基于机器学习的侵财类案件危害程度分析*
2020-01-13卢子涵胡啸峰邱凌峰
卢子涵,胡啸峰,邱凌峰
( 1.中国人民公安大学 信息技术与网络安全学院,北京 102623;2.安全防范技术与风险评估公安部重点实验室,北京 102623;3.上海云从企业发展有限公司 中台产品中心-公共事业组,上海200120)
0 引言
我国正处在经济发展和社会转型的关键时期,侵财类案件数量居高不下,实际破案率却低于15%[1],严重威胁着公民的财产安全,对社会稳定有一定程度影响。随着命案数量的逐年降低,人民群众转而对公安机关针对侵财类刑事案件的打击工作提出了更高的要求。侵财类案件的预测、预警、预防、打击是立体化治安防控体系中的重要环节。
在国内外相关研究中,文献[2]提出了一种基于自回归模型和空间分析的预测方法,可以预测犯罪趋势并检测城市的高风险犯罪区域;文献[3]基于人工神经网络模型对抢劫犯罪的种类进行预测分析;文献[4]建立了犯罪预测模型,可以预测特定时空节点的特殊人群容易遭受的犯罪类型;文献[5]利用改进的BP神经网络模型自动学习、训练各因子与侵财类犯罪的非线性关系,建立了侵财类犯罪预测模型;文献[6]提出一种基于随机森林的改进分类算法,利用案件中犯罪人员的特征,预测重点人员的犯罪倾向;文献[7]提出一种基于Bagging和特征选择差异性的集成学习算法,进行犯罪预测;文献[8]针对雄安新区的治安防控需求,提出了基于机器学习的社会安全事件预测分析方法;文献[9-11]探究了热应力与暴力犯罪案件、侵财类案件之间的相关关系,研究了热应力与犯罪率的关系。
犯罪风险通常包括犯罪发生概率和后果2个部分,对侵财类案件的风险防控及预防打击需要首先对该类案件的发生概率和后果进行预测分析,然而当前大部分研究主要关注对犯罪发生概率的预测,对犯罪后果或危害程度的预测研究则较少。对犯罪危害程度的预测研究能帮助公安机关预测判断某个时空节点的侵财类案件危害程度,合理有效地配置警力资源、划分治安巡逻范围,及时制止危害性极大的犯罪发生。本文利用实际数据,综合运用多种机器学习方法,对以盗窃、抢劫及抢夺为代表的侵财类案件的危害程度进行预测,从而为针对性地开展预防与管控工作、优化警力资源配置提供支持。
1 数据及研究方法
1.1 数据集与研究方案概述
本文所选取的数据来源于ZS市2008—2014年的实际侵财类案件。ZS市位于我国南部平原地带,交通便利,人口众多,气候适宜居住,对我国南部同等规模的大型城市具有一定程度的代表性。
数据集共包含111 579条犯罪案件数据,经过初步提取后,共得到盗窃案件数据32 560条、抢夺案件数据3 218条、抢劫案件数据2 140条。其中每条数据均包含详细的犯罪信息和案件的危害程度分级。
提取的特征经过计算Pearson相关系数、去除取值变化较小的特征等操作后,最后选取的特征包括“发案时间”“发案地域”“选择时机”“选择处所”“选择对象”,以及ZS市统计局提供的2008—2014年“人均地区生产总值”“职工月平均工资”。
