一种基于SSD改进的小目标检测算法
2020-02-04贾小云曾奇
贾小云 曾奇
(陕西科技大学电子信息与人工智能学院 陕西省西安市 710021)
目标检测是计算机视觉方向的研究热点[1]之一,在视频监控,违法车辆检测,智能车牌识别,行人识别检测等各领域[2]起着决定性作用。与此同时,目标检测技术也是一项十分具有挑战性的任务[3]。目标检测算法分为传统目标检测算法和深度学习目标检测算法两类,传统的目标检测算法包括可变形部件模型[4]和滑动窗口模型[5],这两种方法采用提取到的特征和一些分类器进行结合,利用尺度不变特征(Scale Invariant Feature Transform, SIFT)[6],方向梯度直方图(Histogram of Oriented Gradient,HOG)[7],Haar[8]等人工设计的特征结合SVM, Adaboost 等一些分类器,对数据的特征进行识别分类,得到检测结果。除此之外,还有根据数据特征进行模型建立,最后对模型进一步训练优化,得到检测结果。这种方法包括Hough 变换[9],光流法[10],背景减除法[11],帧差法[12]。
深度学习中的卷积神经网络取代了以前手工设计特征的特点,通过卷积计算的形式自主学习位于不同层级的特征,这样得到的特征结果不但表示特征能力强[13],而且更加的丰富多样。主要包括基于区域提议检测和基于回归的检测算法。基于区域提议框是先通过生成候选目标区域算法(例如Selective Search)产生一些目标候选区域,而后将得到的目标候选区域经过卷积神经网络提取与之相关的数据特征,最终用提取到的特征来预测待检测对象中目标的类别和定位。其代表算法有:R-CNN[14],Fast R-CNN[15], Faster R-CNN[16]等。基于回归的检测算法摒弃了费时的目标区域生成过程,而是直接用预先设计好的方法将默认框划分开,随之进行分类和回归,有效地改善了目标对象的检测速度,同时也满足检测系统的实时性要求。其代表算法有:SSD[17], YOLO[18]等。
SSD 算法借鉴了Faster R-CNN 算法中的锚框检测机制(anchor)的思想,虽然保证了检测的实时性和准确率,但是为了改善SSD算法对小目标的漏检情况,结合模型的匹配策略和分类器的分类效果做出改进。以便改善模型对小目标检测的准确率和稳定性。
1 目标检测算法SSD
1.1 SSD算法的模型结构
Single Shot MultiBox Detector 是一种单阶多框检测的算法,使用VGG16[19]模型作为其训练的基础网络结构,将先验框的设计理念引入其中,并且嵌入级联卷积层,采用金字塔结构的特征层直接在不同尺度上通过较小的滤波器分层提取特征,低层次的特征图能代表含有更多细节的低层语义信息,提高语义分割质量,适合小尺度目标的特征学习。高层次的特征图能代表高层语义信息,能够光滑分割结果,适合大尺度的目标进行深入学习,从而获得不同层次多尺度的特征图,实现不同尺度的物体检测。SSD 网络结构图如图1 所示。

