能源行业研发项目的人月费率估算研究与分析
2020-02-21白耀清许相东
白耀清 许相东


摘要:本文为获取软件研发项目人员工作而需要支付的每月费用合计,通过定量分析方法,计算合理人月费用,帮助企业合理规划软件成本。软件研发项目的人月费率中包含软件开发的直接人力成本、间接人类成本、间接非人力成本及合理利润,但不包括直接非人力成本。根据企业的管理需求,在本文中分别给出了“人月费用(含差旅)”和“人月费用(不合差旅)”的测算结果。
关键词:信息化建设;软件成本;数据分析
1 概述
1.1 目的和目标
随着信息化技术的快速发展,信息技术已广泛应用到企业各个产业领域,信息化建设广度和深度也在逐步扩大。同时,对信息化建设工作的重要载体一一信息化建设项目提出了更高的要求。如何对不同类型的信息化建设项目进行准确度量、合理取费,定量计价成为信息化项目投资管控的一大难题。
信息化建设工作中人月费率的确定直接影响到项目的建设成本,是企业关注的重点,本项目从行业数据分析角度,确定合理人月费率给企业实际应用带来参考。
1.2 术语与缩略语
1.2.1 人月费率
为获取人员工作而需要支付的每月费用合计。在国家标准中,软件研发项目的人月费率中包含软件开发的直接人力成本、间接入类成本、间接非人力成本及合理利润,但不包括直接非人力成本。根据企业的管理需求,在本文中分别给出了“人月费用(含差旅)”和“人月费用(不含差旅)”的测算结果。
1.2.2 角色标准
对每一种项目角色,给出类型和名称,定义最低工作经验要求(单位是年)。这是采集和统计数据的基准。
1.2.3 基准角色
在原人工取费标准中,为便于对不同人员角色费用的换算和对比,将换算倍率(权重)为“1”的人员角色定义为基准角色。本文中,维持原有的人员角色基本不变,同时也维持原有的基准角色,支持同原人工取费标准的差异比较。定制开发类项目中的“基准角色”是“中级开发工程师”;套装软件类是“套装软件实施工程师”;规划咨询类是“规划咨询顾问”;运营支撑类是“运维工程师”;安全类是“安全助理”。
1.2.4 基准值
全称是项目基准角色费率值;是在各类项目中,被指定为基准角色人员的费率。原人工取费标准中,“基准值”是项目中其他人员角色费用换算的基准对象,其他各级别角色的人工费率以基准值乘以级别换算倍率计算。本项目通过数据统计测算每种角色的费用,通过基准角色与其他角色与比较,逆算出级别换算倍率。
1.2.5 标准值
全称是项目单位工作量的标准费用值;是项目中各角色人工费率乘以其在项目总工作量中所占比例后的汇总值,代表正常情况下,项目每单位工作量的平均费用。这个值受各类项目的工作量分布和对应角色费用的影响。
1.2.6 配比系数
全称是项目人员工作量配比系数;是各类项目的人工费用标准值与基准值的比值。用于直观感受项目中各类角色的工作量分配比例和费用情况。
1.3 基本原则
本次数据分析的基本原则是在充分了解行业人工取费水平的同时,兼顾企业信息化建设项目特殊性及历史情况,并通过对标行业水平,拉动集团相关能力逐步提升。主要工作策略包括:
(1)全面调研行业数据:利用行业基准数据并充分开展同类企业定向调研,不同数据交叉验证。主要数据来源包括能源行业基准数据、同类企业(能源行业大型国企)定向调研数据及第三方机构(薪酬网)委托调研数据,样本有效时间均处于2019年4月1日至2020年3月31日之间,涉及126个城市,27类岗位,样本总计超24000个;
(2)有效结合集团公司历史情况及现状充分利用原工作成果,基于原各岗位人工取费标准及行业人月费率增长数据,推算各岗位新人工取费标准可能值,并与行业数据测算结果交叉验证,形成各岗位人工费率最终推荐值,以保证新标准既处于行业数据合理范围,也能够最大化地贴近集团实际情况;
