基于Nutch的多源社交媒体情报采集系统
2019-11-19傅魁覃桂双
傅魁,覃桂双
(武汉理工大学 经济学院,湖北 武汉 430070)
一、引 言
中国互联网络信息中心第42次《中国互联网络发展状况统计报告》显示,截至2018年6月30日,我国网民规模达8.02亿,首次超过8亿,互联网普及率为57.7%[1]。互联网成为当今社会信息传播的重要载体,基于互联网技术而生的新型网络交互平台——社交媒体(social media)[2]随之在全球广泛应用,对社会的政治生活、网络安全、商业活动及公共事件等方面产生深远影响。高速发展的社交媒体平台成为互联网情报收集场新重心[3]。
当前的情报采集系统主要面向单个应用[4-9],存在应用范围窄、采集效率低等问题,而针对各类社交媒体平台的通用采集系统仍然屈指可数。因此,在社交媒体情报采集非常必要的前提下,基于对情报采集系统通用性和高效性要求的综合考虑,充分利用Nutch[10]开源技术在网络抓取方面的优势,构建多源社交媒体情报采集系统势在必行。为了实现对互联网上多源社交媒体情报的采集,笔者设计了一个基于新闻、论坛、贴吧、微博等互联网平台的社交媒体情报通用采集系统,以期通过该系统实现对互联网社交媒体平台情报的全方位采集,准确及时、大批量地自动获取互联网情报,摆脱人工采集的繁杂与不便,同时为媒体监测、舆情分析、数据挖掘及在线社会支持等相关领域提供大量准确的数据支持。
二、多源社交媒体情报采集系统整体结构
本文采用模块化程序设计思想,经过对Nutch改进和扩展之后的采集系统整体模块架构如图1所示。整个系统以Nutch采集组件模块为架构基础,将社交媒体情报平台模块作为系统入口,将网络新闻采集模块、论坛贴吧采集模块和微型博客采集模块作为核心工作单位进行情报采集,最后将采集结果输出至情报数据存储中心模块。
其中,社交媒体平台模块的主要作用是向系统输送多源社交媒体情报采集源,支持平台包括网易新闻、今日头条等新闻平台,百度贴吧、豆瓣等贴吧论坛平台,以及新浪微博、腾讯微博等微博平台。情报数据存储中心模块由采集源数据库、新闻内容数据库、论坛贴吧内容数据库、微博内容数据库四部分组成。采集源数据库用于存储URL、请求参数、解析模板等采集源数据,而内容数据库实现对系统抽取解析输出的情报数据进行存储和备份。

图1 社交媒体采集系统结构
(一)Nutch采集组件模块
Nutch采集组件模块以Nutch原有框架和部分组件作为系统基础,针对新任务需求进行抓取流程的修改和完善,解决了采集解析多源社交媒体情报方面的关键问题。该模块由采集列表组件、抓取组件、更新组件、解析组件等功能组件组成。采集列表组件将采集源数据库中存储的社交媒体URL分成多个待检索组别,抓取组件用于检索这些URL对应的网页源码并保存到本地,更新组件实现更新采集系统抓取结果并标记本次抓取是否成功的功能,解析组件实现对数据进行排序、分类、去重、过滤等功能。组件中的解析模板对网页源码内容解析并定位,URL解析出来的页面内容、解析网址、URL抓取后的状态等信息分别保存至Content、Parse_url和Crawl_fetch等输出文件中。
(二)网络新闻采集模块