图1:SSD 网络结构
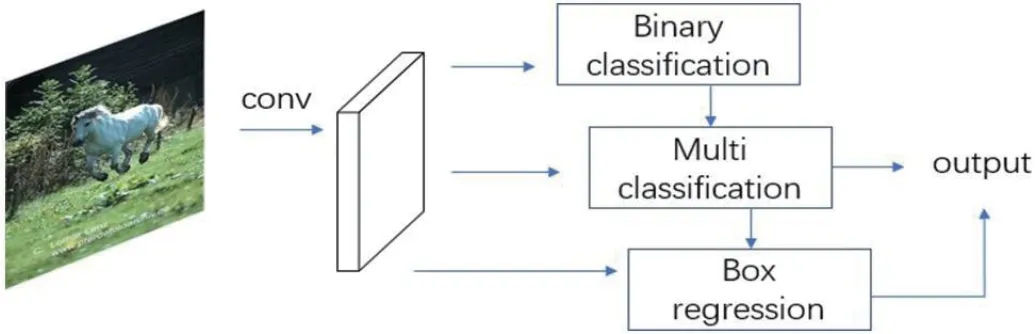
图2:基于SSD 算法改进的网络模块结构

图3:Rank Matching 算法匹配的样本示意图
SSD 借鉴了Faster R-CNN 算法中的anchor 机制和YOLO 算法中的回归思想,并将两者结合,一方面采用anchor 机制通过不同宽高比率的默认框提取不同尺寸的特征,另一方面利用回归的思想减轻深度学习神经网络复杂的计算任务。和YOLO 算法使用全局特征提取的理念相比,SSD 算法对目标的识别检测更加高效。
1.2 损失函数
SSD 算法中的损失函数依据预测部分的输出结果而设计,损失函数包括两部分,一部分是定位损失(localization loss),一部分是置信度损失(confidence loss)。其中,定位损失指的是对目标边界框的坐标回归时产生的误差,公式如下:
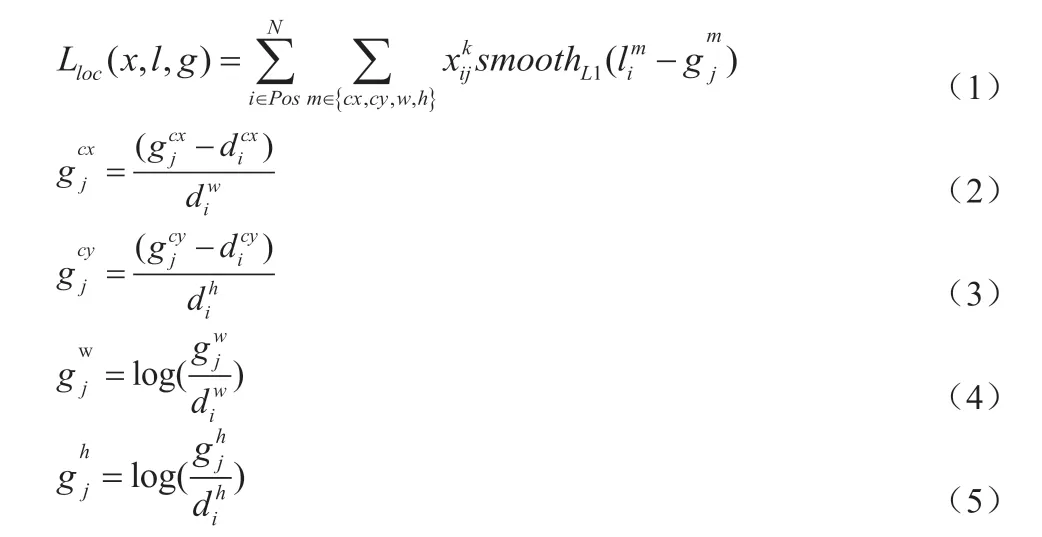
置信度损失指的是在对目标做分类回归时产生的误差,公式如下:

其中c 是经过softmax 处理后得到的类别置信度(class confidence, or class score )。N 是经过匹配策略得到的默认框default boxes。SSD 做类别预测时,并没有像位置预测那样把负向匹配得到的默认边界框忽略掉,而是把背景也作为一个特殊的类别,然后把负向匹配计算出的损失划分到背景类别下。
于是我们得到最终的损失函数为:
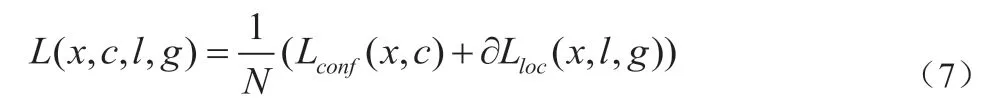
其中,N 是正向匹配得到的默认边界框数, 是位置损失的权重参数,表示置信度损失和位置损失所占的权重关系,一般情况下两者取相同的权重,设值为1。
2 SSD算法中存在的缺陷
2.1 网络结构部分
原始的SSD 算法中网络结构使用的是VGG16 作为主干网络,各个卷积层之间采用级联的方式进行连接,前一层卷积层的输出就是下一层卷积层的输入,相邻的卷积层之间存在影响关系,与之前的卷积层毫无关联,这样的网络结构并没有充分的将之前的卷积层提取计算得到的大量特征数据加以利用。并且,当前面卷积层的权重参数发生更新出现误差时,势必会对后面的卷积层以及权重参数产生影响。与此同时,在SSD原始方法中,背景作为一个特殊的类别,成为了多类别预测器的预测对象。这样做虽然简化了预测过程,但是由于背景中各类的特征纹理数量要远多于正常目标的类别物体。因此会造成多类别分类器的性能失衡。进而也会对最终的预测结果产生影响。
