基于遗传编程的卫星降水量校准方法研究
2020-03-05李曼徐楠楠
李曼,徐楠楠
(南京邮电大学通信与信息工程学院,南京210000)
0 引言
准确地预知降水量的时空分布对农业、畜牧业、放牧、能源生产有着重要且直接的影响,与台风、洪水、干旱和泥石流等灾害也存在密切联系。受地形、水汽来源等多因素影响,降水的时空差异性较大[1],因此,如何精确估计降水的时空特征仍然面临着巨大的挑战。降水的测量包括传统的地面气象站的测量,以及卫星遥感监测[2]。在偏远山区,气象站的雨量计相对稀少且分布不佳导致降雨量的测量困难。近几十年来,卫星遥感监测在不断地发展与进步,新一代的全球卫星降水(Global Precipitation Measurement,GPM)计划[3],与以往的降水产品相比具有更高的精度,更大的覆盖范围,更高的时空分辨率[4]。但是卫星降水产品使用的是可见光/红外传感器、微波估计降雨量,其间接估计的性质,不可避免存在区域和季节性系统偏差和随机误差[5-6]。气象测量站空间分布的局限性以及卫星遥感数据较低的准确性使极端天气事件的预报、气候预报、洪水、干旱和泥石流等灾害的预报有很大的困难[7]。
关于卫星降水校准方法的研究已有许多,并取得了一些成果且发现地理位置、高层、季节、温度均有助于卫星降雨量的校准[8-9]。如:Yang 等人从数字高程模型中提取地形变量,确定其旋转主分量,建立调整TMPA 降水量的逐步回归模型,还建立了反传播(BP)神经网络来校正TMPA 降水量[8]。Shi 等基于EVI 和TRMM月降水数据研究了一种统计降尺度校准程序,利用EVI(Enhanced Vegetation Index)、海拔、坡度、坡向、纬度、经度与降水相关的非参数统计关系,实现了从0.25°到1km 的空间降尺度并且采用加法(additive method)对降尺度降水资料进行了校正[9]。
近年来,许多研究表明降水与植被覆盖[10]关系密切。植被是连结土壤、大气和水分的自然“纽带”,在全球变化研究中起到“指示器”作用[11]。Chen 等人提出了一种新的降尺度方法——地理加权回归(GWR),通过对TRMM、归一化植被指数(NDVI)、数字高程模型(DEM)数据集进行分析和探索,能更准确地生成降尺度的降雨数据[12]。