网络新闻采集模块由新闻网站排名模块、新闻频道采集模块、新闻文章采集模块、新闻模板解析模块四个子模块组成。本系统根据新闻类网站的综合指标对各大新闻网站进行分析,以确定新闻采集的综合来源并形成采集入口。新闻频道采集模块主要有两个作用:获取频道类别中的频道名称列表,采集同一频道下的所有新闻文章页的链接URL列表。新闻文章采集模块从新闻链接URL列表中的各项找到新闻文章页,以实现获取新闻文章页代码并进行相关新闻信息采集两个功能。新闻网站的解析模板包括频道解析模板和文章解析模板,分别用于分析频道中的新闻列表网页以及具体新闻文章网页的源代码,并使用正则表达式等技术进行信息匹配,以确定要采集或过滤的数据块。
(三)论坛贴吧采集模块
论坛贴吧采集模块包含论坛模板解析模块、论坛版块采集模块、论坛帖子采集模块、论坛领域建模模块四个子模块。论坛领域建模模块用于建立论坛领域模型,确立版块及帖子的采集方法与相应的数据存储方式。版块用于划分相同主题的帖子,论坛版块采集模块对采集的论坛中主题相同的帖子进行内容的采集解析。帖子是论坛的最根本产物,包括主帖和回帖,论坛帖子采集模块实现对板块中具体帖子的内容进行采集抽取及存储的功能。论坛模板解析模块根据论坛的结构特点,采取分块解析的方式从版块及帖子网页源代码中抽取出结构化的数据块,并解析出对应的数据项,封装存储,以备他用。
(四)微型博客采集模块
微型博客采集模块主要由微博模拟登录模块、微博话题采集模块、微博页面采集模块、微博模板解析模块四个子模块构成。由于目前的微博系统都需要用户登录才能浏览,本系统设计模拟登录模块通过微博平台提供的API接口模拟登录工作,再采用基于HTTP请求的爬虫技术进行数据抓取。话题采集模块实现抓取微博话题中关键字的功能,进而通过微博页面采集模块抓取具体微博内容。微博数据解析模块利用话题解析模板及微博解析模板对抓取到的数据进行转换并进一步解析,以满足系统微博领域模型的形式,同时对所有微博内容建立索引,最终保存数据到微博情报数据库中。
三、基于Nutch的多源社交媒体情报采集
首先,分别针对各采集模块建立领域模型,在社交媒体情报采集领域数据库设计相应实体;然后,根据社交媒体平台的模块化抓取思路,在Nutch开源技术的基础上对系统进行设计改进,抓取流程分为两轮;最后,基于领域实体作内容解析,即从网页源代码中根据需要抽取出结构化的数据并封装为领域对象,采集的各状态信息及采集到的网页内容保存于相应的数据库中。根据社交媒体平台的结构特点,本文采用“分块解析”的方法,从一个页面中定位出每一个数据块,这些数据块通常具有相同或相似的源码特征,再进一步抽取出对应的数据项,每个数据项对应有逻辑意义的一个领域概念,多个数据项能够组成领域实体。
(一)网络新闻情报数据采集
1.网络新闻领域建模
网络新闻采集领域数据库的主要实体包括频道、新闻、评论、图片、网站等(如图2所示)。频道用于划分主题相同的新闻,包含频道ID、URL、名称等属性,由若干篇新闻组成。新闻包含评论及图片,以及其他属性——网站ID、获取人ID、获取时间、关键字、内容、频道ID、URL、新闻来源、编辑人、发表时间、标题、新闻ID等。评论的属性包括父评论ID、评论内容、新闻ID、评论ID等。图片包含图片URL、新闻ID等属性。网站是新闻主页网站,其属性包括名称、URL、网站ID、权重等。

