基于随机森林特征重要性的K-匿名特征优选
2020-03-13黄梅朱焱
黄 梅 朱 焱
(西南交通大学信息科学与技术学院 四川 成都 611756)
0 引 言
近年来,随着互联网技术和数据存储技术的快速发展,从数据中提取隐含的、具有潜在价值的信息变得更加便捷。数据挖掘技术常用于决策支持和科学研究,数据在拥有者和使用者之间共享屡见不鲜。然而,这些数据中可能包含了某些敏感隐私信息,如个体隐私、政府机密及商业情报等。如果将这些数据不加处理的发布共享,就会造成隐私信息的泄露。近年来,随着多起隐私数据泄露事件,如NetFlex的推荐比赛中用户观影记录泄露[1]、FaceBook与数据分析公司Cambridge Analytica的不当共享造成8 700万用户个人信息泄露[2]等,隐私保护技术得到极大关注,成为数据挖掘和信息安全领域的研究热点。
自隐私保护数据挖掘(Privacy Preserving Data Mining,PPDM)作为知识发现应用领域的一个核心问题,不断有学者对其进行研究,并试图制定提供隐私保护的模型,经典的包括K-匿名[3]、L-多样性和T-接近及差分隐私等。其中,K-匿名因其灵活有效,在隐私保护领域得到广泛研究。该模型最早由Sweeney等[3]提出,并提出使用MinGen[3]算法来选取最优泛化操作,使待发布数据满足K-匿名原则。韩建民等[5]针对隐私的敏感度提出了面向敏感值的个性化(a,K)-匿名隐私保护模型。这种方法对低敏感值的敏感属性使用较低的K-匿名约束,对高敏感值的敏感属性则用较高的K值进行约束,降低了单敏感属性因隐私保护而引起的信息损失。此外,许多研究者通过结合聚类实现K-匿名。Li等[6]应用聚类思想,依据合并泛化信息损失量最小原则,每次随机选取一个元组数小于K的类簇与另一个类簇进行合并,直至所有类簇的元组数大于等于K。Zhang等[7]提出在K-匿名聚类中应用信息熵,先将表数据聚类为不同的簇,然后将记录数小于1K的簇合并,大于2K的簇拆分,使每个簇的记录数在1K于2K之间,最后再对每个簇进行泛化。文献[8]根据泛化树层次的类别分别度量元组间和等价类间的信息损失,按照K值每次选择一条记录加入类簇,实现等价类的均衡划分。
