融合表情符号与短文本的微博多维情感分类
2020-02-24赵晓芳金志刚
赵晓芳,金志刚
(天津大学 电气自动化与信息工程学院,天津 300072)

表情符号的使用可以揭示隐藏在文本之下的情感,例如,“体测一千米,都没有喘不过气来ヾ(≧≦*)ヾ”表示快乐和兴奋;“我不知道把钢笔放在了哪里QAQ”为不安的情绪;“连续42小时的工作,已经忘记了时间的存在”表示兴奋和收获的满足.在这些句子中,虽然文字并没有明确地传达出情绪,但结尾处的表情符号可以有效识别个体的情感状态.
2019年3月,新浪微博数据中心发布最新《2018微博用户发展报告》[2],报告显示2018年第4季度微博月活跃用户4.62亿,其中95后用户高达41%.由于微博有着迅捷性、蔓延性、平等性与自组织性等4大特点,其热点话题随时都会引发万级的转发和评论,例如从“长生生物等疫苗造假事件”到“翟天临被指论文抄袭事件”再到最近的“996工作制”事件,无一不是在微博上迅速发酵,并最终对现实社会产生影响,而且这种线上影响线下的趋势越来越明显.为了更好地利用微博,产生有益社会价值,消除潜在危害,本文提出微博多维度情感分析,这有利于分析群体情感倾向,提高舆情分析、引导的准确率,在网络言论尚未形成舆论前,及早预测可能导致用户负面情绪的舆论或报道,实现对舆情的早期介入和有效引导.
目前,针对中文媒体中情感符号进行分析的方法多针对Emoji,对于颜文字情感倾向并没有相关分析.本文在文本基础上,结合了Emoji、颜文字情感特征,提出了一种融合表情符号与短文本的多维情感分类方法(EmotT):收集95后在微博发表的评论,通过现有的日式颜文字资源,构建中文颜文字词典,提取颜文字中的结构特征、类别特征以及运动学特征,并利用多层感知机(Multi-Layer Perception,MLP)对颜文字进行情感检测,得到颜文字的7种情感强度值;采用基于注意力机制的CNN和LSTM对文本和Emoji进行编码,将得到的融合特征作为MLP的输入,进一步挖掘文本和Emoji组合部分与情感标签的深层次关联,计算文本和Emoji组合部分的7种情感强度值;结合以上两种情感倾向设计计算模型,通过相关实验,验证了构建的融合表情符号与短文本的多维情感分类方法可以进一步提高情感分析性能,补充了中文媒体评论中颜文字情感研究的空白,且该方法获取的语句7种情感强度,为群体情感走向提供了更细粒度分析.
1 相关工作
微博语句的情感分析,不仅需要对微博文本进行分析,还需要考虑用户使用的表情符号,有相关研究将表情符号作为特征进行情感分析,这些方法改善了社交媒体的情感分析结果,例如Jonathon[3]提出使用朴素贝叶斯和支持向量机分类器代替话题敏感词进行情感分析时,可以使用表情符号来减少话题依赖性.Yang[4]等提出将Emoji这种表情符号作为自动注释工具,使用支持向量机和条件随机场等算法将句子标记为4种情感类别,可以减少手动注释节省时间和人力.
以上研究证实了表情符号对情感分析的积极影响.然而,对中文社交媒体的分析仅仅局限于Emoji,并没有分析Emoji和颜文字两种表情符号对情感表达的影响.例如Song等[5]提出利用情感种子词和情感符号来构建情感词典,以便更准确地捕捉候选情感词的细粒度情感倾向;Jiang等[6]利用表情符号的词向量构建表情符号向量空间模型,并将文本中所有的词映射到向量空间中,采用支持向量模型实现对文本的情感分类;何等[7]为常见的表情符号构建情感空间的特征表示矩阵,通过将文本词向量矩阵与表情符号的特征表示矩阵进行乘积运算,实现词义到情感空间的映射,从而构建文本的情感表示矩阵;张等[8]提出基于双重注意力模型的情感分析方法,分别对文本和情感符号进行编码.此外,相关学者对日式颜文字进行了情感分类,如Utsu等[9]通过对日式颜文字中包含的眼睛、嘴巴等符号的出现概率进而对颜文字进行情感极性判别;Yu等[10]通过构建颜文字词典对日语旅游网站评论进行情感分类;Yu等[11]提出了AZEmo系统,实现了对社交媒体和电子商务网站中颜文字的提取和分类.
本文针对包含Emoji和颜文字的语句,将其分为两部分进行多维情感分类.第一部分是对文本和Emoji组合部分进行情感倾向分析,为了提高特征表达能力,进一步挖掘文本和Emoji组合部分与情感的深层次关联,采用基于注意力结构的CNN、LSTM分别提取组合部分的语义特征,将得到的两种语义特征进行融合后,通过MLP进一步提取高级语义表示,最后使用softmax分类层得到文本与Emoji组合部分的多维情感强度值;第二部分通过构建的中文颜文字词典,提取颜文字结构、情感类别、运动学特征,采用MLP对颜文字的情感倾向进行分析,得到颜文字的7种情感强度值.最后基于上述两部分的情感倾向分析,设计情感计算模型得到语句的多维情感强度值.
2 融合表情符号与短文本的微博多维情感分类
新浪微博等社交媒体中的Emoji和颜文字是目前常用的两种表情符号,人们借助情感符号表达更加微妙的情感变化,如加强、澄清或强调、幽默等.Emoji、颜文字是微博文本情感倾向的重要特征,相比于文字,表情符号对情感的语义区分能力更高.本文在对文本、Emoji组合部分情感分析的基础上,结合了颜文字的情感倾向,为包含颜文字、Emoji的社交媒体评论的情感分析提供了模型基础,如图1所示为情感分类模型框架.

