样点数量与空间分布对县域尺度土壤属性空间预测效果的影响*
2020-01-15巫振富赵彦锋程道全
巫振富 赵彦锋 程道全 陈 杰†
(1 郑州大学公共管理学院,郑州 450001)
(2 郑州大学农学院,郑州 450001)
(3 河南省土壤肥料站,郑州 450002)
土壤属性及其空间分布信息是区域耕地地力评价、土壤改良利用、精准农业实践、生态环境保护等一系列科研与生产活动不可或缺的数据基础。随着数据获取、处理和挖掘相关技术的迅猛发展,基于土壤空间预测的数字土壤制图(Digital soil mapping)已成为当前高效组织和表达土壤信息空间分布的最主要方法[1-2]。所谓数字化土壤制图,就是基于土壤观测数据与土壤学知识,应用数学模型推断土壤类型和土壤属性的时间与空间变异,创建和组织空间土壤信息系统的过程[2-4],被誉为20 世纪以来继航空摄影应用于土壤调查制图之后的又一次技术革命[5]。
样点是土壤属性观测信息、相关环境因子信息以及两者之间关系信息的载体,是土壤调查与制图的基石。在各种尺度上,土壤采样策略均对土壤空间预测效果与数字化土壤制图输出精度具有决定性影响。样点数量与空间布局是土壤采样策略的核心,需要在全面权衡预测精度、采样成本、作业效率等多方面因素的基础上确定。以往相关研究主要分析和探讨样点数量对土壤空间预测精度的影响,其主要目的是寻求确定最优样点数量的策略与途径。此类研究常用的技术手段是在案例研究中设置若干不同数量的样点系列,通过对比不同样点系列的土壤属性空间预测精度以发现和确定最优采样点数量[6-10]。如张晓光等[11]以土壤盐分为对象,通过对比分析12个不同数量的样点系列的预测结果,发现满足黄河三角洲县域尺度下土壤盐分空间变异表达的土壤样点数量每1 000 km2不能小于107 个样点。这类研究的不足之处在于探讨样点数量变化对土壤属性预测结果的影响时,忽略了样点数量变化会导致样点空间分布的变化这一客观事实,因此很难判断上述两种因素对土壤空间预测结果的具体影响。一些学者[12-13]则基于土壤属性的统计学特征,利用经验公式直接计算得到一定置信水平条件下的最优采样点数量,但经验公式忽略了土壤属性的空间变异情况,以此得到的最佳样点数量是否可靠有待商榷[14]。
另外一类研究则将重点放在揭示和分析样点空间分布在土壤空间预测中的重要影响,其核心目的是优化土壤样点的空间分布格局[15-20]。如van Arkel和Kaleita[21]在田块尺度上利用K均值聚类方法确定了用于估算表层土壤水分的最佳采样点位置。Yang等[22]在土壤样点数相同的条件下,比较了综合等级逐步采样(integrative hierarchical stepwise sampling,IHS)、分层随机抽样(stratified random sampling,SRS)以及条件拉丁超立方采样(conditioned Latin hypercube sampling,cLHS)三种采样策略,发现IHS在获取代表性样点空间位置方面表现最佳。刘雪琦等[23]提出一种基于传统土壤图、依据土壤面积对土壤类型分级,并按照等级之间的比例关系布设训练样点,最后通过案例实践验证了该方法的有效性。样点空间分布格局优化相关研究主要探讨和分析最佳采样点空间位置,或在特定样点数量条件下比较和揭示样点空间分布变化对土壤空间预测精度的影响,而样点数量与空间分布同步变化对土壤预测效果的影响及其机制缺乏深入分析与讨论。
本文以河南省新野县耕地表层土壤有机质含量空间预测为目标,利用简单随机抽样设置十二个分别包含不同样点数量的样点系列,每个系列设置五个样点空间分布,通过比较基于不同样点系列、不同空间分布的土壤有机质空间预测结果的差异,探讨样点数量和空间分布同步变化对土壤属性空间预测效果与数字化制图精度的影响,籍此为县域尺度土壤采样设计相关研究与实践提供参考。