“发案时间”指的是案件发生的具体时间,如“2010-10-14 20∶00”;“发案地域”指的是案件发生的地址,如“某省某市某区SJ街道107国道旁某邮政局门口”;“选择时机”指的是案件发生的时间为工作日还是假期,如“工作日,上旬,昼,上午”;“选择处所”指的是案件发生的地点属于什么样的地段,如“其他繁华地段”;“选择对象”指的是受害人的基本属性,如“外地人,中年男子”;“人均地区生产总值”指的是按照街道划分地域的每人每月的平均生产总值;“职工月平均工资”指的是按街道划分地域的每人每月的平均工资。
案件的危害程度作为标签分为:一般、重大和特大3级。综合危害程度的级别由原始数据集提供(在原始数据生成时,相关司法人员结合专业的法律知识,综合案件的财产损失、造成的影响等要素进行判断)。
研究方案如图1所示。首先进行提取关键字、处理时间特征等数据处理工作,其次将数据集按照一定的比例随机分为训练集和测试集,运用多种机器学习方法对训练集进行分类计算和交叉验证,然后用测试集进行准确性检验、提出最优模式,最后使用Apriori算法挖掘关联规则。
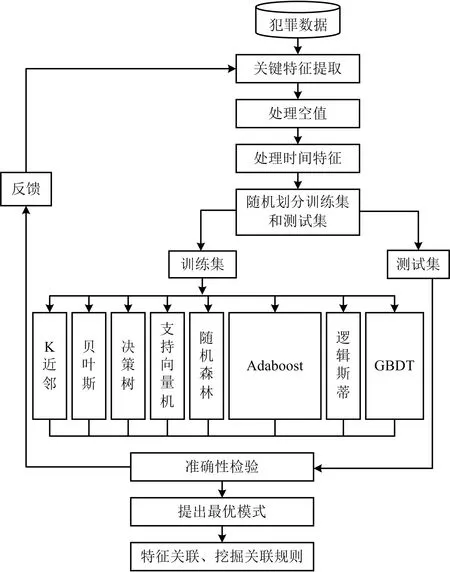
图1 研究方案Fig.1 Research scheme
1.2 数据预处理
将“发案时间”“选择时机”“选择处所”“选择对象”转换为整型数据,从“选择地域”中提取关键字并转换为整型数据,将“一般”“重大”“特大”3种危害程度等级分别标记为0,1,2。最终的数据样式如表1所示。
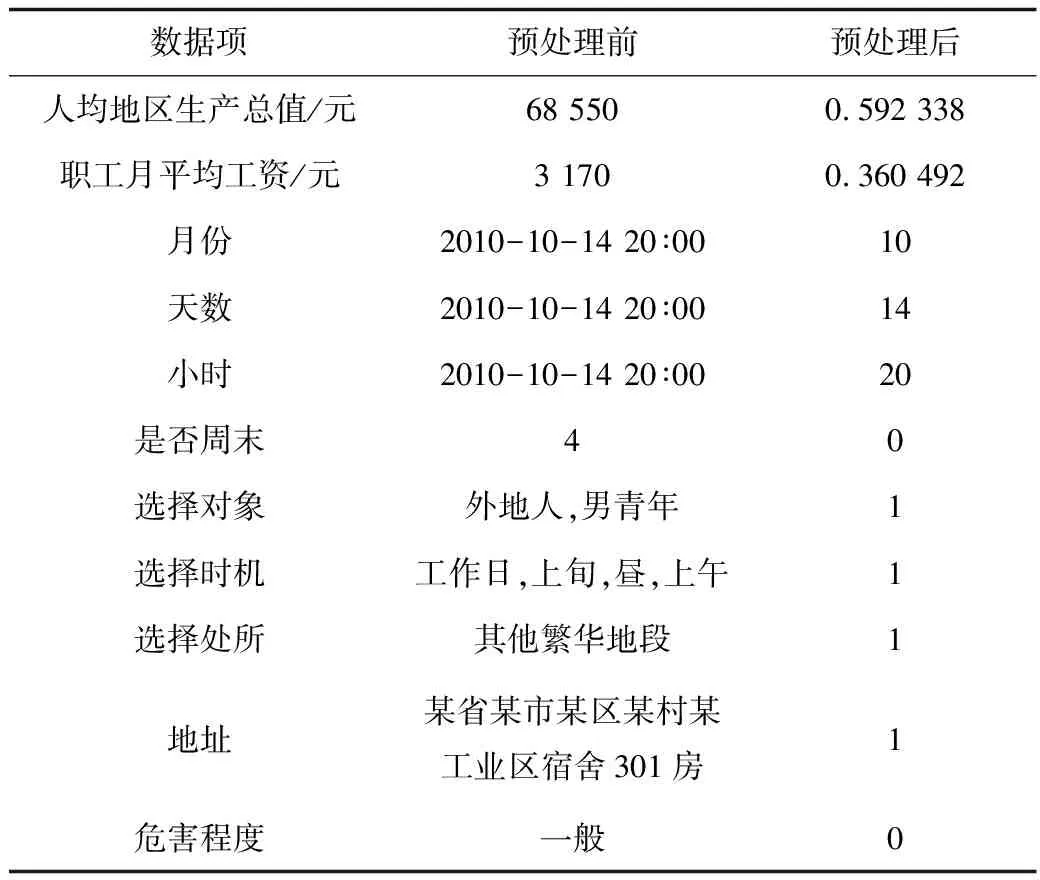
表1 数据样式Table 1 Data pattern
1.2.1 关键特征提取
如表2所示,通过关键字提取4个特征。

表2 特征提取Table 2 Features extraction
1)案发的地点在“发案详细地址”中通过关键字提取得到。原始分类中地址种类包含上万种,种类过多影响分类的精度。本文将发案地址按照街道划分为7类。
2)罪犯选择的犯罪时机可以在“选择时机”中通过关键字提取得到。原始数据包含的部分特征例如“上旬”“昼”“上午”等,可以通过“发案时间”中提取到的“月份”“小时”体现出来。所以本文只提取其中的相应字段作为特征,从而判定是否是工作日。
3)侵财类案件发生的处所可以在“选择处所”中通过关键字提取得到。原始数据中的处所包含486种类型,根据实际业务工作经验以及对数据数量的统计,本文对数量最多的前5种地名进行提取,其中包含“繁华、偏僻、公路、其他处所、住宅”。
4)“性别”和“是否是本地人”可以在“选择对象”特征中通过关键字提取得到。经过统计,“选择对象”特征中有235种类型。“选择对象”的原始数据样式如“外地人,中年男子”。本文根据数据特点,从中提取出“性别”和“是否是本地人”2个特征。“性别”中包括“男”和“女”,“是否是本地人”中包括“外地人”和“非外地人”。
1.2.2 处理空值
由于部分数据中并不存在要提取的关键字信息,数据集中出现了大量的空值。统计发现,“选择时机”中的“工作日”,“选择处所”中的“其他处所”,“选择对象”中的“其他”占据了此类数据中的大部分。这些占比较大的数据是大概率出现的情况,所以将各个特征中数量最多的作为填充数据,即将“选择时机”中的空值填充为“工作日”,将“选择处所”中的空值填充为“其他处所”,将“选择对象”中的空值填充为“其他”。