图1 情感分类模型(EmotT)
2.1 颜文字情感计算
颜文字的情感计算主要包括3部分:中文颜文字词典构建、颜文字提取以及颜文字情感倾向值计算.
2.1.1 颜文字词典构建
目前,并没有大规模的中文颜文字词典,因此本文在Ptaszynski等[12]构建日语颜文字词典基础上构建中文颜文字词典.在词典中,每种情感标签均包含一系列颜文字,且每个颜文字只属于一种情感标签.中文颜文字词典构建规则分以下两步:
明确颜文字情感标签:在构建中文颜文字词典时忽略无法推断出是否具有明显情感倾向的颜文字,只收集带有明确情感含义标签的颜文字.
截断处理:由于日式颜文字包含的不仅有眼睛、嘴巴等符号,还有一些日语来帮助解释颜文字的含义,如颜文字“ヾ(@⌒ー⌒@)ノおはよう”中“おはよう”是早上好的意思,用来帮助解释颜文字的含义,在构建中文颜文字词典时,对其中的日语进行了截断处理,例如:日式颜文字“ヾ(@⌒ー⌒@)ノおはよう”在构建的中文颜文字词典时最终变为“ヾ(@⌒ー⌒@)ノ”.
2.1.2 颜文字提取
Birdwhistell[13]最先提出了人体运动学理论,该理论确定了颜文字中的字符所对应的身体或面部表情.本文采用Michal等[10]构建的人体运动学模型,将每个颜文字表示为9个部分:{S1}{B1}{S2}{EL}{M}{ER}{S3}{B2}{S4},各个部分与颜文字的对应关系如表1.

表1 颜文字组成
{B1}{B2}分别为颜文字的左右边界;{EL}{M}{ER}与人体运动学中的左眼睛、嘴巴、右眼睛对应,是颜文字的核心部分并记为{S5};{S1}{S2}{S3}{S4}为颜文字中与人体运动学理论对应的其他部分,如胳膊、汗水等,称为补充分量.并不是每个颜文字都严格地遵循这9个部分,没有的部分用“空”表示.中文文本中提取颜文字步骤如图2.
2.1.3 颜文字情感倾向值计算
本文采用Xu等[14]提出的7大情感类别,将颜文字的情感分为乐、好、哀、恶、怒、惧和惊.此外,分别将颜文字的核心部分{S5}和4个补充分量{S1}{S2}{S3}{S4}映射到7种情感类别中,每个分量出现在7种情感类别中概率计算为
(1)
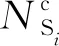
在文本挖掘和情感分析研究中,提取结构、句法和语义特征被广泛采用.然而,由于颜文字的性质不同于语言句子,一些特征(如句法特征)不适用于颜文字.因此,采用Yu等[11]提出的颜文字特征表示方法,从颜文字中提取4种结构特征、7种分类特征和35种人体动力学特征.提取的特征以及解释如表2.

