基于自编码器的文章侧面信息提取技术研究
2019-12-26杨泽华毛月月
杨泽华 毛月月


摘 要:通过结合Word2Vec模型、TF-IDF算法和自编码器模型,提出了一种从纯文本文章中提取侧面信息算法(WT-AutoEncoder)。首先,爬取相关语料,对文章进行分词、去停用词等数据预处理,对词进行向量化表示;然后,利用TF-IDF算法对得到的词向量做关键词提取;最后,将得到的关键词应用到自编码器模型中,通过权重排序后,获取最终的关键词,即代表文章侧面信息。结果表明,应用TF-IDF算法和自编码器模型后,可以获得到较为准确的信息提取结果。
关键词:Word2Vec模型 TF-IDF算法 自编码器模型 文本信息提取
Abstract:By combining TF-IDF algorithm and AutoEncoder model, a method of extracting side information from plain text articles is proposed. Firstly, the relevant corpus is crawled, and the data such as word segmentation and word deactivation are preprocessed, and the words are vectorized; secondly, the keywords are extracted by TF-IDF algorithm; finally, the keywords are applied to the AutoEncoder model, and the final keywords are obtained by weight ranking. That is to say, it represents the side information of the article. The results show that more accurate information extraction results can be obtained by using TF-IDF algorithm and AutoEncoder model.
Keywords:Word2Vec model TF-IDF algorithm AutoEncoder model Text Information Extraction
中图分类号:TP391 文献标识码:A 文章编号:1003-9082 (2019)12-000-02
一、引言
随着互联网的出现和大量可用的文本数据,当前的挑战是开发新的工具,以简洁的形式表示内容。自动文本摘要是自然语言处理的一个重要研究方向,它主要是以压缩的方式表达长文档,以方便能够快速地理解和读取信息。近几年,基于深度学习的方法在许多自然语言处理任务中都具有令人印象深刻的准确性,例如在问答、情感分析、文本分类、机器翻译等领域。为了输入数据的效果良好以及语义上更有意义的表示,深度学习需要大量的训练数据。大多数基于深度学习的方法,例如卷积神经网络(RNN),循环神经网络(RNN)的等都是需要标记数据来训练参数的深度网络构架。
目前将有监督学习的深度学习方法应用于提取文本摘要的最大挑战是需要人工创建大规模的标签。本文通过利用不需要标记数据进行训练的技术来解决这个缺点,尤其是基于词嵌入(Word2Vec)和自编码器(AutoEncoder)的深度学习方法。
本文其余部分安排如下:第二节介绍相关理论研究。第三节详细介绍模型的流程。第四节是对实验的数据及结果展示分析。最后,第五节总结全文所做的工作和主要贡献,并提出一些在未来扩展的想法。
二、相关研究