K-匿名作为常用的隐私保护模型,泛化和隐藏是实现该模型的主要手段。上述方法均是采用泛化,即采用一个域更广的新值代替原始具体值,如年龄值24和34都可以泛化到区间(20,40]。泛化需要预先制定泛化层次,而不同的泛化层次对结果的影响较大。例如年龄24可以泛化到(20,30],也可以直接泛化到(20,40]。而隐藏一般在确定无法泛化到更高层级后才使用。比如性别特征取值只有“男”和“女”,没有更高的域值包含这两个值,那么直接从数据集中删除该特征或用“*”代替。不同于以往,文献[9]提出的Greedy_Hamdist算法,无需预先制定泛化层次,而是通过隐藏分类性能低的特征使特征子集对应数据集满足K-匿名,扩展了K-匿名实现的新思路。
本文受文献[9]的启发,提出一种基于随机森林特征重要性的分类性能度量方法,并结合K-匿名要求,用于选择满足K-匿名的特征子集,具体工作流程如图1所示。通过在两个真实数据集上进行实验,并与基于Greedy_Hamdist的特征选择算法比较可知,本文算法更有效地保证了隐私保护与数据挖掘性能之间的平衡,运行效率也更优。
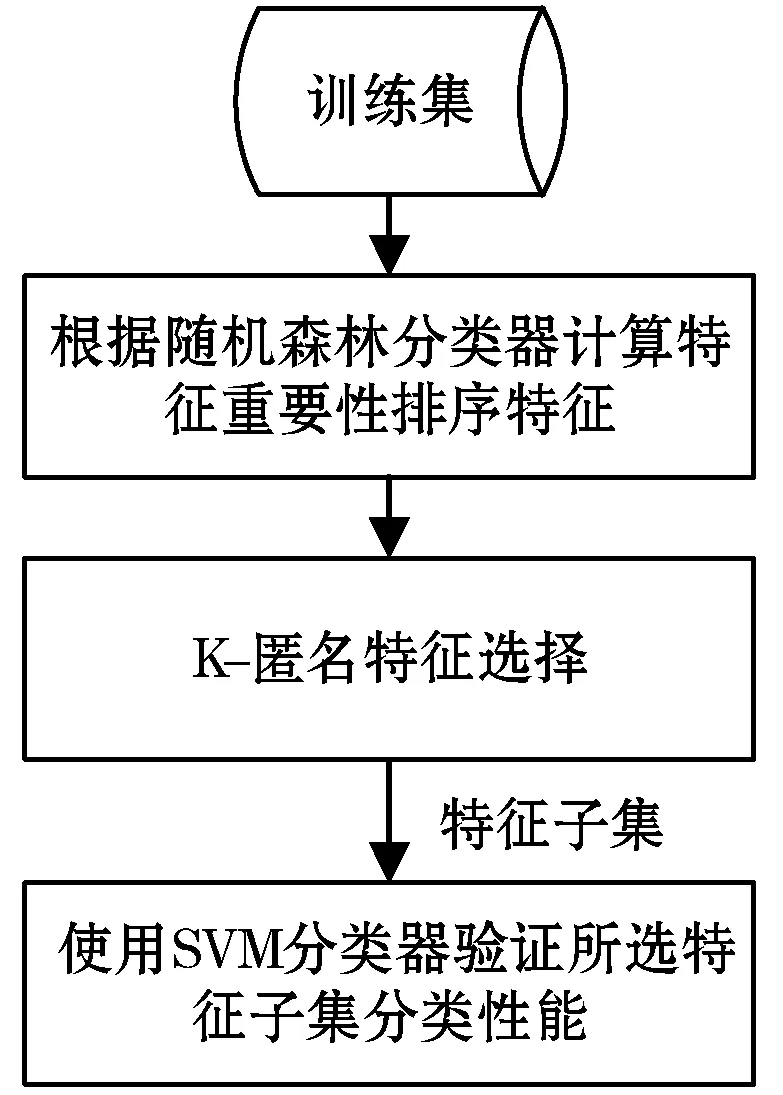
图1 工作流程
1 相关技术
1.1 K-匿名特征选择
K-匿名模型常用于抵抗链接攻击,该模型可以消除个体与敏感隐私信息之间的关联关系[3]。为方便讨论,假定待发布的数据表包含n个记录,属性集合由d个准标识属性和1个敏感属性构成。设T=(t1,t2,…,tn)为待发布的数据表,tj(j=1,2,…,n)为表中第j个元组。记A=(A1,A2,…,Ad)为表中所有准标识属性,Ai(i=1,2,…,d)为表中第i个准标识属性,AS为敏感属性,则数据表可以用表1表示。

表1 数据表
定义1(等价类) 在数据表中,具有相同A取值的若干记录组成的集合称为一个等价类,记为Ci,则有∀ti,tj∈Cw,有ti[A]=tj[A],i≠j,w∈[1,m]。其中m为等价类的个数。
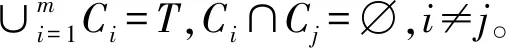
定义2(K-匿名) 将数据表T经匿名技术处理后,划分为多个等价类,每个等价类包含至少K条记录,则称数据表T满足K-匿名。
可见,K-匿名要求对数据表中任一元组,至少存在K-1个其他元组,它们在准标识属性上的取值相同,理论上侵犯者最多只有1/K的概率能够定位出个体用户所属的记录并获得敏感属性,即K值的大小决定了隐私泄露的风险,K值越大,隐私泄露风险越低,反之越高。