图2 中文文本中提取颜文字框架

表2 颜文字特征
结构特征考虑了颜文字的结构信息.该类型包括颜文字的总长度、ASCII字符的比例、不同类型字符的数量以及颜文字中出现频率最高的字符的数量.
情感特征借助Yamada等[15]提出的方法,通过提取颜文字中每个字符在特定情感类别中的出现次数除以该字符在所有颜文字中的出现总次数,得出该字符表达特定情感的概率.
通过从表情中提取人体运动学特征,计算核心和其他成分的情感类别概率.颜文字的情感是由人体运动学成分构成的,这意味着运动学成分的情感概率在颜文字的情感类别中占很大比例.如果两个人体运动学成分在两个情感类别中具有相似的类别频率,则认为它们在构建表情符号方面具有相似的功能.若颜文字中不包含某些人体运动学成分时,其对应的情感概率为0.通过上述分析,特征向量中共有35个人体运动学特征值(有些为空).
情感预测质量的评价与具体的预测模型有关,本文采用不含隐藏层的MLP分析颜文字的情感倾向.对MLP的输出向量采用Rectifier函数进行非线性变换后,得到情感标签的得分向量为
Sscore(K)=g(WKx+bK).
(2)
式中:Sscore(K)∈R|C|为颜文字K的情感得分向量,C为7种情感标签集合,g取RELU函数,WK、bK分别为MLP的参数矩阵和偏置,情感得分向量作为softmax的输入,得出颜文字的多情感分类概率为
(3)
得到多维情感强度为:QK=PK(c/K).
2.2 基于注意力的文本和Emoji情感计算
本文采用Jiang[6]提出的利用表情符号构建表情符号向量空间模型,并将文本中的所有词映射到向量空间中.文本词语及Emoji词向量的获取可以看作是一个查词典的过程.词典Rd×N通过大规模语料采用词向量训练模型学习得到.对于一个文本序列T={t1,t2…tn},将词语的词向量拼接起来,就得到整个文本序列的词向量表示,拼接方式如式(4)所示:
RT=r1⊕r2⊕…r|N|.
(4)
式中:ri∈Rd×N为ti对应于词典中的元素,⊕为行向量拼接操作,d为词向量的维数,|N|为词典中词语的个数.对Emoji集合中的词向量同样采用上式的方式进行拼接,RT和RE的维数分别为词语的数目和Emoji的数目.
文本的词向量矩阵RT以及Emoji的词向量矩阵RE作为深度学习模型的输入.为了进一步提高对文本和Emoji建模能力,首先采用基于注意力机制的CNN和RNN分别提取局部以及上下文相关特征,然后对提取的特征进行融合,增强模型表达能力的同时获得更多相关的语义特征.如图3为基于注意力的文本和Emoji建模框架.
基于CNN与RNN模型的语义获取与融合
RT和RE作为CNN模型的输入,卷积层用大小为h×d的滤波器对文本矩阵执行卷积操作,提取局部特征:
ct=f(F·R+b).
(5)
式中:F代表宽度为h的滤波器,b为偏置量;f为通过RELU进行非线性操作的函数;ct为通过卷积操作得到的局部特征.随着滤波器依靠为1的步长从上往下进行滑动,采用VALID方式进行padding操作,获得与原输入相同长度的特征向量Ct.

