基于深度学习的模糊图像超分辨率重建方法
2020-02-04彭雯
彭雯
(江西理工大学软件工程学院 江西省南昌市 330013)
通常情况下,利用硬件设备提升模糊图像分辨率,例如在成像过程中,增加传感器数量或者减少传感器尺寸,均可以获得高分辨率图像[1]。但是,在单位像素尺寸内,具有一定的光学限制,传感器的扩散与散粒是无法避免的,导致得到的图像模糊较重,信噪比较低,依然无法达到图像信息服务的要求。在图像处理角度来看,增加一个图像像素从低分辨率恢复到高分辨率的过程;在信息处理角度来看,提升图像分辨率就是对数字采样信号进行再采样的操作。由于模糊图像信息的不确定性,上述两个角度都是一个比较困难的挑战[2]。
模糊图像超分辨率重建方法可以很好的解决上述问题,但是现有模糊图像超分辨率重建方法存在着峰值信噪比(PSNR)与相似性度量值(SSIM)较高的缺陷,为此提出基于深度学习的模糊图像超分辨率重建方法研究。
1 模糊图像超分辨率重建方法研究
1.1 深度学习结构选取
深度学习结构具有多种,目前使用较为广泛的包含受限玻尔兹曼机、深度置信网络、自编码器与卷积神经网络[3]。通过现有文献研究发现,受限玻尔兹曼机更适用于模糊图像信息处理,为此选取受限玻尔兹曼机作为此研究的深度学习结构。
受限玻尔兹曼机(RBM)是一种随机神经网络结构,节点之间采用对称方式连接,并且层间全连接,层内无连接。受限玻尔兹曼机结构如图1 所示。
如图1 所示,可见层的功能为输入数据;隐含层的功能为特征提取;权重矩阵指的是可见层与隐含层之间的连接权重矩阵。受限玻尔兹曼机节点单元是任意指数族单元,其状态取值为0 或1,其中,0 表示的是未激活,1 表示的是激活。
假设可见层单元数量为n,隐含层单元数量为m,受限玻尔兹曼机状态记为(v,h),其具备的能量表示为:
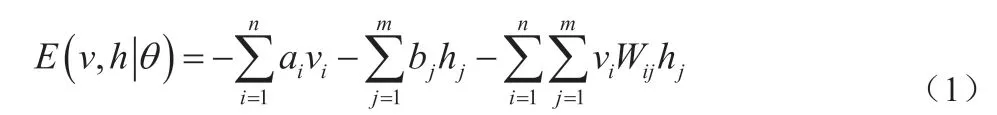
对于实值参数θ 的求解,利用最大化似然函数学习训练得到,表达式为:

式(2)中,T 表示的是学习训练样本的数量。
上述过程完成了深度学习结构的选取,选取结果为受限玻尔兹曼机模型,为下述模糊图像稀疏表示模型构建提供理论基础。
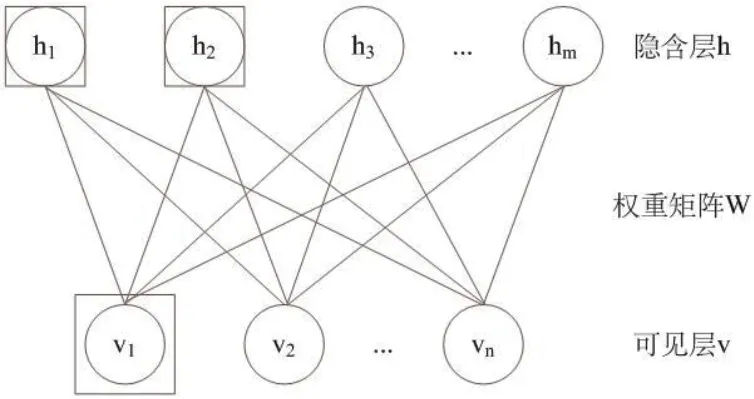
图1:受限玻尔兹曼机结构图
1.2 模糊图像稀疏表示模型构建
在模糊图像表示领域中,呈现着一定的稀疏性,而模糊图像超分辨率重建的关键就是找到图像的自相似性关系,即构建模糊图像稀疏表示模型。
在模糊图像中提取一个图像块,记为y,从对应超分辨率图像相同位置提取一个图像块,记为x。通过受限玻尔兹曼机模型对样本模糊图像进行训练,得到低分辨率字典Dl与超分辨字典Dh。则x 在超分辨字典Dh中原子的稀疏线性组合表示为:
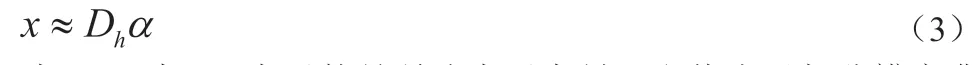
式(3)中,α 表示的是稀疏表示向量,取值小于超分辨字典原子数量k。
则y 在超分辨字典Dh中原子的稀疏线性组合表示为:

依据得到的低分辨率字典与超分辨字典,对于模糊图像的任意一个图像块y,均可以通过公式(4)得到模糊图像块的稀疏表示向量α,通过公式(3)得到相应的超分辨率图像块x。
由此可见,在模糊图像超分辨率重建过程中,模糊图像稀疏表示是其中的重中之重。上述过程通过联合字典学习,保障了模糊图像子块与相应超分辨率图像子块稀疏描述的一致性,为模糊图像超分辨率重建的实现做准备。
1.3 模糊图像超分辨率重建
以上述构建的模糊图像稀疏表示模型为基础,制定模糊图像超分辨率重建程序,具体步骤如下所示:
步骤一:超分辨率图像子块的重构。
对于模糊图像的某个子块y,依据模糊图像稀疏表示模型获取模糊图像子块y 的稀疏表示向量α,利用迭代收缩算法求解下述模型:

式(5)中,||α||1表示的是α 的1-范数。

表1:峰值信噪比数据表

表2:相似性度量值数据表
基于联合字典学习理论可知,α 也是模糊图像对应超分辨率图像子块的稀疏描述。为此,在得到稀疏表示向量α 后,依据公式(3)对超分辨率图像子块x 进行重构;
步骤二:超分辨率初始图像的生成。
上述步骤实现了超分辨率图像子块的重构,但是图像子块位置并不全部正确,为此需要将重构子块依据正确位置关系进行拼接,得到超分辨率初始图像;
步骤三:全局误差补偿。
对于模糊图像的超分辨率重建来说,过程中涉及图像子块重叠区域的平滑运算,可能会致使模糊图像细节信息无法恢复,故引入残差图像的迭代误差反向投影策略实现超分辨率图像的高频补偿;
步骤四:输出超分辨率图像。
模糊图像超分辨率重建程序中,最关键的步骤就是误差补偿,其实现流程如下:
输入:原始模糊图像Y,初始超分辨率图像X,设置最大迭代次数为Q;

对超分辨率图像进行下采样Xdown;
求解模糊图像与Xdown的差值图像C;
对差值图像C 进行上采样D;
利用模板P 对D 进行卷积,得到Xh;
End
step 3:输出超分辨率重建图像X=Xh。通过上述过程实现了基于深度学习的模糊图像超分辨率的重建,为图像信息的获取提供便利。
2 对比实验分析
2.1 实验准备
为了保障实验的顺利进行,首要的任务是设置仿真对比实验参数,主要包含训练样本集使用轮数、步长与误差补偿迭代次数,具体实验参数确定过程如下所示。
依据网络搜索得到训练样本集,包括人物、风景、自然图像等。
实验过程中,设置采样因子为s,取值为2。将训练样本作为超分辨率基准图像,利用5×5 高斯模板进行平滑滤波处理,并通过字典规模训练样本。通过上述过程得到最佳训练样本集使用轮数、步长与误差补偿迭代次数分别为100 轮、1 与20 次。
2.2 峰值信噪比(PSNR)分析
峰值信噪比指的是信号最大可能功率和噪声功率的比值。常规情况下,峰值信噪比越小,表明图像分辨率越高,则方法性能越好。
以图2 选取的训练样本为实验对象,分别在自变量—联合字典维数256、512、1024 下进行实验,得到峰值信噪比数据如表1 所示。
如表1 数据显示,随着联合字典维数的增加,重建图像峰值信噪比不断增加,分辨率逐渐降低,充分说明当联合字典维数为256时,重建图像峰值信噪比最低,重建图像分辨率最高。
2.3 相似性度量值(SSIM)分析
相似性度量值是判定两个事物之间相近程度的一种度量。常规情况下,相似性度量值越小,表明图像分辨率越高,则方法性能越好。
任选两幅模糊图像为实验对象,分别在不同图像子块大小(5×5、6×6、7×7、8×8、9×9)下进行实验,得到相似性度量值数据如表2所示。
如表2 数据显示,随着图像子块大小的增加,相似性度量值呈现“V”型变化趋势,当图像子块大小为7×7 时,相似性度量值最小,重建分辨率最高。
通过上述实验结果显示:提出方法在联合字典维数为256,图像子块大小为7×7 时,峰值信噪比与相似性度量值最低,图像分辨率较高,充分说明提出方法具备更好的性能。
3 结束语
此研究将深度学习理论引入到模糊图像超分辨率重建方法中,极大的降低了峰值信噪比与相似性度量值,得到分辨率更好的重建图像,为图像信息的获取提供便利。
