基于SVM与改进D-S理论电路板故障诊断算法
2019-11-20郝建新贾春宇
郝建新,贾春宇
(1.中国民航大学 基础实验中心,天津 300300;2.中国民航大学 电子信息与自动化学院,天津 300300)
0 引 言
随着电子技术的迅速发展,电路板上元件排列密度不断增大,集成化程度日益提高,其结构越来越复杂[1-3]。传统电路板故障诊断方法耗时长、难度大,对检测人员的专业技能水平要求较高,检测效率较低并且可能造成元器件及电路板的损伤。单一的传统检测方法越来越难以完成如此电路的故障判断与定位[4-5]。
研究发现,元件温度与故障之间存在重要联系,电路板发生故障时其上元器件的温度也会随之发生相应改变,这给电路故障与诊断提供了一种新的思路[6-8]。然而,只依靠温度信息同样不能提供电路板故障诊断所需的全部信息。
为获取更全面的故障信息[9-10],本文提出一种新的电路板故障诊断方法,将传统方法与红外技术相结合,提高故障诊断准确度。首先,预处理电信号与红外信号,构成故障特征向量;将特征向量分别输入到SVM 诊断模块组,通过不同证据体的权重系数及基本概率分配构成加权概率分配;最后,将各证据体下加权概率值进行基于D-S 证据理论的融合,获取诊断结果。利用本文算法,对标准滤波电路故障进行试验检测的结果表明,与单一传感器诊断算法相比较,本文算法提高了故障诊断准确度,为电路板故障诊断提供了新的思路,对电路板故障快速诊断与维修具有较好的指导作用。
1 SVM与D-S证据理论
1.1 SVM基本原理
SVM 是由贝尔实验室 Vapink 于 20世纪 90年代提出的一种新的机器学习理论[11],以统计学习VC 维理论与结构风险最小化原则建立。对给定的一个两类模式分类问题,基于SVM 的线性分类问题求解二次规划:
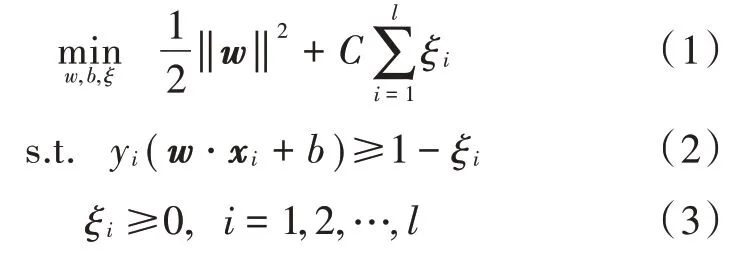
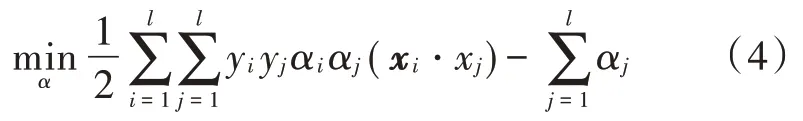
约束条件:
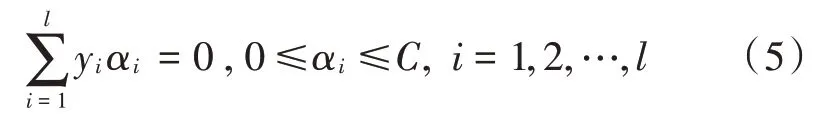
在非线性情况下引入变换φ:Rn→F,把样本从输入空间Rn映射到高维特征空间F,使得原空间非线性可分的两类样本在高位空间变得线性可分。引入拉格朗日函数,式(1)可以优化为:
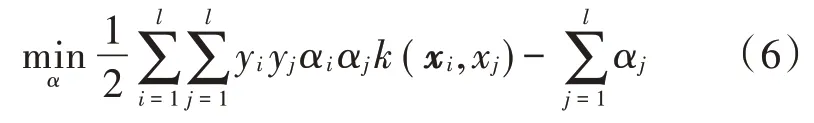
约束条件:
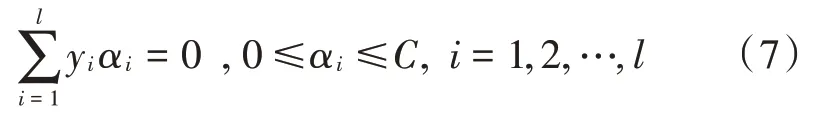
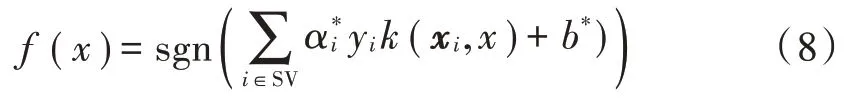
1.2 D-S证据理论基本原理
D-S(Dempster-Shafer)理论的实质是在同一识别框架下,将不同的证据体通过其证据组合规则合成一个新证据体的过程[12]。
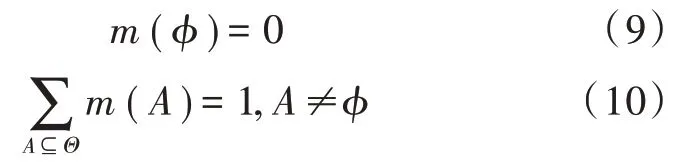
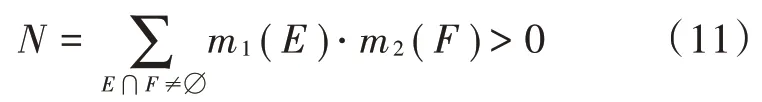
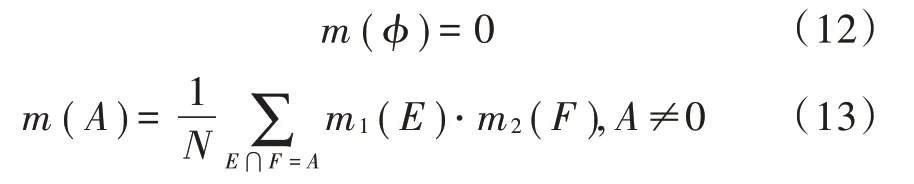
式中,N为规范数,其作用是将空集之上丢失的信度按比例分配到非空集上,从而满足概率分配要求。N值是证据冲突程度的反映,N值越小说明证据的冲突越大;如果N=0,则证据完全冲突,合成公式都不再适用。
2 基于SVM和改进D-S理论的故障诊断算法
本文将SVM 算法与D-S 理论相结合,按照如下步骤完成故障电路板卡的故障诊断,流程如图1所示。
1)通过使用不同的设备及传感器,获得故障电路板卡的输出的电信号以及电路板元件温度信号数据,利用小波分解处理原始数据,提取特征参数;
2)建立SVM 诊断模块组,将预处理完成的特征参数作为诊断模块的输入,构建混淆矩阵;
3)利用混淆矩阵计算诊断模块的可信度与加权系数后,将特征参数输入SVM 模块,完成故障类型“一对一”分类,提取证据体隶属度与BPA;
4)基于同一识别框架下改进D-S 证据理论,完成不同证据体所提供的加权BPA 的推理融合,确定故障类型。
2.1 基于SVM的初级诊断及可靠度分析
