基于图遍历的计算DEM数据洪水淹没范围的算法
2020-04-01王思雪李英成刘沛耿中元孙新博
王思雪,李英成,刘沛,耿中元,孙新博
(1.航空遥感技术国家测绘地理信息局重点实验室,北京 100039;2.中测新图(北京)遥感技术有限责任公司,北京 100039)
0 引言
我国是一个地貌复杂多样的国家,山川河流纵横交错,洪水灾害常伴随强降雨发生,尤其是南方近河流地区发生比较频繁。无论是灾害预警还是应急救灾,及时有效地获取洪水淹没地区范围,对保障人民生命和财产安全有重大意义。近年来,国内外已广泛利用GIS、RS、LiDAR、SAR等手段对洪水淹没范围进行预测和评估[1-4]。在以通过各种手段获取并经过处理得到的DEM为栅格影像数据进行洪水淹没分析时,有静态水平面[5]和建立水动力学模型[6]2种方法,根据静态水平面计算淹没范围相比于基于水文、水动力学构建的洪水演进模型的方法来说,精确度不如后者,但是实用性强,在防洪抗洪工作中有较大的实际意义。
静态水平面法按给定水位的“水平面”计算淹没范围,分为无源式淹没和有源式淹没2种方式。无源式水淹分析算法通过将DEM中高程点低于设定水位的视为淹没点。有源式淹没则需考虑水淹区域的连通性,将高程低于设定水位并与指定位置有连通的DEM格网点视为淹没点,我国近河流地形条件的复杂性决定有源淹没更具有适用性。刘仁义等[7-8]采用种子蔓延法通过给定的种子点(即指定淹没源)按照四邻域或八邻域进行扩散找到邻接的低于给定水位高度的连通点,所有连通点的集合就是淹没区范围。杨启贵等[9]采用分块种子蔓延算法对DEM数据进行将研究区域分成预先设定大小的块,对所有的正方形块内使用种子蔓延法计算,对相邻块间判断连通性,最后通过包含初始种子点的淹没区以及其所对应的关联表来提取出整个淹没区。沈定涛等[10]采用分块压缩追踪法将研究区域划分为条带,将条带中每行中高程值低于设定水位的相邻网格单元进行游程编码压缩,在较大程度上降低了栅格数据量,由种子点压缩单元开始,以压缩单元两侧作为追踪边,在不同条带上进行追踪,最后提取栅格场上被追踪过的所有压缩单元即可构建淹没区。
在分析了几种洪水淹没算法后,考虑到处理系统可靠性和算法安全性,对算法进行了如下设计:在DEM数据读入时进行分条带读入计算机内存,在数据压缩方式上采用了块码压缩将潜在连通块标记并将条带序列化为二进制流存入磁盘,在搜索连通区域时,将遍历到的条带从磁盘反序列化释放到内存,利用求解图的连通性问题的思路,采用图遍历的广度优先搜索法进行连通区域的递归查找。程序上通过设定的洪水水位、选定种子点计算某个区域内的淹没范围。选取北京市、四川省的DEM数据进行实验,与种子蔓延算法和分块种子蔓延法进行比较,最后输出淹没区所在条带的DEM,实现了快速计算和减小内存占用的效果。