1 材料与方法
1.1 研究区概况
河南省新野县位于南阳盆地南部,地理坐标112°14′44″~112°35′42″E、32°19′30″~32°49′08″N 之间,南北长52 km,东西宽22 km,国土面积为1.06×103km2,其中耕地面积为7.13×104hm2。该县属北亚热带地区,具有明显的大陆性季风气候特征,年平均气温15.1℃,年平均降水量721.0 mm,全年平均日照总时数1 816 h,年平均无霜期228 d。该县地势自西北向东南倾斜,地势平坦,海拔高度为77~108 m。如图1所示,耕作土壤以发育于古河湖相沉积物的湿润雏形土(砂姜黑土)、发育于黄土母质和风化残积母质上的湿润淋溶土(黄褐土)以及发育于近现代河流冲积物上的冲积新成土(潮土)等年轻土壤为主,分别各占耕地面积的 64.7%、19.4%和15.9%。新野县农业历史悠久、农业基础雄厚,是国家现代农业示范区、全国无公害蔬菜生产基地示范县、国家商品粮生产基地县以及优质棉基地县。
1.2 数据来源及处理
研究区土壤样点信息与表层土壤有机质含量数据(采用油浴加热重铬酸钾容量法,按照 NY/T 1121.6-2006 测定)源于2007—2012年新野县实施的测土配方施肥补贴项目,由河南省土壤肥料站提供。对照野外工作原始记录与工作底图上标注的样点空间位置,对所有样点进行逐一核对,将底图标注与野外记录信息不吻合且无法更正的样点删除。对样点表层土壤有机质测定值采用3σ准则识别异常值,即采用样本平均值μ加减三倍标准差σ,在区间(μ-3σ,μ+3σ)以外的数据假定为异常值予以删除[24]。经样点空间位置核准和属性异常值检验后,最终得到研究区有效土壤样点5 403 个(图1)。

图1 新野县土壤类型(a))和土壤样点空间分布图(b)) Fig.1 Soil type(a))and soil sampling site(b))distribution maps of Xinye County,Henan Province
1.3 研究方法
利用ArcMap10.1 软件的Geostatistical Analyst分析工具,分别采用普通Kriging(Ordinary Kriging,OK)和反距离加权(Inverse Distance Weighted,IDW)插值实现研究区表层土壤有机质含量空间预测,并将预测结果输出为30 m×30 m 分辨率的栅格图。鉴于OK 和IDW 方法均为常用的土壤空间预测方法,相关计算原理这里不予赘述。插值过程中,依据样点实际分布情况,根据每一步长内点对数不小于20 对、优先拟合近距离经验半方差值等原则,经过对比筛选确定OK 插值最优参数[25-26];根据最小平均误差标准选择IDW 插值权重计算参数[27-28]。
表层土壤有机质含量空间预测基于不同的样点数量与空间分布进行:(1)首先从研究区5 403 个有效样点中随机抽取403 个样点组成验证数据集。(2)剩余5 000 个样点用作训练数据总集,先从其中随机抽取2 500 个样点作为一个训练数据子集,再从剩余的2 500 个样点中随机抽取1 250 个样点作为一个训练数据子集,按上述方法不重复随机抽样形成分别包含2 500、1 250、625、313、156、78、39、20、10 个样点的9 个训练数据子集;然后再从5 000、2 500 个训练样点中分别随机抽取包含3 750和1 875 个样点的2 个训练数据子集,最终形成分别包含3 750、2 500、1 875、1 250、625、313、156、78、39、20、10 个样点的11 个训练数据子集。