机器翻译的终极之路在哪里(上)
2020-02-10倪俊杰
倪俊杰


编者按:据不完全统计,世界上现存语言超过7000多种,即使人类不眠不休穷尽一生的力量也只能掌握几十种语言。于是,很多科学家开始思考,如何用机器来帮助人们解决沟通问题,因此机器翻译应运而生了。那么,什么是机器翻译?机器翻译是如何发展的?目前还有哪些应用呢?接下来,我们将共同来了解这些内容。
50多年前,由刘涌泉、高祖舜、刘倬三人共同编著的《机器翻译浅说》由科学普及出版社出版,书中提出了两个很有意思的设想。第一个设想是当你在人民大会堂的时候,你会发现无论哪个国家的人在台上讲话,与会者都能从耳机里听到自己国家的语言,同时你会发现在耳机里进行翻译的不是人,而是我们的万能翻译博士;第二个设想是当你去国外旅行的时候,随身可以携带一个半导体和其他材料制成的小型万能博士,当我们跟外国朋友交谈的时候,博士能立刻给你翻译出各自国家的语言。这两个设想在当时看来是“天方夜谭”,但现在都已经成为现实,第一个是现在的同声传译,第二个就是翻译机。这两项技术的实现都得益于机器翻译技术。那么,什么是机器翻译呢?实际上,机器翻译是一个充满挑战的研究领域,正因为难度很大,所以它被列为21世纪世界十大科技难题之首。但随着全球化进程的加速以及国际交流的日趋频繁,人们对翻译的需求空前增长,在这一领域的竞争正变得空前激烈,世界各国都在这个领域投入了大量的人力和财力,也使得机器翻译能够深切地融入到我们的生活中。既然如此,我们就有必要了解机器翻译的发展历程以及它的基本应用。
什么是机器翻译
百度百科释义:机器翻译(Machine Translation)又称为自动翻译,是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。机器翻译是自然语言处理(Natural Language Processing)的一个分支,与计算语言学(Computational Linguistics)和自然语言理解(Natural Language Understanding)之间存在着密不可分的关系。实际上,机器翻译的研究历史早于计算机的诞生,可以追溯到20世纪30年代初,法国科学家G.B.阿尔楚尼提出了用机器来进行翻译的想法。1933年,苏联发明家特罗扬斯基设计了把一种语言翻译成另一种语言的机器,只可惜他的翻译机因为客观原因最终没有制成。1946年,第一台现代电子计算机ENIAC诞生。随后不久,信息论的先驱、美国科学家W. Weaver和英国工程师A. D. Booth在讨论电子计算机的应用范围时,提出了利用计算机进行语言自动翻译的想法。1949年,W. Weaver发表《翻译备忘录》,正式提出机器翻译的思想。
细数机器翻译的发展进程,也是漫长而曲折的。1954年,美国乔治敦大学在IBM公司的协同下,用IBM-701计算机首次完成了英俄机器翻译试验(如下页图1),向公众和科学界展示了机器翻译的可行性,从而拉开了机器翻译研究的序幕。它能将俄语翻译为英文,但里面只内建了6条文法规则以及250个单字。