1 算法设计
1.1 算法基本思路
DEM是以栅格形式存储的地形数据,其表示形式包括规则矩阵格网和不规则三角网,本文研究的DEM是规则格网形式的,由一系列地面点及其所具有的高程组成,在计算机高级语言中,它就是一个二维数组或者数学上的一个二维矩阵{Zij}[11-12]。
当大范围DEM的数据量较大时,一次读入和输出通常会造成对内存很大的占用,容易造成系统崩溃。考虑到系统安全性,采取对DEM数据进行划分,分次读入和分次输出。划分方式可以按行列划分为规则矩形,可以按行划分为条带。考虑到本文需要将DEM数据分批次由磁盘读入内存,再经过将潜在淹没栅格存入磁盘待调用,故使用将DEM划分为条带的方法,使其能更方便地存储和调用,且按条带比按规则矩形更容易实现辨别水流横向上连通关系,减少循环迭代的判断次数。
算法主要分为数据压缩存储阶段和查找连通区阶段。矩阵格网DEM具有可进行压缩存储的特点,基于这个特点,本文在数据压缩存储阶段,对每条带内不同行和列的低于某个高程值的相邻像元(具有潜在连通性的淹没栅格)形成的面实体以块码压缩存储,即采用方形区域作为记录单元,每个记录单元包括相邻的若干栅格,数据结构由初始位置(行、列号)和半径,再加上记录单位的代码组成[13]。块码在合并、插入、检查延伸性、计算面积等操作时有明显的优越性。
图遍历方法是数据结构中求解图的连通性问题、拓扑排序和求关键路径等算法的基础。图的遍历方法目前有深度优先搜索法和广度优先搜索法2种算法[14]。广度优先搜索是从图的某个顶点出发,访问该顶点后依次访问其相邻的未被访问的点,然后分别从这些邻接点出发依次访问它们的邻接点,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中还有顶点未被访问,则另选图中一个未被访问的低点作为起点,重复上述过程,直到图中所有顶点都被访问到为止。深度优先搜索与广度优先搜索类似,只是在遍历顺序上是以顶点访问后的邻接点出发,使用深度优先遍历图。图遍历的实质就是对每个顶点查找邻接点的一个递归的过程。本文在查找连通区阶段使用广度优先搜索法由种子点所在块(简称种子块)作为顶点出发找到邻接块,再由访问后的块找到邻接的未访问到的块,所有被访问的块构成的集合就是有源淹没的淹没范围。本文算法的基本思路如图1所示。
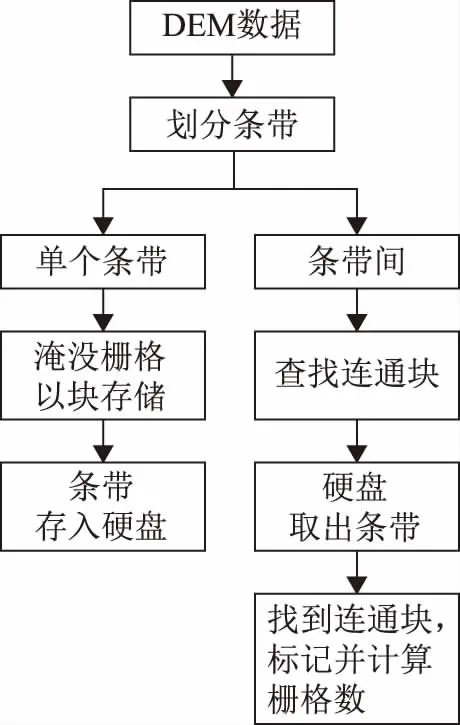
图1 算法基本思路链图
由于水流本身蜿蜒曲折的特点,单个条带肯定会被多次重复搜索淹没栅格,故本算法首先由种子点所在条带(简称种子条带)开始,确定每个条带内所有具有潜在连通性的淹没栅格,压缩成块,块作为判断条带间连通性的基本形式。条带以块为组成,块由压缩单元组成。