对于电路板不同工作状态下的输出响应信号,选取最优小波函数对输出响应数据进行多尺度分解,将获得的不同故障模式下输出信号的高频部分系数做进一步处理,作为SVM 诊断组的输入特征向量。
对于工作与不同状态下的电路板,利用红外设备提取工作元件的核心区域温度随时间变化的序列值,对获得的核心区域温度信息做进一步处理后,作为另外一个SVM 诊断组的输入特征向量。
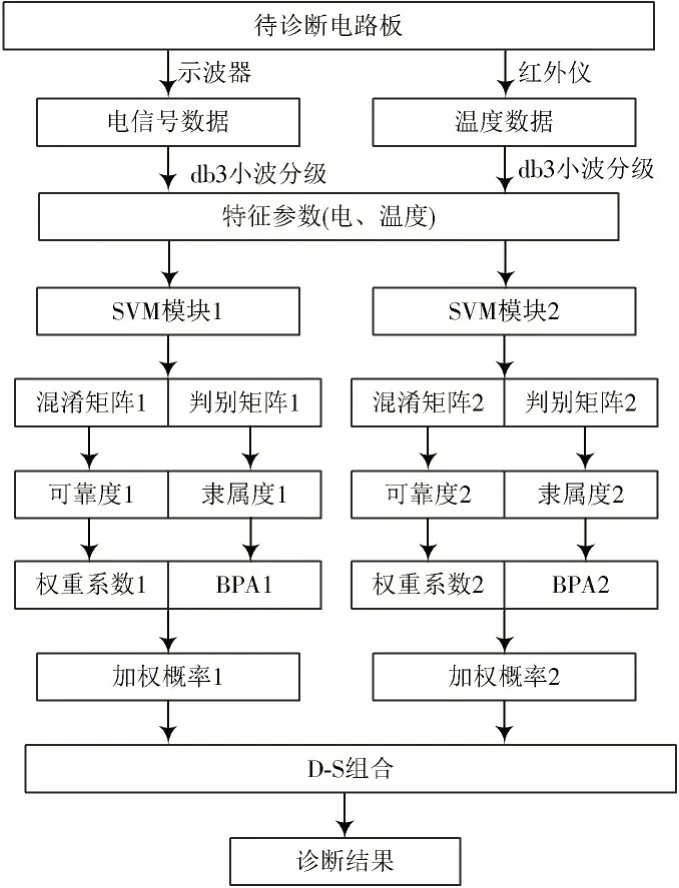
图1 故障诊断算法流程图Fig.1 Flow chart of fault diagnosis algorithm
基于SVM 的初级诊断则是将上述两类证据体所提供的特征向量分别输入到各自的SVM 诊断模块中。假设共有n类故障模式,分别为通过各自SVM 诊断子模块的故障诊断测试,可以得到n×n维故障诊断混淆矩阵CM(Confusion Matrix)。

式中:cmij表示第i类故障被SVM 诊断模块判别为第j类故障的数量1 ≤i≤n,1 ≤j≤n。由此可知,矩阵中对角线元素即为被故障被诊断正确的数量,混淆矩阵的提出反映了该诊断模块对于此类故障的诊断可靠度(Reliability)
不同SVM 诊断模块的混淆矩阵反应了其诊断结果的可靠度,那么对于故障类型j,其诊断结果的可靠度R_Fj为该诊断模块正确判断j类故障的数量与该模块所诊断的所有j类故障数量的比值,如下:
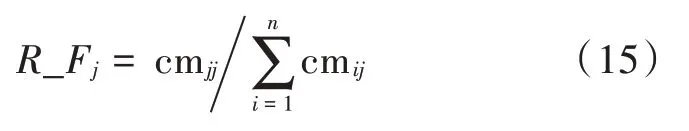
依据R_Fj得到每一个SVM 局部诊断模块的可靠度信息,其可靠度越高则代表该SVM 诊断模块的结果越可信。
2.2 基于SVM的基本概率分配
如何构造并获取BPA 是有效应用D-S 理论的关键。本文利用SVM 局部诊断模块概率输出作为D-S 理论BPA,采用“一对一”算法,对识别框架中的n类故障模式建立个SVM 子分类器。其求解问题可以描述为:
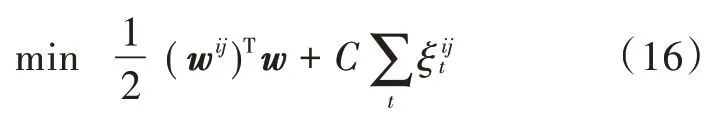

