统一渲染架构GPU中可配置二级Cache设计
2020-04-07杜慧敏康浩然
杜慧敏,康浩然,王 可
(西安邮电大学 电子工程学院,陕西 西安 710121)
图形处理器(graphics processing unit,GPU)是专门用于图像和图形相关运算工作的微处理器。GPU可以分为统一渲染架构和分离式渲染架构两种类型。相较于分离式渲染架构,统一渲染架构GPU增加了几何着色器模块,并将顶点着色器和像素着色器被合成为一个流处理器,同时负责顶点着色和像素着色,降低了附载不均衡现象,提高了渲染效果,成为当前主流的渲染架构。
二级高速缓存(L2 Cache)作为统一渲染架构GPU缓存结构中重要的一级,直接影响着GPU整体的性能[1]。由于统一渲染架构GPU中存储系统所占用的芯片面积大多来源于Cache[2],因此对Cache的结构参数和性能方面的优化十分必要[3]。受功耗和面积的限制,统一渲染架构GPU中固定的缓存结构难以兼顾不同应用场景下存取速度快、容量大和成本低的需求[4]。
事实上,L2 Cache结构和配置取决于整个系统平台的应用场景要求[5],不同应用场景的3D图形渲染需要处理的数据量也不同[6],例如,对于图形渲染能力要求不高的场景,容量更小的Cache存储器能够在满足应用需求的情况下降低访存代价;而在图形渲染能力要求高的场景,则需要统一渲染架构GPU使用容量更大的Cache,充分利用片上资源实现性能提升。例如,文献[7]从缓存的容量、空间逻辑组织结构的组大小、块大小、数据的替换算法和写入Cache的数据地址流等方面对Cache命中率的影响进行分析,选择合适的参数,提高了缓存的命中率。然而,这些对缓存的优化方法都是针对于Cache内部结构进行相应的改善,虽然在一定程度上可以提高缓存的命中率,但是也相应地导致缓存结构更加复杂。
针对上述问题,拟提出一种统一渲染架构GPU中可配置L2 Cache设计方案。L2 Cache采用4路组相联映射方式,应用读贯穿策略处理读缺失,分别使用写不分配策略及直写策略处理写缺失及写命中,同时,采用路预测以及改进后的最近最少使用(least recently used,LRU)替换算法提升结构性能,应用哈希选择算法,根据不同的应用场景配置统一渲染架构GPU内部Cache的大小和数目,以期在实现统一渲染架构GPU缓存结构的可扩展性及可定制性的同时,提高缓存的性能。
1 设计思路
1.1 L2 Cache的映射方式
L2 Cache采用4路组相联映射方式。访问L2 Cache的物理地址位宽为40 bit。单个的L2 Cache的大小有128 kB、256 kB和512 kB等3种配置。索引位宽bi的计算公式为
(1)
其中:SC表示单个Cache的大小配置;MC表示Cache内部的块大小;P表示Cache内部的相联度。标记位宽bT的计算公式为
bT=ba-bi-bo。
(2)
其中:ba表示物理地址的位宽;bo表示偏移量的位宽。
1.2 L2 Cache的读写策略
对L2 Cache的访问由处理器核中的一级缓存L1 Cache发起,L1 Cache与L2 Cache直接通过高级可扩展接口(advanced extensible interface,AXI)总线协议进行握手操作。L2 Cache采取读贯穿策略处理读取缺失,采取直写策略处理写命中,采取写不分配策略处理写缺失[8]。
1.3 L2 Cache的替换算法
对于4路组相联而言,如果采用经典的LRU算法,需要为每一组设置对应位置来记录每一路的使用状态,造成逻辑资源的大量消耗。改进后的LRU算法,如伪LRU(pseudo-LRU,PLRU)替换算法[9]、改进的伪LRU替换算法MPLRU (modified pseudo-LRU)[10]和PLRU-0(pseudo-LRU-0)[11]等算法可以在使用资源较少的情况下,达到接近经典LRU算法的性能。根据在不同情况下替换结果的准确率,对PLRU、MPLRU和PLRU-0等3种算法测试比较发现,PLRU-0算法的替换结果更加接近于LRU替换算法,故采用PLRU-0算法作为L2 Cache的替换算法。
1.4 路预测
在计算机系统中,大部分访问存储的操作都是载入操作,即大部分的处理器指令不会对存储器有写入操作。一般在无内部互锁流水级的微处理器(microprocessor without interlocked piped stages,MIPS)程序中,存储指令操作占10%,载入指令占26%。在存储器通信的总流量中,写入操作流量约占10%。根据读取操作对缓存进行优化可以获得计算性能的提升[12]。
采用路预测技术后,4路组相联的L2 Cache综合了直接相联的优点。在Cache访问时,采用直接相联的方式访问预测的路,预测成功后返回数据,缩短了命中时间,即使预测失败也不会造成额外的延迟。
2 硬件电路设计
设计的L2 Cache主要由哈希选择模块、片上网络(network-on-chip,NoC)接收模块、仲裁器模块、标识匹配模块、缓存行获取模块、缺失Buffer模块以及写入缓冲区模块组成。设计的L2 Cache整体硬件架构示意图如图1所示。