本算法定义的条带间连通条件:块顶端(块头)存在行号等于所在条带首行行号的压缩单元,或者块末端(块尾)存在行号等于所在条带末行行号的压缩单元。
本算法定义的条带上下追踪条件:条带内存在行数等于条带栅格行数的块,可以向上一条带或者下一条带继续追踪满足条带间连通条件的块。
将满足条带上下追踪条件的条带由内存写入磁盘,再由种子块开始在条带间循环遍历,找到不同条带间连通的淹没压缩块,从磁盘将数据调出来,标记条带内满足追踪条件的块头和/或块尾并计算块内栅格个数,经过多次循环迭代最终计算得到整个淹没连通区的范围大小。算法分为数据压缩存储和查找连通块2个阶段执行,如图2所示。

图2 算法示意图
数据压缩阶段:
①读取种子点的条带1,对种子点所在栅格进行数据压缩得到块0。如果块0符合连通条件,即种子点选取合适,在该条带从左到右遍历找到符合连通条件的块1、块2,然后该条带存入磁盘。
②对条带1上条带的栅格执行数据压缩和存盘,并依次向上方条带执行,直到条带的顶栅格行中无压缩单元。
③对条带1下一条带执行数据压缩和存盘,并依次向下方条带执行,直到条带的底栅格行中无压缩单元。
查找连通块阶段:
①将条带1从磁盘取到内存,由块0的顶部压缩单元向上一条带搜索(条带0取到内存),找到条带0中块1、块2,标记块底压缩单元,并向下一条带搜索,找到条带1中满足连通条件且未标记的块1,标记其块顶压缩单元。由条带1中块1向上一条带搜索,无未标记连通块,结束查找。
②由条带1中块0的底部2个压缩单元向下一条带搜索(条带2取到内存),找到条带2中块0,标记块顶压缩单元,因其块底压缩单元不在条带底部,不满足条带上下追踪条件,结束查找。
③对条带0~2中所有满足条带上下追踪条件的被标记的块,通过读取块结构内栅格总数计算得到淹没面积,并记录有效条带号(0~2)。
1.2 数据压缩存储
数据压缩存储的算法流程图如图3所示。由种子条带开始,读取种子条带的DEM栅格数据,开始遍历所有淹没栅格,并将每行中连续淹没栅格记录成一个压缩单元DataCell,压缩单元内记录起始列号、终止列号、行号、编号。
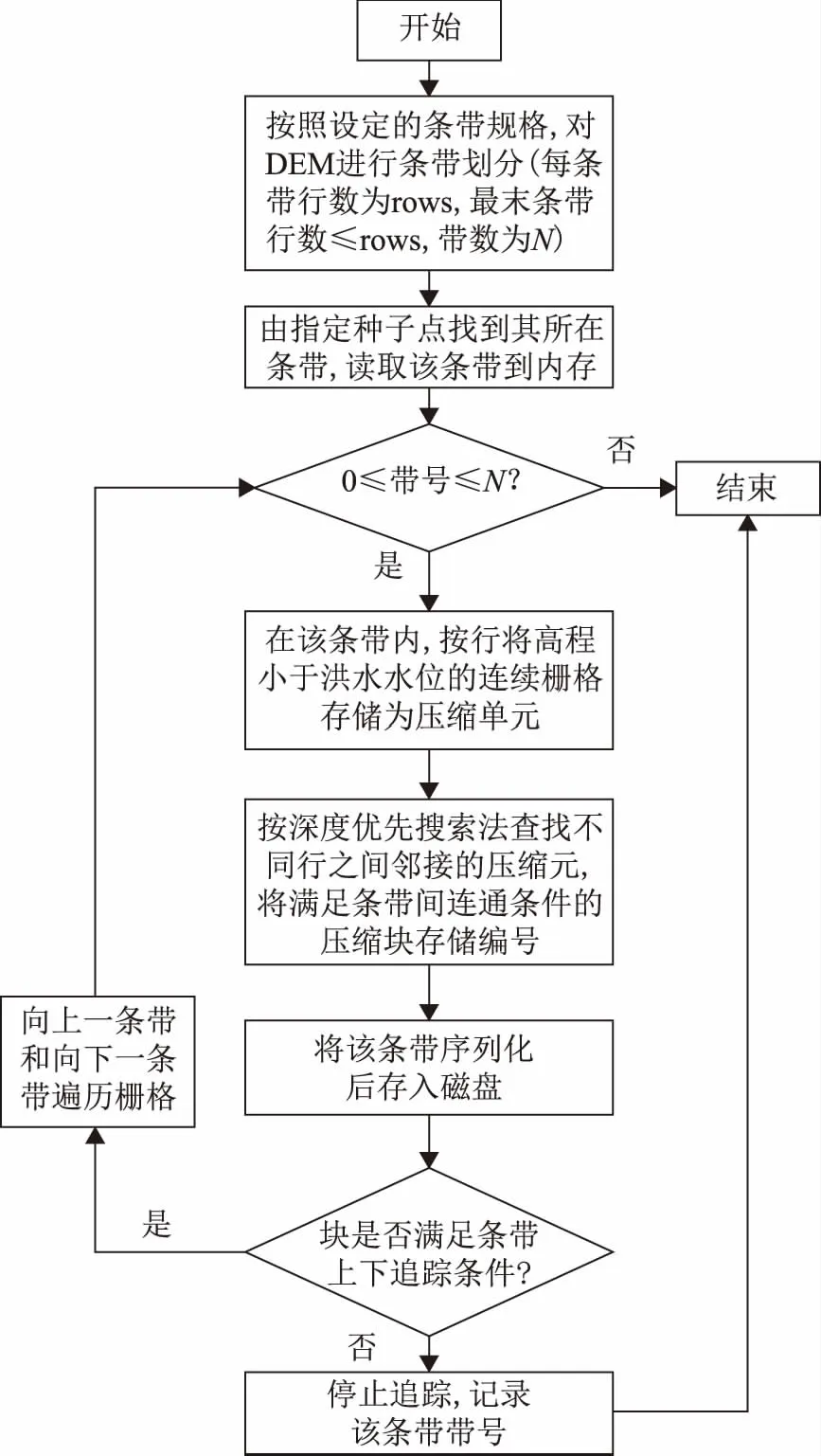
(注:图3默认选取的种子点是淹没点,种子块满足条带间连通条件。)图3 数据压缩存储流程图
栅格点结构如下:
public class Point
{
public int x; //列号
public int y; //行号
public double elevation;//像素值(高程值)
}
压缩单元结构如下:
public class DataCell
{