图3 基于注意力的文本和Emoji建模框架
对于输入序列x=(x1,x2,…xt),一个标准的RNN模型计算隐藏和输出序列分别为
ht=σ(Wxhxt+Whhht-1+bh),
(6)
yt=Whyht+by.
(7)
式中:W项为权重,b为偏置,σ取sigmoid函数.然而,由于RNN梯度容易消失、爆炸等缺点,RNN的变体长短时记忆(LSTM)被越来越广泛的应用.LSTM模型可看作一种权值共享的深度神经网络,利用门信号的线性循环连接来解决时间层面的梯度弥散问题,进而学习长期的依赖关系.本文使用LSTM模型提取语句的语义信息表示为Ht.为捕获更直接的语义依赖关系,采用Bahdanau[16]提出的注意力模型,将两种模型的输出分别作为注意力模型的输入,得到的文本表示向量为
(8)
式中ft为Ct或Ht;输入状态的权重为
(9)
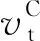
为了得出文本与Emoji融合特征的多分类情感概率,与处理颜文字的过程类似,将融合特征作为MLP的输入,并对MLP的输出向量采用Rectifier函数进行非线性变换,得到情感标签的得分向量:
Sscore(S)=g(WTEv+bTE).
(10)
式中:Sscore(S)∈R|C|为文本与Emoji融合部分的情感分类向量,C为7种情感标签集合,g取RELU函数,WTE、bTE分别为MLP的参数矩阵和偏置,情感得分向量作为softmax的输入,得出文本与Emoji的多情感分类概率为
(11)
选择softmax层输出的概率作为多维情感强度值QTE=PTE(c/S).
2.3 微博语句情感计算
对于情感倾向要综合考虑表情符号和文本两部分,通过对上述两部分的情感倾向值加权处理后即可得到微博的多维情感概率:Q=(1-λ)QTE+λQK.QTE为微博文本与Emoji的多维情感概率,QK为颜文字的多维情感概率,λ为正的可变参数,表示情感倾向所占的比重,且λ∈(0,1).
3 实验与分析
本文针对95后在社交网络中发表的评论进行情感倾向性分析,考虑到95后在社交媒体的评论中喜欢使用颜文字的特点,提出的情感分类模型考虑了文本中包含的Emoji及颜文字,由于目前并未发现合适的公开数据集,因此自行爬取2017年—2018年约40 000 000条微博评论构建实验数据集,并将其分为带有颜文字的与不带有颜文字的两类.由于Emoji和颜文字数量较多,通过对表情符号进行情感标注和降序排列,最终各选择前100的表情符号进行实验.实验进行了两部分的对比,第一组是滤除颜文字,采用提出的基于注意力机制的方法与选取的模型进行对比,验证提出模型对文本和Emoji组合部分建模的有效性;第二组是对含有Emoji、颜文字的语句进行多情感分类,验证颜文字对情感分类性能的影响.
3.1 第一组实验:无颜文字
实验数据采用NLPCC的2014年中文微博评测任务的公共数据集NLPCC2014.数据集分为测试集和训练集两部分,标注的情感标签主要分为7类,如表3所示:
为了学习文本词语和Emoji的词向量,本文将爬取的不含有颜文字的语句经过NLPIR分词、去噪、繁简转换、url替换以及删除长度较短的无意义的微博之后,构建了Word2Vec词向量训练语料库,包含微博31 394 583条,词语数1 034 869 204个,选择skip-gram模型进行训练,得到词向量空间包含649 302个词,词向量维数为200维.实验中CNN、LSTM的参数如表4所示.
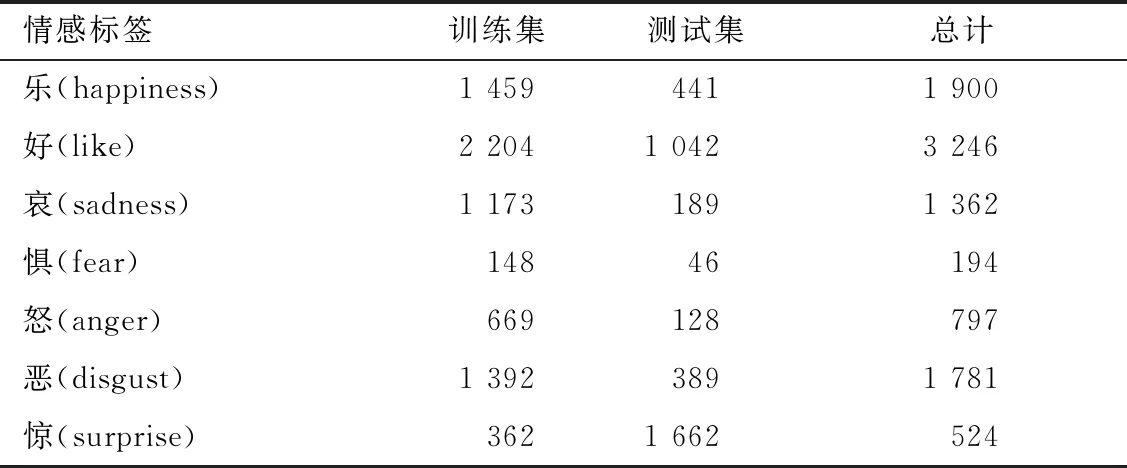
表3 NLPCC2014标注数据集