(3)数据分析方法适应性调整本次测算工作相较原测算工作,以相对小样本的定向数据为主变为小样本定向数据与大样本行业数据相结合。数据来源的不同导致数据处理方法及要点发生变化,大样本行业数据的处理关注异常处理、规格化处理(如地域、分级及级差测算)。在使用行业数据时,重点关注中值(P50)、相对低值(P25)和相对高值(P75),而将超过P90或不足P10的数据视为异常数据,通常也不与P90或P10对标,而是视为不应逾越的红线。
本次测算工作的主要内容包括:
(1)保持“项目分类”和“人员分类(角色)”基本不变;
(2)新增“人员分级标准(角色标准)”;
(3)修訂“人员费率标准(角色费用基准值、项目费用标准值、项目配比系数)”;
(4)修订“人员级差”,支持对角色标准和角色系数的优化和调整。
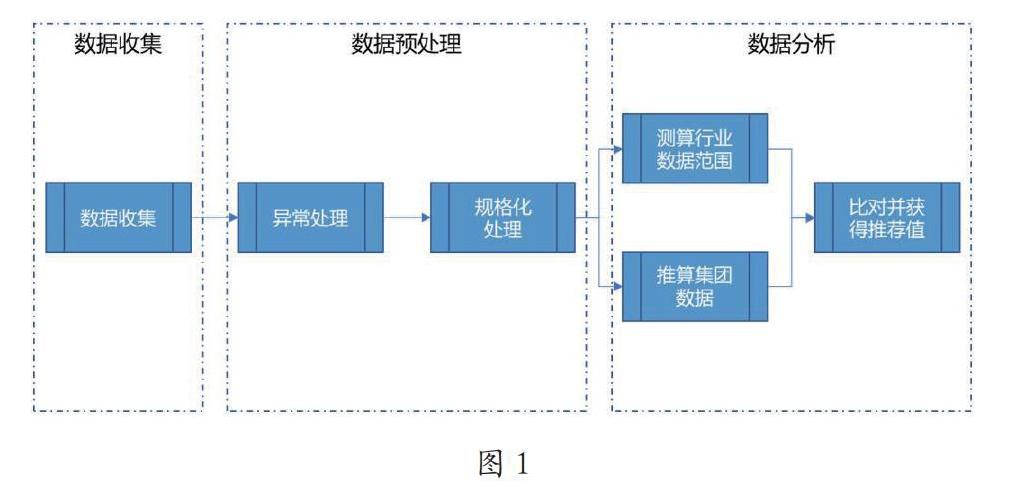
1.4 数据分析过程
本次数据分析的主要流程如图1所示。
对于主要数据及标准的分析要点如下:
(1)确定人月费率:主要借鉴能源行业及同类企业(如中石油、中石化、国网、南网、国家核电等)数据,以及相关定向研究报告结论,测算不同类型人员人月费率中值(P50)及合理范围,同时根据集团下属及关联公司历史数据推算相关单位当前人月费率水平及范围,并与能源行业数据测算范围交叉验证,尽量确保最终确定人月费率落于行业数据测算范围之内;若超出行业数据测算范围,则取行业数据测算高值(或低值);
(2)分类分级:主要基于当前分类分级方式,适当微调(增加安全相关);
(3)确定人员级差:以行业人员分级模型为基础适度简化,以提高模型的适用性和易用性,并用于对原始数据的规格化处理。
以下通过示例说明人月费率的确定方式。
假设岗位A的人月费率行业数据测算结果及基于集团原标准推算的数据如图2所示。
此时集团推算数据与行业数据有交集,则推荐值取行业数据测算结果与集团数据推算结果的均值。即该岗位新的人月费率建议值为(3.39+3.92) /2-3.66(万元/人月),其计算结果如图3所示。
而如果岗位A的集团推算数据为4.57万元/人月,此时集团数据与行业数据测算结果交集为空,则推荐值取行业数据测算结果高值或低值。即该岗位新的人月费率建议值为4.06万元/人月。其计算结果如图4所示。
2 主要数据来源
2.1 行业基准数据
CSBMK-2019年中国软件行业基准数据非常客观和清晰,能够为项目在大维度的数据度量上提供指导。
大维度数据包括软件项目人力成本、城市间费用差异、年度之间成本费用变化等。在本项目中,直接和间接使用的数据包括:
2.1.1 典型城市软件开发人月费率变化情况
如表2所示。
2.1.2 费率一薪酬转化系数
“费率一薪酬转化系数”通常用于在已知相关人员人月费率的情况下推算其薪酬水平,或者在已知相关人员薪酬水平的前提下测算其人月费率;计算公式为:
人月费率一人员薪酬水平×转换系数
[注:“人员薪酬水平”指人员的平均月度总收入,包括月薪、福利和年终奖等。]
在人工取费标准的测算过程中,对数据做规格化处理过程中需要使用“费率一薪酬转化系数”。本项目依据行业数据(CSBMK R 201906)中能源行业的796个高可信样本,其中组织级样本34,团队级样本547个,项目级样本215个;利用每个样本中的平均人月费率数据除以平均人员薪酬数据,得到费率一薪酬转化系数,然后计算所有费率一薪酬转化系数的主要百分位数(PIO/P25/P50/ P75/90)。