Fi,j表示故障类别投票分类结果,如果计算结果判别为i类,Fi,j=+1;若判定属j类,则Fi,j=-1。SVM 的判决矩阵的第j行即为第j类参与的两两分类次数为n-1次,被判决为j类的次数即j行中投票结果为1 的次数之和。引入隶属度,j类参与两两分类时被判决属于j类的次数与j类参与的总分类次数之比。
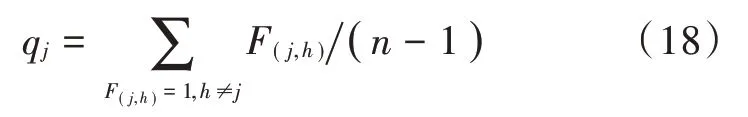
对于SVM 分类器无法识别的类,引入不确定的隶属度概念。
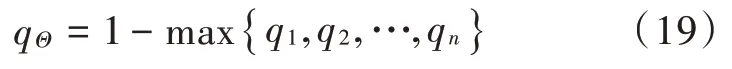
依据“一对一”SVM 多分类判决矩阵得到的隶属度qj越大,那么该故障属于j的可能性也就越大,该类故障的BPA 也就越大。据此,BPA 分配公式为:
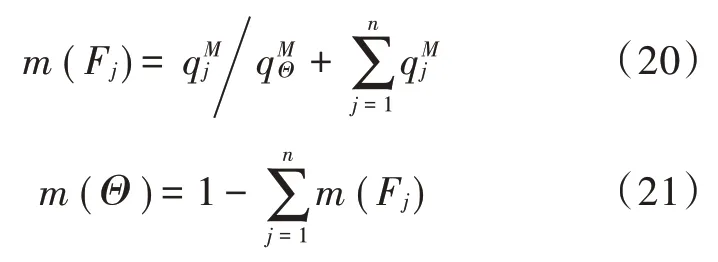
式中,M定义为各类故障模式的隶属度qj之和,代表多分类规模。
2.3 基于改进D-S理论融合诊断
本文中综合利用了故障电路板的电信号信息与红外热信息作为原始证据数据,经处理后进行证据诊断融合。如果不同传感器的证据数据存在严重冲突,D-S 证据合成法则无法正确反映客观事实甚至不再适用。
出现这种缺陷的原因主要是由于在进行证据合成过程中,将两种证据体视为同等重要,没有考虑到不同来源的证据体在D-S 识别框架中是具有不用可靠度的。因此,基于第2.1,2.2 节的内容,将可靠度与基本分配概率引入到D-S 证据合成理论中完成改进。
在相同的识别框架Θ中,来源不同的各证据体对框架中各种故障命题识别的可靠度定义为R(F)→那么
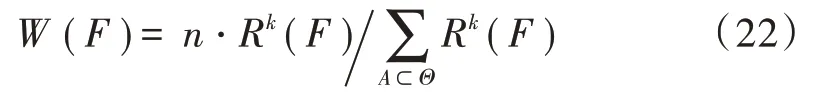
式中,W(F)是证据体对F的权系数分配,证据体对故障命题的可靠程度越高K越大,权系数W(F)代表了不同来源证据体对于识别框架内故障命题的可靠程度。
为了充分考虑各证据体在融合中的权重,在进行D-S 证据融合中对SVM 的BPA 采用进行加权处理。对于∀A⊆Θ,加权后的概率分配为:
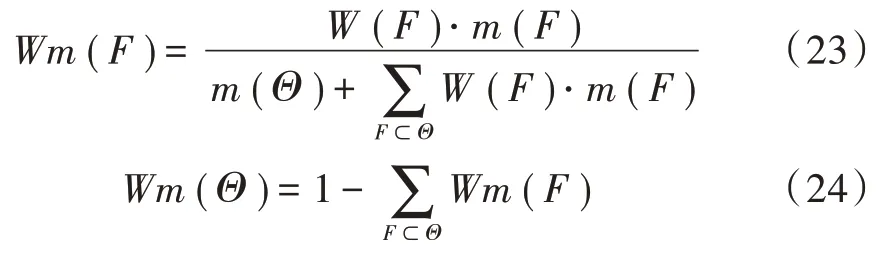
经过加权处理后的BPA,增强了合理性证据在故障诊断中对结果的判别影响的同时,削弱不合理证据对判别结果的影响。依据式(25)所示:
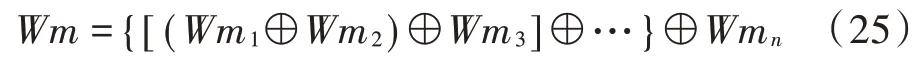
将多个证据的加权概率分配函数进行加权融合,得到识别框架中所有故障模式的诊断可信度Wm(Fj)和不确定度Wm(Θ)。
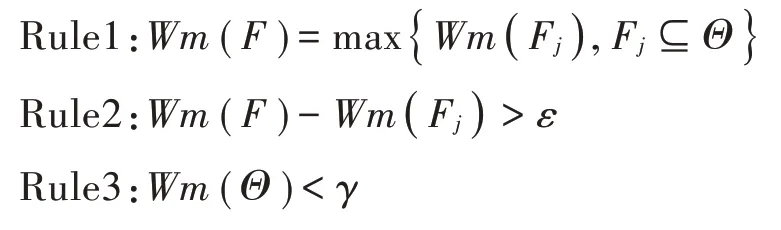
最后,依据Rule1~Rule3 陈述,要求确诊的故障模式其可信度不仅要最大,而且必须比排名第二的故障的可信度大出某一个阈值ε。对于故障的不确定度,则要求其应小于某一个值γ。
3 实验结果分析
本文选择经典滤波电路如图2所示。构建滤波电路中电阻R4和R5、电容C1和C2、芯片 Q1共 5 种元件故障模式。 因此,故障系统识别框架可设置为Θ=如表1所示。
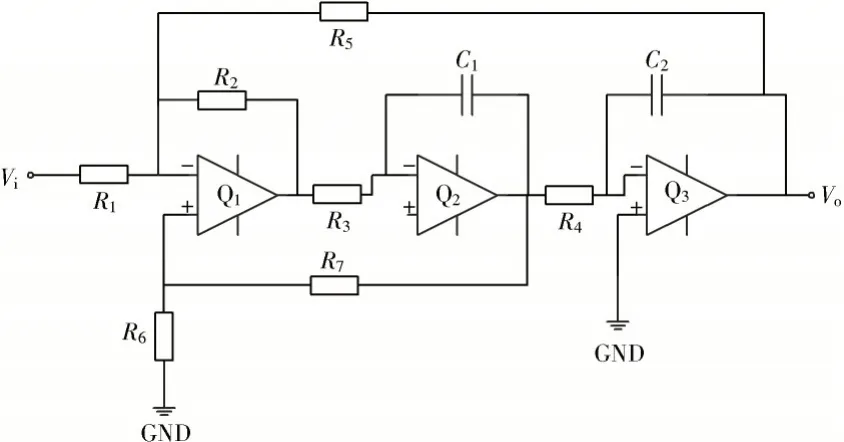
图2 滤波电路图Fig.2 Circuit diagram of filtering
针对5 种电路板元件故障,输入一阶阶跃信号,使用DS4000 系列示波器采集滤波电路输出的响应数据,通过Matlab 对原始输出数据做5 层db3 小波分解,获取高频系数;每层高频小波系数做绝对值求和,得到的特征向量作为证据体E1;利用德国Infra Tec 公司ImageIR 系列高端红外成像热像仪采集滤波电路上元件随时间变化的温度序列数据并进行预处理,将得到目标元件温度平均值、平均变化率、方差、平均二阶变化率组成特征向量作为证据体 E2。利用不同证据体所提供的两类特征向量组成的独立特征子空间,从不同的角度对电路板的故障进行诊断。

表1 故障模式框架及故障信息表Table 1 Fault mode framework and fault information
