基于线性回归新模型的插补方法实证研究
2020-02-22曾梅
曾梅


摘 要:在实际生活中搜集数据时,数据缺失的情况是很常见的。在通常的情况下,当辅助变量和缺失变量之间有着较强的线性关系时,如果我们利用回归插补方法对缺失数据进行插补是合理的。在很多研究中,对于回归插补法一般是使用最小二乘法,在本文中将根据研究者提出来的一种新线性回归估计方法,运用到回归插补中,并和普通最小二乘回归插补及均值插补进行比较,运用R语言进行数据缺失的模拟分析,最后得出前者所得效果更好,丰富了缺失数据插补方法,并且为实际运用中选取处理缺失数据的插补方法时,提供了较多的选择范围。
关键词:缺失数据 回归插补 均值插补 R语言
中图分类号:O212.1 文献标识码:A 文章编号:1674-098X(2020)10(c)-0094-07
Abstract: When collecting data in real life, there are often missing data. Under normal circumstances, when there is a strong linear relationship between the auxiliary variable and the missing variable, we use the regression imputation method to impute the missing data is very effective. In many studies, the least squares method is generally used for regression interpolation. This article will apply a new linear regression estimation method proposed by the researcher to the interpolation method of missing data, and use ordinary least squares regression Imputation and mean imputation are compared, and the R language is used to simulate and analyze the missing data. Finally, it is concluded that the former has better results, which provides more options for selecting missing data imputation methods in actual applications.
Key Words: Missing data; Regression imputation; Mean imputation; R language
在现在这个信息时代,对数据的处理变得越来越为重要。对于许多数据都会存在缺失的情况,例如在UCI数据集中,含有大量的缺失数据,缺失比例超过了40%;在我们运用统计年鉴上的数据时,也会发现对于一些指标的数据,在有些年份有,而有些年份却没有;在医疗数据的搜集中也会发现由于病人的离世或者提前放弃了治疗从而导致数据存在缺失的情况。直接删除法是处理缺失数据最简单的方法,但是采取这种方法会导致大量的信息丢失,造成分析结果的不准确,不能充分满足数据分析的要求,而统计学方法对数据的完整性具有很高的要求,因此对缺失数据的插补在数据的初步清洗中扮演着重要的角色。Little和Rubin从缺失机制将缺失数据划分为完全随机缺失(MCAR),随机缺失(MAR)和非随机缺失(MNAR)[12]。为了方便,本文选取完全随机缺失机制进行研究。