2.2 模型匹配过程
在SSD 算法的匹配策略中,采取的方法与Faster R-CNN 中的方法类似。首先每一个ground true box 目标框都会选择一个与其IOU 最大的anchor 进行匹配,从而保证每个ground true box 至少匹配到一个anchor,然后在anchor 与ground true box 所有的IOU 中,挑选出阈值大于0.5 的部分,被用于后续的预测环节,同时将这个anchor 匹配到其最大IOU 对应的物体上。然而,对于较小或较大物体,其匹配到的正样本数量非常有限,大大少于中等规模物体匹配到的样本数量。经实验证明,样本数量的巨大差异不利于训练过程中损失函数的收敛,对检测性能存在一定的影响。
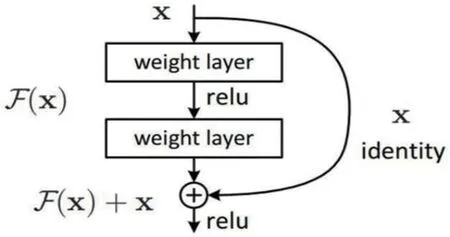
图4:残差块计算示意图
3 改进后的SSD网络模型
3.1 网络结构
针对SSD 原算法中背景的多样性造成的多类别分类器性能失衡的问题,加入一种新的二分类器对样本是背景还是物体进行预测,而将正式的多分类任务交由原算法中多类别分类器来完成。这样设计,由于背景和物体是使用单独的分类器进行预测,因此可以通过改变其正负样本来提高分类器的性能。改进后的网络结构如图2 所示。
3.2 匹配策略
为了解决不同尺寸的物体匹配到的正样本数量不均衡的问题,提出了一种新的匹配方法Rank Matching。其匹配过程中的主要思想是将每个ground true box 对应的IOU 进行降序排列,然后取前P个IOU 对应的anchor 作为正样本,每个anchor 有且仅有一次的匹配机会。其中,Rank Matching 的输入包括:每个anchor 与ground true box 对应的IOU {uij},参数P。输出包括:每个anchor 所匹配得到的ground true box 的索引Match。样本匹配的示意图如图3。
3.3 模型训练
3.3.1 主干网络的构建
SSD 模型中的VGG16 网络是其结构特征为密集的3 * 3 卷积层,缺少短接路径,与ResNet[20]相比,当性能相同时,VGG 占用的参数量大5 到10 倍,由于显存空间,计算力代价,时间成本等因素的限制,因此我们放弃SSD 主干网络VGG16,而是使用在ILSVRC 上预训练的ResNet-50 作为主干网络。ResNet 是2015年何恺明等人提出的一种用于ILSVRC 分类任务的深度的神经网络,其主要特点是在层与层之间引入了短接路径(shortcut path),许多个残差块(residual block)内部有短接路径连接残差块的输入与输出,以此提高特征数据的利用价值。残差块计算示意图如图4 所示。因此得到优良的语义保持特征,在分类任务的性能表现上,相比其他的深度神经网络更为优良。
