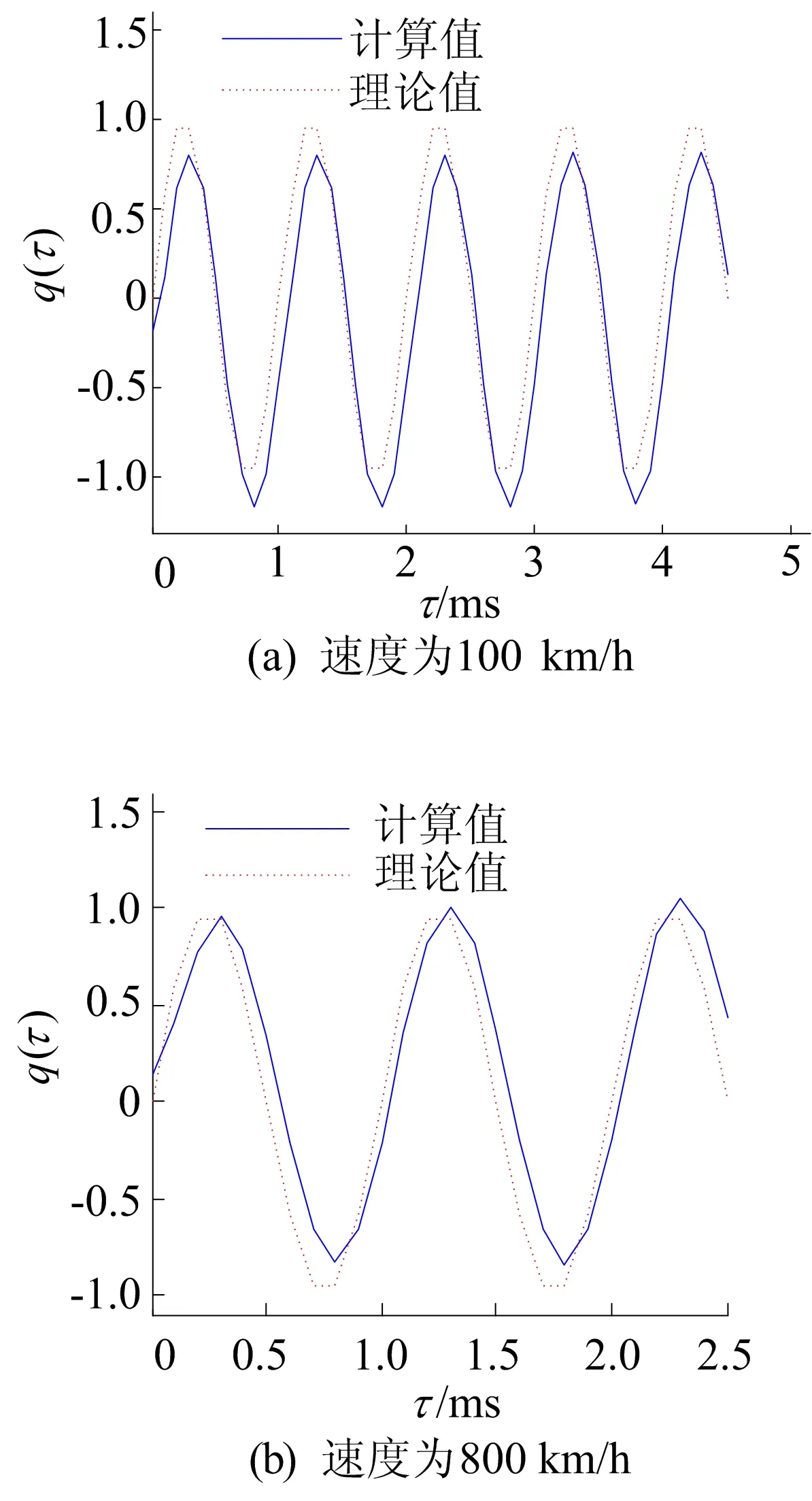
图6 基于(14)式求得的源强时域信号与理论源强信号的对比
3 结 论
本文对用于识别运动声源的时域波束形成Beamforming技术进行了研究,提出了一种考虑运动声源辐射声场中近场项影响的Beamforming方法。该方法采用时域有限差分近似运动点源辐射场中的源强时间导数,通过矩阵求逆计算源强。本文分别给出了基于向后差分、向前差分和中心差分3种时域差分格式的Beamforming方法,采用这些方法可以直接得到聚焦点处的源强时域信号。通过数值仿真对比了3种差分算法的效果,结果表明,基于向前差分的Beamforming方法的效果最好并且最稳定。通过数值仿真还对比了基于向前差分的Beamforming方法和忽略近场项的Beamforming方法的声源识别效果,结果表明,在声源低速运动时,不管是考虑或忽略近场项都可以准确识别出运动声源的位置;在声源高速运动时,忽略近场项的Beamforming方法识别效果较差,而采用本文方法可以准确识别出运动声源。