图1 L2 Cache硬件架构
2.1 哈希选择模块
由于L2 Cache数量可配置,当存在多个L2 Cache时,需要对当前请求访问的L2 Cache进行判断。以512 kB大小的L2 Cache为例,可以有1个512 kB的Cache块、2个256 kB的Cache块和4个128 kB的Cache块3种配置方案,即L2 Cache通过改变配置字段L2_config将L2 Cache数量配置为1、2或4个,每一种配置都对应着Model 1、Model 2和Model 4中的一种L2 Cache的选择方法,L2 Cache ID与模式选择方法如表1所示。
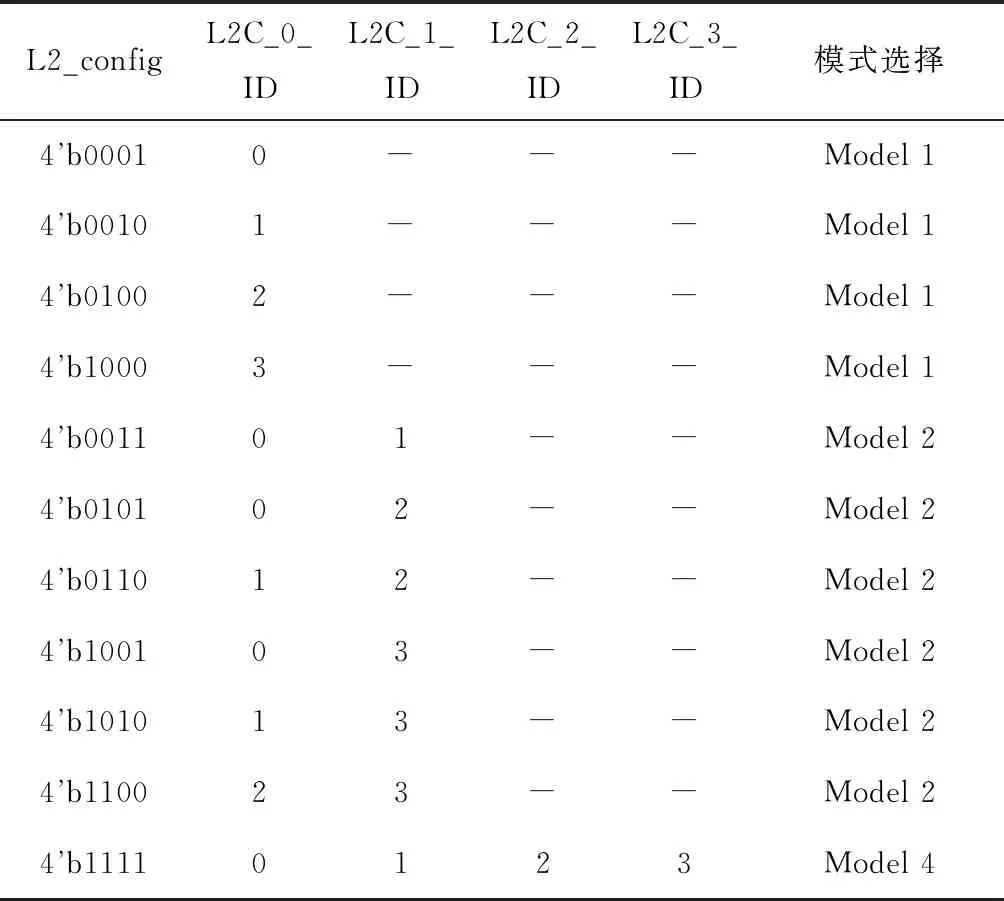
表1 L2 Cache ID和模式选择方法
根据当前L2 Cache的配置对地址进行位哈希运算,得到不同配置模式下选择L2 Cache的方法Model 1、Model 2、Model 4,分别对应使能1个、2个和4个L2 Cache的模式。访问L2 Cache地址的具体计算方法示意图如图2所示,其中Abus代表地址总线。