另外由于统计局提供数据的缺失,在“人均地区生产总值”“职工月平均工资”2个特征中均出现了不同程度的空值。本文由于数据量较大,因此采用欠采样的方式处理“人均地区生产总值”“职工月平均工资”中的空值。
1.2.3 处理时间特征
原始数据中的时间格式按照“2010-10-14 20∶00”形式存储,种类达到了上万种,采用原始分类会导致分类器的分类精度严重下降。在真实的案件中,往往受害人在受到侵害后很难准确地将受害时间叙述出来,所以本文进行了时间的分割、统计及分段。在统计的过程中,发现每个月除31号外,每日发生的案件数量接近,根据业务工作经验,将每天时间划分为6个阶段:1)0点至4点标为“1”;2)5点至6点标为“2”;3)7点至11点标为“3”;4)12点至13点标为“4”;5)14点至17点标为“5”;6)18点至24点标为“6”。
1.2.4 处理数据共线性问题
通过相关性系数的热图分析,发现特征之间存在不同程度的共线性问题。共线性对各个机器学习结果均有不同程度的影响。本文采用主成分分析法(Principal Component Analysis,PCA)消除共线性的影响。
PCA是一种实现数据降维的技术[12],能处理变量间的共线问题。其核心思想是通过旋转坐标将数据投影到新的坐标轴上,使数据方差最大化,得到在新空间表示的数据。这些新得到的数据可以消除原数据空间的多重共线性[13]。
由于特征变量经过关键特征提取和时间特征提取后出现了新的特征,并且在上述热图分析中出现共线现象,所以本文将上述处理后的数据进行降维处理。降维处理的结果作为新的特征列。对这些新的特征列进行相关性系数的热图分析,确保消除共线性,提高预测精度。
1.2.5 数据不平衡处理
经数据统计发现,在3类侵财类案件中,盗窃类案件和抢夺类案件的数据存在数据不平衡现象,即危害程度为一般的案件数量远多于危害程度为重大和特大的案件数量。不平衡的数据集会影响分类器的性能[14],因此,本文利用SMOTEENN算法对抢夺案、盗窃案样本进行采样处理。
SMOTEENN算法是SMOTE算法和ENN算法的集成算法。SMOTE合成少数过采样技术[15],是一种过采样方法,其主要思想是通过插值形成新的少数类例子[16]。ENN算法[16]主要思想是删除不满足标准的相邻数据。
经过SMOTEENN算法处理后,不平衡数据的现象得到解决。
1.3 特征规则关联
数据集中频繁出现的数据称为频繁数据集[17]。频繁数据集之间联系构成的规则能体现特征之间某些关联性。
为挖掘侵财类案件特征属性之间的关联性,掌握案件的发生规律,本文利用Apriori算法进行关联规则分析。Apriori算法是一种挖掘关联规则频繁项集的算法,其实质是一个逐层迭代搜索的方法,利用K项集探索K+1项集[18]。
2 结果分析
2.1 不同机器学习方法上的分类性能比较
本文在构建预测分类模型时所使用的训练集是从全部数据集中随机抽取的数据集(占比70%),采用准确率和F1-macro值对模型的性能进行评估。准确率越高、F1-macro值越高,说明模型的泛化能力越好。如式(1)~(4)所示。预测结果如图2所示。