因此在进行卫星降水校准方面的研究时,应将植被作为一个重要的考虑因素。此外,卫星降水数据的偏差和误差与季节季风有很大的相关性[13-14]。Prakash 等人广泛评估印度地区的TMPA 产品,通过分析季风前、季风中和季风后的降雨量,表明将TMPA 数据集应用到水文领域之前,需要对TMPA 数据集进行适当的区域和季节相关偏差校正[14]。
近年来,遗传编程技术作为遗传算法的分支,被广泛的应用于数据分析、数据挖掘方面。Rampone 等人利用人工神经网络和遗传编程预测未来季节平均气温[15]。Kisi 等人利用小波-遗传编程(Wavelet-Genetic Programming)和小波-神经模糊(Wavelet-Neuro-Fuzzy)结合模型进行日降水预报[16]。从这些研究可得,遗传编程技术能够进一步发现影响卫星降水产品测量的相关变量之间可能存在的关系。然而,目前从遗传编程角度分析降雨量的研究很少。
大多数卫星降水产品的校准和评估都是基于月尺度和年尺度,很少对日降水尺度的数据进行分析。因此,考虑植被对降水的影响,在本研究中,我们利用遗传编程挖掘卫星降水数据、全国气象站降水数据与相关因素(经纬度、高程、温度、时间、植被类型)之间的关系,构建了一种校正方法,以提高我国卫星日尺度降水数据的精度。
1 数据的来源与介绍
在本研究中,主要用到数据包括:全国气象站点数据,GPM 降水数据集和全国植被区划数据集。
(1)气象站点数据选取来源于中国气象数据网(http://data.cma.cn/)的日尺度数据集,选取全国地区气象站点2016 年1 月至2016 年12 月的日降水序列,其中研究区内气象站点660 个(见图1 全国站点分布)。
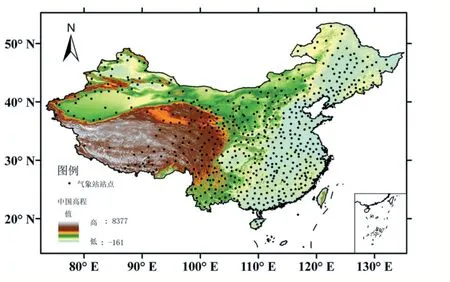
图1全国站点分布
(2)GPM 数据集通过美国国家航空航天局戈达德航天飞行中心(NASA-GSFC)获取(https://pmm.nasa.gov/precipitation-measurement-missions),收集2016 年1 月至2016 年12 月的日尺度降水序列,覆盖范围为17.95N~54.95N,72.05E~133.95E,空 间 分 辨 率 为0.1°×0.1°。