图2 网络新闻领域实体
2.采集流程实现
网络新闻采集由新闻频道采集和新闻文章采集两轮采集实现,采集流程如图3所示。

图3 网络新闻采集流程
首先,根据Alexa排名和CIIS排名的综合指标对各大新闻网站进行分析,计算网站权重并排序,以确定新闻采集的综合来源,从中选取一个新闻网站的主页作为采集入口,并将其注入新闻采集源数据库(即新闻采集源DB中),Reducer同时将相同key值对应的多个value值进行合并。此时进入新闻频道采集模块抓取频道列表页面的频道名称,采集列表组件选取符合条件的URL生成待抓取列表,抓取组件将URL地址作为输入,生成存放频道页面内容、每个下载URL状态的Content和Crawl_fetch两个文件夹,并由解析组件的解析模板对Content里面的二进制源代码内容进行解析和整理,抽取出的外部链接、频道名称以及相应的所有新闻列表等分别存放在Parse_data和Pase_text等文件夹中。随后解析组件会进行二次解析,调用解析分页的插件来解析频道下一页的URL,并以此来判断抓取行为是否达到配置文件所设定的最大值。若未达到最大抓取值,则将该URL生成一个抓取项,放入抓取队列中,抓取组件和解析组件对其重复之前的操作,直至抓取的页数达到最大值为止,至此,频道采集工作完成。
接着进入新闻文章页面采集模块,将前面抓取解析出的新闻列表信息注入到文章采集数据库中,新注入的新闻列表URL形成待抓取队列,抓取组件根据该队列将对应页面源代码的内容抓取到本地,并由解析组件对抓取的网页进行分块解析,将文章的ID、标题、发表时间、编辑人、来源、URL、频道ID、文章内容、关键字、获取时间、获取人ID、网站ID等输出并保存到Parse_text文件夹中。另外,解析组件再次调用分页插件解析文章最后一页的URL,将该URL生成一个抓取项,直到同一篇新闻文章的抓取达到最大页数。如果文章的分页抓取从最后一页往前抓取时,解析出上一页的URL。最后进入更新单元,更新组件不断更新URL抓取队列,解析出新的外链。
最后,根据建立索引的算法对所有新闻文章创建索引,包括地址、关键词、内容等,供后续进行不同类型的内容的搜索、分类及匹配,并将相应数据保存到新闻情报数据库中。
3.新闻内容解析
首先用Xpath对初始URL对应的网页源代码进行抽取,定位新闻频道列表网页数据块,解析出该频道下的频道名称列表及其对应的URL和频道ID。进一步定位具体新闻文章页面数据块,输出文章ID、标题、发表时间、编辑人、来源、URL、频道ID、文章内容、关键字、获取时间、获取人ID、网站ID等相应的数据项,以及评论、图片等数据块到Parse_text中。解析单元对这些数据块进行析取,进而解析出父评论ID、评论内容、用户名、新闻ID、图片URL、图片ID等数据项。最后,系统将这些抽取的内容封装得到新闻领域对象。
(二)论坛贴吧情报数据采集
1.论坛贴吧领域建模
论坛贴吧采集领域数据库主要设计如下实体:主帖、回帖、用户、帖子列表网页、帖子网页等。每位用户每发表一次即产生一个帖子,帖子的页面由主帖和回帖组成,进行分页显示,主帖在第一页,可以没有回帖。板块的页面是帖子列表网页,进行分页显示,由一条条帖子(主帖)的基本信息组成,一般不显示回帖的信息。论坛贴吧领域实体如图4所示。