Accuracy=(TP+TN)/(TP+FN+FP+TN)
(1)
Precision=TP/(TP+FP)
(2)
Recall=TP/(TP+FN)
(3)
(4)
式中:n表示多标签分类任务中类的数量;TP表示被正确分类的正样本数;FP表示被错误分类的负样本数;FN表示被错误分类的正样本数;TN表示被正确分类的负样本数。F1-macro是分别计算每个类别的F1,然后做平均(各类别F1的权重相同)。利用python3.6中的Scikit-learn开源机器学习模型库建立模型。
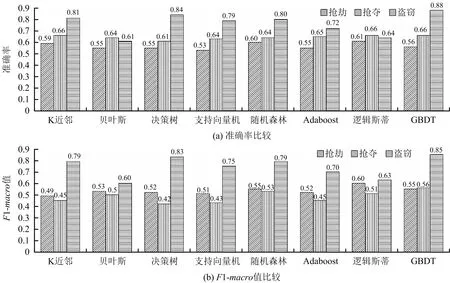
图2 模型评估结果Fig.2 Evaluation results of model
由图2可知,在3种案例中,抢劫案利用逻辑斯蒂算法预测的准确率最高达到0.61,F1-macro的值为0.6;抢夺案利用GBDT算法预测的准确率最高达到0.66,F1-macro的值为0.56;盗窃案利用GBDT算法预测的准确率最高达到0.88,F1-macro的值为0.85。由此可知,盗窃案的预测精度明显高于抢劫案和抢夺案的预测精度。本文分析出现此类情况的原因与抢劫案和抢夺案样本不平衡且发案不规律有关。
表3所示为特征重要度排序。通过重要度排序,可以发现3种案件类型的“发案时间”和“选择处所”特征重要度之和均超过70%,即在对侵财类案件的预测过程中,时空因素对预测结果的影响占比较大。
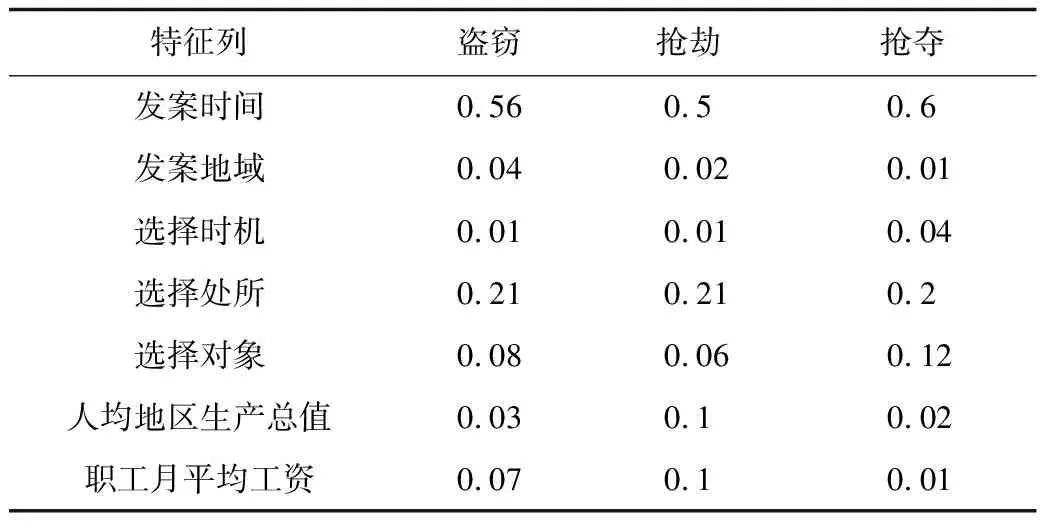
表3 特征重要度排序Table 3 Ranking of features' importance
因此,为探究抢劫案和抢夺案的样本及发生规律,本文将处理完成的数据进行时空统计分析。图3为抢劫、抢夺发生时空规律统计。
由图3可知,危害程度为一般的抢劫案在2008—2011年间的发案量有上升趋势,在2011年之后发案量大幅度下降,其中在2009年之后的抢劫案更容易发生在繁华地带(商业区等);危害程度为重大的抢劫案在2008年至2011年间趋于稳定,在2011年之后发案量大幅度下降,其中在2011年繁华地带的发案量已经远远超出其他处所(除住宅地、偏僻地区、公路地区和繁华地带的零散区域)的发案量;危害程度为特大的抢劫案数量在2009年发案量达到最大值,之后便大幅度下降,其中危害程度特大的抢劫案几乎都发生在其他处所(除住宅地、偏僻地区、公路地区和繁华地带的零散区域)。危害程度为一般的抢夺案数量在2012年之前呈波动状态,2012年之后发案数量大幅度下降,其中在2010年之前案件大多发生在其他处所(除住宅地、偏僻地区、公路地区和繁华地带的零散区域),2010年之后案件大多发生在繁华的地带(商业区等);危害程度为重大的抢夺案数量在2010年开始大幅度下降,由原本大多发生在其他处所(除住宅地、偏僻地区、公路地区和繁华地带的零散区域)转变为大多发生在繁华地带(商业区等);危害程度为特大的抢夺案数量在2010年开始大幅度下降。本文推测,2010年和2011年案件数量下降的原因可能与ZS市在2011年举办了大运会有关,相关的活动促使警方推出了一系列“群防群治”、“平安大运”的有关打击犯罪政策;犯罪人选择犯罪地域由零散的其他处所变为繁华地带表明犯罪人更加青睐高犯罪所得,符合理性选择理论。