中国也在1956年就把这项研究列入了全国科学工作发展规划。1957年,中国科学院语言研究所与计算技术研究所合作开展俄汉机器翻译试验,翻译了9种不同类型的较为复杂的句子。但是在1966年,美国国家科学院语言自动处理咨询委员会(Automatic Language Processing Advisory Committee,ALPAC)发布题为《语言与机器》的报告,宣称“目前给机器翻译研究以大力支持没有太多的理由”“机器翻译遇到了难以克服的语义障碍”,从而导致机器翻译研究在世界范围内走向低迷。
进入70年代,随着计算机科学、语言学研究的发展,特别是计算机硬件技术的大幅度提高以及人工智能在自然语言处理上的应用,各种实用的以及实验的系统被先后推出,如Weinder系统、EURPOTRA多国语言翻译系统、TAUM-METEO系统等。20世纪80年代末期,IBM公司实现了基于噪声信道模型的统计机器翻译系统,并在美國国防部高级研究计划署(ARPA)组织的评测中取得了较好成绩,推动了机器翻译技术的快速发展。我国的“784”工程也给予了机器翻译研究足够的重视。80年代中期以后,我国首先成功研制了 KY-1 和MT/EC863 两个英汉机译系统。进入90年代,互联网的快速发展让人们对机器翻译的需求空前增长,国际性的关于机器翻译研究的会议频繁召开。中国也取得了前所未有的成就,相继推出了一系列机器翻译软件,如“译星”“雅信”等。21世纪以来,互联网公司纷纷成立机器翻译研究组,研发了基于互联网大数据的机器翻译系统,从而使机器翻译真正走向实用,如“有道翻译”“百度翻译”“谷歌翻译”等。近年来,随着深度学习的进展,机器翻译技术得到了进一步的发展,促进了翻译质量的快速提升,在口语等领域的翻译也能更加地道、更加流畅。
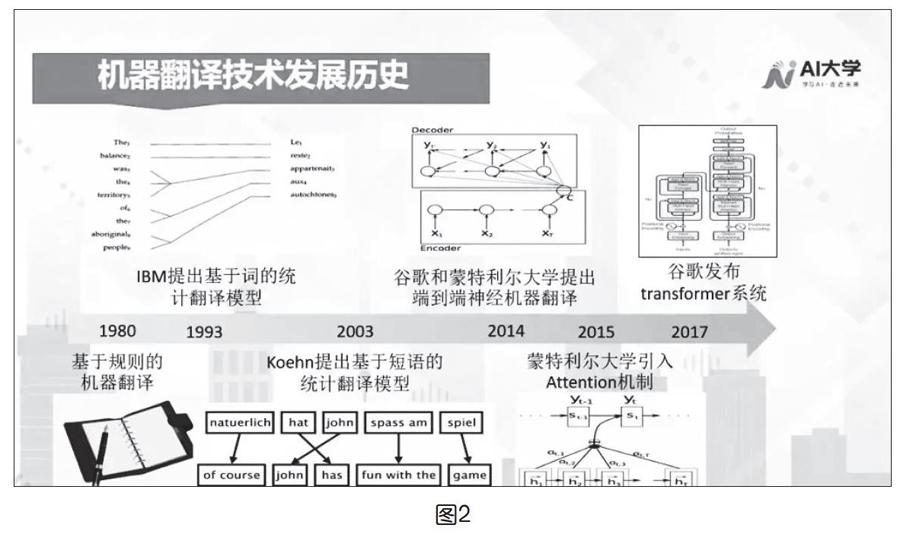
机器翻译技术的发展历程
机器翻译的原理并不简单,其发展历程也是由浅入深的。随着计算机技术和语言学的快速发展,机器翻译的方法也在更新迭代(如图2)。大致可以分为三种类型,分别是基于规则的方法、基于统计的方法和基于神经网络的方法。
1.基于规则的方法
最早期的机器翻译就是采用基于规则的方法。这类方法要找大量的人类语言学家来写规则,把一个单词翻译成另外一个单词、这个成分翻译成另外一个成分、在句子中出现在什么位置,都要用各种各样的规则表示出来,如早期的文曲星(如上页图3)。这类方法是知识驱动,需要语言学家的专业知识,包括源语言和目标语言的词法、语法、句法等,翻译的时候就基于这些规则去“嵌套运用”,最终“组合”成相应的句子。很显然,这种方法的优点是准确率比较高,缺点是成本很高,这里包括人力成本和开发周期成本,不同的语言要找不同语言的语言学家,而且如果句子长度、语境做出改变,规则的复杂度也会越来越高。基于规则的机器翻译的优点是十分精细的翻译引擎可翻译广泛的文本,缺点是必须为每个语言建立自定义的解析软件和词典,而且,基于规则的方法是相当“脆弱”的,它不能很好地处理俚语或隐喻文本。
基于规则的机器翻译的主要供应商包括Systran、PROMT、Lucy Software(商业软件)和Apertium(开源)。Systran从业较久,是网页翻译的先驱(早在20世纪90年代他们的翻译引擎就为Babelfish提供网页翻译服务了)。Apertium是由西班牙Universitat dAlacant主导的开源项目。
2.基于统计的方法