(3)重复步骤(2)5 次,获得各训练数据子集的5 个重复,代表包含不同样点数量训练子集的5 种样点空间分布实例,分别以Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ型分布表示。上述抽样过程利用 ArcMap10.1 软件的Geostatistical Analyst Tools/Subset Features 工具实现。
用研究区验证样点表层土壤有机质含量预测值与实测值的相关系数(r)、预测均方根误差(Root mean square error,RMSE)分析和评价基于不同训练样点子集、不同样点空间分布模式获取的研究区土壤有机质含量空间预测效果,其中:

式中,n为研究区验证样点数量(n=403),Yi和Y*i分别为第i个验证样点表层土壤有机质实测值与预测值。
2 结果与讨论
2.1 研究区表层土壤有机质含量统计学特征
基于全部训练数据(5 000 个样点)的表层土壤有机质含量统计结果表明(表1),研究区土壤有机质含量变异系数为22.9%,均值与中值基本一致,偏度和峰度接近0,K-S 检验呈正态分布(P>0.05)。包含不同数量样点的11 个训练数据子集统计结果显示(空间分布Ⅰ型样点统计结果见表1,分布Ⅱ、Ⅲ、Ⅳ、Ⅴ型统计结果略),当训练子集中样点数量自3 750 减少至20 个时,均值、中值、变异系数与全部训练数据的统计结果相比变化不大,说明较少的土壤样点数量即可满足研究区表层土壤有机质含量描述性整体估算的要求,并且K-S 正态性检验的P值均大于0.05,表明各训练子集表层土壤有机质含量呈正态分布。
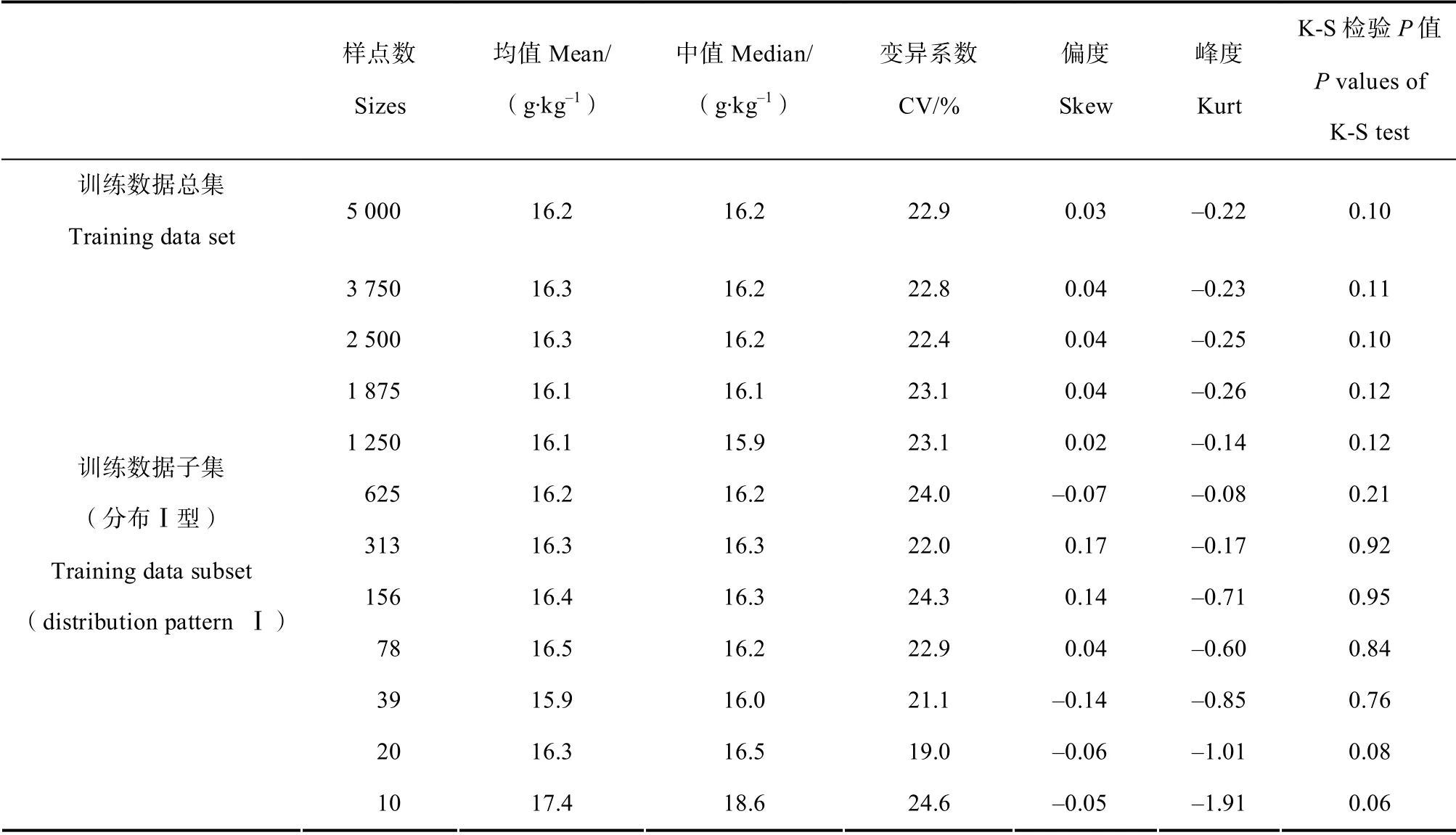
表1 研究区表层土壤有机质含量描述性统计特征 Table1 Descriptive statistics of organic matter contents in topsoil layer
变异函数是地统计学的核心和基本工具,是分析变量空间变异特征的有效手段。在应用OK 插值实施研究区表层土壤有机质含量预测前,对各训练数据样点表层土壤有机质含量实测值分别进行最优变异函数模型拟合(每个训练数据均以样点空间分布Ⅰ型为例,见表2),结果表明,对于包含样点数量较少的训练子集,拟合的变异函数模型参数变化较大,当训练子集的样点数量达到156 个时,表层土壤有机质含量变异函数模型拟合效果较好且更趋稳定,结构性比例为25%~75%,表现出中等程度的空间相关性[29]。
2.2 样点数量和空间分布对研究区表层土壤有机质预测结果空间特征的影响
前文关于训练数据的统计学特征分析表明,研究区表层土壤有机质含量满足地统计学插值的数学条件。以样点空间分布Ⅰ型为例,基于训练数据总集(5 000 个样点)以及不同训练数据子集,应用OK、IDW 插值获得的研究区表层土壤有机质含量空间预测制图结果见图2和图3。首先,基于训练数据总集的预测结果表明,研究区表层土壤有机质含量较高的区域主要分布于县域西北部、西南部、东部和东北部的湿润雏形土区域,有机质含量较低的区域集中分布在白河、湍河以及唐河两岸的冲积新成土和湿润淋溶土地带。其次,由图2、图3可以看出,表层土壤有机质含量预测结果的空间特征随土壤样点数量变化而发生渐进性变化:当样点数量由5 000 减至39 个,表层土壤有机质含量预测值空间分布的局部变异细节信息逐渐减少;进一步减少样点数量至20、10 个,研究区表层土壤有机质含量空间预测信息出现失真畸变,表现出与样点减少前不一样的空间分布格局。基于各训练数据子集空间分布Ⅱ、Ⅲ、Ⅳ、Ⅴ型的预测结果与空间分布Ⅰ型呈类似规律,不再赘述。上述现象表明样点数量对于县域尺度土壤属性空间表征具有重要影响,这与王志刚等[30]、程道全等[31]的研究结果一致。