图2 哈希选择计算方法示意图
2.2 NoC接收模块
NoC接收模块负责接收来自片上网络的L2 Cache读请求、写回请求和写请求。来自片上网络的读请求事务信息包含读有效信号、读地址和读事务ID等信息。写请求是对L2 Cache某个地址的写操作,写回请求是L1 Cache中为“脏”的数据在替换时向L2 Cache发出的写回请求,以保证二者数据的一致性。写回请求和写请求包含写有效信号、写地址、写数据和写事务ID等信息。NoC接收模块通过对读请求、写回请求和写请求进行缓存处理,保证L2 Cache每处理一个请求时其他请求不会丢失,同时输出对应事务的事务信息传递给仲裁模块进行仲裁。处理读请求、写回请求和写请求的结构相同,以读请求为例说明其原理,NoC接收模块中的读请求原理示意图如图3所示。

图3 NoC接收模块读请求原理
2.3 仲裁模块
仲裁模块会接收来自互联网络和任务控制总线(job control bus,JCB)上的各种请求并进行仲裁处理,具体包括写请求、写回请求、读请求、JCB总线请求和重匹配请求等。仲裁模块会对这些请求进行优先级的判断,输出最终送往Tag_tp模块的事务。仲裁模块结构示意图如图4所示。

图4 仲裁模块结构
2.4 路预测模块
路预测模块的作用是对读取操作采取预测处理。在组相联的Cache中,对当前命中的路进行预测,以有效地减少延迟。采用路预测时,若预测成功,可以减少Tag匹配的时间,即使预测失败,延迟增加也较小,失败代价为多访问一次数据随机存取存储器(random access memory,RAM)的时间。
2.5 标识匹配模块
标识匹配模块主要进行访问地址Tag的匹配、LRU状态的更新以及根据当前LRU状态选择合适的LRU块进行替换。标识匹配模块中主要包含LRU_UPDATE模块和LRU_REPLACE模块。标识匹配模块结构示意图如图5所示。

图5 标识匹配模块结构
LRU_UPDATE模块根据当前访问的缓存块来进行LRU状态的更新。每当对一个缓存块进行访问或者替换时,都会根据hit_way或者vict_way更新LRU信息,以此来保证LRU状态保存的是当前最新的LRU块。
LRU_REPLACE模块主要根据读取的LRU状态来计算当前所要替换的路vict_way,并将从内存中读取回来的数据写入RAM中所要替换的数据块。
整个Tag的匹配过程是一个4级流水线。首先,根据arb_trans_addr[16:6]读取4路组中的Tag和State。其次,进行请求地址与Cache本身Tag的匹配。再次,根据当前请求命中情况进行读写操作。最后,将产生信号进行一级缓冲,输出RAM更新信息。
2.6 缓存行获取模块
缓存行模块主要负责在发生读取缺失时,将缺失地址等信息通过AXI总线发送给内存,取出数据后写回到对应需要替换的缓存块。该模块需要缓存读取缺失时的地址以及需要替换的缓存块号,以保证数据返回后写入Data_RAM的位置正确。缓存行获取模块结构示意图如图6所示。
lf_buffer主要缓存读取缺失需要替换的缓存块信息,即每次缺失需要替换的缓存的组lf_line和根据PLRU计算出来的需要替换的路lf_way。AXI模块是对当前事务信息进行处理,得到标准的AXI读地址通道信息。

图6 缓存行获取模块结构
2.7 缺失buffer模块
缺失buffer负责缓存请求缺失的地址和ID。由于采取读贯穿策略,当前读取请求缺失时会将缺失地址发送给内存请求数据,在请求数据返回Cache后会将本次缺失地址发送给Cache再次进行匹配,缺失地址采用先入先出的形式发送给Cache。
2.8 写入缓冲区模块
L2 Cache在写命中时采用直写策略,在写缺失时采用写不分配策略。无论写入操作是否命中,写操作的内容都必须发送到内存。由于内存的写入操作时间过长,L2 Cache需要等待写入内存完成才能继续工作,为此引入写入缓冲区。当写入缓冲区为空状态时,写地址和写数据存入写入缓冲区,处理核默认写入操作完成,继续处理其他请求,实际写入操作由写入缓冲区完成。当写入缓冲区为满状态时,缓存必须等待写缓冲区中的项目写入内存,直到写入缓冲区有空,写入缓冲区模块结构示意图如图7所示。

图7 写缓冲区模块结构
3 测试结果及分析
使用Xilinx Virtex UltraScale系列的XCVU440平台对搭载可重配置L2 Cache的统一渲染架构GPU进行测试。XCVU440平台有432 680个逻辑单元、88.6 Mb的BRAM、2 880个DSP Slices和6个PCIe嵌入式IP硬核,是常用的GPU性能测试平台。由于XCVU440测试平台的板载资源有限,将待测试GPU架构中L2 Cache的总大小固定为512 kB,根据L2 Cache的可配置性,将L2 Cache的大小及数目分为1个512 kB、2个256 kB以及4个128 kB三种情况。
渲染任务选用了“兽人”“花瓣”“甜甜圈”“猴子”“汽车”等5种较为典型的OpenGL ES 2.0应用程序,渲染任务如图8所示。