表4 模型参数
实验选取的对比模型如下:
MNB模型(multinomial naive bayes, MNB):作为机器学习的代表,在很多情感分类任务中都取得了优秀的效果.
ESM模型:Jiang等[6]针对Emoji提出的表情符号空间模型,完成了词语到情感空间的映射,本文选择对映射后的词语求最大、最小和求和的方法作为对比模型.
EMCNN模型:何等[7]提出的为Emoji构建语义特征表示矩阵,通过矩阵乘积运算增强微博文本语义,采用多通道卷积神经网络对特征学习实现情感分类.
DAM模型:张等[8]提出的基于双重注意力机制,分别对文本和情感符号进行编码,在构建语义表示后进行情感分类.
通过实验,对NLPCC2014评测结果如表5所示:
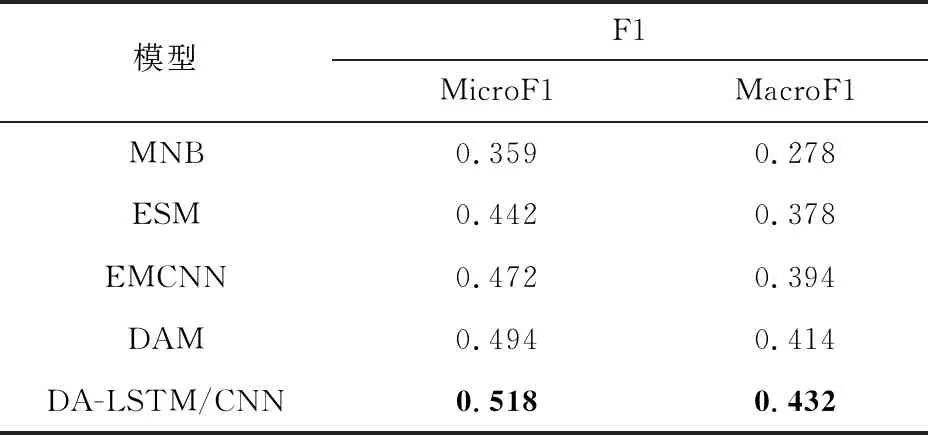
表5 NLPCC2014评测结果
从上表看出,本文方法得到的MicroF1和MacroF1两个评价指标较其他模型分别平均提高7.6%和6.6%,明显优于其他模型,这主要是因为采用基于注意力机制的CNN和RNN分别提取局部以及上下文相关特征,并对提取的特征进行融合,进一步提高了对文本和Emoji建模能力.其次,为了进一步验证该模型可以在增强模型表达能力的同时获得更多相关的语义特征,选择了两个实例来可视化注意力结果.可视化结果如图4和图5所示.其中颜色由浅到深意味着注意力权重由高到低.
如图4所示,“这是一部令人兴奋的关于运动的动作电影,还有一个我喜欢的故事”,看出本文提出的模型为每个特征提取层分配了不同的注意力权重.在基于LSTM的特征提取层中,兴奋、[乐]和喜欢的权重更高,在基于CNN的特征提取层中,故事、兴奋和[乐]的权重更高,而且在两种特征提取中,Emoji都具有较高的注意力权重,CNN和LSTM模型都可以很好地捕捉语句中的表情符号,最后该模型将它们结合起来确定情感极性.此外,句子中的一些噪音如“的”、“令人”等对语句情感极性判断没有贡献,因此其注意力值很小.

图4 注意力可视化结果(“这是一部令人兴奋的关于运动的动作电影,还有一个我喜欢的故事[乐]”.)
Fig.4 Visualization of attention (“This is an exciting action movie about sports, and there is a story I like[laugh].”)