public int columnStartId;//起始列号
public int columnEndId;//终止列号
public int rowId;//行号
public int cellId;//压缩单元编号
public bool isFlood;//是否已标记
}
以种子点所在的压缩单元为顶点,用深度优先搜索法将不同行之间的相邻压缩单元压缩成块,块内以链表形式存储块头和块尾的压缩单元,并记录块内栅格行数、块号、条带号、栅格总数。
块结构如下:
public class Lump
{
public Queue
public int rowsNum;//块内行数
public int lumpId;//块的编号
public int stripeId;//所在条带编号
public int pointsNum;//块内栅格总数
}
对条带内满足条带间连通条件的块按从左到右、从上到下的顺序进行编号,将不满足条带间连通条件的块舍弃,条带以链表形式存储已编号的块。
条带需满足条带上下追踪条件。具体地,如果种子条带的顶栅格行有被编号的块,向种子条带的上一条带执行同样方式的压缩存储,并以此一直向上执行,直到向上的条带内没有满足条带上下追踪条件的块,表示已不能再继续向上追踪,向上搜索结束,记录最小截止条带号TStripeId。
同样地,如果种子条带的底栅格行有被编号的块,向种子条带的下一条带执行压缩存储,并以此一直向下执行,直到向下的条带内没有满足条带上下追踪条件的块,结束向下搜索,记录最大截止条带号EStripeId。
1.3 查找连通块
查找连通块的算法如图4所示。为了在遍历过程中标记块头和块尾压缩单元是否是连通的,需设置布尔对象isFlood,初值设为“false”,当访问到该压缩单元时值为“true”,表示是已标记的连通的压缩单元,避免重复运算。若块头或者块尾存在已标记的压缩单元,代表该块为淹没块,若已标记块的行数等于所在条带行数,则表示该块满足条带上下追踪条件。

图4 查找连通块流程图
根据条带号从硬盘将种子条带反序列化到内存,在上下截止条带号区间内,由种子块开始,取种子块头压缩单元(多个DataCell)加入队列,取种子条带顶栅格行上所有压缩单元和其上一条带(反序列化从磁盘读取出)底栅格行上的所有压缩单元放入搜索队列,用广度优先搜索找到与种子块(已标记)相邻接的压缩单元,进而找到对应的连通块。
同样地,取种子块尾压缩单元(多个DataCell)加入队列,取种子条带底栅格行上所有压缩单元和其下一条带(反序列化从磁盘读取出)的所有底栅格行上的压缩单元,通过条带之间邻接的压缩单元到对应连通块。
