基于特征关联的服装图像特征描述研究∗
2019-11-29谢玉玲
龚 安 谢玉玲
(中国石油大学(华东)计算机与通信工程学院 青岛 266580)
1 引言
据中国电子商务研究中心给出的数据显示,仅2017 上半年中国电子商务交易额就达13.35 万亿元[1];服饰类商品在整个网络购物市场中交易最多,截止2015 年,我国服装网购市场交易规模达7457亿元[2]。而图像作为商品的信息载体,规模和数量也随之呈现高速发展的态势。服装图像描述是直接输入服装图片,自动生成对服装图像的自然语言描述。
近年来,图像描述生成技术无论是流程化方法还是端到端的方法都取得了迅猛发展,大都基于深度卷积神经网络和循环神经网络的结合。微软Fang 等[3]利用多实例学习(Multiple Instance Learning,MIL)的弱监督方法,训练视觉检测器来提取一副图像中由卷积神经网络(Convolutional Neural Networks,CNN)获取的特征单词,然后学习一个统计 模 型 用 于 生 成 描 述。Kiros 等[4]利 用CNN 和LSTM 对图片进行编码,再利用提出的方法SC-NLM(Structure-Content Nearal Language Model)预测句子结构进行解码。受机器翻译的启发谷歌Vinyals 等[5]设计了一个从编码到解码的图像描述生成器,实现这个系统模型的是DCNN 和RNN 的结合。Karpathy 等[6]通过多通道嵌入设计image-sentence embedding 模型能够将句子描述内容片段和图片局部区域对应起来,然后引入BRNN(Bidirectional Recurrent Neural Network)架构来生成图片描述。同样在2015年的CVPR会议上Donahue 等[7]实现一个端到端的图像LRCNs(Long-term Recurrent Convolutional Networks)模型直接在可变长度的图像序列输入和可变长度的文字输出之间建立映射关系。Xu等[8]则将注意力机制引入LSTM模型,以提取到图像中更需关注的目标特征。目前在技术和性能方面处于领先地位的除了谷歌在TensorFlow 上开源的自动图像描述系统“Show and Tell”[5],还有Li-Feifei 团队[6]设计的方法也是CNN到RNN的描述过程。