表2 表层土壤有机质含量变异函数模型 Table2 Variogram model of organic matter contents in topsoil layer
最能凸显研究区表层土壤有机质含量空间分布格局的高、低值区可以视为空间预测与制图表达的“关键区域”,只有当足够的土壤样点分布于这些“关键区域”,才可保证预测制图输出结果在最大程度上反映研究区表层土壤有机质含量实际的空间分布格局。根据基于训练数据总集的OK 和IDW 预测制图结果,划定研究区表层土壤有机质含量制图表达的“关键区域”(图4)。如图4所示,当样点数量为313个时,高值区H1、H2、H3、H4 样点数分别为27、3、12、4 个,低值区L1、L2、L3 样点数分别为33、15、10 个;当样点数量为20 个时,高值区H2 和低值区L3 无样点分布,其余“关键区域”样点数为1或2 个;当样点数量为10 个时,高值区H2、H3 和低值区L1、L3 无样点分布,其余“关键区域”样点数为1 个。在本研究中,当样点数量依次减少为2 500、1 250、625、313、156 甚至更少时,因为能够保证样点在“关键区域”分布,预测制图输出结果仍然能够表达研究区表层土壤有机质含量空间分布的基本格局,尽管空间局部变异细节信息的损失随着样点数量的减少而加剧;当土壤样点数量进一步减少,“关键区域”内样点数量稀少甚至缺失样点时,预测制图输出结果开始出现失真畸变。

图2 基于不同训练子集(样点空间分布Ⅰ型)的表层土壤有机质含量预测制图(OK 插值) Fig.2 Predictive maps of OM content in topsoil layer based on OK interpolation relative to training subset,Type I in sampling stie distribution pattern

图3 基于不同训练子集(样点空间分布Ⅰ型)的表层土壤有机质含量预测制图(IDW 插值) Fig.3 Predictive maps of OM content in topsoil layer based on IDW interpolation relative to training subset,Type I in sampling site distribution pattern

图4 不同训练子集(样点空间分布Ⅰ型)样点在“关键区域”的空间分布 Fig.4 Spatial distribution of sampling sites in the key area relative to training subset,Type I in sampling site distribution pattern
以分别包含2 500、1 250 和78 个样点的3 个训练数据子集为例,分析和讨论子集内土壤样点空间分布对土壤空间预测结果的影响。图5为上述3 个训练子集的不同空间分布类型,图6、图7则为基于上述3 个训练子集的5 种样点随机空间分布类型的研究区表层土壤有机质含量OK、IDW 插值结果。限于篇幅,仅列出Ⅰ、Ⅱ、Ⅲ三种空间分布类型及其插值结果。图5表明,当样点数量为2 500 和1 250个时,同一训练子集的不同空间分布类型在“关键区域”有较多样点;当样点数量为78 个时,分布Ⅰ、Ⅲ型在“关键区域”存在样点,但是分布Ⅱ型在西南部的高值区H4 无样点分布。