假设表2为待匿名数据集,由于每条记录与其他记录在准标识符属性上不具有相同的特征取值,所以数据集不满足2-匿名。但如果特征集为(A1,A2,A5)时,即表中灰色部分,数据集中的任意一条记录都存在至少1条其他记录与其取值相同,满足2-匿名。

表2 特征选择实现2-匿名示例
因此通过特征选择的方式,可以使数据满足K-匿名以达到隐私保护的目的。基于以上思想,可以使用特征选择得到合适的特征子集,使对应的数据集满足K-匿名。但是从全部特征中得到最佳匿名特征子集是NP完全问题[13],表2除了(A1,A2,A5)满足2-匿名条件外,(A2,A3,A4)也是满足2-匿名的。不同的特征子集具有不同的分类挖掘性能,为了使满足K-匿名的特征子集具有较好的分类性能,本文提出使用随机森林特征重要性度量特征的分类性能,并采用前向序列搜索策略选择特征。
1.2 随机森林特征重要性
随机森林(Radom Forest,RF)是一种基于Bagging的集成分类器,由多棵完全生长的决策树组成。在分类预测中,样本的类标由这些决策树输出类标的众数决定[10]。
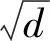
(1)
式中:pk表示第k个类标在数据中所占比例。|y|表示类标取值种类数。Gini(D)反映了从数据集D中抽取两个样本,其类别不一样的概率。所以,Gini(D)越小,数据集D的纯度越高。数据集D根据属性a分裂得到的Gini增益可由下式计算得到:
(2)
式中:V表示a的取值种类数,|Dv|则表示第v种取值对应的样本数。Gini增益最大化原理就是计算节点所有属性的Gini增益,并选择Gini增益最大的属性作为分裂属性。根据该原理得到的分裂属性可以使子节点数据集纯度最高,说明该属性的分类性能最好。分类性能越好的属性在特征集中越重要,因此特征的重要性可以根据决策树节点的划分体现。然而,由于随机森林的双重随机机制,仅使用属性在随机森林决策树中的出现频率来体现特征重要性不可取,因此为了更准确地反映出特征的重要性,本文选择基于OOB data分类正确率的方法度量特征的重要性。假设RF中有k棵决策树,则特征a的重要性可由以下步骤得出:
1) 初始时令k=1,采用自助重采样生成训练集和袋外数据集OOB,在训练集上构建决策树Tk;
2) 基于Tk对OOB数据进行预测分类,统计分类正确的样本数,记为Rk;
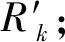
4) 令k=2,3,…,K,重复步骤1至步骤3;
5) 特征a的重要性可由下式计算得出:
(3)
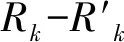
2 算法设计
为了保证数据匿名后还能保持较高的分类性能,本文提出使用选择随机森林度量特征的分类性能,对原始集的特征进行排序,并采用序列前向搜索的贪心策略,进行K-匿名特征选择。初始化特征子集为空,每次选择分类性最高的特征加入,并判断数据的匿名性,留下满足K-匿名的特征,否则剔除,直到没有特征可加入,最终得到满足K-匿名的特征子集。具体如算法1所示。
算法1RFKA(D,k)
输入:数据集D,隐私值K
输出:满足K-匿名的数据集D′
Begin:
1. 构建随机森林计算每个特征的重要性
2. 根据特征重要性对特征降序排序,得到F_IMP_List
3. 初始化特征子集sub={}
4. for F_IMP_List中的每个特征X:
5. sub=sub.append(X)
6.D′=D在sub上的投影数据集
7. if privacy_test(D′):
8. sub=sub.delete(X)
9.D′=D在sub上的投影数据集
10. 输出数据集D′
End
注意,数据集D只包含准标识属性,不包括敏感属性。算法第7行privacy_test(D′)对数据集D′进行了是否违反K-匿名的判断,判断条件是根据K-匿名的定义设计的,即任意一条数据都至少存在K-1条数据与其具有相同的准标识符。本文中的准标识符即样本在特征子集上的取值,所以privacy_test(D′)的具体实现如算法2所示,其中2~9行为等价类划分过程。
算法2privacy_test(D′)输入:数据集D′,隐私值k
输出:True或False
//True:满足,False:不满足
Begin
1. 初始化字典record={}
2. forD′中的每一个样本t:
3. 准标识符q=t的取值
4. ifq在字典中:
5. record[q]++
6. else
7. record[q]=1
8. end if
9. end for
10. for record字典中每一个等价类C:
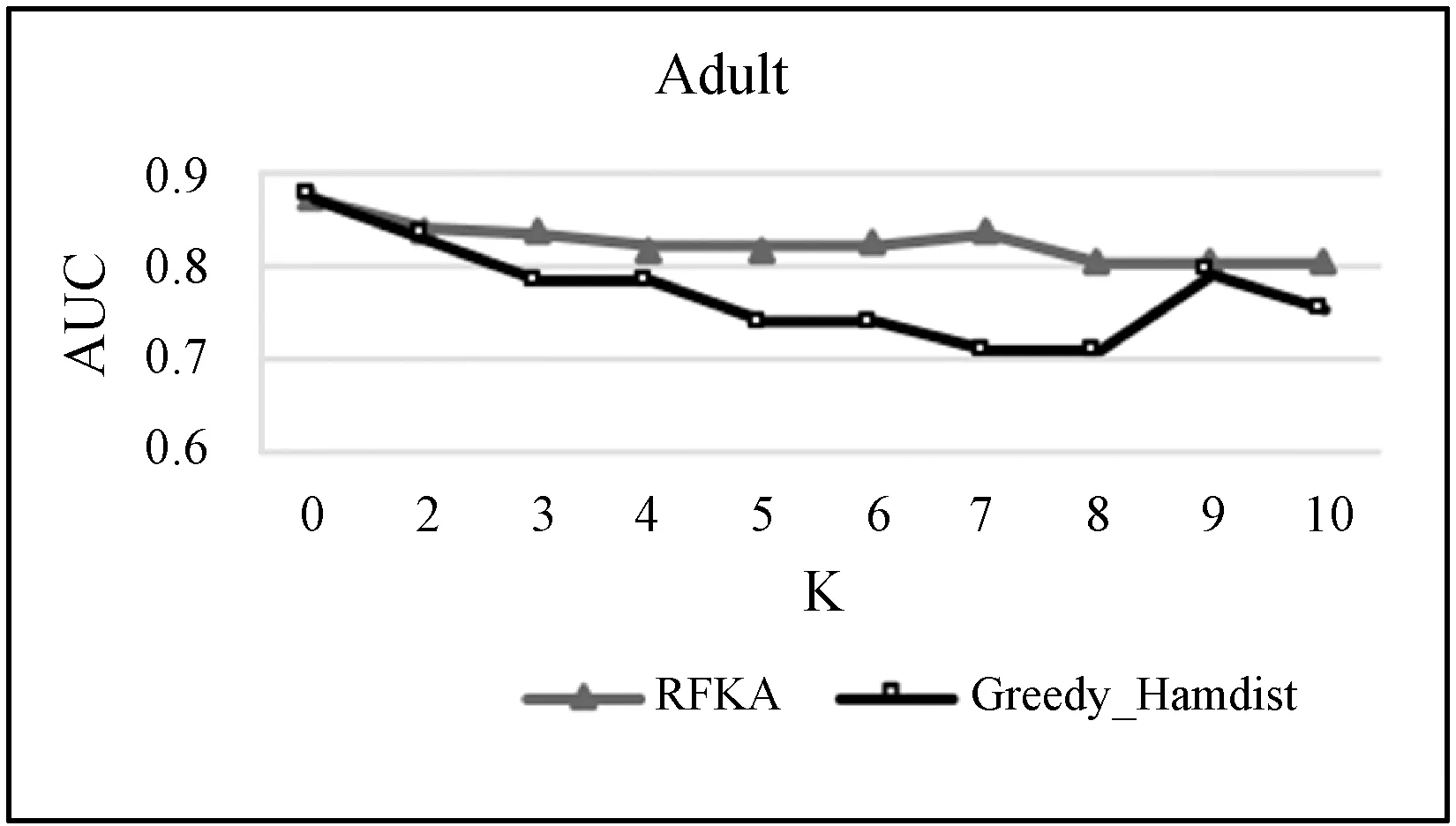
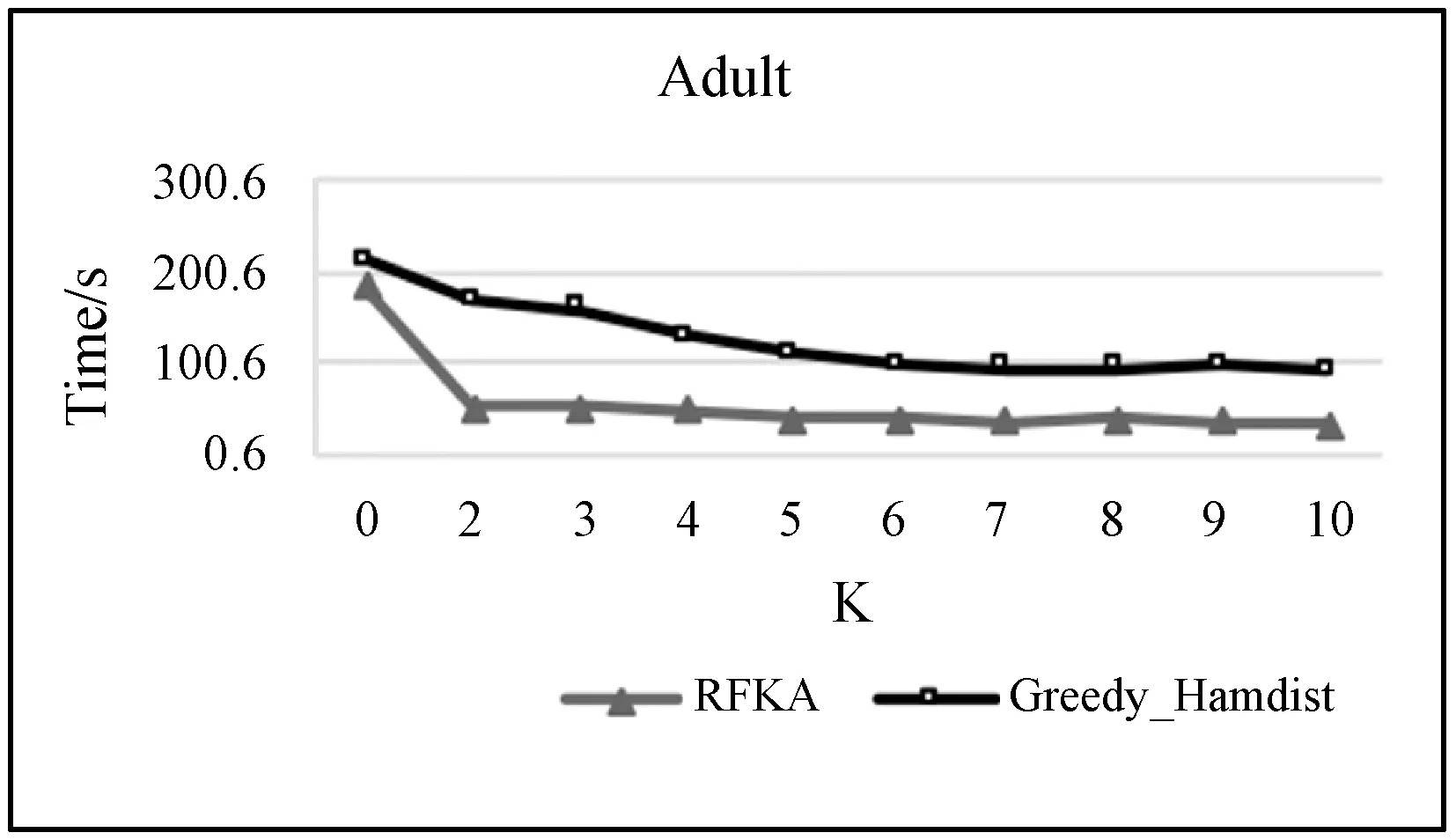
11. if len(C) 12. return false 13. end if 14. end for 15. return true End 为了验证本文算法能有效地平衡数据隐私保护程度与分类挖掘性能,本文选用了UCI两个经典真实数据集——乳腺癌数据集(Breast-Cancer)和Adult数据集进行实验,并将本文算法与文献[9]中的Greedy_Hamdist从分类性能和运行效率两个方面进行对比。乳腺癌数据集总计699条数据,本文将病态为良性的记录作为正类,恶性则为负类。将包括Clump Thickness、Bare Nuclei、Uniformity of Cell Size等在内的8个离散型属性均作为准标识符属性。Adult数据集为隐私保护领域常用的经典数据集,本文按正负类原始比例随机抽取2000条样本进行实验,正类为年收入大于5万的记录,负类为年收入小于等于5万的记录。属性集包括6个连续性属性,如Age、fnlwgt、education-num等,8个离散型属性,例workclass、marital-status、relationship等,本文将这14个属性均作为准标识符属性。两个数据集均不含有缺失值,分类的类标即为敏感属性。 由于Greedy_Hamdist只能处理二值数据,为了使本文算法与其更具有可比性,需要对原始数据中的连续型数据进行离散,然后进行OneHot处理。离散化采用常用的等距处理,如年龄值离散到(0,20]、(20,40]、(40,60]、(60,80]、(80,∞)。 为了验证本文算法选择的特征子集优于Greedy_Hamdist,本文使用ROC曲线下的面积AUC值分类指标客观地评价特征子集对应数据集的分类挖掘性能,此外,还会从运行时间对两个算法进行比较。 最后为了评价特征子集对应数据集分类挖掘性能,本文采用sklearn中默认设置的SVM分类器对特征选择后的数据进行分类,核函数设置为径向基函数,并使用五折交叉验证方式来保证分类的稳定性。