相比于服装产品特征的多样性和消费者购物需求的多变性,2016 年在服装识别与搜索研究有一定的进展,DeepFashion[9]通过联合预测衣服的关键点处(如领口、袖口、腰间、裤脚等)提取特征,以抵消严重形变带来的影响。但是目前图像分类、目标检测和图像语义分割等处理技术大都还仅仅处在对服装款式单一的分类(款式和颜色特征)任务上,无法识别出商品属性上消费者更关注的特性(如面料、风格),对图片自然语言的描述工作也更多地注重语言的流畅性和结构完整性;这都局限了产品信息的展现,不利于服装特征的描述和信息的检索。故本文利用目前趋于成熟的电商平台提供的丰富描述标题,挖掘文本信息里服装特征,将深度视觉和自然语言处理结合,按一定的关联准则整理图片和文本特征,作为输入训练LSTM 模型,生成服装特征的自然语言描述。这样不仅可以改进商家手工标注带来的繁琐,还可以提高商品的分类准确性和服装信息的全面性,提高搜索的精度和用户的购物体验。
2 获取文本特征
2.1 文本预处理
文本语料整理自各电商平台爬取的特定款式服装店铺提供的结构化描述语句,按服装款式类别保存为txt 文件,共12 个。文本预处理是特征关联中获取文本特征的第一步,利用Python开发的结巴中文分词组件。结巴分词支持三种分词模式:全模式、精确模式、搜索引擎模式。服装图像的特征描述最终用于电商平台的信息检索,故本文采用搜索引擎模式,它能在精确模式的基础上对长词进行更细粒度的切分,提高分词的召回率。
其处理过程如下:
1)基于Trie 树构建款式语句的有向无环图(Directed Acyclic Graph,DAG)
将图片的描述语句所有可能成词的情况构建DAG,一个词对应于DAG 中的一条边,初始字符为边的起点,结束字符为边的结点,词频为边上权重,图的流向表示字符顶点顺序。
2)动态规划求解构词的最大路径
使用Unigram(一元)的语法模型,最大概率问题转化求最大路径,将当前词出现的概率P(wi)设为自身词频J(wi)/N(J(wi)为wi在语料中出现次数,N 为语料总词数),句子的最佳分词方案win=(w1,w2,…wn)为最大联合概率,满足:
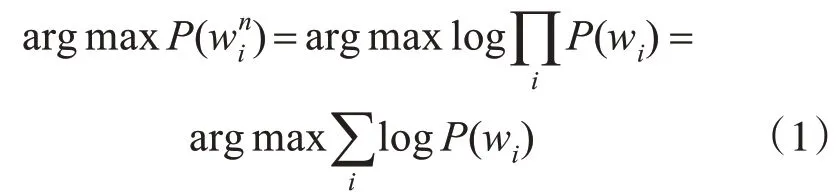
3)HMM识别未登录词
将没有被收录在分词词表中的人名、地名、店铺名等切分出来,自定义部分停用词(如时间(2017年)、新款等)以达到过滤效果。
由于店铺商品描述文本语料数据本身趋于结构化,分词效果准确率高。以夏天连衣裙为例,显示分词后的结果如图1 所示,空格作为词间的分隔。

图1 夏天连衣裙分词效果
2.2 提取文本特征
在同一类服装的款式特征中,部分特征具有普遍性和互为潜在关联,很多规律有章可循,对应的文本描述词也是整个语料的高频词或共现高频词,而仅仅凭借图像特征提取是无法获取的,所以文本特征词的提取是非常重要的步骤,特征的好坏直接影响着语句生成的优劣。
基于研究的领域特点,文本特征的计算分为两类:权重值高的词语和与高权词具有高共现率的密切联系词语。权重值由修改的TF-IDF(Term Frequency-Inverse Document Frequency)[10]方法得到,定义了两个影响因子,权重值代表着词语的价值。