目前,国内外研究者在文本信息抽取方面有多种研究方法。文献[1] 通过结合Doc2Vec模型、K-means算法和TextRank算法,提出一种文本摘要提取算法(DK-TextRank)。文献[2]利用文本主题上下围概念的提取和不同权值的度量方式相结合的方式,提出了主体局的提取方法。文献[3] 根据句子时间信息得到的时序权重,使得时间较近的新闻内容具有更高的权重,提出一种基于查询的文本摘要技术。文献[4] 提出一种用于单个文档的通用抽取文本摘要的新方法SummCoder,该方法根据句子内容相关性、句子新颖性和句子位置相关性这三个学习指标生成摘要。文献[5] 提出了一种自动、通用、抽取的阿拉伯文单文档汇总方法,该方法旨在生成信息丰富的摘要。
在自编码器方面,文献[6] 提出了一种门控联合池化的自编码器模型,用于学习中英文的文本语义特征。在编码阶段,提出了均值-最大化联合表征策略来捕捉输入文本中多样性的语义信息。文献[7] 首先经稀疏自编码器降维,然后通过LDA主题聚类算法进行文本聚类,提高聚类准确性来提取文本特征。
三、模型介绍
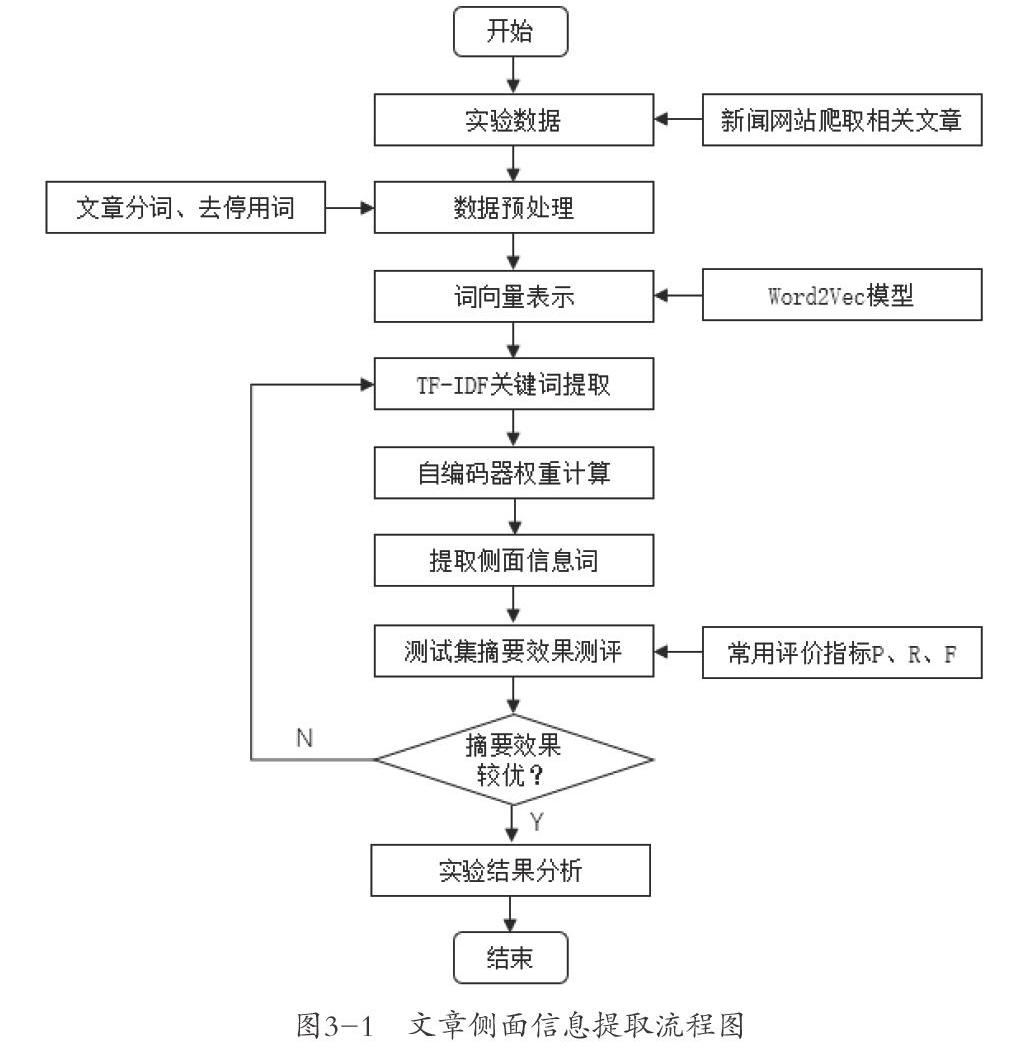
对于一篇纯文本文章,在进行文章分词、去停用词等一系列数据预处理过程之后,首先对文本进行基于Word2Vec模型的词向量表示;然后利用TF-IDF算法,做关键词提取工作;最后将提取到的關键词通过自编码器模型训练得到权重值较大的词语作为最终的侧面信息词。如果对结果不满意,可以调整自编码器模型参数来调试结果,知道效果较优为止。
具体流程如图3-1所示:
1.基于Word2Vec模型的词向量化
为了提高信息提取的准确性,本文采用能更好表达词语间关系的Word2vec模型来对文本中的词语进行向量化表示。Word2Vec模型可以将文本表征为数字化向量。 该模型参考了神经网络语言模型,构建多层神经网络,以极大似然作为目标函数简历模型,将每个词语映射成数字化向量。经过大量训练,可以获得高精度的词向量表示,成为NLP在语义相似度计算中的重大突破。
Word2Vec模型主要包括两种算法,CBOW和Skip-gram。其中,CBOW是指用上下文预测当前词,而Skip-gram使用当前词来预测上下文词的思路。结合本文的问题,这里采用CBOW。
2.基于TF-IDF算法的文章关键词提取
TF-IDF(Term Frequency-Inverse DocumentFrequency, 词频-逆文件频率)是一种评估一个词语对一篇文档的重要程度。詞语的重要程度与她在文档中出现的次数成正比,但与他在所有文档中出现的频率成反比。所以,TF-IDF常被应用于搜索引擎中,作为评价用户查询的相关程度的度量。
词频(TF)是指某个词在文档中的出现次数。逆文档频率(IDF)则是指一个词语普遍重要性的度量。TF-IDf则是词频与逆文档频率的乘积。
其中,分母加1是为了避免所有文档都不存在该词时,分母为零的情况
3.基于自编码器的文章侧面信息提取
自编码器(AutoEncoder)是一种采用无监督学习方式的神经网络模型。它可以有效地对高维数据进行特征提取和表示。
AutoEncoder的目的是尝试将输入向量压缩再还原,使得输出向量尽量还原成为输入向量,训练过后,得到的中间层向量可以作为输入的向量表示。因此,它可以看作两部分组成,一个编码器函数和一个生成重构的解码器函数。编码器部分的功能是将输入压缩成为潜在空间表征,而解码器部分则用来重构来自潜在空间表征的输入。整个自编码器可以用来描述,其中输入r与原始输入x接近
如上图2-1所示,这是AutoEncoder的一个基本结构。如果AutoEncoder的唯一目的是让输入值等于输出值,那么将没有任何作用。我们希望通过训练输入值等于输出值的自编码器,让潜在表征h更具代表性。
一般地,我们并不关心自编码器的输出,而是关注通过自编码器后可以得到隐藏层的潜在表征h。AutoEncoder模型的输入层和输出层的维度必须相等,才可以进行无监督训练。并且,隐藏层的维度一般要小于输入层,这样才能实现数据的压缩,从而提取出主要特征。
一个神经网络模型,一定要有一个输入、输出和损失函数。AutoEncoder的输入值与输出值相同。换个角度理解,自编码器就是一个标签就是输入本身的有监督学习。而损失函数L可以是交叉熵、均方差等,表示输入值与输出值之间的误差。