基于证据体E1,取每组故障模式的特征向量100 组,将所有的特征向量输入到该证据体对应的SVM1 诊断模块,得到混淆矩阵CM1。
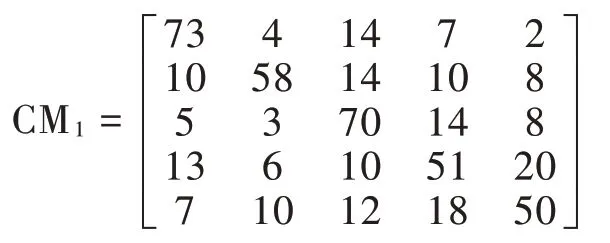
基于证据体E2,取每组故障模式的特征向量100 组,将所有的特征向量输入到该证据体对应的SVM2 诊断模块,得到混淆矩阵CM2。

依据式(15)对两个混淆矩阵进行处理,从而得到两个证据体对于该电路板元件5 种故障模式的可靠度指标,如表2所示。
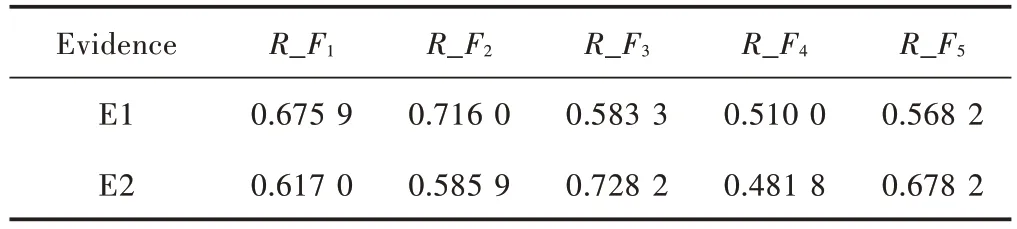
表2 两个证据体对故障识别可靠度Table 2 Reliability of two evidence bodies for fault identification
将各个证据体对各个故障识别的可靠度指标代入式(22)中,得到各证据体的加权系数,如表3所示。
取一组故障已明确(F2:R5阻值超过50%)的原始属于作为样本,将该样本分别输入到已经构建完成的各单一故障诊断模块,按照“一对一”分类算法进行SVM 投票分类,投票结果如表4所示。将投票结果按式(18)和式(19)完成局部诊断的隶属度计算,结果如表5所示。
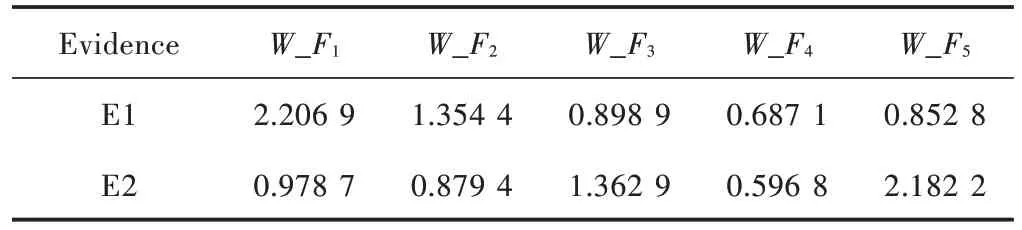
表3 各证据体对故障的加权系数Table 3 Weighting coefficient of each evidence body to fault
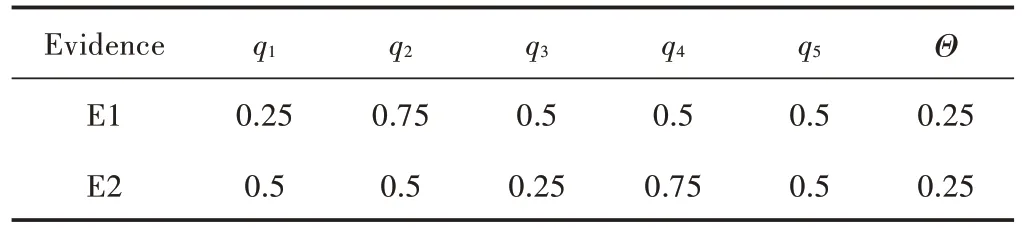
表5 各证据体的局部诊断隶属度Table 5 Membership degree of local diagnosis of each evidence body
各证据体的基本概率分配按照式(20)和式(23)进行计算,得到的具体结果如表6和表7所示。
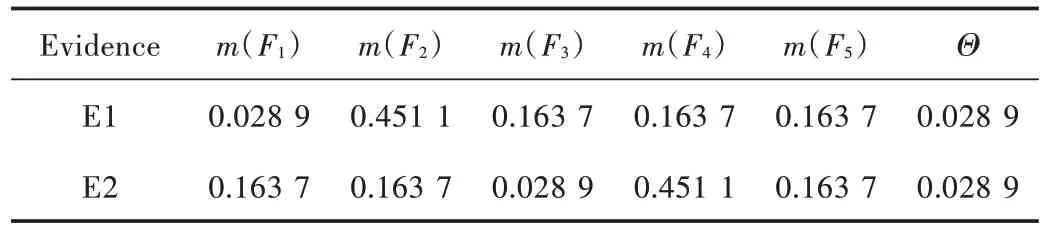