3.3.2 特征的提取
将300 × 300 的图片送入 ResNet-50 后,其中间各特征图的尺寸分别是 (1, 256, 75, 75),(1, 512, 38, 38), (1, 1024, 19, 19), (1, 2048, 10, 10),由于第一层特征图太靠近图片输入端,语义信息不强,其参数量空间占比较大,所以不使用第一层特征图,而使用从第二层开始的中间特征层输出。在这三层特征图基础上,在顶端分别使用通道数为 256,卷积核大小为3 * 3,步长为 2 的卷积核再增加两层下采样层,得到的输出特征图的尺寸分别为 (1, 256,4, 4) 及 (1, 256, 1, 1)。由 ResNet-50 得到的3 层特征图加上由扩展得到的 2 层特征图,构成了 SSD 模型所使用的所有特征图。
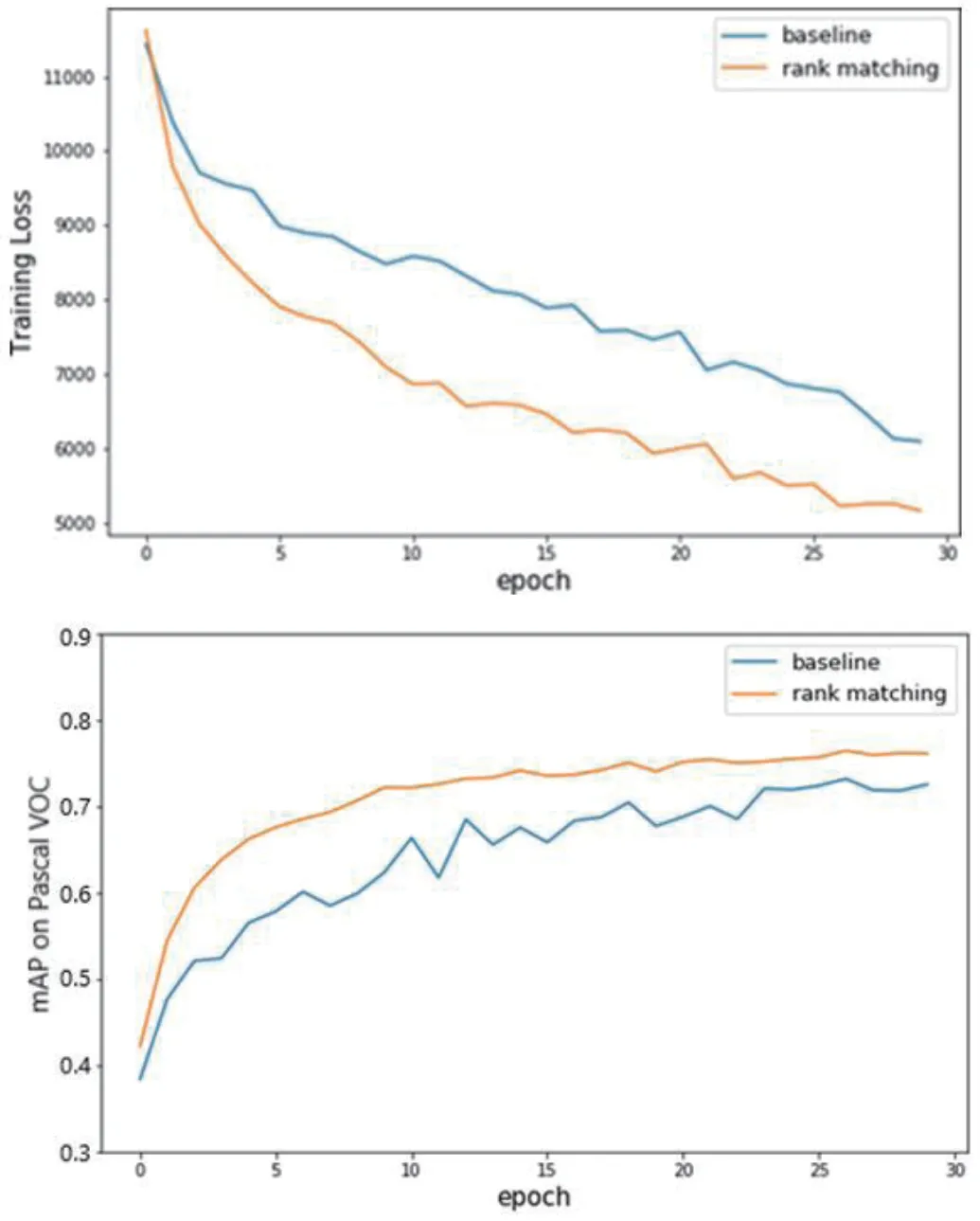
图5:Rank Matching 匹配策略的训练曲线
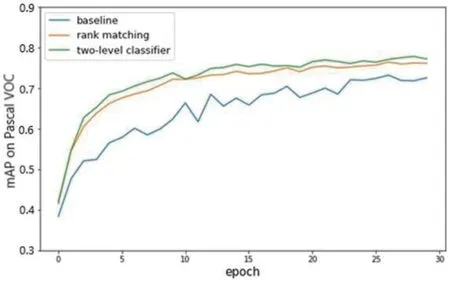
图6:调整分类输出阈值后的AP 曲线
在这5 层特征图上构建边界框回归预测器和多分类预测器。边界框回归预测器仅由一个卷积核大小为3*3,通道数为4N,步长为1,padding 数为1 的卷积核构成,其中N 指的是每个位置的 anchor 数。而多分类预测器由一个卷积核大小为3 × 3,通道数为N × (C + 1),步长为 1,padding 也 为 1 的卷积核构成,其中C 指的是数据集中所有类别的数量,在 Pascal VOC 数据集上,C 等于 20。由于它们在整个特征图上参数共享,所以占用空间小,计算速度快,训练过程较为稳定。这两个卷积核通过在特征图上“滑动”的方式对每个位置的 anchor 进行预测,从而得到固定数目的输出预测。通过进一步对这些输出预测做筛选,得到目标检测模型最终的输出框。
3.3.3 anchor 尺寸的设定
SSD 的另外一个特征是引入anchor 机制。在复现SSD 时,为了保证简洁性和有效性,本文按照SSD 算法中的公式,在特征图的每个位置设定6 个anchor,并且其在每层特征图上的基准尺寸遵循以下经验公式:

图7:目标检测效果图
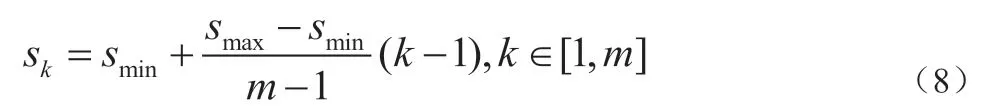
取smin = 0.2,smax = 0.9,m = 5,由经验公式得到的5 层特征图对应的 anchor 的基准尺寸SK分别为 {0.2, 0.375, 0.55, 0.725, 0.9}。每个anchor 具体的宽和高(anchor 的宽和高都是相对于原图片宽和高的比例)可由如下公式计算得出:

分别取宽高比为{1, 2, 3, 1/2, 1/3},按照第一个宽高比匹配所有的SK,第二个及其后面的宽高比只匹配第一个Sk的匹配方式,可以得到5 个anchor 的尺寸。另外,为了增加anchor 的覆盖率,对于宽高比等于1 的情况,额外地增加了一个基准尺寸S'k,其计算方式如下:

由此我们得到每层特征图对应的 anchor 尺寸如表1 所示。
表格中的数据对(w, h)分别代表anchor 的宽和高,这里的宽和高指的是相对于输入图片的宽和高的比例。通过这种方式定义anchor,我们一共可以在5 层特征图上得到6 × (382 + 192 + 102 + 42 + 12) = 11532 个anchor。
3.3.4 损失函数的定义
损失函数定义如下:
对于回归损失, 我们取 Smooth L1 作为损失函数:

对于分类损失,对 softmax 的结果取对数后,采用 Cross-Entropy Loss 作为损失函数。经实验发现,对正样本和负样本的损失同时进行取均值可以提高模型的精度,因此采用和 SSD 原方法不一样的多分类损失函数计算方法:
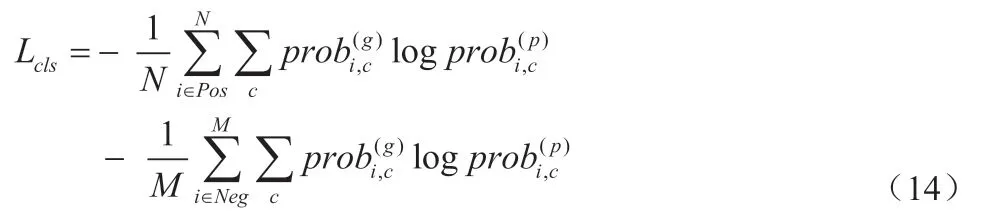
其中,Pos 指的是一张图片中正样本的anchor 的索引,N 为正样本的数目,Neg 指的是一张图片中负样本的anchor 的索引,M为负样本的数目,(g)表示ground truth,(p)表示 prediction,即预测结果。

表1:在5 层特征图上的 anchor 尺寸

表2:目标检测结果的对比
对回归任务和分类任务进行联合训练,得到如下的模型总损失函数:

经交叉验证,在Pascal VOC 数据集及实验过程中,我们取 = 1。
4 实验及结果分析
为检验改进后的算法有效性,在PASCAL VOC 2007+2012 数据集上进行测试,并将测试结果与改进前后的结果进行对比。
4.1 实验细节
改进后的算法使用ResNet-50 v2 作为主干网络,删去网络顶层的 BatchNorm 层,全局池化层及分类输出层后,扩展了两层卷积层,提取整个网络顶端的 5 层残差块或卷积层的输出作为特征图,在这 5 层特征图上分别构建两个3 * 3 的卷积核作为 predictor,使用 Xavier 的初始化方法对新添加的卷积层进行参数初始化。使用 Pascal VOC training 数据集,batch size 为 5,使用的优化方法为 SGD,初始学习率设置为 0.01,weight decay 设置为 0.0005,动量(momentum)为 0.9,学习策略使用多项式学习策略,其中的指数参数设置为 0.9,在整个数据集上训练的 epoch 数为 30,得到的最优 mAP 值为79.2%。