自编码器的主要用途在数据降噪和降维两个方面。数据降噪是通过输入得到更加准确的输出,从而达到去噪的效果;降维是通过训练,得到中间的低维度的隐藏层,达到降维的效果。而本文对于自编码器的用途不同于以上两点,主要是通过训练得到输入层与隐藏层之间的权值,然后对权值排序,获得权值较大的词语作为最终需要提取的文章侧面信息词。
四、实验结果与分析
实验环境:处理器:Intel(R)Core(TM)i5-6500 CPU @ 3.20GHz(4处理器),内存(RAM):8.00GB,系统:64位Windows操作系统,编程环境:Python/Pycharm。
1.实验过程
实验过程具体如下:
1)数据采集。本文爬取新华网、凤凰新闻网、网易新闻网等新闻文章,涉及文化、教育、体育、经济、社会等多个方面,共5000篇。
2)数据预处理。通过正则表达式去除一些特殊字符,然后使用jieba分词工具进行分词,最后再去掉停用词。
3)词向量化。输入4000篇文章,用于训练Word2Vec模型。向量维度设定为200维,得到可以表征语义的词向量集合T,文章可以表示为向量化后的词语所组成的矩阵。
4)关键词提取。使用TF-IDF算法对得到的词向量计算每个词语的重要程度。
5)自编码器权值计算。训练模型后,保存编码器的权值作为排序的依据。
6)文章侧面信息输出。
2.结果分析
通常采用内部评价方法评价自动摘要的提取效果,即与人工撰写的摘要进行比较评价文摘质量。本文实验采用F值衡量自编码器训练效果,F值越高,说明模型效果越好。
五、结论与展望
本文通过对文章的预处理得到有效数据,在使用Word2Vec模型生成词向量的基础上,应用自编码器模型进行训练,并通过训练后的模型得出输入层的权值,通过排序提取最终的关键词。利用新闻报道文章进行文章侧面信息提取实验,结果表明相对于传统TF-IDF算法本文提出的WT-Autoencoder算法能有效的提高提取信息的质量。下一步将对WT-Autoencoder模型进一步训练,从而提升算法效率。
参考文献
[1]徐馨韬,柴小丽,谢彬,等.基于改进TextRank算法的中文文本摘要提取[J].计算机工程,2019,45(3):273-277.
[2]张云涛,龚玲,王永成.基于综合方法的文本主题句的自动抽取[J].上海交通大学学报,2006(5):771-774,782.
[3]王凯祥,任明.基于查询的新闻多文档自动摘要技术研究[J].中文信息学报,2019,33(4):93-100.
[4]Akanksha Joshi,E.Fidalgo,E.Alegre,Laura Fernández-Robles.SummCoder: An unsupervised framework for extractive text summarization based on deep auto-encoders[J].Expert Systems With Applications,2019,129.
[5]Aziz Qaroush,Ibrahim Abu Farha,Wasel Ghanem,Mahdi Washaha,Eman Maali.An efficient single document Arabic text summarization using a combination of statistical and semantic features[J].Journal of King Saud University - Computer and Information Sciences,2019.
[6]张明华,吴云芳,李伟康,等.基于门控联合池化自编码器的通用性文本表征[J].中文信息学报,2019,33(3):25-32.
[7]黄炜,黄建桥,李岳峰.一种基于稀疏自编码器的涉恐短文本特征提取方法[J].情报杂志,2019,38(3):203-207,186.