20世纪80年代,日本京都大学的长尾真教授提出了基于实例的机器翻译(example based machine translate),也就是别再去想让机器从无到有来翻译,它的理念是利用相似性复用系统中现有的翻译用例,这是一种数据驱动的方法。基于实例的机器翻译为统计机器翻译奠定了基础。统计机器翻译系统是基于概率和统计的模型而不是语法规则,它建立了一个数学建模,可以在大数据的基础上进行训练。它的工作方式是使用非常庞大的平行文本(源文本及其翻译)以及单语语料库训练翻译引擎。系统会寻找源文本和译文之间的统计相关性,然后根据源语言句子,去查找概率最大的译文,翻译引擎本身没有规则或语法概念。IBM于1993年发表了论文《机器翻译的数学理论》,提出了由五种以词为单位的统计模型,称为“IBM模型1”到“IBM模型5”。基于统计的机器翻译能够结合上下文,以及词、短语、句法等知识,从统计学的角度判断哪种翻译方式的正确率更高,统计模型的思路是把翻译当成几率问题。
总的来说,统计机器翻译的主要优点是不需要像基于规则的机器翻译一样,针对每个语言打造专门的翻译引擎,只要收集足够多的文本,就可以训练针对任何语言的通用翻译引擎。统计机器翻译的主要缺点是在翻译训练语料库中没有相似的资料文本时,不能得到准确译文。统计机器翻译通常不能生成高质量的文本,它经常在不顾及上下文联系的情况下翻译原文,而且译文语序往往不对。相比基于规则的方法,基于统计的方法成本较低,因为它和语言没有关系,一旦翻译模型建立以后,其翻译知识来自于大数据的自动训练。因此,在基于统计的机器翻译中,语言模型的建立至关重要,因为语言模型是衡量一个句子在目标语言中是不是流利和地道的关键,计算机可以使用翻译模型来“计算”如何将文本从一种语言转换为另一种语言。
基于统计的机器翻译的主要产品提供商有BeGlobal (SDL)、Google Translate、Microsoft Bing Translator、Moses等。其中Google Translate是谷歌基于自有的翻译引擎和研究技术,提供的免费在线翻译服务。Moses是一个开源的统计机器翻译引擎,它已被业界广泛应用于构建定制的机器翻译引擎。
3.基于神经网络的方法
随着深度学习技术的发展,从2014年起基于神经网络的机器翻译方法开始兴起。相比统计机器翻译,神经网络翻译从模型上来说相对简单,它主要包含两个部分,一个是编码器,一个是解码器。编码器是把源语言经过一系列的神经网络的变换之后,表示成一个高维的向量。解码器负责把这个高维向量再重新解码(翻译)成目标语言。2015年,百度发布了全球首个基于互联网神经网络的翻译系统。2016年,Google公布了神经网络机器翻译(GNMT),科大讯飞也上线了NMT系统。短短三四年间,神经网络翻译系统在大部分的语言上已经超过了基于统计的方法(PBMT),已经极大地接近普通人的翻译水平。
从图4中可以看出,从基于统计的方法到基于神经网络的方法,翻译能力可以提升到60%以上,这是极大的进步。相比基于规则和统计系统,基于神经网络的结构使系统更自适应,能处理更多更复杂的模型。它也可以根据经验自我学习,如果它提供了不正确的输出,它能从错误中吸取教训,并做出调整,以便下次更有效地执行任务。
机器翻译在生活中的应用