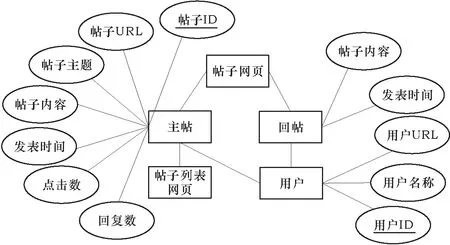
图4 论坛贴吧领域实体
2.采集流程实现
论坛贴吧采集由论坛版块采集和论坛帖子采集两轮采集实现,采集流程如图5所示。
首先进行版块采集。从采集源DB中将采集源注入到论坛版块采集数据库中,采集列表组件选取URL生成待抓取列表,接着抓取组件抓取出URL对应的网页内容,并由解析组件中从网页内容中抽取出所需数据,包括解析帖子列表,解析并抓取下一页,修改输出格式,用“多输出”输出帖子列表信息等操作。此外,解析组件会进行二次解析,抓取组件及解析组件循环直至抓取页数达到设定最大值。至此,版块采集工作完成。
随后进行帖子采集。先将上一轮板块抓取解析出的帖子信息,从Parse_url中注入到帖子采集数据库中,同时进行合并,以比较帖子的更新时间,将有更新的帖子的状态改为unfetched。接着选出所有状态为unfetched的URL并产生待抓取列表。抓取组件完整抓取URL对应的网页内容,同时解析组件对网页内容进行解析,抽取主帖与回帖的信息,解析并抓取下一页,覆盖Nutch的Parse_text输出等操作。另外,解析组件再次解析帖子末尾页URL,循环进行调用抓取及解析组件,直到抓取达到最大页数,则停止抓取。最后,更新组件将抓取的状态更新到帖子采集数据库中,不断更新解析出的外链。

图5 论坛贴吧采集流程
3.论坛贴吧内容解析
针对论坛贴吧的解析模板包括版块解析模板和帖子解析模板。系统首先抽取初始网页源代码并定位到帖子列表网页数据块,解析出该板块下的所有主帖列表。进一步定位其对应的主帖,抽取输出帖子URL、主题、内容、发表时间、点击数、回复数等相应的数据项,解析内容、解析网址及爬取时间等信息会分别输出保存至Content、Parse_url和Parse_data等输出文件中。该主帖数据块对应帖子列表数据块,进一步对该数据块进行解析,抽取出回帖数据块,输出回帖内容、发表时间等数据项。其中,主帖和回帖两个数据块均可以定位到用户数据块,进而解析出用户URL、名称等数据项。最后,对输出内容进行封装,得到论坛贴吧领域对象。
(三)微型博客情报数据采集
1.微型博客领域建模
针对微博采集领域数据库设计如下实体:微博、用户、转发、评论、微博话题等。其中,微博和用户是其他实体概念的基础。微博包含评论与转发,以及ID、URL、内容、抓取时间、转发数、评论数、发表时间等属性。用户是发微博或对微博进行评论或转发的人,属性包括名称、URL、ID、关注数、粉丝数、微博数、等级、认证方式等。微博话题由若干主题相同的微博组成,其属性包括URL、话题名称等。微型博客领域实体如图6所示。

图6 微型博客领域实体
2.采集流程实现
微博采集由微博话题采集和微博页面采集两轮采集实现,采集流程如图7所示。
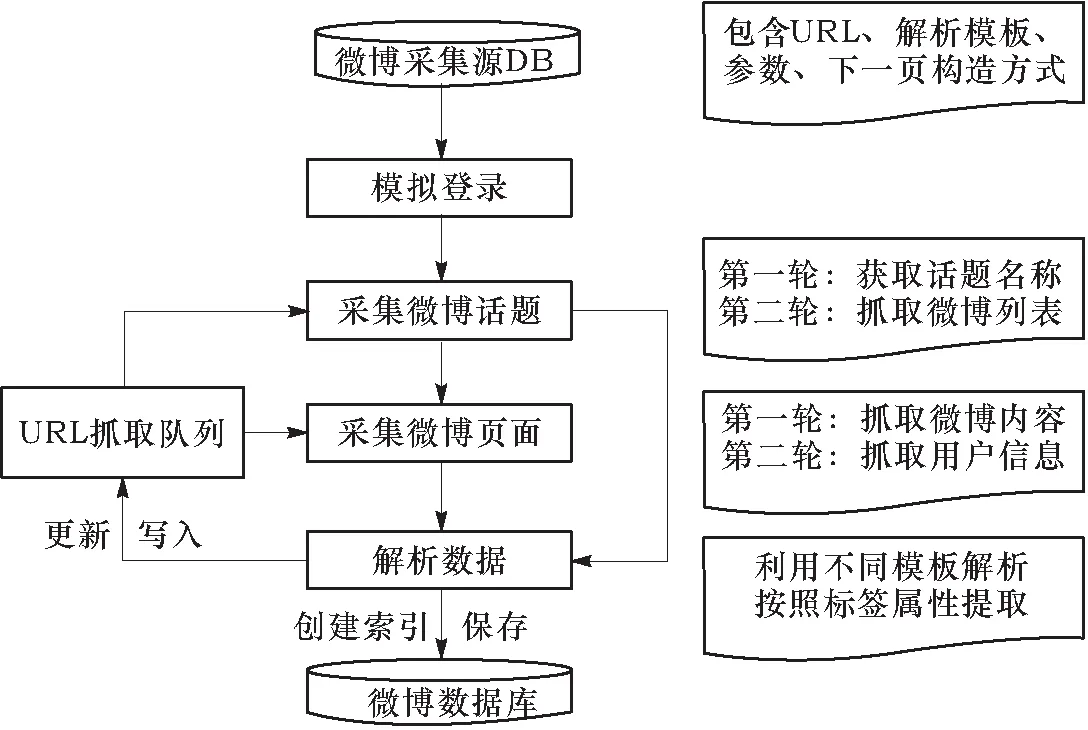
图7 微型博客采集流程