对比基于同一训练子集不同样点空间分布的制图结果(图6、图7)可 以发现,当训练子集中土壤样点数量足够多时(如2 500、1 250 个),样点空间分布的差异不会导致预测制图输出结果的明显差异;而当训练子集中样点数量减少到一定程度时(如78 个),则样点空间分布的不同可导致制图结果的明显差异。这是因为当训练样点足够多时,随机抽样形成的不同样点空间分布均可确保“关键区域”有样点存在;当训练样点数量较少时,不同样点空间分布能否确保“关键区域”有样点存在就成了一种概率事件,换言之,基于相同样点数量而不同样点空间分布的土壤预测制图结果可能会出现明显差异。Yang 等[22]在样点数量相同的条件下通过综合等级逐步采样、分层随机抽样和条件拉丁超立方采样三种方法确定样点空间位置,通过对比沙粒含量和土系的预测制图精度发现基于综合等级逐步采样确定的样点分布制图精度优于其他两种方法,证实了在相同样点数量条件下样点空间分布对土壤预测制图精度的影响,这与本研究结果一致。确保在预测变量“关键区域”内布设足够数量的样点,是提高土壤采样代表性和土壤空间预测精度的重要策略和手段之一[32-33]。
2.3 样点数量和空间分布对研究区表层土壤有机质含量预测精度的影响
图8显示了土壤样点数量及其空间分布对表层土壤有机质含量空间预测精度参数的影响。在应用OK 插值实施预测制图过程中,当训练子集的样点数量分别为5 000、3 750、2 500、1 875 和1 250 个时,研究区验证样点表层土壤有机质含量实测值与预测值之间相关系数r变幅在0.55~0.59 之间、预测均方根误差RMSE 变幅在3.03~3.15 之间,表现平稳,且各训练子集样点空间分布的变化也未引起预测精度的明显差异。从训练子集样点数量减少至625个开始,预测制图的精度随样点数量下降而明显降低,即r明显减小、RMSE 显著增大;样点分布对预测精度的影响开始凸显,表现为基于同一训练子集不同样点空间分布的预测精度呈现出明显差异;随着样点数量的减少,样点空间分布对预测精度的影响作用可能超过样点数量,如包含156 个样点的分布Ⅴ型预测精度高于包含 313 个样点的分布Ⅳ型。李凯等[34]研究采样数量对土壤Cd 污染指数预测精度的影响时得出,基于2 033、1 830、1 423 和1 017 个样点的污染指数预测精度变化很小,当样点数量减少至610 和203 个时预测精度大幅下降,此结果与本研究得出的样点数量对土壤有机质预测精度的影响规律一致。范曼曼等[35]在探讨采样密度对土壤有机质空间预测精度的影响时发现,r和RMSE分别随样点数减少而逐渐减小和增大,但是当样点 数进一步降至707 时r开始增大,RMSE 开始减小;齐雁冰等[36]在研究采样数量与县域土壤有机质OK插值精度的关系时也得出类似结果。从本研究结果来看,出现上述现象的原因可能是当样点数量下降到一定程度之后,样点空间分布对预测精度的影响作用逐渐凸显,并超过了样点数量对预测精度的影响。

图5 包含2 500(上)、1 250(中)和78(下)个样点的训练子集不同空间分布示例 Fig.5 Examples of sampling site distribution pattern relative to training subset and sample size(2 500(top),1 250(middle)and 78(bottom)