在 Pascal VOC 2007+2012 数据集上,以 0.005 为初始学习率,使用多项式平滑下降的学习策略,分别得到使用SSD 原始匹配策略和 Rank Matching 匹配策略训练过程的 Loss 随迭代次数的变化及 mAP 随迭代过程的变化如图5 所示。
从图中可以看出,在刚开始的时候,两者mAP 的增长速率几乎相同,但是随着迭代次数的增加,原始匹配方法对应的 mAP 上升趋势减缓,而 Rank Matching 方法仍保持着良好的增速。这是因为原始匹配方法得到的正样本数目不均衡的训练样本使得 loss 函数在收敛的过程中无法找到全局最优点。复现出现的SSD mAP 为74.3%,经过改进其匹配算法后,mAP 达到 77.8%,可见对匹配策略的改进是有效的。
因为增加了二分类器,所以损失函数也需要改写:
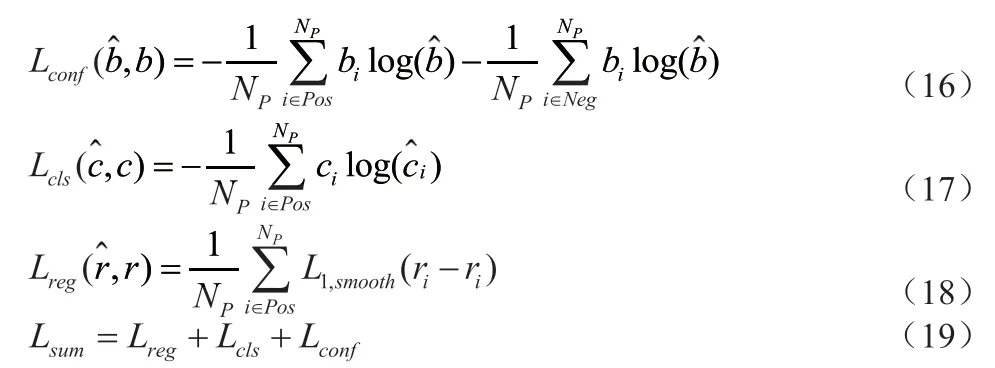
经实验测试,可以通过将两个分类器设定阈值,把二分类器和多分类器改成“半并联“的结构,并且辅以调整损失函数中各部分的权重,对数据进行更多样式的增广等方式来改善新网络结构性能,得到每次迭代的mAP 值,如图6 所示,可以看出,经过调整后,新的网络结构性能大幅上升,准确率比原始方法提高了约4.9%。
4.2 实验结果
以ResNet-50 v2 为主干网络,对SSD 模型进行了复现,并对 SSD 模型提出了两点改进方案。其中,新的匹配方法 Rank Matching 使模型精度在 Pascal VOC 2007+2012数据集上升了 3.5%,新的网络结构使模型精度提升了1.4%,特别是对于小目标的检测性能有了显著的提高。部分小目标实验检测效果和目标检测结果如图7 和表2 所示。
5 结论
研究过程中首先介绍了原始SSD 算法的网络模型框架以及工作原理,然后分析了该算法对小目标检测效果较差的原因,同时指出在网络框架和匹配策略方面有待改进的地方,针对这些问题提出了相应的改进方法,首先使用具有残差结构的ResNet50 骨干网络代替级联的网络,除此之外加入Two-level classifier 对样本是背景还是物体进行预测,从而改善背景因素对多分类器检测目标的影响,同时为了解决正负样本不均衡问题,在网络结构中加入了Rank Matching 匹配方法并从头开始训练,以提取更多的特征细节。改进之后的SSD 算法在Pascal VOC 2007+2012 数据集上进行了训练和测试,获得了较高的mAP,相比原始算法准确率共提高了4.9。尤其是对于小目标的检测而言,效果显著。下一步将扩大数据集范围,使之涵盖更多类型目标,改善算法模型,加强各层之间的特征共享,提高模型的泛化性,进一步提高模型性能。