2.2.1 修正TF-IDF的款式高权重值计算
高权重词反应了某一服装款式的普遍特性,例如作为夏天的睡衣,对全棉(或纯棉)的布料需求很高。TF-IDF 是信息检索与文本挖掘中广泛使用的特征向量化方法,利用加权技术衡量一个关键词对于查询(可看作文档)所能提供的信息,TF 考虑词语在其对应的款式文本文件中出现的频率,IDF 考虑了词语在所有文本集中出现的区域集中性。路永和等[11]介绍了传统及一些改进的TF-IDF 算法。由服装语料的具体特征,本文修改了两个影响因子,并对计算公式做了优化,具体如下:
1)对于词语wi在该文本文件中出现的频率为J(wi)/N,频率越高,提供的信息对该文本(款式)越重要。
2)包含词语的款式文件数,文本文件数为M,m 为包含词语的文本数,m 越小,即它的范围小,那么它对该款式价值比较大,是该款式所特有的文本描述。
在这两种影响因子下,文本Tj下词语wi的权重值计算公式修改为
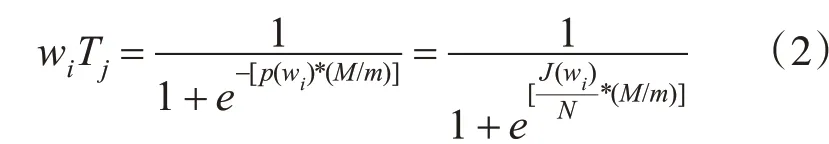
定义了款式文档相应的高权重值词集QTj,设置阈值β1,大于等于阈值词收录在高权重词集里,部分款式文件高权重词的结果如表1所示。
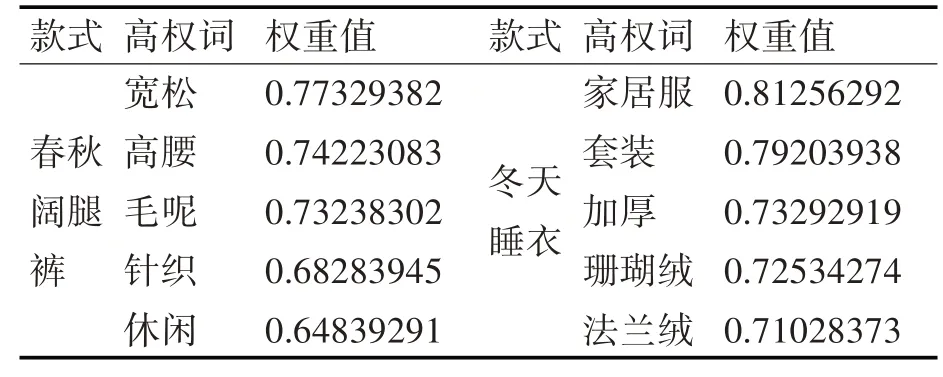
表1 高权词的结果
2.2.2 共现特征词的提取方法
与高权词存在高共现度的词是潜在密切联系的词语,对服装的特征获取具有显著意义。作为服装三要素的款式、面料、颜色是相互关联的,面料不仅可以诠释服装的风格和特性,而且直接左右着服装的色彩、造型的表现效果。比如连衣裙布料很多为雪纺,产品的拍摄地选择海边的几率很大,海、度假、沙滩裙的描述同时出现的概率很高,引入条件概率来计算词与词之间的关联度Rel(wi,wj),依次从RTj中选择一个高权重词计算与其他词的条件概率,公式如下:
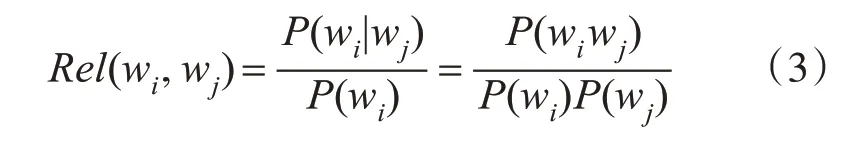
从这个公式不难发现,它的结果体现了共现词对的相关性程度,具体情况为
1)如果Rel大于1,wi在wj存在的条件下比无条件下出现的概率大,并随着Rel 值越大,wj带动wi的出现。
2)如果Rel 小于1,wi的存在抑制了wj的出现。
3)如果Rel等于1,那么wi和wj相互不存在关联。
将Rel>1 的共现词对收录在高共现词对集合RTj中,得到需要的文本特征:高权重值词集QTj和高共现词对集合RTj。利用它们按一定规则与图像特征进行关联。
3 基于特征关联的服装图像特征描述
3.1 提取图像特征