图6 基于不同样点空间分布的表层土壤有机质含量预测制图(OK 插值)(上:1 250 个样点,下:78 个样点) Fig.6 Predictive maps of OM content in topsoil layers based on OK interpolation relative to sampling site spatial distribution pattern and sample size(top:1 250 samples and,bottom:78 samples)

图7 基于不同样点空间分布的表层土壤有机质含量预测制图(IDW 插值)(上:2 500 个样点,下:78 个样点) Fig.7 Predictive maps of OM content in topsoil layers based on IDW interpolation relative to sampling site spatial distribution pattern and sample size(top:2 500 samples and,bottom:78 samples)
使用IDW 插值技术预测研究区表层土壤有机质含量时,预测结果的精度随样点数量与空间分布的变化表现出与OK 插值大致相同的趋势。不同的是,IDW 插值精度在5 000、3 750、2 500 个样点时表现平稳,r变幅在0.49~0.50 之间、RMSE 变幅在3.31~3.35 之间;从训练子集样点数量减少至1 875个开始,IDW 插值输出结果的精度便随样点数量的减少出现明显下降,且基于同一训练子集不同样点分布的预测结果之间的精度差异大于OK 插值,表明随着样点数量的减少IDW 插值精度较OK 插值更早响应样点数量和空间分布的变化,并且对于空间分布的变化更为敏感;对比IDW 和OK 的平均制图 精度,在制图结果发生失真畸变之前(样点数量大于20 个),OK 平均插值精度及其整体变幅大于IDW。陈昌华等[37]对不同空间插值方法精度的比较分析表明,与OK 相比,IDW 插值精度较低且更快对样本数量的变化做出响应,这与本研究结果基本一致。导致上述差异的根本原因,在于IDW 和OK插值技术工作原理的不同:IDW 属于确定性插值方法,以研究区待测点与训练样点的空间距离确定权重进行加权平均计算,训练样点的数量和空间分布对权重的大小具有决定性作用;OK 则属于地统计插值方法,基于训练样点的土壤属性结构信息(通过变异函数表征)进行无偏最优估计,该方法除了训练样点空间位置信息外还有效利用了训练样点属性值的空间相关性,与IDW 方法相比,土壤属性结构性越强,训练样点的数量和空间分布对预测结果的影响就越弱[38]。

图8 土壤样点数量和空间分布对表层土壤有机质含量预测精度的影响 Fig.8 Influence of sample size and sampling site spatial distribution pattern on accuracy of the prediction of OM contents in topsoil layers
3 结 论
在县域尺度上,土壤样点数量和样点空间分布均会对研究区基于OK 和IDW 插值技术的土壤空间预测结果产生重要影响,这些影响可通过预测制图结果的空间特征以及预测精度参数的变化进行分析与评估。当样点数量足够多时,研究区样点数量和空间分布对OK 和IDW 插值预测制图和预测精度的影响非常有限;当样点数量减少到一定程度时,随着样点数量的减少,预测制图结果的空间局部变异细节信息逐渐减少,预测精度逐渐下降,同时样点空间分布对预测结果的影响不断增强,甚至可能取代样点数量成为预测结果的决定性因素。由于工作原理的不同,在空间预测结果发生失真畸变之前,与OK 相比,IDW 插值精度较低且更早响应样点数量和空间分布的变化。