在实际生活中,我们会发现,有很多数据之间都具有一定的联系,但是经常會出现数据丢失的情况,因此回归插补法具有重大的研究意义。最小二乘回归是人们较为熟悉的方法,由于其简单方便,因此在使用回归插补时,常用最小二乘来进行估计。为了寻找其他有效的方法,本文将基于一种新的回归方法进行插补,并和最小二乘进行比较,期望得到更加有效的回归插补方法。
本文的基本脉络如下:第1部分介绍回归插补和均值插补的基本原理;第2部分介绍最小二乘回归法以及学者提出来的新的线性回归模型;第3部分运用实际数据进行实证研究,验证新方法的有效性;第4部分对文章进行总结分析。
1 回归插补和均值插补介绍
1.1 回归插补
对于实际中的很多数据,都存在一定的线性关系。顾名思义,回归插补的主要思想就是根据各变量之间的关系建立回归模型,然后把缺失变量看成因变量,运用建立的模型得到预测值,并把其作为缺失值的填补值。
回归插补的步骤如下:
第一步:对于给定数据集,检测出变量之间如果具有很强的相关性,则可以运用回归插补。
第二步:利用完整数据集建立回归模型,把缺失变量看成因变量,把与缺失变量对应的辅助变量代入得到的回归模型中,得到的值作为对应缺失值的代替值。
回归插补法是一种单一插补方法,主要针对数据集中存在一个变量缺失的情况,也即是单变量缺失的模式。利用回归插补法时,由于其操作简单,在建立回归模型时通常使用最小二乘。
1.2 均值插补
均值插补是运用现有数据的均值来代替缺失值的一种方法。均值插补主要包括单一均值插补和分层均值插补,均值插补已近常被广泛的使用。本文主要使用的是单一均值插补,因此仅简单介绍单一均值插补方法。
单一均值插补是利用已观测到的变量并计算其均值作为该缺失变量的填补值。其插补值可以表示为:
其中示性函数,为变量中已经观测到的个数。
因此,可以得到总体的均值估计为:
进一步计算插补后的样本方差,可以得到:
2 线性回归方法的介绍
2.1 最小二乘回归(OLS)
2.1.1 一元线性回归
最小二乘回归是非常有效的方法,由于它的简单性,在经济、医疗等领域都具有广泛的应用。最小二乘法的主要思想是使得预测值和实际值差的平方和最小,然后对相应的参数进行估计。一元线性回归的数学模型如下:
通过最小二乘可以得到和的参数估计如下:
在上式中,表示截距,表示斜率,表示自变量,表示因变量,和表示均值。
2.1.2 多元线性回归
在现实生活中,影响因变量的因素通常有很多,因此出现了多元线性回归,它也是对一元线性回归的推广。模型如下(3)式:
2.2 线性回归新模型
最小二乘法发展成熟,且计算简单被运用广泛运用在各个领域。但是其在预测方面并不是最准确的,而且对异常值也较为敏感,因此赵茂先和余阳提出了在某些情况下预测精度和绝对误差的效果比最小二乘好的估计方法[1]。
为了方便,把第一种方法作为记为ML1,其主要的思想是把已知数据的均值和所有数据的斜率求平均作为线性回归模型的斜率,同时再根据均值和斜率求出截距,公式如下:
同样的道理,把第二种方法作为记为ML2,由于自变量和因变量都满足方程
在上式中,和未知,和已知,因此和可以得到:
根据(6)式可以解得和的估计值
这是ML2方法的一元形式,推广到多元的形式可以得到多元线性函数的参数估计如下所示:
其中
3 模拟分析
我们将利用实际的数据,运用最小二乘回归的插补方法、均值插补法以及ML1插补、ML2插补对具有不同缺失率的数据进行填补,通过对不同评价指标比较,得出ML1插补和ML2插补的有效性。
3.1 评价指标
3.1.1 从插补值的角度
(1)平均绝对误差。
其中表示变量中缺失值的个数,表示缺失的插补值,表示实际值。
(2)均方误差。
从插补值的角度出发,本文用MAE、MSE来判定插补效果的好坏。平均绝对误差表示的是填补值和真实值之间差值的平均,MAE越小,说明填补值和真实值之间的误差越小,说明填补效果越好,反之,说明效果越差。对于均方误差MSE也是同样的道理。
3.1.2 从模型的角度