表6 各证据体基本概率分配(BPA)Table 6 Basic probability allocation(BPA)of each evidence body
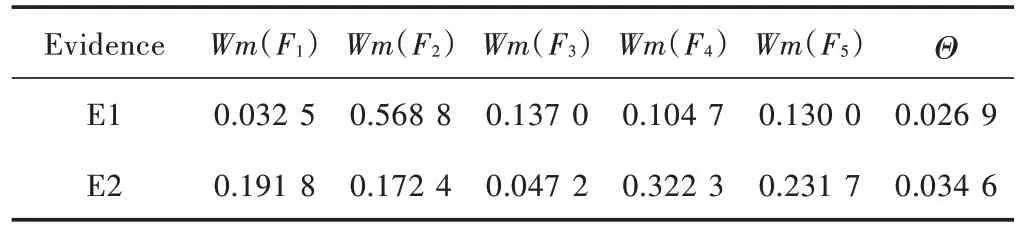
表7 各证据体加权概率分配Table 7 Weighted probability distribution of each evidence body
分析表4~表6可以发现,不同的证据体所得到的各个故障的模式在投票结果、隶属度和BPA 存在明显的冲突,如证据体E1 对故障F2的BPA 和证据体E2 对故障F4的BPA 相等,及不同的证据体对于同一种故障模式所得到的诊断结果不同,对于下一步多证据体的融合起到负面影响。将表6与表7进行对比可以发现,通过对BPA 进行加权处理操作,证据体E1 对于故障F2的可信度由0.451 1 提高到0.568 8;证据体E2 对故障F4的可信度由0.451 1 降低到0.322 3。由此可以说明,通过对证据体进行加权处理,可以有效地降低不利证据体对错误故障的概率分配,有利于后续的加权融合操作,提高多证据融合诊断的准确率。
分别利用传统的D-S 融合诊断算法和本文的加权D-S 融合诊断算法对证据体E1 和E2 两个证据体进行融合诊断,诊断结果如表8所示。由该诊断结果可以得出,在传统的D-S 融合诊断算法下,F2与F4故障可信度都是0.380 2,并不能通过该诊断结果判断故障的类型;经过BPA 加权后再利用D-S 进行融合诊断,F2的可信度此时由0.380 2 提高到0.520 2,而诊断错误的故障F4的可信度则降低到了0.195 8。由此可以得出,利用本文改进后的D-S 加权融合算法,对于正确的诊断结果给予加强,对于错误的诊断结果则给予削弱,从而有效地降低了不同证据体之间对于诊断结果的冲突,提高了故障诊断的准确率。
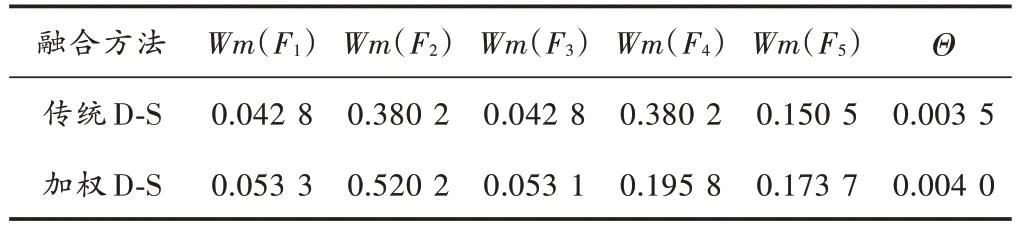
表8 E1 & E2 融合诊断结果Table 8 Results of fusion diagnosis of E1 & E2