图5 注意力可视化结果(“几乎在每个关键时刻影片都破坏了剧本的亮点[怒]”)
Fig.5 Visualization of attention (“The highlights of the script are destroyed by the movie at almost every important moment[anger].”)
上述两个可视化结果都反映了提出模型对语义表达能力的增强,即本文提出的基于注意力机制的深度学习模型,通过特征提取和特征组合两步将局部信息和上下文信息组合在一起,很好地捕捉文本词语、Emoji和句子结构的搭配,以识别情感倾向.
3.2 第二组实验:包含颜文字
为验证提出的融合表情符号和短文本的多维情感分类效果,选取爬取的带有颜文字的微博语句8 000条和不带有颜文字的微博语句2 000条,分别验证不同的λ取值对情感分类准确率的影响,以及加入颜文字对最终情感分类准确率的影响.
3.2.1λ取值
对于微博的情感倾向,要综合考虑文本、Emoji组合部分以及颜文字的情感,通过对这两部分的情感倾向值加权处理后即得到微博情感倾向值.为了判断λ的取值,设计了正负情感二分类实验,将选择的8 000条微博所标注的7种标签中的乐、好作为正向标签,哀、惧、怒、恶和惊作为负向标签,其中正、负向微博各4 000条.综合正负情感倾向值,得到的准确率见图6.
通过图6得出,随着λ的增大,正负情感分类准确率提高,当λ=0.4时准确率达到最高,当λ>0.4时,正负情感分类准确率有下降的趋势,因此为了使颜文字在情感分类中更好地发挥作用,最终确定文本和Emoji组合、颜文字占比分别为0.6和0.4.
3.2.2 颜文字对最终情感分类准确率的影响
为了验证加入颜文字对情感分类准确度的影响,实验选取微博数据集10 000条,其中包含颜文字的微博8 000条,不包含颜文字的微博2 000条,为了验证颜文字对微博情感分类准确率的影响,实验对比了MNB模型、ESM模型、EMCNN模型、DAM模型以及本文提出的EmotT模型在3组数据集设置下的分类准确率:第1组全部微博共10 000条;第2组包含颜文字微博共8 000条;第3组在第2组数据集基础上去掉所有颜文字的微博8 000条.
从图7、8得出,含颜文字的情感分类性能指标始终高于不含颜文字的分类性能,表明分析颜文字的情感表达能力有助于提高情感分类准确率.此外,提出模型在3种数据集上的表现均优于其他模型,表明提出的针对短文本和Emoji组合部分情感分类模型可以更好地挖掘语句与情感标签之间的关联,加入的颜文字也进一步提高了情感分类性能.
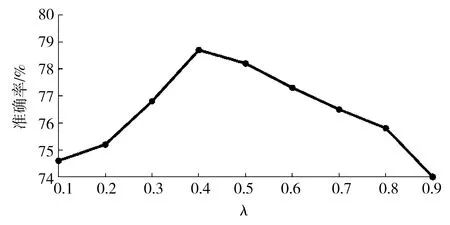
图6 λ对情感判断准确率影响

图7 情感分类结果MacroF1

图8 情感分类结果MicroF1
4 结 论
本文提出了一种融合表情符号与短文本的多维情感分类方法,实现了对含有Emoji和颜文字的微博的情感分类,为群体情感细粒度分析提供了模型基础.主要贡献有:通过对日语颜文字的处理,构建中文颜文字词典;通过对NLPCC2014标准数据集的分析,本文模型得出的MicroF1和MacroF1值较其他模型分别平均提高7.6%和6.6%,即该方法可以有效提高对文本和Emoji的多情感分类性能,验证了所提出的基于注意力机制的CNN和LSTM组合模型对微博文本和Emoji进行语义建模的有效性;对自行爬取的含有颜文字、Emoji的微博语句进行多维情感分类,通过实验分析当文本、Emoji组合部分与颜文字所占比例分别为0.6和0.4时所得到的多维情感分类准确率最高,且实验得出含颜文字的微博语句的MicroF1和MacroF1指标始终高于不含颜文字的微博语句,表明分析颜文字的情感表达能力有助于提高微博的情感分类准确率.通过以上结论,进一步说明本文提出的加入颜文字特征进行多维情感分类,提升了微博情感分类的性能,为中文社交媒体情感分析提供了新方法.