(1)调整后的决定系数。
其中SSE表示残差平方和,SST表示总的离差平方和。
(2)回归系数相对误差。
其中表示原始数据得到的回归系数,表示进行行插补之后再进行回归得到的与之对应系数,对应的回归系数相对误差越小越好。
3.2 数据说明
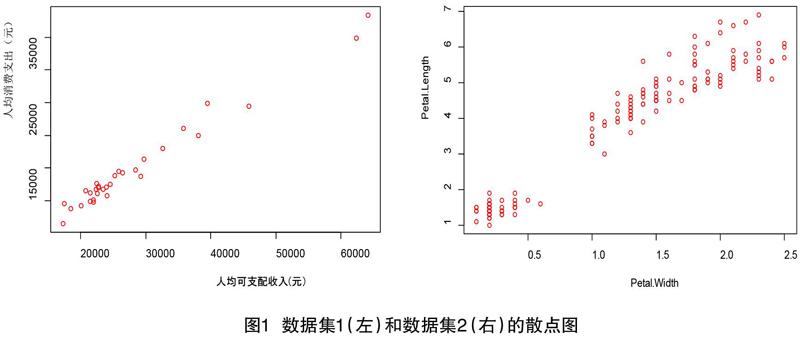
本文采用的数据集1是全国各地区2018年的人均消费支出和人均可支配收入的数据,把前者看成因变量,后者作为自变量。数据来源于中国统计年鉴。数据集2是R语言里自带的iris数据集,把Petal.Length看成因变量,Petal.Width作为自变量,对于这两个数据集采用一元线性回归的模型进行填补。对于多元线性回归的模型,使用的是影响我国财政收入的数据,均来源于《中国统计年鉴》。其中财政收入为因变量,税收,年末从业人员数为自变量。分别设置因变量的缺失情况为为完全随机缺失,且缺失率为5%、10%、20%、30%。
为了探究各地区人均消费支出和人均可支配收入的数据关系,做出散点图如图1所示。
从图中我们可以看到数据集1中的人均消费支出和人均可支配收入呈线性关系,同时计算两者的相关系数为0.9881。数据集二中两个变量之间也具有很强的线性关系,且通过计算得到相关系数为0.9639。因此对于两个数据集来说,如果数据有缺失的情况,运用回归插補处理是可行的。
3.3 结果分析
3.3.1 数据集一的结果分析
对于数据集1,采用完全随机缺失的模式进行模拟研究。设置因变量的缺失率依次为5%,10%,20%,30%,运用均值插补、最小二乘回归插补,ML1插补,ML2插补四种方法得到的MAE、MSE结果如表1。
从平均相对误差来看,比较四种方法可以发现,对于数据不同的缺失率情况下,ML1的MAE值最小,其次是最小二乘和ML2,最大的是均值插补的方法。从均方误差来看,不同的缺失率下,ML1的MSE值最小,其次是最小二乘和ML2,最大的是均值插补的方法。所以评价指标无论是MAE还是MSE,ML1的插补效果最好,其次是最小二乘和ML2,均值插补的效果最差。为了更加直观的看出各种方法的插补效果,做出不同方法的MAE和MSE的对比图,如图2所示。
从模型角度比较来看,分析不同方法不同缺失率下线性回归得到的调整。
原始数据的为0.9756,从调整的来看,在不同的缺失率之间,运用最小二乘、ML1、ML2所得到的相差不大,但是均值插补后进行回归得到的和原始数据的相差较大。运用各种插补方法之后得到完整的数据集,再对数据进行线性回归,得到回归系数和原始数据的回归系数的相对误差情况如表3。
从表3可知,当缺失率为5%时,和的MAE最小的是ML1方法,其次是最小二乘和ML2的方法,最大的是均值插补的方法。当缺失率为10%,20%,30%时,得到结果和缺失率为5%时一致。
从平均相对误差来看,比较四种方法可以发现,对于数据不同的缺失率情况下,ML2的MAE值最小,其次是最小二乘和ML1,最大的是均值插补的方法。从均方误差来看,不同的缺失率下,ML2的MSE值最小,其次是最小二乘和ML1,最大的是均值插补的方法。所以评价指标无论是MAE还是MSE,ML2的效果最好,其次是最小二乘和ML1,均值插补的效果最差。为了更加直观的看出各种方法的插补效果,做出不同方法的平均相对误差对比图和均方误差对比图,如图3所示。
如表4、表5,从模型角度比较来看,分析不同方法不同缺失率下线性回归得到的调整对于iris数据来说,原始数据的为0.9266,在缺失率不同时使用不同的方法ML2的结果和最小二乘的结果相差不大,均值插补得到的和原始数据相差较大。运用各种插补方法之后得到完整的数据集,再对数据进行线性回归,得到回归系数和原始数据的回归系数的相对误差情况如表6。
从表6可得,当缺失率为5%时,比较和的相对误差最小的是ML2方法,其次是最小二乘和ML1的方法,相对误差最大的是均值插补的方法。当缺失率为10%,20%,30%时,得到和缺失率为5%时同样的结果。
