分布式数据清洗系统设计
2020-03-07
(陕西科技大学电子信息与人工智能学院 陕西 710021)
1 引言
随着大数据的发展,数据[1]已经成为一个企业的生存根基,对于企业来说,合理的利用所掌握的数据资源,对企业的未来发展至关重要。数据仓库[2]技术作为海量数据的存储之地,为企业进行数据分析[3]时提供了一种解决方案,而在数据仓库的构建中,数据清洗[4]则为最重要的一个环节。
数据清洗分为三个步骤,即抽取[5]、转换[6]、加载[7]。当数据量增大时,传统的清洗技术已无法满足企业之间的技术支持,所以本文结合MapReduce 分而治之的思想[7]设计出分布式数据清洗系统,具体如下:
(1)使用Hadoop 集群、HDFS[8]、MapReduce 等大数据相关技术进行集群搭建,然后将清洗后的数据加载到Hive[9]数据仓库中。
(2)采用前后端分离思想对分布式数据清洗系统进行流程设计、架构设计、功能设计。
(3)采用改进后的分区聚合算法对Reduce 操作进行优化,避免数据在清洗过程中造成数据积累,从而发生数据倾斜等问题。
2 分布式数据清洗系统设计
2.1 流程设计
分布式数据清洗系统以MapReduce[10]为设计核心,MapRduce将采集过来的日志数据通过Map和Reduce 进行操作,Map端从HDFS 分布式文件系统中读取文件,然后将这个文件进行分割,不同的分片执行不同的Map 任务,再经过shuffle 阶段进入到Reduce阶段进行聚合操作,流程图如图1所示:

图1 MapReduce 流程图
具体操作步骤如下:
(1)从HDFS中读取文件,将这个文件进行分片,划分成多个Key/Value 键值对。
(2)Map 根据Key计算Value值,然后进行统计。
(3)Combiner对每个分区Map所对应的key值进行聚合,将Map端的输出作为Combiner的输入。
(4)Partition 针对分片进行处理,将Combiner 统计出的key 进行分区。
(5)Reduce 完成最终的数据聚合,存入数据仓库中。
2.2 架构设计
由于分布式数据清洗系统是对接日志分析的子系统,其数据最终加载到数据仓库中,所以在视图层将不做深入探讨,只将清洗过后的数据展示出来。按照分层思想将从四个层级进行设计,分别为视图层、控制层、业务处理层、存储层,并包括两个主要的子系统模块,分别是Mysql后端数据管理模块和以MapReduce计算为主的数据清洗模块,系统架构图如图2所示。
如图2所示:系统总体设计包括视图层、控制层、业务处理层以及存储层四个层次。
(1)视图层:主要是显示清洗过后的数据,前端界面采用HTML、CSS、JavaScript、JQuery[11]、Ajax[12]进行设计。
(2)控制层:在数据清洗过程中通过Map和Reduce 操作对海量数据实现快速过滤,去重,并采用改进的分区聚合算法来提高清洗效率。
(3)业务处理层:主要进行海量数据的批处理,数据集为旅游景点产生的log日志,通过Flume 将日志数据从服务器中采集过来上传到HDFS中,运用Mapreduce 编程对日志数据进行抽取、转换、加载等操作,完成一系列的清洗功能之后,存储到数据仓库中。
(4)存储层:保存清洗之后的数据,存储工具包括HBase[13]、Hive、Mysql 等,为视图层提供数据支持。
2.3 功能设计
分布式数据清洗系统包括数据界面展示模块,数据清洗模块、资源管理模块、配置模块等。本系统应用于各子系统并结合改进的分区聚合算法对大批量数据进行清洗,以保证日志数据的精准度和提升数据的清洗效率。分布式数据清洗系统功能模块图如图3所示:

图3 分布式数据清洗系统功能模块图
分布式数据清洗系统主要用于大数据集群之间节点配置、数据清洗之后的资源统计,系统登录之后分为超级管理员和普通管理员两类,超级管理员可以执行所有权限,普通管理员可以进行集群配置和日志数据的清洗,数据清洗管理主要通过MapReduce 进行清洗,结合算法进行优化,将清洗之后的数据存储在数据仓库中,资源统计管理进行数据展示以及数据统计。
3 清洗技术
3.1 数据清洗概述
数据清洗主要是对脏数据进行一个重新检查、去重、过滤的过程,其中主要经过数据抽取,数据转换,数据加载三个阶段,目的在于删除不合格数据,只保留有用数据,因为本文抽取的是从web网站中生成的日志数据,所以相对而言主要是提高数据清洗的转换效率。
针对清洗的转换效率进行研究,重点解决数据倾斜效率问题。
3.2 改进的分区聚合算法
聚合处理一般发生在Shuffle 阶段,在MapReduce中,Shuffle操作执行前的Map 被分为一个阶段,执行后Reduce 会分为一个阶段,但在一些情况下,由于第一阶段产生的数据中,某些字段的Key值过大,那么在聚合时,就会出现99%的分区已经执行完毕而1%的分区执行时间过长的现象,就会出现数据倾斜。
如图4所示:

图4 Shuffle 发生数据倾斜
从图4中可以看出,Shuffle 操作过程中,按照Key 键对数据进行重新划分,其中Key(Tom)对应的数据量远远大于key(Name,China)的数量,这将导致后续数据清洗过程中,Task1的清洗时间远远超过Task2和Task3的运行时间总和,从而造成数据倾斜甚至内存溢出。
基于上述问题,本文提出改进后的分区聚合算法,将聚合阶段分成两阶段,先局部聚合,再全局聚合。算法执行示意图如图5所示:
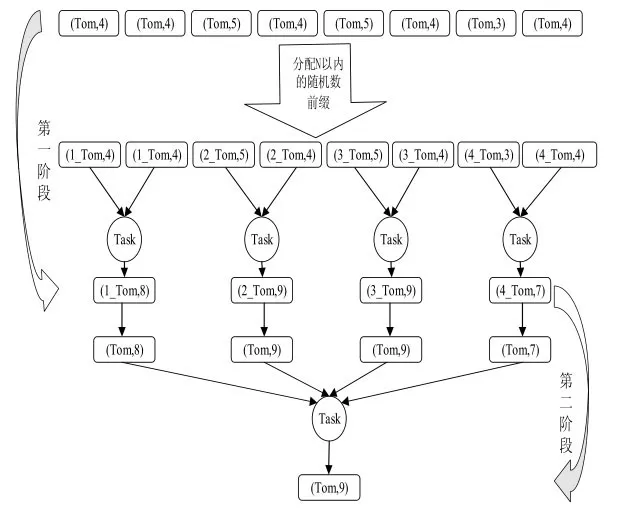
图5 数据预处理算法
如图5所示:第一阶段对Key(Tom)加上N 以内的随机数前缀,此时将Key(Tom)分散成N 份,然后对N 份Key(Tom)进行局部计算,产生N个计算结果。第二阶段去除N 份Key(Tom)的随机数前缀,然后做全局聚合,最终计算出结果。
4 实验分析对比
4.1 实验环境
为了对比传统清洗系统与分布式清洗系统的清洗效率,本实验进行Hadoop 进群搭建,采取5 台服务器进行部署,分别命名为Hadoop1至Hadoop5 其中Hadoop1为主节点,Hadoop2 至Hadoop5为从节点,每台服务器均安装部署Centos-7,Hadoop-2.6.5,Jdk-8u191-linux-x64,Zookeeper-3.4.5,内存配置为8G、处理器内核总数为4,每个处理器的内核数量为2,磁盘大小为100G,集群开发工具使用IDEA。
4.2 实验数据
本文实验数据来自智慧咸阳大数据分析平台中的一个旅游子系统产生的日志数据,现采用200万、400万、600万与800万条日志数据进行实验测试。
4.3 实验结果
本实验将从两个方面进行大数据清洗效率对比。
(1)传统清洗系统和分布式清洗系统在不同数据样例下的运行速率,实验结果如图5所示:
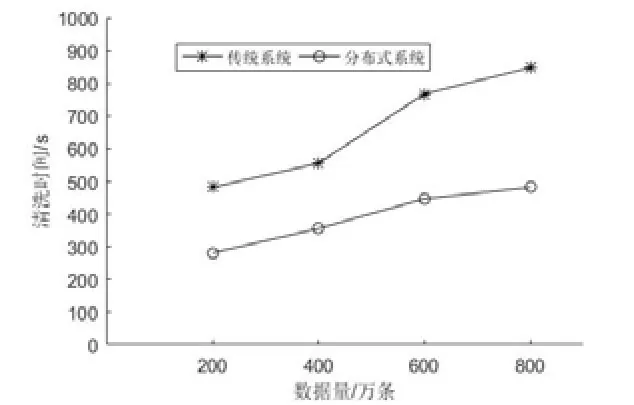
图6 传统系统与分布式系统清洗时间对比
如图6所示,随着数据的增长,两种清洗方式所用的时间折线图斜率逐渐变缓,但分布式清洗数据所用时间明显少于普通系统所用时间。
(2)在分布式数据清洗系统中,使用改进的分区聚合算法和未使用改进的分区聚合算法进行实验对比,实验如图7所示。实验结果如图7所示,在数据量相同时,改进的分区聚合算法清洗时间更短,效率更高。
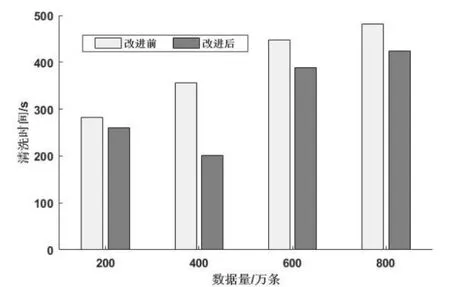
图7 算法改进前后数据清洗时间对比
5 结束语
本文实现了分布式日志清洗系统设计,实验结果表明相比于传统清洗系统来说,清洗效率大大提升,能够高效、快速地完成大数据的清洗任务。
(1)通过Hadoop,Flume,MapReduce 等大数据组件进行系统搭建。
(2)提出改进的分区聚合算法,对Reduce端进行优化,避免数据在清洗过程中造成数据积累,从而发生数据倾斜等问题。