VGG16[12]是公认的较好的深度卷积神经网络模型,它赢得了2014 世界ILSVRC(ImageNet Large Scale Visual Recognition Challenge)在数据集ImageNet 上目标检测的冠军,把VGG16 应用在本文的图片数据集上训练。首先使用labelImg 工具对服装图片进行基于款式的人工标注,标注的内容是目标对象和对象的ground truth boxes,VGG16 模型默认输入尺寸224px*224px,其他的参数Minibatch 等于256、bias 为0、高斯分布服从(0,0.01),预训练权值参数模型提取图像特征。
3.2 基于LSTM的自然语言描述模型
本文使用LSTM 网络模型[13]进行自然语言描述,作为一个时间递归神经网络,它包含一个内置的记忆单元来存储信息和学习长期依赖信息,解决了“梯度消失”和“梯度爆炸”问题,模型在自然语言领域已经取得了很好的效果。利用LSTM 能够处理不同长度输入和生成不同长度的序列作为输出的特点,本文的输入是特征关联后的特征向量和图片标注的自然语言特征描述语句转化后的向量,输出是单词序列{y1,y2,…,yn},学习和训练LSTM模型的部分参数如表2所示。
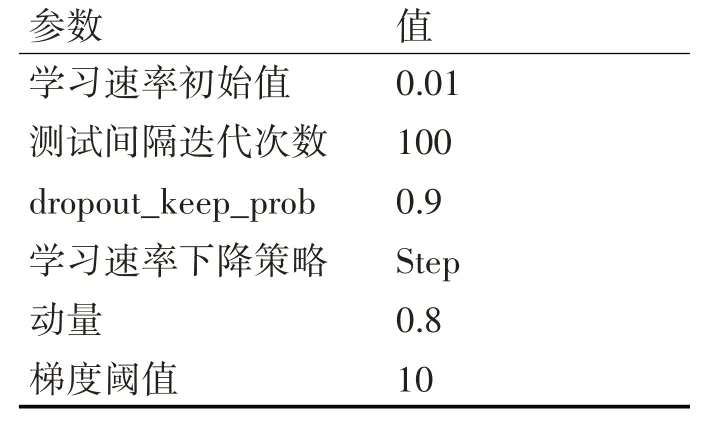
表2 训练LSTM模型部分参数
3.3 引入特征关联的算法流程
特征关联是对服装图像的图片特征和文本特征按一定的规则获得最优的服装信息,用于服装特征的自然语言描述生成,算法步骤如下:
1)图片预处理:把原始图片缩放到最小边S=384px上,然后在整个图片上提取224*224的片段;
2)图片特征提取:提取的图片片段输入3.1 节预训练的VGG16 网络进行图片分类,并提取全连接层(fc7)的特征向量;
3)特征关联:对VGG16网络fc7的4096维特征向量进行拆分,获得相应的特征目标向量,映射到2.2.2 节描述的RTj中,若存在共现词对,收入到特征向量集合Ci中,然后将图片类别映射到2.2.1 节描述的QTj中,得到除共现词对以外相应的款式高权词集合,按权重值排序收入备选特征向量集合Cr中;
4)对第3)步得到的备选特征集合Cr进行筛选,然后连接到特征向量集合Ci中,使组合后的集合大小与训练数据集标注的自然语言描述向量维度一致,并一起作为模型输入,最后学习和训练基于LSTM的自然语言描述模型;
5)测试阶段:使用通过训练得到的权值向量W,在测试数据集上验证生成的自然语言描述的评估分数。
4 实验与结果分析
4.1 实验数据集