3.3.2 数据集3的结果分析
对于多元线性回归,使用的数据集是影响我国财政收入的数据,均来源于《中国统计年鉴》。其中财政收入为因变量,税收,年末从业人员数为自变量。同样设置因变量的缺失机制为完全随机缺失,缺失率分别为5%,10%,20%,30%。运用最小二乘和ML2两种方法进行多元线性回归插补得到MAE、MSE结果如表7。
从表中我们可以看出,当缺失率为5%时,ML2的方法得到的平均相对误差,均方误差都比最小二乘的方法要小,说明相比于最小二乘,此时运用ML2的方法效果较好。当因变量的缺失率为10%,20%时,ML2方法所得到的MAE大于使用最小二乘的MAE,但是ML2 方法所得到的MSE远远小于使用最小二乘所得到的MSE。
4 结语
缺失数据的情况是非常常见的,这在进行数据分析时给我们带来很大的困难,如果只是单纯的删掉那些具有缺失数据的变量,这会使得我们丢掉很多现有的信息,使得分析的结果不准确。同时由于一些统计分析方法通常对数据的完整性要求较高,因此对缺失数据进行插补之后再进行相关的统计分析是非常有必要的。
文中针对具有较强相关性的数据,设置的缺失模式为完全随机缺失,对数据进行模拟验证分析,采用最小二乘回归插补,ML1回归插补、ML2回归插补、均值回归插补四种方法进行分析,从插补值的角度和模型的角度进行对比,最终发现,运用均值插补的效果最差,而且均值插补会随着数据缺失率的增加,而削弱插补的效果。而ML1回归插补、ML2回归插补在某些情况下优于最小二乘回归插补,因此可以运用到处理关联性数据进行插补,为实际运用中插补方法提供了更多的选择。
参考文献
[1] 赵茂先,余阳.一种线性回归新模型[J].统计与决策,2019,35(18):21-25.
[2] 廖祥超.九种常用缺失值插补方法的比较[D].昆明:云南師范大学,2017.
[3] 董世杰.三种线性回归多重插补法的模拟比较[D].天津:天津财经大学,2017.
[4] 程豪.大数据背景下缺失数据问题及对策[J].中国统计,2019(10):72-74.
[5] 魏娜,孙霞.统计缺失数据处理方法的比较研究[J].知识经济,2017(18):29-30.
[6] 邓建新,单路宝,贺德强,等.缺失数据的处理方法及其发展趋势[J].统计与决策,2019,35(23):28-34.
[7] 冯丽红.调查数据缺失值常用插补方法比较的实证分析[D].石家庄:河北经贸大学,2014.
[8] 张海霞.城镇居民医疗费用影响因素的调查中对不同机制下应答偏倚并存时的校正[D].太原:山西医科大学,2015.
[9] 邱贻涛,吴刘仓,马婷.缺失数据下联合均值与方差模型的参数估计[J].数理统计与管理,2015,34(4):621-627.
[10] 吕丹.一类数据挖掘算法及其在宫颈癌智能诊断中的应用[D].长春:长春工业大学,2019.
[12] 张晓琴,程誉莹.基于随机森林模型的成分数据缺失值填补法[J].应用概率统计,2017,33(1):102-110.
[13] 桂风云,魏传华.地理加权似乎不相关回归模型及其估计[J].统计与决策,2016(8):4-6.
[14] 吴刘仓,张家茂,邱贻涛.缺失偏态数据下线性回归模型的统计推断[J].统计与信息论坛,2013,28(9):22-26.
[15] 安佰玲,王森,胡洪胜.线性回归模型在因变量缺失下的约束估计[J].统计与决策,2013(11):19-21.
[16] 杨徐佳,于倩倩,王森.因变量缺失下线性回归模型的估计与检验[J].淮北师范大学学报:自然科学版,2011,32(1):24-28.
[17]刘宝慧.缺失数据情形下的回归插补及其方差分析[J].甘肃联合大学学报:自然科学版,2009,23(1):19-21.
[18]袁中萸. 多元线性回归模型中缺失数据填补方法的效果比较[D].长沙:中南大学,2008.