随机森林的决策树数量n_estimators设置为1 000,使用袋外数据衡量训练集特征重要性oob_score为True,其余采用sklearn中随机森林的默认设置。实验环境为:Intel(R) Core(TM) i5-6200U CPU @2.30 GHz 2.40 GHz;4.00 GB(RAM)内存;Windows 10 64位操作系统。 算法均采用Python实现。 使用本文提出的RFKA算法与文献[9]中的Greedy_Hamdist算法分别在Adult数据集和Breast-Cancer数据集上进行不同K值下的分类实验,得到如图2和图3所示的实验结果。当K=0时,表示不对原始数据做隐私保护。随着K值越来越大,对应数据集的隐私泄露风险越来越低,隐私保护程度越高。由于剔除了原始数据中不满足K-匿名要求、但重要性高的特征,所以分类性能会降低,但本文的算法无论在K值为多少时,AUC都是大于等于Greedy_Hamdist算法的,说明使用随机森林度量特征重要性比Hamdist方法更优,更适合用于K-匿名的实现。 图2 Adult数据集在不同K值下的AUC值 图3 Breast-Cancer数据集在不同K值下的AUC值 在运行时间方面得到的实验结果如图4和图5所示。在两个数据集上,不同K值下,本文的RFKA算法所用时间均比Greedy_Hamdist更短,表明本文算法在实现K-匿名时的运行效率更优。 图4 Adult数据集在不同K值下的运行时间 图5 Breast-Cancer数据集在不同K值下的运行时间 本文借助随机森林特征重要性度量特征的分类性能,并结合K-匿名约束对数据实现特征选择,使得特征子集对应的数据集满足K-匿名隐私保护条件。实验结果证明,无论是从挖掘性能还是运行效率上,本文提出的算法都优于Greedy_Hamdist。 在隐私保护领域,K-匿名只是基础的隐私保护模型,因此可以考虑将特征选择结合其他模型实现隐私保护作为未来工作扩展,也可以提出更优的特征分类性能度量方法,进一步优化隐私保护与挖掘性能之间的平衡。3 实验设置
3.1 数据集与预处理
3.2 评价指标与实验设置
4 结果与分析
4.1 分类挖掘性能分析

4.2 运行时间分析

5 结 语