本文实验数据来源于香港中文大学开放的large-scale 数 据 集DeepFashion[9]和 整 理 自 各 电 商平台爬取的数据。数据分为两种:图像数据和文本语料数据,每张图片对应一条店铺爬取的描述语句,和两条由人工标注的语句。图像数据12000张,包括按要求选定的部分DeepFashion数据,图像数据及其描述语句的70%作为训练集,余下为测试集。训练数据和测试数据无重复以保证实验结果的准确性。同时把图片训练集的描述语句按款式保存为文本文档,用来提取文本特征,其中共计款式12 种,各种款式的服装数据量相当,并统一图片标注格式。
4.2 评价指标
为了对提出的方法进行更客观全面的评估,本文的评估指标有两种:采用自动评价标准中的BLEU(Bilingual Evaluation Understudy)[14]评估和人类判断[15]评估。人类判断就是对生成的语句描述与参考的服装特征描述对比进行错误率打分。
BLEU计算标准在图像标注结果评价中使用很广泛,用它来分析待评价的特征描述语句和参考的描述语句之间n 元组的相关性,图片Ii由模型生成的自然语言描述语句是Li,参考标注语句的词语集合Si={Si1,Si2,…,Sim}(i=1、2、3),本文只评价语句里面的BLEU_1 和BLEU_2 在所有参考语句里面的概率得分,对于Si中的重复词或者相似词作为一个词处理,因为商品的语义描述主要用于检索,注重对商品特征描述的全面性,BLEU_3 和BLEU_4 这两种长元组的评分是对语言流畅性的评价。计算出的指标值越高表示描述越接近参考语句。
4.3 实验方案
本文图片序列特征提取、描述文本语料训练和特征关联,以及自然语言描述模型的训练均使用深度学习框架Caffe[16]完成,并在高速并行的图形处理器GPU 上计算以提高训练的速度。在本文的测试集上,从横向和纵向上分别评估了多种图像自动生成自然语言描述的模型,横向上评估了以往经典模型和本文模型的差距,纵向上评估了在以往模型的基础上使用本文的特征关联后的表现;以及本文方法在产生好的特征表现时需要付出的负面代价。
4.4 实验结果分析
4.4.1 BLEU的评分结果
为了验证算法的有效性,实验评估包括Deep-Fashion[9]的服装图像目标识别方法(该方法通过联合预测衣服的关键点,学习衣服的局部特征用于检索,如领口、袖口、腰间、裤脚等),部分流程化方法(Kiros 等[4]的CNN+LSTM 模型)和端到端模型(如Vinyals 等[5]的CNN+RNN 的模型)。实验结果如表3所示。
通过数据的对比分析可以得出以下结论:
1)从横向上进行模型的对比发现,在本文VGG16+LSTM 模型上关联了文本类型的特征后在评测分值上获得了明显的提升如表3 中的第6、7行,也以明显的优势超过了其他的模型方法,表中的第1、3、5、7行。
2)纵向上,本文特征关联的思想用在其他模型上进行服装特征生成能够获得效果的提升。如表中前两组的对比可以显示BLEU_1、BLEU_2 的评测分值提升明显。