抢劫案和抢夺案的发案量都是“由低到高、再到低”的过程,发案率逐年下降[19],尤其是2013—2014年2种案件的总体数量保持较低的水平,危害程度为重大和特大的案件几乎没有,使得样本数据在时间维度上不平衡。同时,犯罪人员在2010年前后犯罪地域的选择上的变化使得样本在空间维度上没有规律性。因此,近几年来“两抢”案件的低发以及2011年前后的发案规律变化较大正是分类结果不完全准确的原因。

图3 抢劫、抢夺发生时空规律统计Fig.3 Statistics on incidence temporal and spatial laws of robbery and forcible seizure
2.2 关联规则分析
犯罪案件的各个特征属性之间存在一定的关联性。通过对关联规则进行分析,不仅能掌握犯罪分子实施侵财类犯罪的选择偏好,对预测结果作出解释,而且能在一定程度弥补上文抢劫、抢夺类案件预测准确度相对偏低的缺陷,探究案件特征和危害程度之间的关系。
分析得到的关联规则如表4所示,由表4可知:1)抢劫案发生时,在工作日中城区发生案件的置信度为0.91;在城区中发生危害程度为一般的案件的置信度为0.7。2)抢夺案发生时,在工作日的城区中发生案件的置信度为0.95;在工作日中发生危害程度为一般的案件的置信度为0.7;在工作日的城区中发生危害程度为一般的案件置信度为0.8。3)盗窃案发生时,在工作日的城区中发生危害程度为一般的案件置信度为0.8;在工作日的城区中发生案件的置信度为0.9。

表4 关联规则结果Table 4 Results of association rules
通过分析可知,3种不同的侵财类案件特征属性之间的关联特点基本相同,3种侵财类案件的犯罪时间基本都为工作日期间,犯罪地点基本选择在城区当中,并且发生案件的危害程度大多数为一般。在工作日中,住宅中缺少居住人监管并且在公共场所中上下班时间节点人流量巨大,给犯罪人员带来了犯罪的契机,促使犯罪人员进行犯罪活动。在城区中,犯罪人员能获得更高的犯罪利益所得。由此可见,侵财类犯罪在宏观的时空上具有一定的共性。
3 结论
1)针对近年来侵财类案件发案数量多、频次高、破案率低、危害程度差异大、消耗警力资源严重的现状,本文利用ZS市2008—2014年实际抢劫、抢夺和盗窃的数据,提出基于多种机器学习模型的分类预测方法,提高对盗窃案件危害程度的预测准确率。提供针对侵财类案件的规律挖掘框架,为自动挖掘侵财类案件的发生规律及实现警务资源的合理配置提供方法支持,提高出警效率。
2)根据数据挖掘的结果,抢劫案和抢夺案的发案量都是由低到高再到低的过程,发案率逐年下降。在抢劫案和抢夺案中,危害程度为一般和重大的案件高发地由其他处所(除住宅地、偏僻地区、公路地区和繁华地带的零散区域)转移到繁华地带(商业区等),危害程度为特大的案件高发地为其他处所(除住宅地、偏僻地区、公路地区和繁华地带的零散区域)。侵财类案件更倾向于在工作日的城区中发生,发生的危害程度大都为一般。以上结论可以为针对“两抢一盗”案件的安全防范提供策略支持。