(3)全国植被区划数据来源于中国科学院资源环境科学数据中心(http://www.resdc.cn),该数据根据植被和气候类型,将全国划分为八个区域。为了方便统计,本研究将八个植被区域用数值1-8 代替,替换结果如表1 所示。
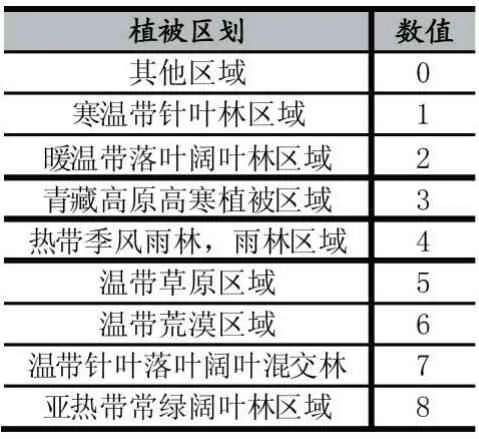
表1 植被区划数值表
根据全国气象站2016 年的可用数据以及对卫星校准方面的研究分析,我们考虑8 个评价降水条件的参数(表2)。所有的特性都表示为数值变量。
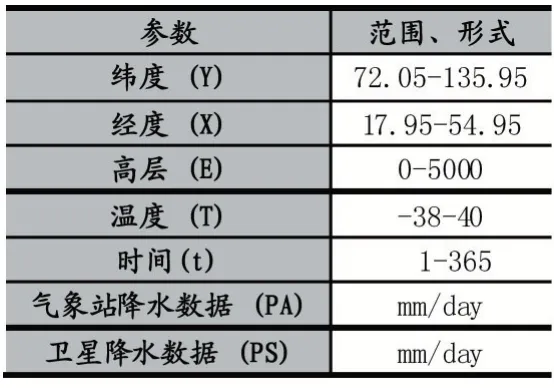
表2 参数列表
2 实验方法与过程
2.1 遗传编程的基本思想
遗传编程是在遗传算法的基础上引入自动程序设计的一种算法,它可以通过自身的学习快速发现数据与数学表达式之间的关系,通常由树形结构表示[7]。遗传编程开始于一群由随机生成的千百万个计算机程序组成的“人群”,然后根据一个程序完成给定的任务的能力来确定某个程序的适合度,应用达尔文的自然选择(适者生存)确定胜出的程序。计算机程序间也模拟两性组合、变异、基因复制,基因删除等代代进化,直到达到预先确定的某个中止条件为止[17]。遗传编程流程图如图2 所示。
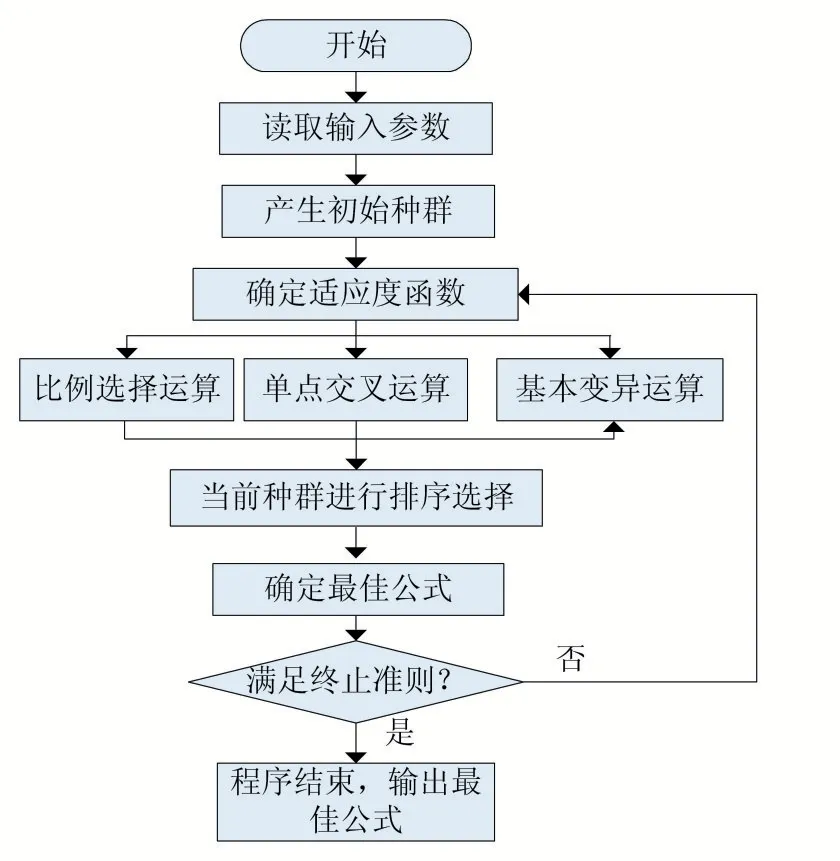
图2 遗传编程流程图
2.2 基于遗传编程的实验过程
本研究中由于地形、高程、温度、气候类型,植被覆盖等因素对卫星降雨测量产品的影响不明确,将遗传编程用作挖掘降水与相关因素之间关系的工具。在运用遗传编程前,需要确定所需的数据集和函数集。PA(气象站降水)为遗传编程的目标,输入数据集包括X(纬度)、Y(经度)、E(高程)、t(时间)、T(温度)和PS(卫星降水)。函数集如下:

利用遗传编程生成校准公式的步骤为:
(1)将数据集随机分为两个独立的集合:训练集和验证集。设置函数集PA= f(PS,X,Y,E,T,t),产生初始的校准群体。初始种群由数据集和函数集随机生成。
(2)数据集随机分为两个独立的集合:训练集和验证集,训练集经过遗传操作(选择、交叉、变异)得到初步的校准公式。