从种子条带开始,将所有相邻2个条带间的邻接两行(顶/底)满足追踪条件的块头和块尾压缩单元放入搜索队列。同时将满足追踪条件的该条带带号存入条带号队列,用于存储有效条带号。最后输出和显示有效条带间的淹没区域,减小输出DEM的大小。
如果已标记过一端的块满足条带上下追踪条件,将块的另一端未标记压缩单元也标记,递归使用广度优先搜索法对[TStripeId,EStripeId]条带间满足条带间连通条件的块进行搜索,最终得到连通区间有效截止条带号,并通过统计连通块的面积得到整个淹没区域面积。
2 实验与分析
本文使用VS2010.NET3.5平台,C#编程语言开发,为验证算法运行效率和内存占用,使用运行环境:Windows 64位,CPU为Intel 酷睿i5 5200u处理器,4 GB内存空间的笔记本做测试。
实验所用DEM数据选取北京地区DEM(数据包含的网格数8 621列×11 102行,数据文件大小100 MB)和四川省DEM(数据包含的网格数45 210列×25 201行,数据文件大小2.57 GB)做测试。划分条带数量过多会造成迭代次数多、计算机运行效率低。划分条带数量过少会使计算机一次读入内存的数据量大。经过多次实验,使用取素数的方法取得符合512×512大小内最大的行数,以整除为优先。设定北京地区洪水水位为250 m,四川省洪水水位为800 m,使用软件ERDAS IMAGINE 2013展示淹没区域。如图5所示,右侧叠加在原始DEM图上的白色区域,即为算法输出的淹没区域DEM。

图5 原始DEM和提取淹没区域后DEM对比
本次水淹分析的算法使用北京地区DEM和四川省DEM作为数据源,对种子蔓延法、分块种子蔓延算法与本文算法进行比较(其中运行平均时间包括计算淹没水面面积和输出淹没区域DEM)。
由表1可见,对栅格数据压缩成压缩单元明显提高了运行效率,内存占用最小,且采用本文只对有效影像条带区域输出的方法(图5),输出的淹没区域DEM数据相比于原始DEM在数据量上很大程度地缩小,有利于影像快速输出和传输。

表1 3种算法运算效率和内存占用对比
由表2可见,本算法在对于不同数据大小的DEM数据进行洪水淹没范围提取中兼顾了运行效率和防止内存溢出两方面的优势,内存占用几乎不受原始DEM数据大小限制。

表2 算法对不同数据大小的DEM处理效率对比
3 结束语
本文针对大区域DEM数据量较大而计算机性能有限的问题,使用块码压缩和图遍历的方法进行洪水淹没范围提取。实验结果表明该算法能有效地提取出洪水淹没范围,对内存的占用大大降低,DEM数据大小和个人计算机配置高低对算法的影响不大。本算法在输出生成的淹没区域DEM时,不需要预先生成与原DEM大小相同的空值栅格影像,只生成淹没条带间的区域,使得输出的影像大小比原始影像小很多,大大节省了磁盘空间,提高了传输效率。