机器翻译的快速发展,在很多领域得到了广泛的应用。机器翻译技术的进步和系统性能的提升在为人们日常生活和工作带来更多便利的同时,也为该技术的产业化发展带来了更多商机。关于机器翻译的基本应用,大致可以分为三大场景:信息获取为目的的场景、信息发布为目的的场景、信息交流为目的的场景。以信息获取为目的的场景,可能大家都比较熟悉,如翻译或是海外购物,遇到一些生僻的词就可以借助机器翻译技术,来了解它的真正意思。在信息发布为目的的场景中,典型的应用是辅助笔译,比如起草一份文件需要多国语言的版本,就需要用到机器翻译技术了。以信息交流为目的的场景,主要解决人与人之间的语言沟通问题,如同声传译等。接下来,我们来看一些比较有意思的应用。
1.特殊中文翻译
机器翻译除了能做多国不同语言的翻译之外,还可以在中文方面做一些有意思的事情。中文博大精深,源远流长,文言文就是很有中國特色的语言表达方式。在百度翻译中,实现了输入白话文后,就能输出文言文的效果(如图5)。
除了翻译文言文,机器翻译还可以写诗、写春联。在微信里关注小程序“为你作首诗”,输入藏头文字,选择诗句类型,就可以由程序自动写一首诗(如下页图6)。说起机器写诗,就不得不提微软小冰了。微软小冰是由微软(亚洲)互联网工程院于2014年正式推出的融合了自然语言处理、计算机语音和计算机视觉等技术的人工智能“机器人”。微软小冰已通过人工智能创造技术,学习优秀的人类创造者的能力,进行基于文本、语音和视觉的内容生成。在文本创作方面,主要覆盖诗歌、金融摘要及研报等领域。2017年5月,微软与湛庐文化公司合作,授权出版了历史上第一部由人工智能创作的诗集《阳光失了玻璃窗》。同年8月,中国台湾与时代文化公司合作,授权出版了该诗集的繁体中文版本。2019年,与中国青年出版总社合作并授权出版了第一部由人工智能与200位人类诗人联合创作的诗集《花是绿水的沉默》。
2.同声传译设备
什么是同声传译?其实可以分解开来看,“同”表示时间延迟要短,在说话的同时基本上翻译结果就传递出来;“声”是指用到的是语音技术,包括语音识别和合成;“传”就是信息传递要准确,得把原本的意思准确地表达出来;“译”就是翻译技术,对应到机器翻译。同声传译设备是实现高级别国际会议同步翻译不可缺少的系统设备,通过该设备可以保证演讲者在演讲的同时,内容被同声翻译成指定的目标语言。随着当前社会现代化进程的不断推进以及人们生活水平的提高,同声传译已经不仅仅是高端需求,普通民众在出国旅游或者商务洽谈的时候也会有此类需求。在某购物网站搜索“同声传译器”,价格从几百到几千不等,款式有手持式、头戴式,也有耳机式。点开某热销款同传翻译设备,可以看到如下介绍:支持59种语言,可以实现0.5秒快速翻译,中英文离线翻译也能达到大学英语六级水平(如图7)。
美国发明家、未来学家雷·科兹威尔最近在接受《赫芬顿邮报》采访时预言,到2029年机器翻译的质量将达到人工翻译的水平。对于这一论断,学术界还存在很多争议。当机器翻译得到广泛应用的时候,就有声音说机器翻译将会取代人工翻译,“翻译员”可能会集体下岗,真的会这样吗?梦想与现实的距离到底有多远?客观地说,尽管神经网络带来了翻译质量的巨大提升,但仍面临许多挑战。为此,关于机器翻译关键技术原理以及它的发展与挑战,我们将在下一期进行探讨,敬请期待!