本项目规格化处理使用的P50和P75数值,测算结果的使用如图5所示。
2.2 能源行业的数据
能源行业有自己的项目分类方式和方法,这源于企业性质、业务能力和经营方式等。能源行业的每类项目的建设过程、工作量和角色安排,也有区别于其他行业的特点。
我们需要总结本行业的项目特点,建立项目分类、以及配套的项目角色分类和标准。
(1)数据来源:来自行业基准数据库中1954套高可信度数据及互联网招聘数据共计23417条,剔除无效及重复样本后,有效样本合计9607条。
(2)数据范围:样本有效时间均处于2019年4月1日至2020年3月31日之间,涉及126个城市,27类岗位。
(3)薪酬一费率转换:对于原始数据为薪酬数据的,乘以行业数据中的费率一薪酬转化系数中位数(2.21)。
(4)要求:剔除异常数据后,每类岗位的每个级别,有效样本不低于30个。
2.3 同企业类数据
主要借鉴能源行业及同类企业(如中石油、中石化、国网、南网、国家核电等)的数据,以及相关薪酬研究报告数据,测算不同角色类型人员的人月费率中值(P50)及上下限等。
(1)数据来源:本次定向调研共收集745条数据(涉及中石油、中石化、国家电网、南方电网、国家核电等35家能源行业国有大型企业),剔除无效样本后,有效样本合计483条。
(2)数据范围:样本有效时间均处于2019年4月1日至2020年3月31日之间,涉及28个城市,18类岗位。
(3)地区规格化:以相关岗位北京地区人员为基准,采用行业数据(CSBMK⑧201906)各城市人月费率转换系数进行折算,对于非副省级城市,归类到A/B/C/D类数据后再折算。
(4)级差规格化:以相应级别中间水平为基准,采用级差模型进行规格化处理。
(5)薪酬一费率转换:对于原始数据为薪酬数据的,乘以行业数据中的费率一薪酬转化系数上限(2.49)。
(6)统计方法统计各岗位各级别薪酬数据并进行规格化处理,计算各百分位数后剔除异常数据,再次计算各百分位数,以P50为标准值,以P25和P75为上下限。
(7)其他要求:剔除异常数据后,每类岗位有效样本不低于30个;每个岗位的每个级别,有效样本不低于7个。
工作量估算方法:
[注:工作量×人工费率一费用,每类项目都有可用的工作量估算方法规则。对工作量估算方法的定义和使用限制等,在本次的咨询活动中未作优化调整,本文“6数据使用”中依据的就是原“工作量估算方法”和使用规则,这里就不作重复展示了。]
3 数据处理与分析方法
3.1 数据处理
3.1.1 异常数据处理
数据统计过程中,常规的异常处理是指在数据分组中,剔除所有小于P10或大于P90的数据。(数据统计结果是在此基础上做规格化和再次计算的各百分位数,以P50为标准值,以P25和P75为上下限。)
本项目在做角色级差测算的过程中,需要使用逐步去除最大偏离数据的方法,通过多次去除那些权重最低、数值偏离主体结构最大的数据,以获取可用的级差模型和参数。
例如:
定制研发类项目中高级研发工程师费率的统计过程中,获取的数据如图6所示。
这些数据都可以作为人工取费的可用数据,却不能全部直接用于角色级差测算。薪资与经验关系如图7所示。
如表3所示,去掉“倒数第3行”的数量6/经验0/费用55729(数值最大和偏离最大),和“最后一行”无数量/经验0/费用21952(无数量不可信)后,得到当前使用的测算结果。
3.1.2规格化处理
来源数据包含有多种不同的影響因素属性,规格化是依据可度量的影响因素间的差异关系,通过影响因素的转换系数去除干扰属性,把需要的数据转换出相同属性(影响因素)下的数值。如图9所示。