最后,选取每种故障模式下100 组数据样本进行预处理提取故障特征,分别输入到单一的SVM 故障诊断模块和基于SVM 与加权D-S 融合的诊断命中进行测试,决策规则均参照 Rule1~Rule3。其中ε取 0.3,γ取 0.1,测试结果如表9所示。分析该诊断结果可以发现,利用本文基于加权的SVM & DS 故障诊断算法得到的诊断结果识别率远高于传统方法与单一SVM 诊断方法,诊断准确率明显提高。
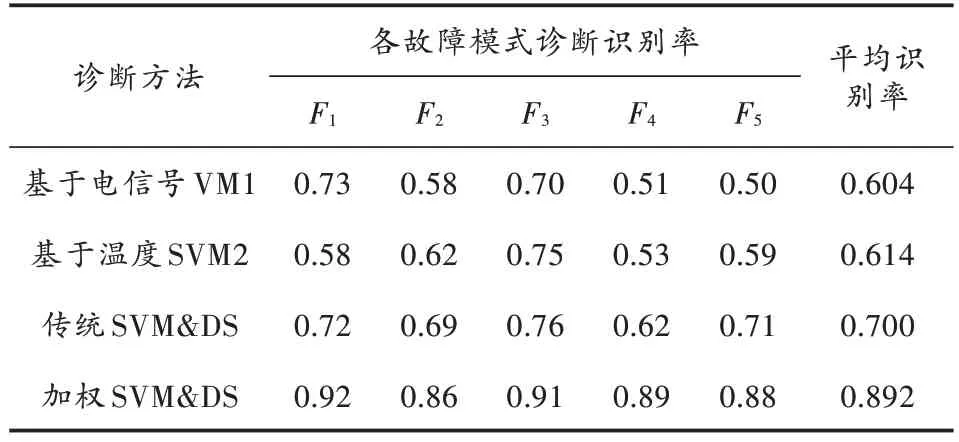
表9 单一SVM 与加权融合诊断结果对比Table 9 Comparison of diagnostic identification between single SVM and weighting fusion
4 结 论
本文提出一种基于SVM 与D-S 理论相结合的电路板故障诊断算法,将获取的电信号数据与和红外温度信号数据做预处理后分别输入到对应的SVM 诊断模块,将输出结果按照本文算法进行加权融合,从而得出最终诊断结论。本文算法有如下特点:
1)本文引入可靠度与加权系数的概念。将原始数据进行预处理后分别输入其对应的单一SVM 诊断模块形成混淆矩阵,进一步获取到该证据体在不同故障下的可靠度,通过分配加权系数以提高正确诊断结论的可信度,降低错误诊断结果可信度,从而解决了不同证据体之间对诊断结论的冲突问题。
2)对于“一对一”SVM 分类算法的硬输出判决矩阵无法完成后续研究所需的BPA 分配问题,本文利用“一对一”耦合并投票的方法构造了一种BPA 分配方法,为后续基于D-S 的融合提供了有效地概率分配数据。
3)本文算法充分利用电信号数据与红外温度数据,通过改进D-S 理论进行融合,在有效降低了两类证据体之间冲突的前提下,可以更加有效地使两类证据体所提供的故障信息实现互补。对比单一的SVM 诊断算法和传统的SVM & DS 诊断算法,本文算法对于诊断结果的准确率有显著提高,充分验证了多信息融合对于故障诊断的有效性。