(3)定义种群的适应度函数,用于评估种群中的每个公式的适应度。在本研究中,我们使用均方根误差(RMSE)作为适应度函数。验证集用于评估步骤(2)中公式的适应度。
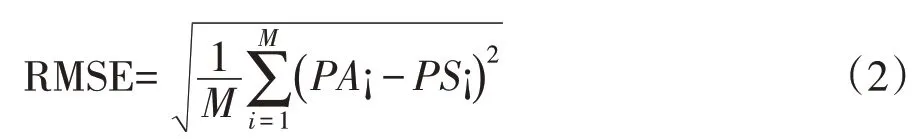
其中i 为气象站点秩数,M 为气象站总数,PS 为卫星降水数据,PA 为气象站降水数据。
(4)重复步骤(2-3),直到训练时间达到停止准则(本研究中为500 小时)。
(5)程序结束,由公式得到的校准后的降水量与实际卫星降水量的拟合优度判定系数R2选出最终最优公式。
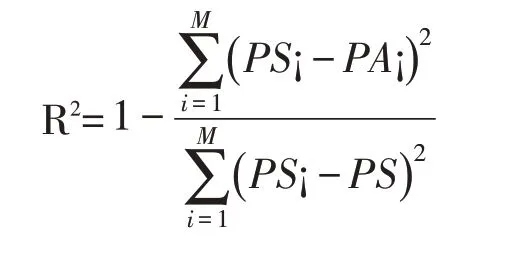
3 结果分析
3.1 全国卫星降水量数据集分析
受季风影响,我国降水季节特征显著。基于此,本研究按照季节尺度(春、夏、秋、冬)对2016 年GPM 日降水量进行校准。各季节的最终最优校准公式如表3所示。
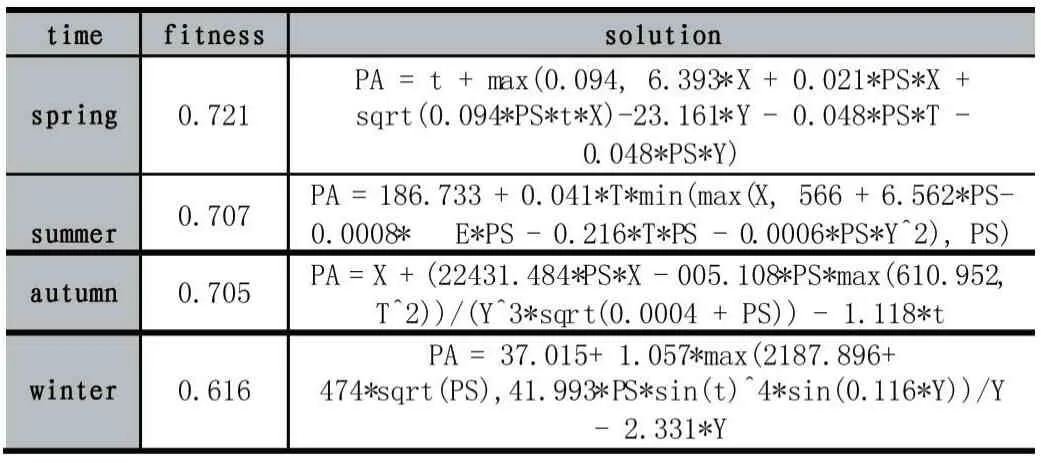
表3 2016 年全国区域最终校准公式
我们使用泰勒图来表示春夏秋冬四个季节的卫星降雨量原始数据和校准值与气象站实测日降水数据之间的对应程度(图3)。它利用了相关系数(CC)和标准差(SD)之间的三角转换关系。可以看出,春夏秋冬卫星日降水量原始数据与气象站实测日降水量的相关系数均在0.4-0.5 之间,经过遗传编程校准后校准值和实测值的相关系数在0.5-0.7 之间,CC 提高了10%左右,且标准差和均方根误差均明显降低。总的来说,对于日降水量的校准,夏季校准效果较好一些,冬季校准虽然CC 较大,SD 较小,但由于部分校准值出现了负值,总体校准效果较差。主要是因为冬季温度较低,冰雹、雪固体降雨量难测量,气象站的实际测量与卫星遥感数据偏差较大,导致校准精度不高。而夏季降雨量充沛,校准精度相对较高。
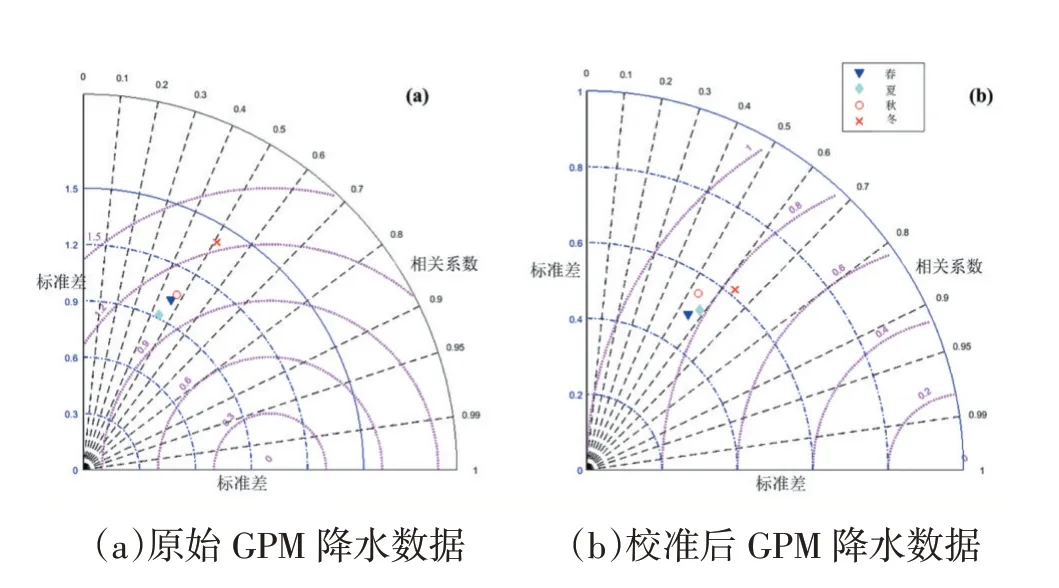
图3 春夏秋冬的GPM日降水量与气象站实测日降水量的泰勒分布图
上面的结论充分利用了卫星降水数据空间分辨率高,探测范围广的特点,但仍存在部分地区校准效果不佳。造成这种校准效果不佳的原因较多,主要是因为地理位置、温度、植被覆盖、气候类型存在较大的不同。故本研究根据植被和气候类型,将全国划分为八种区域,分别进行卫星日降水量的校准,进而提升卫星降水产品的可靠性。