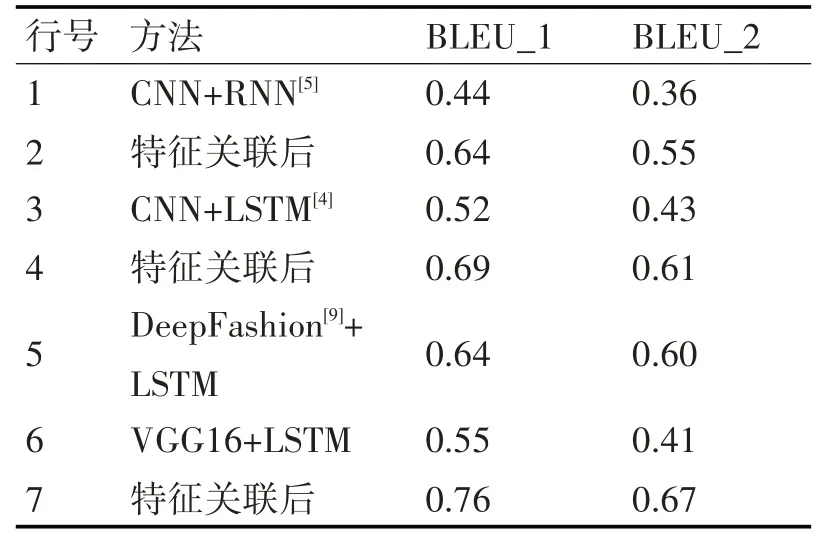
表3 BLEU评估结果
3)利用DeepFashion[9]+LSTM 方法在服装特征提取上也有着较好的实验效果,能识别出服装领口、袖口、腰间、裙摆等部位的细节样式,认为该方法获取服装特征与本文从文本获取的服装特征形成互补,可以和本文特征关联方法结合做进一步的实验研究。
4.4.2 人类判断的实验结果
人类判断是为了更客观地评价本文方法。把错误率分值分四个等级:[0.90~1.0]分表示描述没有错误,[0.70~0.89]分表示描述中有些小错误,[0.40~0.69]分表示描述错误明显(明显错误特征有1~3 个)和[0~0.39]分表示描述与图片无关。挑选了四张分别在不同错误率等级的图片如图2 所示,生成相应的语句描述如表4 所示,错误率分值由高到低处在四个等级中。统计在特征关联前后模型在四个错误率等级的数据项分别占有的比例如图3所示。

图2 错误率等级的服装图片
从图4 中可看出,特征关联后的模型,生成的图像特征在高分段的比例相对于特征关联前的比例会有所下降,在[0.90~1.0]和[0.70~0.89]两个分段分别下降了0.04和0.08个百分点,但下降的幅度不大,在[0.40~0.69]的分段提升了0.09 个百分点。由BLEU 的实验结果分析对比,文本特征挖掘了更多的服装特征词,生成的语句描述中融入了较多的服装特征信息,错误率提高是合理的,在只进行图像识别技术获取的图像特征生成自然语言描述时,语句更注重语言的流畅性和结构的完整性,而忽视了服装的信息呈现,所以相应的错误率较低。
表4 生成特征描述的的错误率等级
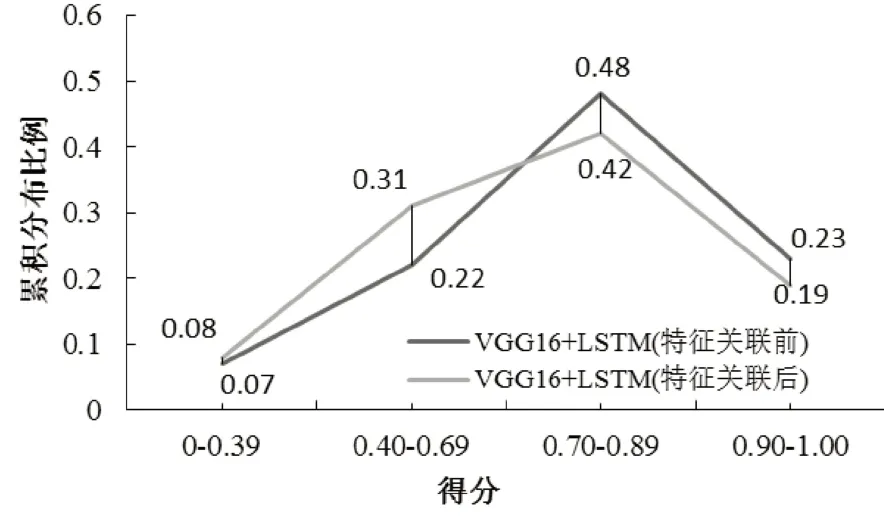
图3 错误率分布比例图
5 结语
针对目前服装领域产品特征的多样性和流行元素的多变性,利用现有的深度技术仅仅从图像上去获取服装的特征单一,极大地限制了服装信息的呈现,本文从服装的描述文本语料中进行数据挖掘获取文本特征,提出特征关联的方法将它引入到服装图像特征的自然语言描述模型中,补充获取图片特征的不足。在获取文本特征时,修正了TF-IDF方法对高权重词提取,也利用了条件概率的方法获得高共现词对,实验采取了人类判断和BLEU 的评估标准,结果表明由本文方法提取的文本特征和关联规则,在自动生成服装的自然语言描述语句中都能在合理的错误率上有效提取服装特征,更全面地描述服装信息,从而提高电子商务系统的服装检索的准确性,为用户提供更好的购物体验。在接下来的工作中进一步对DeepFashion中利用图像识别获取服装多处细节特征的方法和本文从文本中获取的服装多方面的属性特征进行结合做进一步的实验研究,并在针对服装商品领域的文本进行相似度的研究,以提高生成服装特征描述的质量。