图8 渲染任务
测试得到的不同配置情况条件下L2 Cache的命中率如图9所示。


图9 L2 Cache的命中率
可以看出,渲染任务“兽人”所需要处理的顶点个数为39 356个,顶点个数较多。单个L2 Cache容量较小时命中率较低,当逐渐增大L2 Cache容量并减少Cache个数时,内存能映射到L2 Cache的存储块增多,导致命中率有着较大提升。当单个L2 Cache容量从128 kB提高到512 kB时,命中率有将近4%的提升。
渲染任务“花瓣”“甜甜圈”中所需要处理的顶点个数分别为789个和1 985个,绘制过程中处理重复数据次数较多,且数据之间的相关性较高,Cache的命中率较高。由于数据量较少,单个L2 Cache大小的升高反而不会导致命中率有更大的提升。
渲染任务“猴子”中所需要处理的顶点个数为14 985个,且数据之间相关性较小,单个Cache容量较小时,命中率不高。当Cache容量从128 kB增加到512 kB时,命中率约提升了2.5%左右。
渲染任务“汽车”中所需要处理的顶点个数为27 956个,且图形中具有较多镂空,在运行过程中会造成Cache数据的多次替换,具有较少的重复数据,较小的单个Cache容量不利于命中率的提高,其命中率在单个Cache大小为512 kB时约为70.88%,达到最大。
为了进一步验证算法的性能,与文献[14]嵌入式平台统一渲染架构GPU中不可配置L2 Cache的性能进行比较。文献[13]选用“斯坦福兔”“牛”“犹他壶”图形作为渲染任务。为了方便对比,选用同样的渲染图形作为测试用例,统一设置L2 Cache总容量为512 kB。在3种渲染渲染任务中,“斯坦福兔”模型中的三角形有69 451个,是3种测试用例中最多的,在配置时选用单个Cache大小512 kB的模式;“牛”模型中的三角形有5 804个,在3种测试用例中处于居中位置,在配置时选用2个256 kB Cache大小的配置模式;“犹他壶”模型使用的三角形有1 024个,是3种测试用例中最少的,在配置中选用4个128 kB大小的Cache配置模式,命中率与文献[13]对比结果如表2所示。
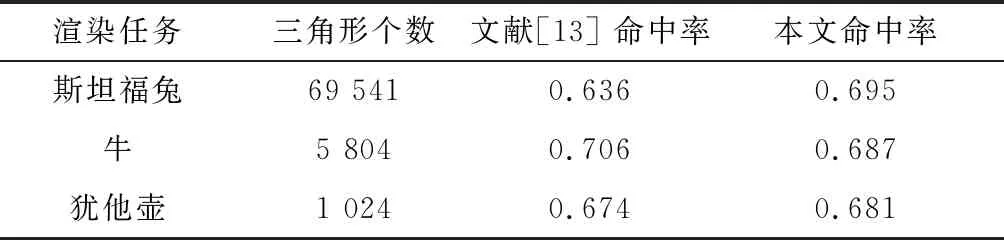
表2 命中率对比结果
得益于更为合理的替换算法,“斯坦福兔”和“犹他壶”模型测试得到的命中率相较于文献[13]分别提升了9.28%和1.03%,“牛”模型测试得到的命中率有所下降,但更小的单一Cache容量能够有效降低数据替换过程的时间、功耗等代价。
4 结语
针对统一渲染架构GPU在不同应用场景下缓存需求差距较大的问题,提出了一种统一渲染架构GPU中可配置L2 Cache设计方案。采用4路组相联映射方式配置L2 Cache结构,应用读贯穿策略处理读缺失,分别使用写不分配策略及直写策略处理写缺失及写命中,采用路预测和PLRU-0替换算法提升结构性能,应用哈希选择算法,根据不同的应用场景配置统一渲染架构GPU内部Cache的大小和数目,最终实现了128 kB、256 kB、512 kB 三种L2 Cache大小及数目的配置模式,实现了主存和缓存之间的高效数据交换。经过系统级测试,与不可配置L2 Cache方案相比,所提设计方案能够为统一渲染架构GPU提供多种存储结构优化方案,使其在不同应用场景下,能够合理划分内部资源,在降低Cache数据替换代价的同时,有效地提升了GPU中缓存结构的性能。