3.2 植被区划降水量数据集分析
将2016 年的数据集按照植被区划分为八个独立的数据集分别进行校准。不同的植被区域校准的效果不同,其中热带季风雨林区域(区域4)和亚热带常绿阔叶林区域(区域8)校准效果较好,温带草原(区域5)、温带荒漠(区域6)效果较差。

表4 2016 年植被区划最终校准公式
图4 分别给出了八个植被区域的卫星降水量原始数据和校准值与站点实测日降水数据的泰勒分布。可以看出,八个植被区域卫星日降水量的原始数据与站点实测日降水量的相关系数相差较大,分布在0.3-0.6之间,校准值和实测值的相关系数主要分布在0.4-0.8之间。八个植被区域校准值的均方根误差和标准差均比原始数据减少了50%左右,相关系数提高15%左右。其中,热带季风林和亚热带常绿阔叶林的校准后的相关系数均大于其他地区,而温带荒漠与温带草原植被区校准后的相关系数相对较小。暖温带落叶阔叶林、温带针叶落叶阔叶混交林、青藏高原高寒植被区域校准效果一般。
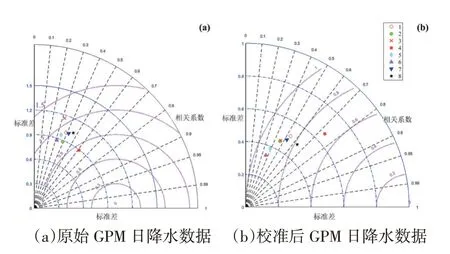
图4 全国植被区域的GPM日降水量与站点实测日降水量的泰勒分布图
综上分析,基于遗传编程的卫星降水量的校准适合降水量充沛的中国东南部地区的校准,降水量越大,相关性越大,校准效果越好。即在考虑植被对GPM 降水产品影响的基础上,遗传编程对GPM 卫星降水量的校准有了进一步的改进。
4 结语
本研究从日降水尺度的数据出发,利用遗传编程挖掘数据,得出卫星降水量与影响因素中的潜在关系,生成直观的公式,实现了卫星降水量的校准。研究表明,空间分布、季节和温度对卫星降水量的校正具有重要价值。夏季温度高且降水量较多,校准后CC 提高了15%左右,校准效果最好;中国东部和南部,温度偏高,降水量充沛,卫星降水容易高估数据,CC 相比其他地区提高10%-20%;中国西部和北部地区降水量相对少,温度普遍较低,冰雹、雪固体降水量难测量,且土壤湿度低,降水量蒸发较快,卫星降水容易低估数据,导致校准效果较差。基于遗传规划的卫星降水量的校准适合降水充沛季节和地区的校准,降水量越大,相关性越大,校准效果越好。