微博采集源数据库中的采集源包括URL、请求时所需发送的参数、下一页的构造方式、解析返回数据的模版。由于用户隐私策略限制,只有登录并通过验证后的用户才能访问微博所有的相关信息。复杂的登录机制问题对网络爬虫[11]提出了很大的难题,而API[12-13]在数据获取速度、调用次数等多方面存在限制,通过微博API调用只能抓取有限的数据。因此,本系统设计方案首先通过API接口来实现爬取系统对微博页面的模拟登录,然后使用网络爬虫来实现微博话题名称以及具体话题下微博的抓取工作。
首先进行话题采集。将采集源注入微博话题板块数据库,创建待抓取话题名称相应的URL列表并写入segments目录中。抓取组件依次抓取该目录下的列表网页内容,同时解析组件使用话题解析模板对抓取到的页面进行解析整理。再从采集到的话题中选取一个作为种子话题,将其析取出的相关信息输入抓取队列,进一步获取这个话题中的具体微博列表。其中,抓取话题名称以及微博列表的下一页是以参数p作为页数添加在HTTP请求里面的。在每次获取HTML数据的时候,解析单元先查验是否包含“下一页”三个字的链接,若包含,则说明还有下一页,继续进行抓取解析操作,否则停止抓取。每次抓完之后,p都需要加1,依次循环,直到输出所有页面话题名称及微博列表。
随后进行微博采集。将在话题采集模块解析出的微博信息注入到微博采集数据库中,更新微博状态并生成待抓取队列。微博在进入一个话题页面的时候,在页面下方会显示关于该话题的当前最新微博,这些微博是以话题名称为关键字利用微博搜索功能搜索出来的,系统通过发送HTTP请求获取最新的微博,在这个过程中系统会根据内容做一次去重和删除垃圾内容的操作。抓取组件抓取相应的页面内容,同时调用解析组件对抓取到的内容进行解析整理,将最初微博抓取返回的JOSN格式数据先转为HTML格式文本,再利用页面解析模板去除其中HTML标签、无用链接等冗余数据,然后将这些数据进一步解析为满足系统概念模型的微博形式,将页面分解得到的微博所属话题名称、用户、时间、链接等内容保存为Parse_data文件。同样,采用分页插件解析话题微博列表末尾页的URL,循环调用抓取和解析组件,直到抓取至最大页数。最后,对所有微博创建索引并保存到微博数据库中。
3.微博内容解析
解析微博话题列表和具体微博内容的方式相似,区别在于解析模板不同,后者需要解析的内容更多。系统首先对初始URL对应的网页源代码进行抽取,定位微博话题列表网页数据块,解析出该话题下的所有微博名称列表及其对应的URL。进一步定位具体微博页面数据块,输出微博URL、内容、发表时间、转发数、评论数、抓取时间、微博ID等相应的数据项,并分别保存到相应的文件中。由评论和转发两个数据块定位至用户数据块,并解析输出用户URL、名称、ID关注数、粉丝数、微博数、等级、认证方式等数据项。最后,系统将所有解析输出的内容进行封装,得到微博领域对象。
四、结 语
在对社交媒体平台结构特点进行深入分析的基础上,借助Nutch开源搜索引擎框架并加以改进,设计了一种模块化的多源社交媒体情报采集系统。以不同平台需求为基础,采取新闻网站的分类排名、论坛贴吧内容的分块解析、基于API与爬虫技术相结合的微博模拟登录与采集等方法,方便将系统应用到新闻、贴吧、论坛、微博等不同的社交媒体平台,以实现自动化、大规模的多源情报数据采集与解析,解决互联网情报采集中的难题。
